Spark RDD概念学习系列之rdd持久化、广播、累加器(十八)
1、rdd持久化
2、广播
3、累加器
1、rdd持久化
通过spark-shell,可以快速的验证我们的想法和操作!
启动hdfs集群
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ sbin/start-dfs.sh

启动spark集群
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6$ sbin/start-all.sh
启动spark-shell
spark@SparkSingleNode:/usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin$ ./spark-shell --master spark://SparkSingleNode:7077 --executor-memory 1g
reduce
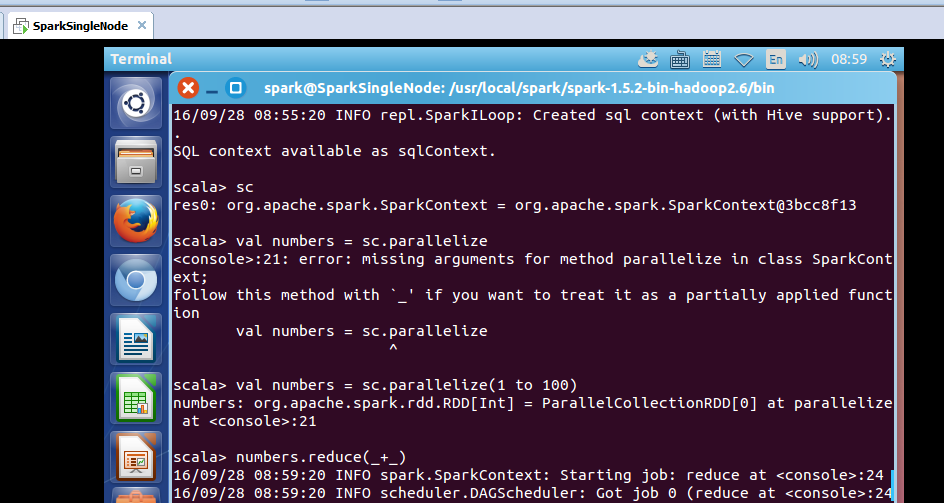
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@3bcc8f13
scala> val numbers = sc.parallelize
<console>:21: error: missing arguments for method parallelize in class SparkContext;
follow this method with `_' if you want to treat it as a partially applied function
val numbers = sc.parallelize
^
scala> val numbers = sc.parallelize(1 to 100)
numbers: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:21
scala> numbers.reduce(_+_)

took 11.790246 s
res1: Int = 5050
可见,reduce是个action。
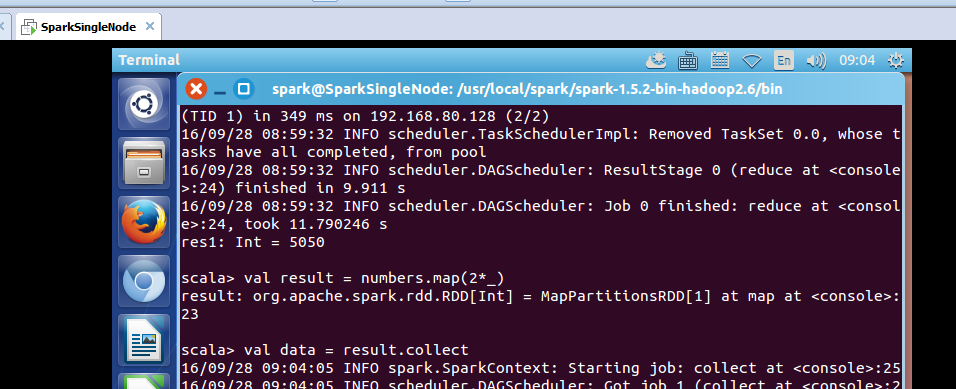
scala> val result = numbers.map(2*_)
result: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:23
scala> val data = result.collect
reduce源码
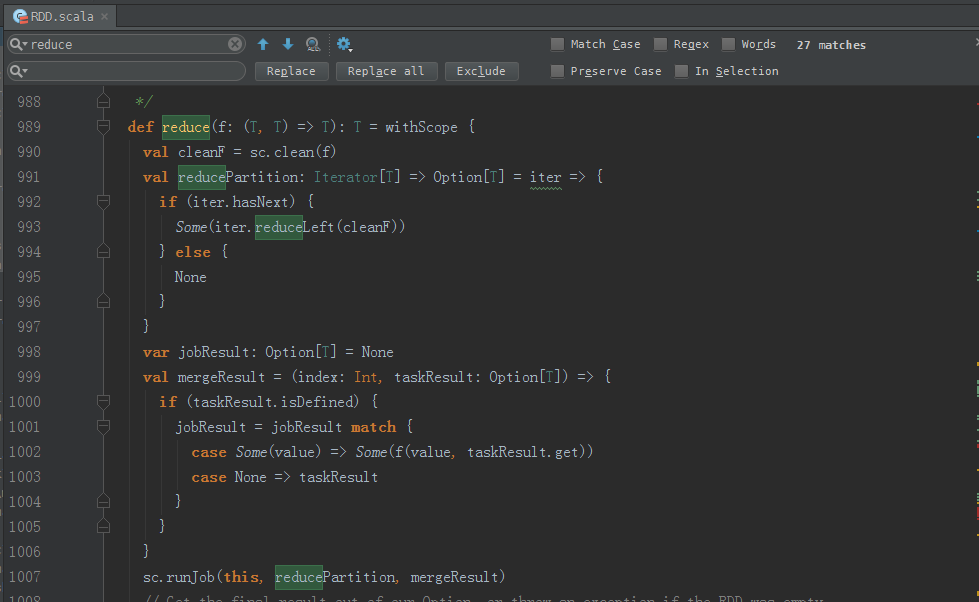
/**
* Reduces the elements of this RDD using the specified commutative and
* associative binary operator.
*/
def reduce(f: (T, T) => T): T = withScope {
val cleanF = sc.clean(f)
val reducePartition: Iterator[T] => Option[T] = iter => {
if (iter.hasNext) {
Some(iter.reduceLeft(cleanF))
} else {
None
}
}
var jobResult: Option[T] = None
val mergeResult = (index: Int, taskResult: Option[T]) => {
if (taskResult.isDefined) {
jobResult = jobResult match {
case Some(value) => Some(f(value, taskResult.get))
case None => taskResult
}
}
}
sc.runJob(this, reducePartition, mergeResult)
// Get the final result out of our Option, or throw an exception if the RDD was empty
jobResult.getOrElse(throw new UnsupportedOperationException("empty collection"))
}
可见,这也是一个action操作。
collect
data: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80, 82, 84, 86, 88, 90, 92, 94, 96, 98, 100, 102, 104, 106, 108, 110, 112, 114, 116, 118, 120, 122, 124, 126, 128, 130, 132, 134, 136, 138, 140, 142, 144, 146, 148, 150, 152, 154, 156, 158, 160, 162, 164, 166, 168, 170, 172, 174, 176, 178, 180, 182, 184, 186, 188, 190, 192, 194, 196, 198, 200)
scala>
collect源码
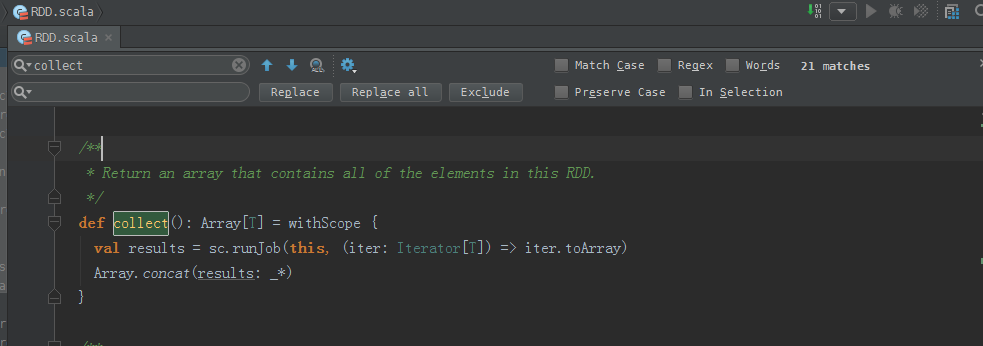
/**
* Return an array that contains all of the elements in this RDD.
*/
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
可见,这也是一个action操作。
从收集结果的角度来说,如果想要在命令行终端中,看到执行结果,就必须collect。
从源码的角度来说,凡是action级别的操作,都会触发sc.rubJob。这点,spark里是一个应用程序允许有多个Job,而hadoop里一个应用程序只能一个Job。
count

scala> numbers
res2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:21
scala> 1 to 100
res3: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100)
scala> numbers.count
took 0.649005 s
res4: Long = 100
count源码
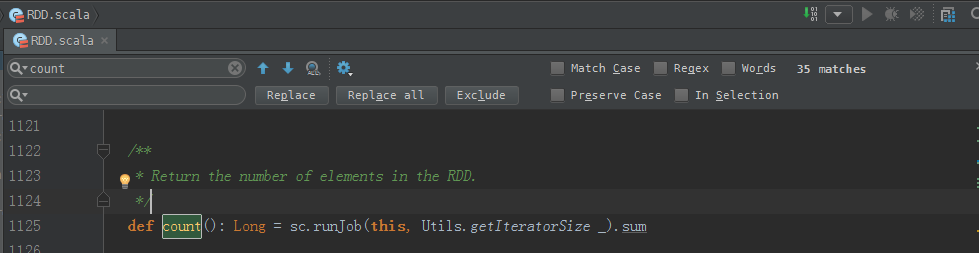
/**
* Return the number of elements in the RDD.
*/
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
可见,这也是一个action操作。
take
scala> val topN = numbers.take(5)

topN: Array[Int] = Array(1, 2, 3, 4, 5)
take源码
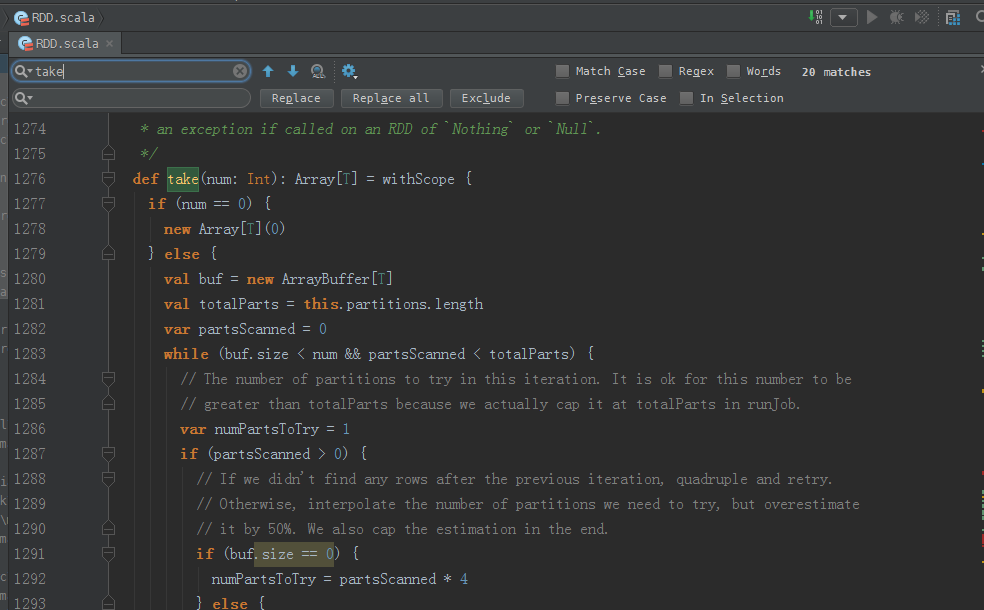
/**
* Take the first num elements of the RDD. It works by first scanning one partition, and use the
* results from that partition to estimate the number of additional partitions needed to satisfy
* the limit.
*
* @note due to complications in the internal implementation, this method will raise
* an exception if called on an RDD of `Nothing` or `Null`.
*/
def take(num: Int): Array[T] = withScope {
if (num == 0) {
new Array[T](0)
} else {
val buf = new ArrayBuffer[T]
val totalParts = this.partitions.length
var partsScanned = 0
while (buf.size < num && partsScanned < totalParts) {
// The number of partitions to try in this iteration. It is ok for this number to be
// greater than totalParts because we actually cap it at totalParts in runJob.
var numPartsToTry = 1
if (partsScanned > 0) {
// If we didn't find any rows after the previous iteration, quadruple and retry.
// Otherwise, interpolate the number of partitions we need to try, but overestimate
// it by 50%. We also cap the estimation in the end.
if (buf.size == 0) {
numPartsToTry = partsScanned * 4
} else {
// the left side of max is >=1 whenever partsScanned >= 2
numPartsToTry = Math.max((1.5 * num * partsScanned / buf.size).toInt - partsScanned, 1)
numPartsToTry = Math.min(numPartsToTry, partsScanned * 4)
}
} val left = num - buf.size
val p = partsScanned until math.min(partsScanned + numPartsToTry, totalParts)
val res = sc.runJob(this, (it: Iterator[T]) => it.take(left).toArray, p) res.foreach(buf ++= _.take(num - buf.size))
partsScanned += numPartsToTry
} buf.toArray
}
}
可见,这也是一个action操作。
countByKey
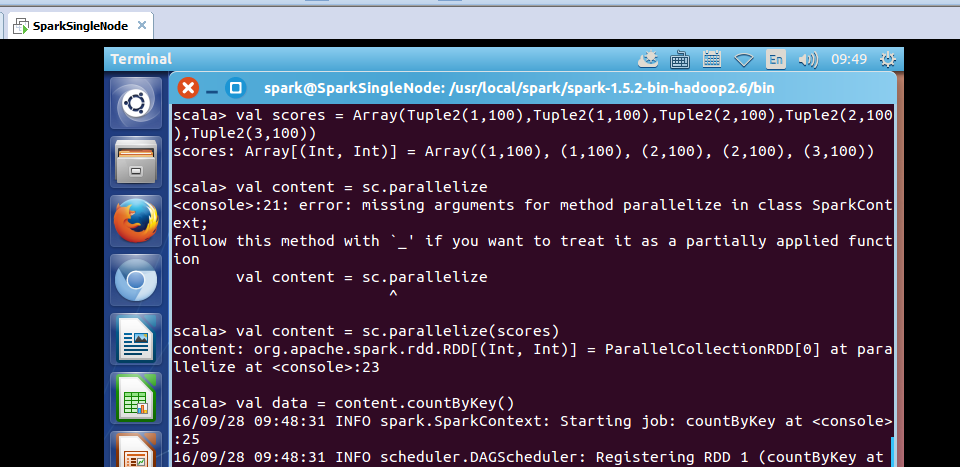
scala> val scores = Array(Tuple2(1,100),Tuple2(1,100),Tuple2(2,100),Tuple2(2,100),Tuple2(3,100))
scores: Array[(Int, Int)] = Array((1,100), (1,100), (2,100), (2,100), (3,100))
scala> val content = sc.parallelize
<console>:21: error: missing arguments for method parallelize in class SparkContext;
follow this method with `_' if you want to treat it as a partially applied function
val content = sc.parallelize
^
scala> val content = sc.parallelize(scores)
content: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:23
scala> val data = content.countByKey()
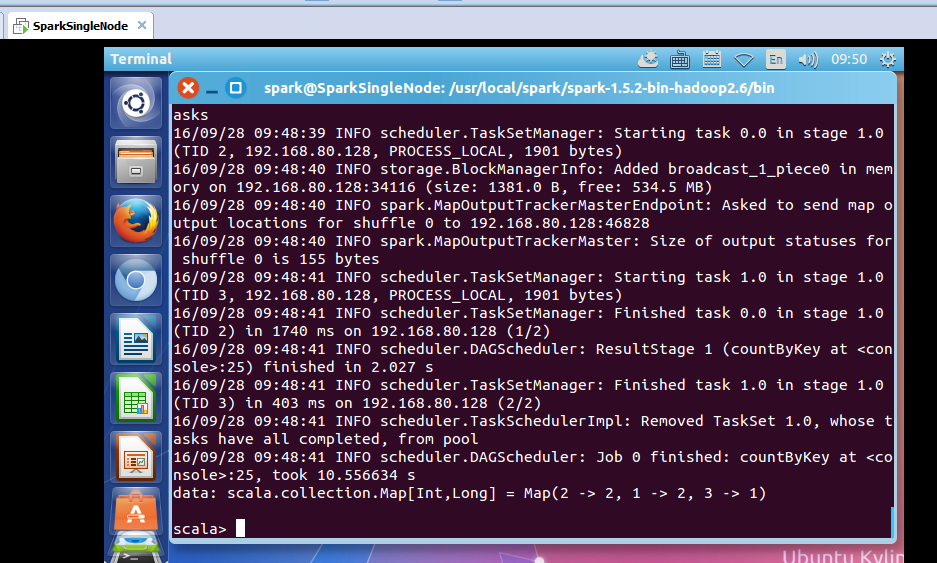
took 10.556634 s
data: scala.collection.Map[Int,Long] = Map(2 -> 2, 1 -> 2, 3 -> 1)
countByKey源码
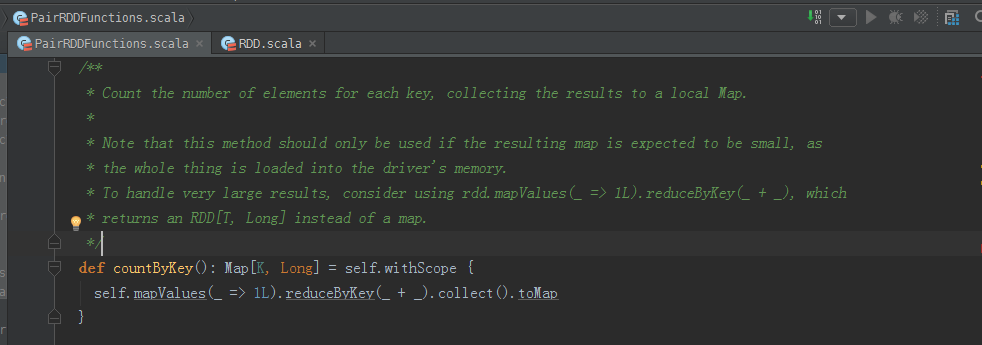
/**
* Count the number of elements for each key, collecting the results to a local Map.
*
* Note that this method should only be used if the resulting map is expected to be small, as
* the whole thing is loaded into the driver's memory.
* To handle very large results, consider using rdd.mapValues(_ => 1L).reduceByKey(_ + _), which
* returns an RDD[T, Long] instead of a map.
*/
def countByKey(): Map[K, Long] = self.withScope {
self.mapValues(_ => 1L).reduceByKey(_ + _).collect().toMap
} 可见,这也是一个action操作。
saveAsTextFile
之前,在 rdd实战(rdd基本操作实战及transformation和action流程图)(源码)
scala> val partitionsReadmeRdd = sc.textFile("hdfs://SparkSingleNode:9000/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).saveAsTextFile("~/partition1README.txt")
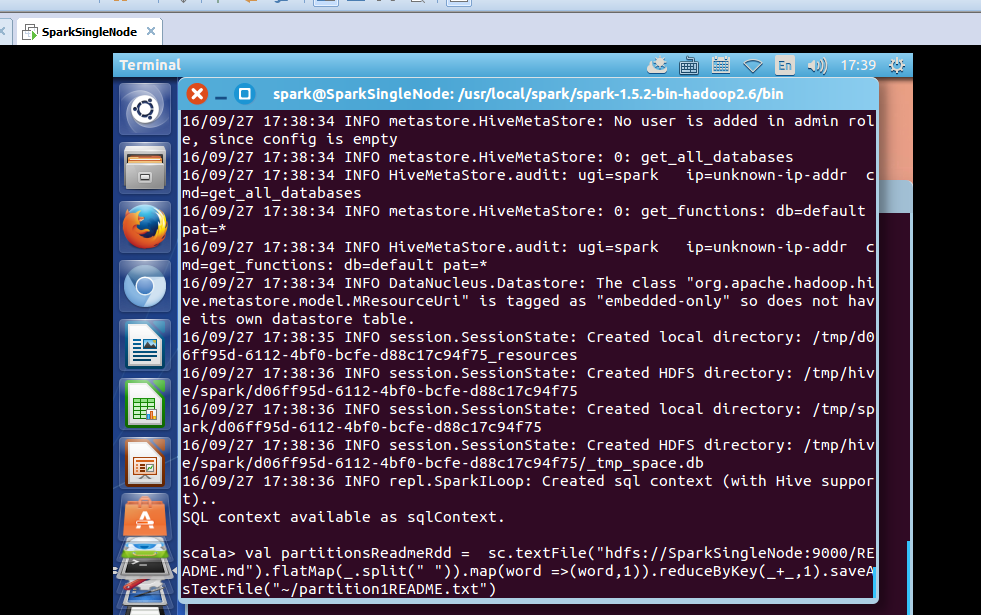
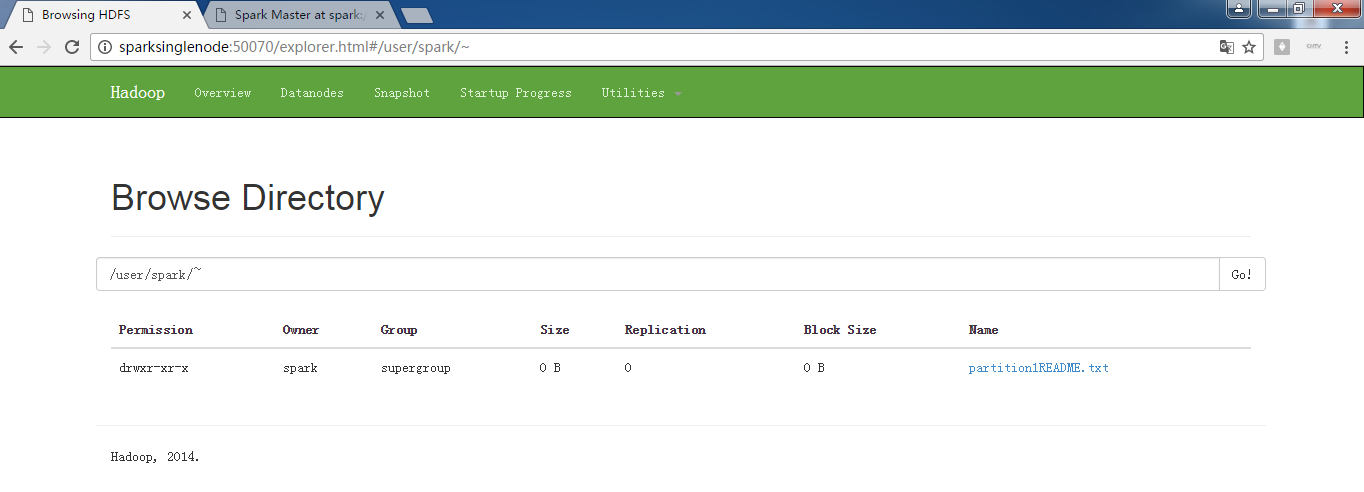
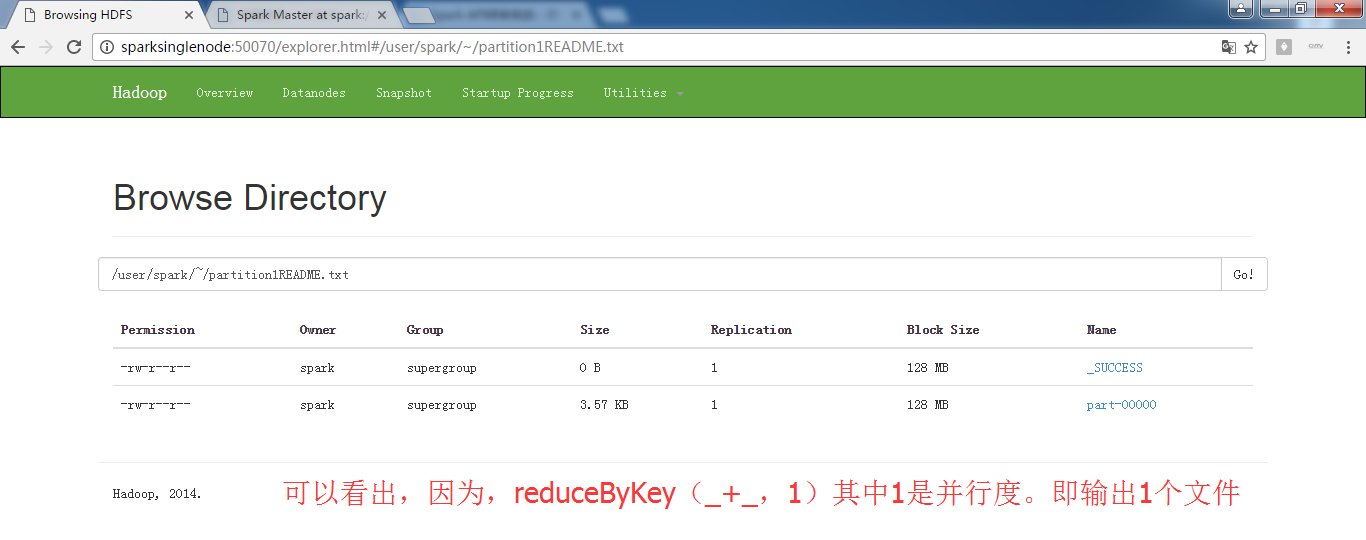
这里呢。
scala> val partitionsReadmeRdd = sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).saveAsTextFile("/partition1README.txt")

scala> val partitionsReadmeRdd = sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).saveAsTextFile("/partition1README.txt")
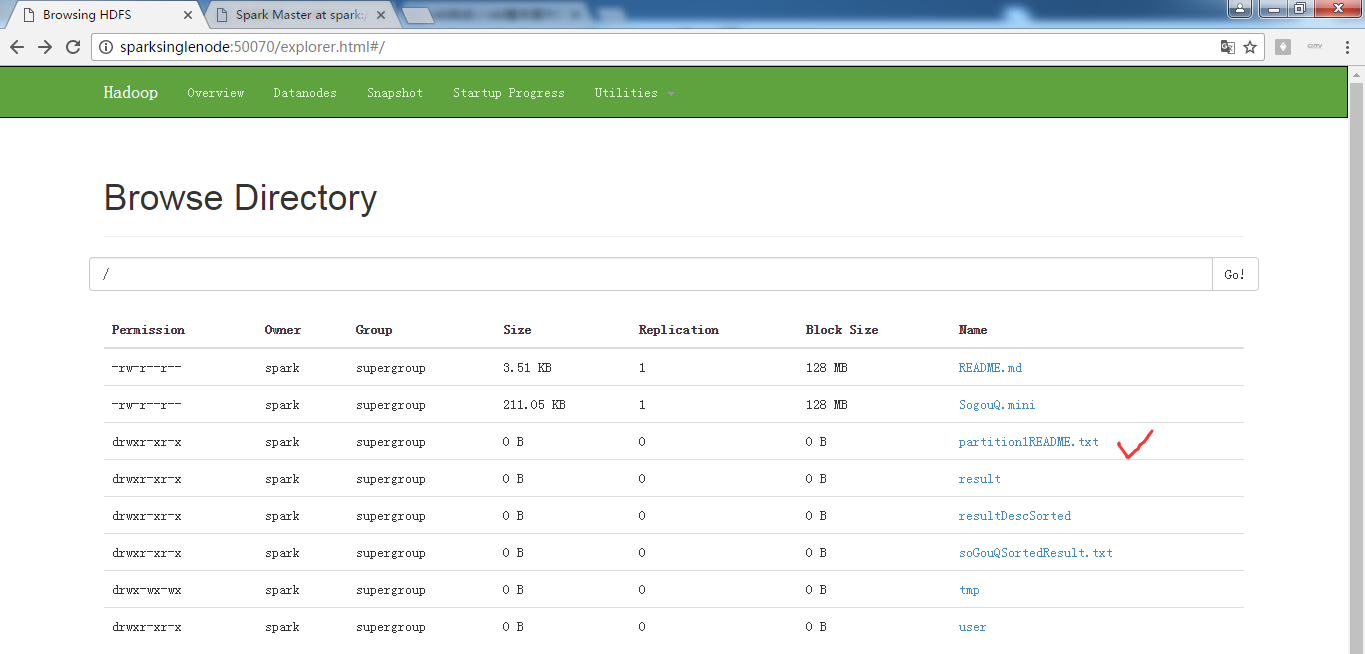
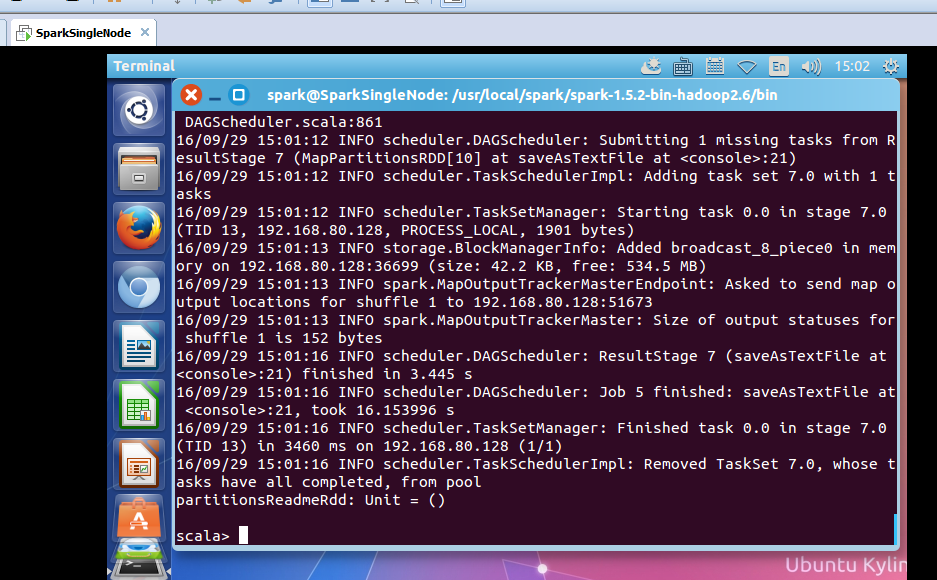
saveAsTextFile源码

/**
* Save this RDD as a text file, using string representations of elements.
*/
def saveAsTextFile(path: String): Unit = withScope {
// https://issues.apache.org/jira/browse/SPARK-2075
//
// NullWritable is a `Comparable` in Hadoop 1.+, so the compiler cannot find an implicit
// Ordering for it and will use the default `null`. However, it's a `Comparable[NullWritable]`
// in Hadoop 2.+, so the compiler will call the implicit `Ordering.ordered` method to create an
// Ordering for `NullWritable`. That's why the compiler will generate different anonymous
// classes for `saveAsTextFile` in Hadoop 1.+ and Hadoop 2.+.
//
// Therefore, here we provide an explicit Ordering `null` to make sure the compiler generate
// same bytecodes for `saveAsTextFile`.
val nullWritableClassTag = implicitly[ClassTag[NullWritable]]
val textClassTag = implicitly[ClassTag[Text]]
val r = this.mapPartitions { iter =>
val text = new Text()
iter.map { x =>
text.set(x.toString)
(NullWritable.get(), text)
}
}
RDD.rddToPairRDDFunctions(r)(nullWritableClassTag, textClassTag, null)
.saveAsHadoopFile[TextOutputFormat[NullWritable, Text]](path)
} /**
* Save this RDD as a compressed text file, using string representations of elements.
*/
def saveAsTextFile(path: String, codec: Class[_ <: CompressionCodec]): Unit = withScope {
// https://issues.apache.org/jira/browse/SPARK-2075
val nullWritableClassTag = implicitly[ClassTag[NullWritable]]
val textClassTag = implicitly[ClassTag[Text]]
val r = this.mapPartitions { iter =>
val text = new Text()
iter.map { x =>
text.set(x.toString)
(NullWritable.get(), text)
}
}
RDD.rddToPairRDDFunctions(r)(nullWritableClassTag, textClassTag, null)
.saveAsHadoopFile[TextOutputFormat[NullWritable, Text]](path, codec)
}
saveAsTextFile不仅,可保存在集群里,也可以保存到本地,这就要看hadoop的运行模式。
由此可见,它也是个action操作。
以上是rdd持久化的第一个方面,就是action级别的操作。
rdd持久化的第二个方面,就是通过persist。
为什么在spark里,随处可见persist的身影呢?
原因一:spark在默认情况下,数据是放在内存中,适合高速迭代。比如在一个stage里,有1000个步骤,它其实只在第1个步骤输入数据,在第1000个步骤输出数据,在中间不产生临时数据。但是,分布式系统,分享非常高,所以,容出错,设计到容错。 由于,rdd是有血统继承关系的,即lineager。如果后面的rdd数据分片出错了或rdd本身出错了,则,可根据其前面依赖的lineager,算出来。
但是,假设1000个步骤,如果之前,没有父rdd进行persist或cache的话,则要重头开始了。亲! 什么时候,该persist?
1、在某个步骤非常费时的情况下,不好使 (手动)
2、计算链条特别长的情况下 (手动)
3、checkpoint所在的rdd也一定要持久化数据 (注意:在checkpoint之前,进行persist) (手动)
checkpoint是rdd的算子,
先写,某个具体rdd.checkpoint 或 某个具体rdd.cache ,再写, 某个具体rdd.persist
4、shuffle之后 (因为shuffle之后,要网络传输,风险大) (手动)
5、shuffle之前 (框架,默认给我们做的,把数据持久化到本地磁盘)
checkpoint源码

/**
* Mark this RDD for checkpointing. It will be saved to a file inside the checkpoint
* directory set with `SparkContext#setCheckpointDir` and all references to its parent
* RDDs will be removed. This function must be called before any job has been
* executed on this RDD. It is strongly recommended that this RDD is persisted in
* memory, otherwise saving it on a file will require recomputation.
*/
def checkpoint(): Unit = RDDCheckpointData.synchronized {
// NOTE: we use a global lock here due to complexities downstream with ensuring
// children RDD partitions point to the correct parent partitions. In the future
// we should revisit this consideration.
if (context.checkpointDir.isEmpty) {
throw new SparkException("Checkpoint directory has not been set in the SparkContext")
} else if (checkpointData.isEmpty) {
checkpointData = Some(new ReliableRDDCheckpointData(this))
}
}
persist源码
/**
* Mark this RDD for persisting using the specified level.
*
* @param newLevel the target storage level
* @param allowOverride whether to override any existing level with the new one
*/
private def persist(newLevel: StorageLevel, allowOverride: Boolean): this.type = {
// TODO: Handle changes of StorageLevel
if (storageLevel != StorageLevel.NONE && newLevel != storageLevel && !allowOverride) {
throw new UnsupportedOperationException(
"Cannot change storage level of an RDD after it was already assigned a level")
}
// If this is the first time this RDD is marked for persisting, register it
// with the SparkContext for cleanups and accounting. Do this only once.
if (storageLevel == StorageLevel.NONE) {
sc.cleaner.foreach(_.registerRDDForCleanup(this))
sc.persistRDD(this)
}
storageLevel = newLevel
this
} /**
* Set this RDD's storage level to persist its values across operations after the first time
* it is computed. This can only be used to assign a new storage level if the RDD does not
* have a storage level set yet. Local checkpointing is an exception.
*/
def persist(newLevel: StorageLevel): this.type = {
if (isLocallyCheckpointed) {
// This means the user previously called localCheckpoint(), which should have already
// marked this RDD for persisting. Here we should override the old storage level with
// one that is explicitly requested by the user (after adapting it to use disk).
persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true)
} else {
persist(newLevel, allowOverride = false)
}
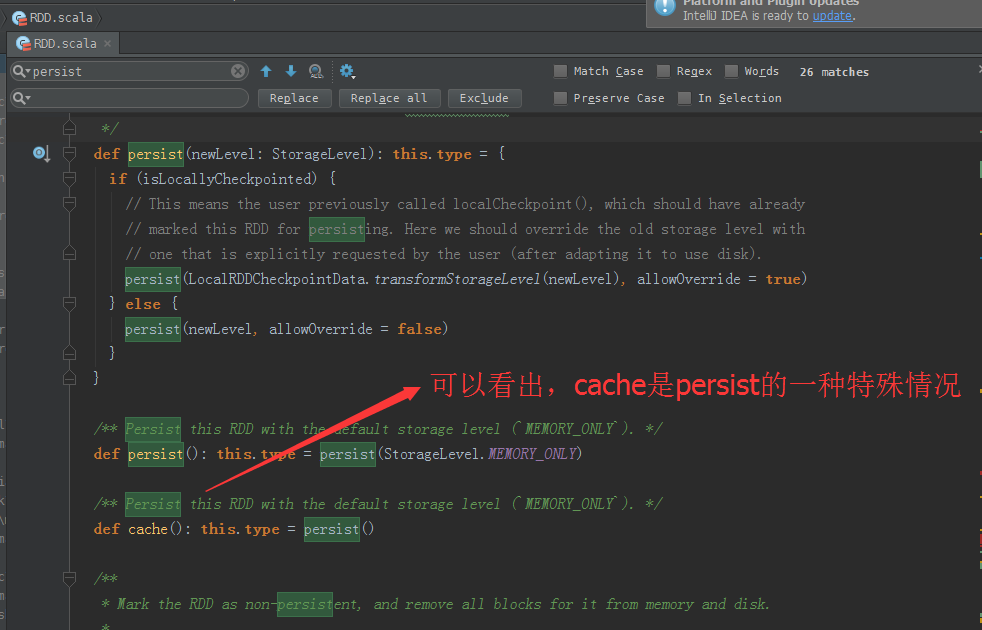
} /** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY) /** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def cache(): this.type = persist()
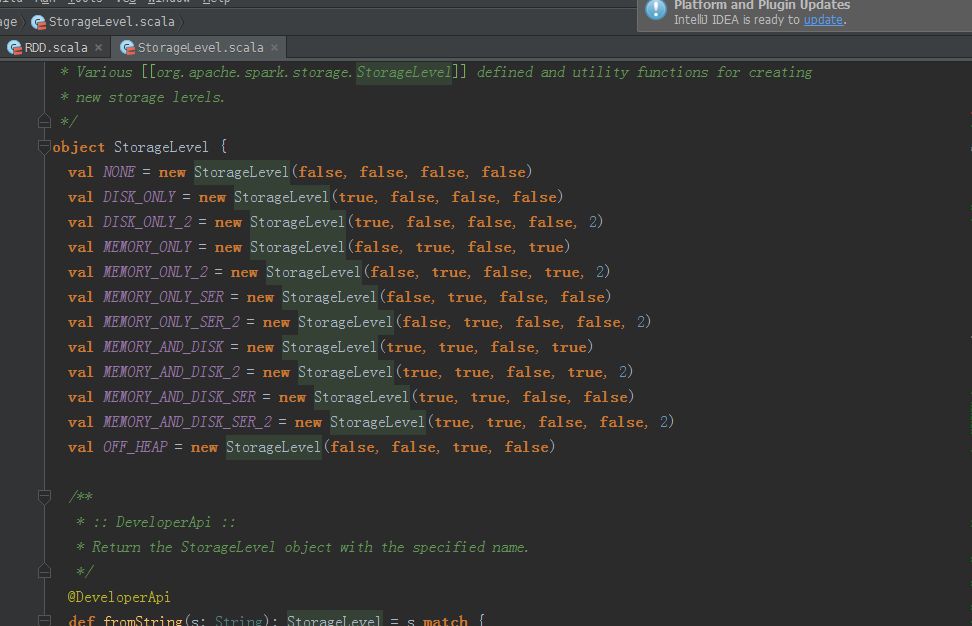
StorageLevel里有很多类型
这里,牵扯到序列化。
问,为什么要序列化?
答:节省空间,减少体积。内存不够时,把MEMORY中的数据,进行序列化。
当然,也有不好一面,序列化时,会反序列化,反序列化耗cpu。
MEMORY_AND_DISK
假设,我们制定数据存储方式是,MEMORY_AND_DISK。则,是不是同时,存储到内存和磁盘呢?
答:不是啊,亲。spark一定是优先考虑内存的啊,只要内存足够,不会考虑磁盘。若内存不够了,则才放部分数据到磁盘。 极大地减少数据丢失概率发生。
MEMORY_ONLY
假设,我们制定数据存储方式是,MEMORY_ONLY。则,只放到内存。当内存不够了,会出现OOM。或数据丢失。
OFF_HEAP
这牵扯到Tachyon,基于内存的分布式系统
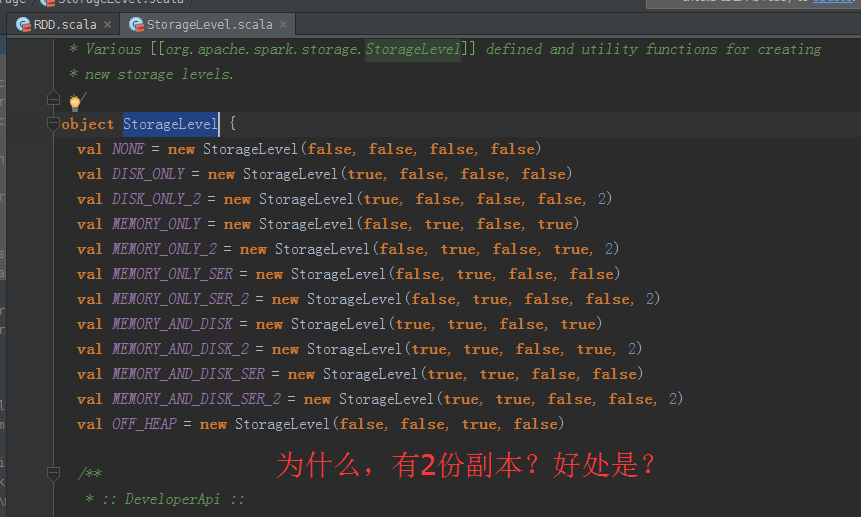
为什么有2分副本?好处是?
假设,一个计算特别耗时,而且,又是基于内存,如果其中一份副本崩溃掉,则可迅速切换到另一份副本去计算。这就是“空间换时间”!非常重要
这不是并行计算,这是计算后的结果,放2份副本。
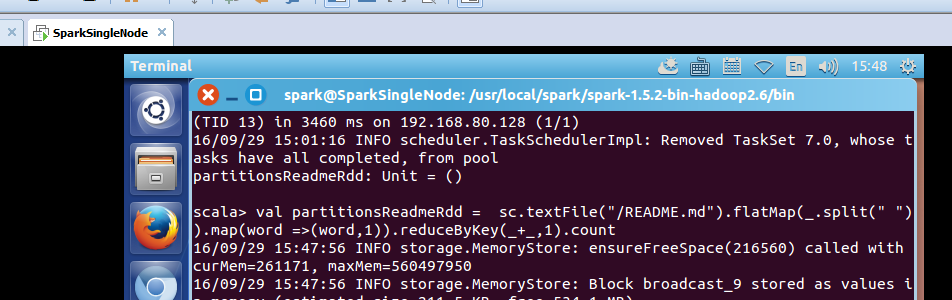
scala> val partitionsReadmeRdd = sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).count
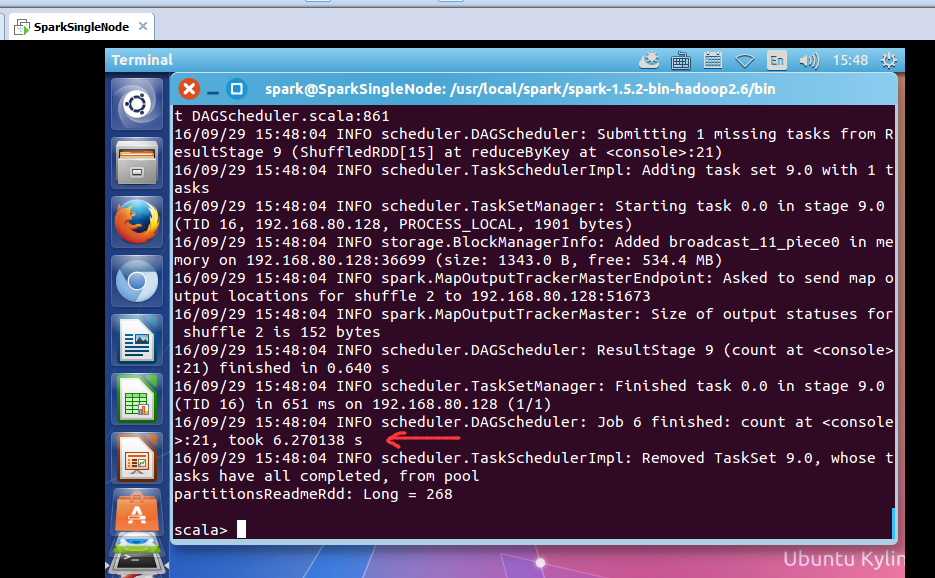
took 6.270138 s
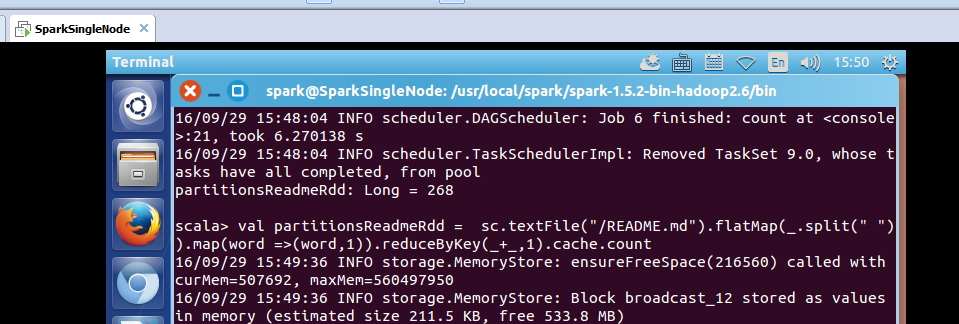
scala> val partitionsReadmeRdd = sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).cache.count

took 4.147545 s

scala> val partitionsReadmeRdd = sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).cache.count
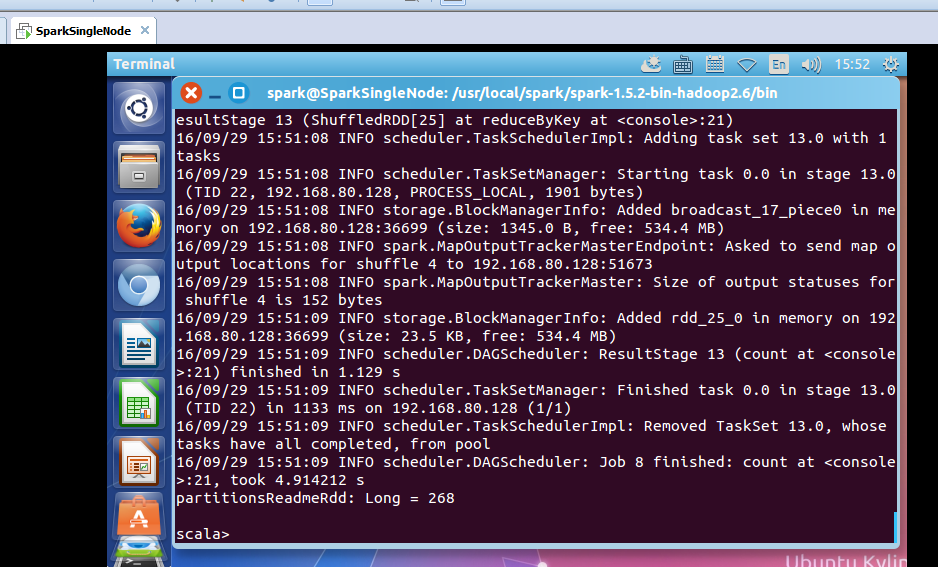
took 4.914212 s

scala> val cacheRdd = sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).cache
scala> cacheRdd.count
took 3.371621
scala> val cacheRdd = sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).cache
scala> cacheRdd.count

took 0.943499 s
我的天啊!

scala> sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).cache.count
took 5.603903
scala> sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).cache.count
took 4.146627
scala> sc.textFile("/README.md").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_,1).cache.count
took 3.071122
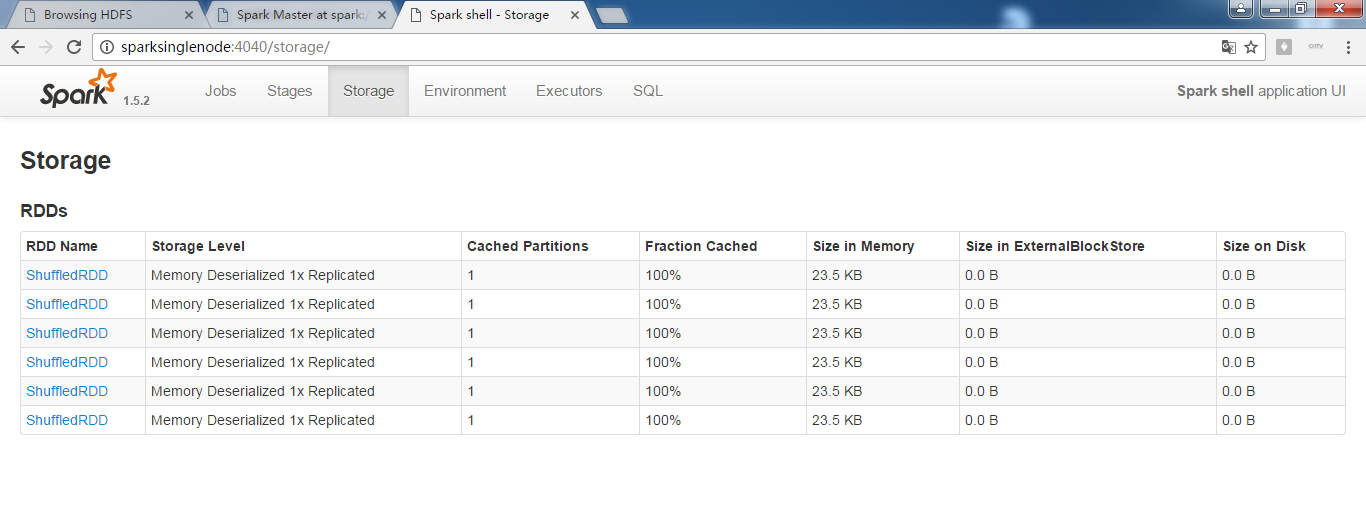
cache之后,一定不能立即有其他算子!
实际工程中, cache之后,如果有其他算子,则会,重新触发这个工作过程。
注意:cache,不是action

cache缓存,怎么让它失效?
答:unpersist
persist是lazy级别的,unpersist是eager级别的。cache是persist的一个特殊情况。
cache和persist的区别?
答:persist可以放到磁盘、放到内存、同时放到内存和磁盘。以及多份副本
cache只能放到内存,以及只能一份副本。
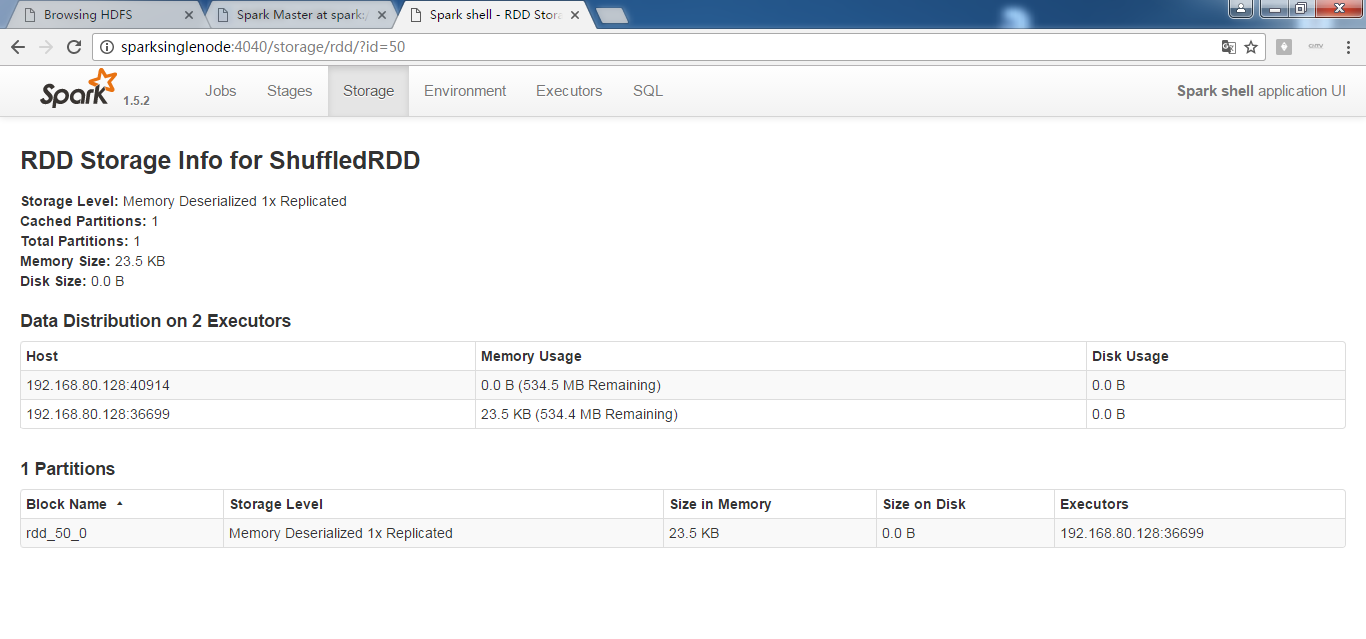
persisit在内存不够时,保存在磁盘的哪个目录?
答:local的process。
好的,以上是,rdd持久化的两个方面。
rdd持久化的第一个方面,就是常用的action级别的操作。
rdd持久化的第二个方面,就是持久化的不同方式,以及它内部的运行情况
小知识:cache之后,一定不能立即有其他算子!实际工程中, cache之后,如果有其他算子,则会,重新触发这个工作过程。
一般都不会跨机器抓内存,宁愿排队。宁愿数据不动代码动。
2、广播
为什么要有,rdd广播?
答:大变量、join、冗余、减少数据移动、通信、状态、集群消息、共享、网络传输慢要提前、数据量大耗网络、减少通信、要同步。
为什么大变量,需要广播呢?
答:原因是,每个task运行,读取全集数据时,task本身执行时,每次都要拷贝一份数据副本,如果变量比较大,如一百万,则要拷贝一百万。
广播变量允许程序员将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量可被用于有效地给每个节点一个大输入数据集的副本。Spark还尝试使用高效地广播算法来分发变量,进而减少通信的开销。
Spark的动作通过一系列的步骤执行,这些步骤由分布式的洗牌操作分开。Spark自动地广播每个步骤每个任务需要的通用数据。这些广播数据被序列化地缓存,在运行任务之前被反序列化出来。这意味着当我们需要在多个阶段的任务之间使用相同的数据,或者以反序列化形式缓存数据是十分重要的时候,显式地创建广播变量才有用。
(本段摘自:http://blog.csdn.net/happyanger6/article/details/46576831)
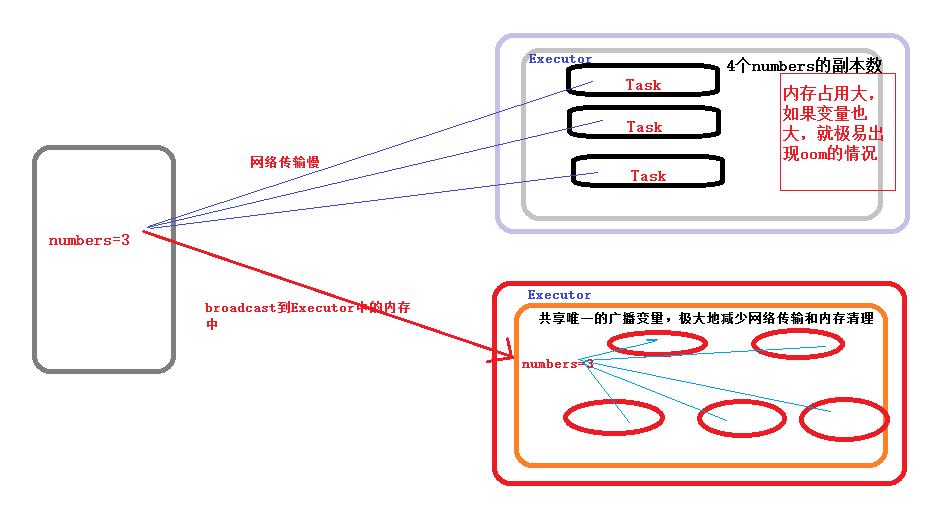
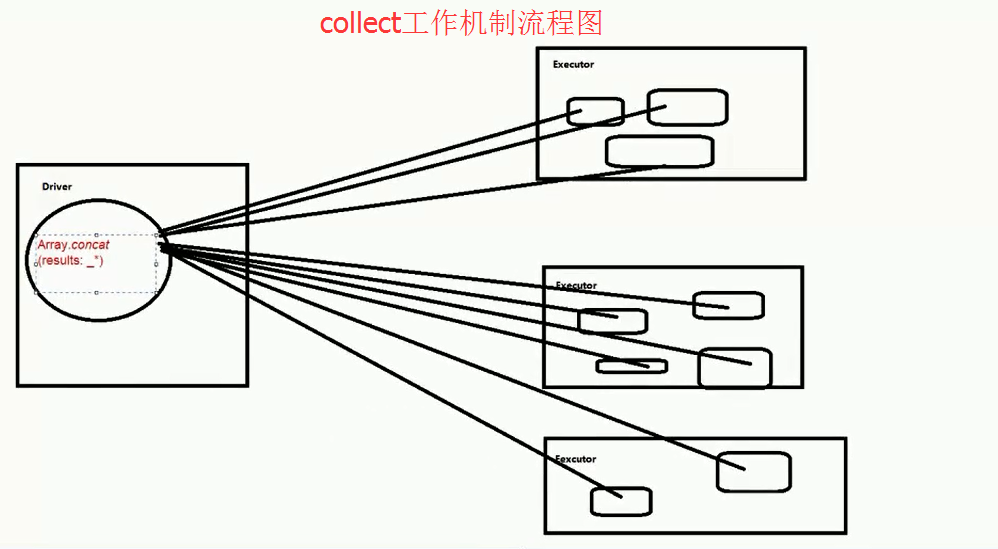
广播工作机制图
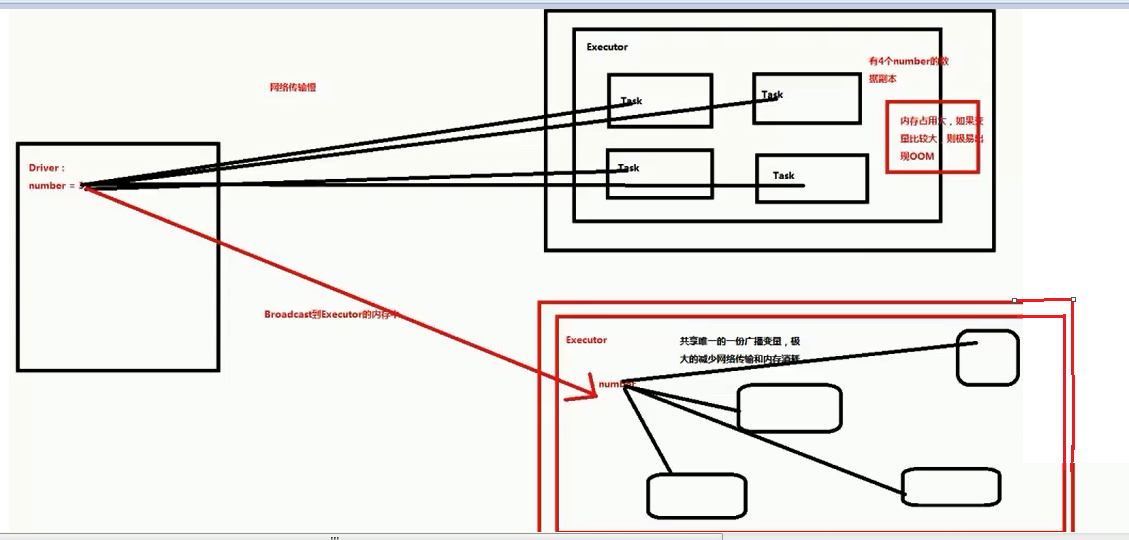
广播工作机制图
参考: http://blog.csdn.net/kxr0502/article/details/50574561
问:读广播,会消耗网络传输吗?
答:不消耗,广播是放在内存中。读取它,不消耗。
问:广播变量是不是就是向每一个executor,广播一份数据,而不是向每一个task,广播一份数据?这样对吗?
答:对
广播是由Driver发给当前Application分配的所有Executor内存级别的全局只读变量,Executor中的线程池中的线程共享该全局变量,极大的减少了网络传输(否则的话每个Task都要传输一次该变量)并极大的节省了内存,当然也隐形的提高的CPU的有效工作。
实战创建广播:

scala> val number = 10
number: Int = 10
scala> val broadcastNumber = sc.broadcast(number)
16/09/29 17:26:47 INFO storage.MemoryStore: ensureFreeSpace(40) called with curMem=1782734, maxMem=560497950
16/09/29 17:26:47 INFO storage.MemoryStore: Block broadcast_38 stored as values in memory (estimated size 40.0 B, free 532.8 MB)
16/09/29 17:26:48 INFO storage.MemoryStore: ensureFreeSpace(97) called with curMem=1782774, maxMem=560497950
16/09/29 17:26:48 INFO storage.MemoryStore: Block broadcast_38_piece0 stored as bytes in memory (estimated size 97.0 B, free 532.8 MB)
16/09/29 17:26:48 INFO storage.BlockManagerInfo: Added broadcast_38_piece0 in memory on 192.168.80.128:40914 (size: 97.0 B, free: 534.4 MB)
16/09/29 17:26:48 INFO spark.SparkContext: Created broadcast 38 from broadcast at <console>:23
broadcastNumber: org.apache.spark.broadcast.Broadcast[Int] = Broadcast(38)

scala> val data = sc.parallelize
<console>:21: error: missing arguments for method parallelize in class SparkContext;
follow this method with `_' if you want to treat it as a partially applied function
val data = sc.parallelize
^
scala> val data = sc.parallelize(1 to 100)
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[61] at parallelize at <console>:21
scala> val bn = data.map(_* broadcastNumber.value)
bn: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[62] at map at <console>:27
scala>
我们知道,是test是要广播变量,但,我们编程,对rdd。
//通过在一个变量v上调用SparkContext.broadcast(v)可以创建广播变量。广播变量是围绕着v的封装,可以通过value方法访问这个变量。
问:广播变量里有很多变量吗?
答:当然可以有很多,用java bin或scala封装,就可以了。
如,在这里。广播变量是,broadcastNumber, 里,有变量value等。
scala> val broadcastNumber = sc.broadcast(number)
scala> val bn = data.map(_* broadcastNumber.value)
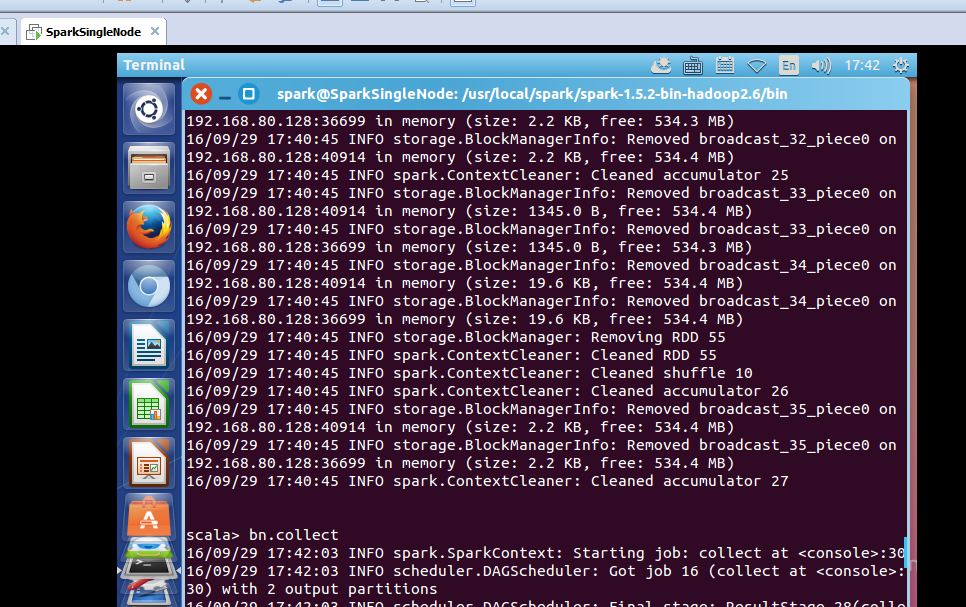
scala> bn.collect

res12: Array[Int] = Array(10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, 200, 210, 220, 230, 240, 250, 260, 270, 280, 290, 300, 310, 320, 330, 340, 350, 360, 370, 380, 390, 400, 410, 420, 430, 440, 450, 460, 470, 480, 490, 500, 510, 520, 530, 540, 550, 560, 570, 580, 590, 600, 610, 620, 630, 640, 650, 660, 670, 680, 690, 700, 710, 720, 730, 740, 750, 760, 770, 780, 790, 800, 810, 820, 830, 840, 850, 860, 870, 880, 890, 900, 910, 920, 930, 940, 950, 960, 970, 980, 990, 1000)
scala>
由此,可见,通过机制、流程图和实战,深度剖析对广播全面详解!
broadcast源码分析
参考: http://www.cnblogs.com/seaspring/p/5682053.html
BroadcastManager源码
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.spark.broadcast import java.util.concurrent.atomic.AtomicLong import scala.reflect.ClassTag import org.apache.spark._
import org.apache.spark.util.Utils private[spark] class BroadcastManager(
val isDriver: Boolean,
conf: SparkConf,
securityManager: SecurityManager)
extends Logging { private var initialized = false
private var broadcastFactory: BroadcastFactory = null initialize() // Called by SparkContext or Executor before using Broadcast
private def initialize() {
synchronized {
if (!initialized) {
val broadcastFactoryClass =
conf.get("spark.broadcast.factory", "org.apache.spark.broadcast.TorrentBroadcastFactory") broadcastFactory =
Utils.classForName(broadcastFactoryClass).newInstance.asInstanceOf[BroadcastFactory] // Initialize appropriate BroadcastFactory and BroadcastObject
broadcastFactory.initialize(isDriver, conf, securityManager) initialized = true
}
}
} def stop() {
broadcastFactory.stop()
} private val nextBroadcastId = new AtomicLong(0) def newBroadcast[T: ClassTag](value_ : T, isLocal: Boolean): Broadcast[T] = {
broadcastFactory.newBroadcast[T](value_, isLocal, nextBroadcastId.getAndIncrement())
} def unbroadcast(id: Long, removeFromDriver: Boolean, blocking: Boolean) {
broadcastFactory.unbroadcast(id, removeFromDriver, blocking)
}
}
Broadcast源码
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.spark.broadcast import java.io.Serializable import org.apache.spark.SparkException
import org.apache.spark.Logging
import org.apache.spark.util.Utils import scala.reflect.ClassTag /**
* A broadcast variable. Broadcast variables allow the programmer to keep a read-only variable
* cached on each machine rather than shipping a copy of it with tasks. They can be used, for
* example, to give every node a copy of a large input dataset in an efficient manner. Spark also
* attempts to distribute broadcast variables using efficient broadcast algorithms to reduce
* communication cost.
*
* Broadcast variables are created from a variable `v` by calling
* [[org.apache.spark.SparkContext#broadcast]].
* The broadcast variable is a wrapper around `v`, and its value can be accessed by calling the
* `value` method. The interpreter session below shows this:
*
* {{{
* scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
* broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
*
* scala> broadcastVar.value
* res0: Array[Int] = Array(1, 2, 3)
* }}}
*
* After the broadcast variable is created, it should be used instead of the value `v` in any
* functions run on the cluster so that `v` is not shipped to the nodes more than once.
* In addition, the object `v` should not be modified after it is broadcast in order to ensure
* that all nodes get the same value of the broadcast variable (e.g. if the variable is shipped
* to a new node later).
*
* @param id A unique identifier for the broadcast variable.
* @tparam T Type of the data contained in the broadcast variable.
*/
abstract class Broadcast[T: ClassTag](val id: Long) extends Serializable with Logging { /**
* Flag signifying whether the broadcast variable is valid
* (that is, not already destroyed) or not.
*/
@volatile private var _isValid = true private var _destroySite = "" /** Get the broadcasted value. */
def value: T = {
assertValid()
getValue()
} /**
* Asynchronously delete cached copies of this broadcast on the executors.
* If the broadcast is used after this is called, it will need to be re-sent to each executor.
*/
def unpersist() {
unpersist(blocking = false)
} /**
* Delete cached copies of this broadcast on the executors. If the broadcast is used after
* this is called, it will need to be re-sent to each executor.
* @param blocking Whether to block until unpersisting has completed
*/
def unpersist(blocking: Boolean) {
assertValid()
doUnpersist(blocking)
} /**
* Destroy all data and metadata related to this broadcast variable. Use this with caution;
* once a broadcast variable has been destroyed, it cannot be used again.
* This method blocks until destroy has completed
*/
def destroy() {
destroy(blocking = true)
} /**
* Destroy all data and metadata related to this broadcast variable. Use this with caution;
* once a broadcast variable has been destroyed, it cannot be used again.
* @param blocking Whether to block until destroy has completed
*/
private[spark] def destroy(blocking: Boolean) {
assertValid()
_isValid = false
_destroySite = Utils.getCallSite().shortForm
logInfo("Destroying %s (from %s)".format(toString, _destroySite))
doDestroy(blocking)
} /**
* Whether this Broadcast is actually usable. This should be false once persisted state is
* removed from the driver.
*/
private[spark] def isValid: Boolean = {
_isValid
} /**
* Actually get the broadcasted value. Concrete implementations of Broadcast class must
* define their own way to get the value.
*/
protected def getValue(): T /**
* Actually unpersist the broadcasted value on the executors. Concrete implementations of
* Broadcast class must define their own logic to unpersist their own data.
*/
protected def doUnpersist(blocking: Boolean) /**
* Actually destroy all data and metadata related to this broadcast variable.
* Implementation of Broadcast class must define their own logic to destroy their own
* state.
*/
protected def doDestroy(blocking: Boolean) /** Check if this broadcast is valid. If not valid, exception is thrown. */
protected def assertValid() {
if (!_isValid) {
throw new SparkException(
"Attempted to use %s after it was destroyed (%s) ".format(toString, _destroySite))
}
} override def toString: String = "Broadcast(" + id + ")"
}
其他的,不一一赘述了。
3、累加器
为什么需要,累加器?
答:第一种情况,是,test把数据副本运行起来。
第二种情况,有全局变量和局部变量,有了广播,为什么还需要累加器?
累加器是仅仅被相关操作累加的变量,因此可以在并行中被有效地支持。它可以被用来实现计数器和总和。Spark原生地只支持数字类型的累加器,编程者可以添加新类型的支持。如果创建累加器时指定了名字,可以在Spark的UI界面看到。这有利于理解每个执行阶段的进程。(对于python还不支持)
累加器通过对一个初始化了的变量v调用SparkContext.accumulator(v)来创建。在集群上运行的任务可以通过add或者"+="方法在累加器上进行累加操作。但是,它们不能读取它的值。只有驱动程序能够读取它的值,通过累加器的value方法。
累加器的特征:全局的,Accumulator:对于Executor只能修改但不可读,只对Driver可读(因为通过Driver控制整个集群的状态),不同的executor 修改,不会彼此覆盖(枷锁机制)
累加器实战:
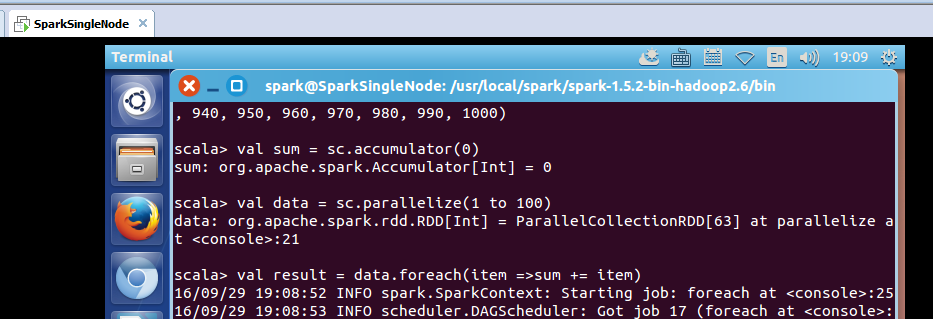
scala> val sum = sc.accumulator(0)
sum: org.apache.spark.Accumulator[Int] = 0
scala> val data = sc.parallelize(1 to 100)
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[63] at parallelize at <console>:21
scala> val result = data.foreach(item =>sum += item)
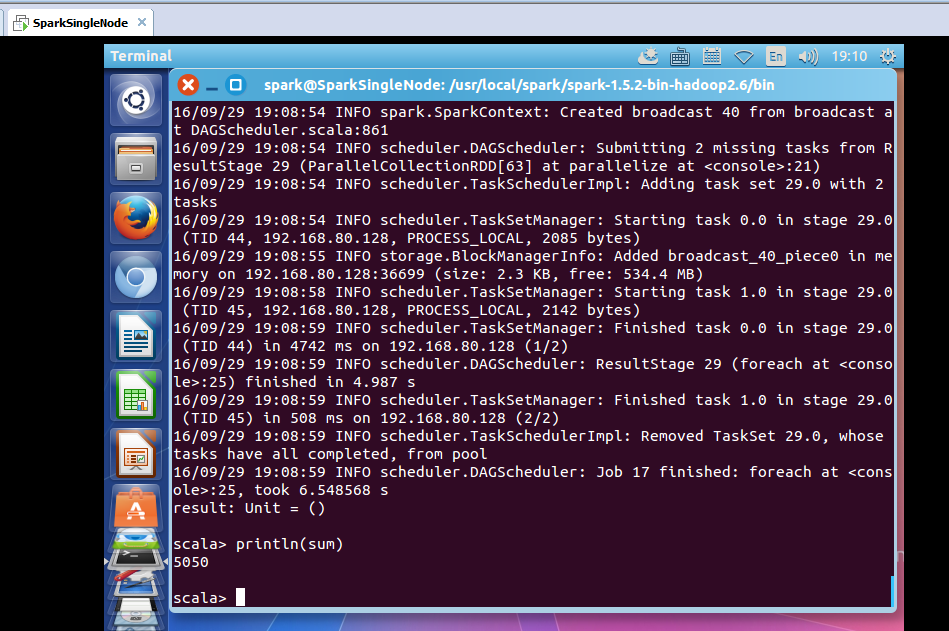
took 6.548568 s
result: Unit = ()
scala> println(sum)
5050
1、累计器全局(全集群)唯一,只增不减(Executor中的task去修改,即累加);2、累加器是Executor共享;
accumulator源码
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.spark import java.io.{ObjectInputStream, Serializable} import scala.collection.generic.Growable
import scala.collection.Map
import scala.collection.mutable
import scala.ref.WeakReference
import scala.reflect.ClassTag import org.apache.spark.serializer.JavaSerializer
import org.apache.spark.util.Utils /**
* A data type that can be accumulated, ie has an commutative and associative "add" operation,
* but where the result type, `R`, may be different from the element type being added, `T`.
*
* You must define how to add data, and how to merge two of these together. For some data types,
* such as a counter, these might be the same operation. In that case, you can use the simpler
* [[org.apache.spark.Accumulator]]. They won't always be the same, though -- e.g., imagine you are
* accumulating a set. You will add items to the set, and you will union two sets together.
*
* @param initialValue initial value of accumulator
* @param param helper object defining how to add elements of type `R` and `T`
* @param name human-readable name for use in Spark's web UI
* @param internal if this [[Accumulable]] is internal. Internal [[Accumulable]]s will be reported
* to the driver via heartbeats. For internal [[Accumulable]]s, `R` must be
* thread safe so that they can be reported correctly.
* @tparam R the full accumulated data (result type)
* @tparam T partial data that can be added in
*/
class Accumulable[R, T] private[spark] (
@transient initialValue: R,
param: AccumulableParam[R, T],
val name: Option[String],
internal: Boolean)
extends Serializable { private[spark] def this(
@transient initialValue: R, param: AccumulableParam[R, T], internal: Boolean) = {
this(initialValue, param, None, internal)
} def this(@transient initialValue: R, param: AccumulableParam[R, T], name: Option[String]) =
this(initialValue, param, name, false) def this(@transient initialValue: R, param: AccumulableParam[R, T]) =
this(initialValue, param, None) val id: Long = Accumulators.newId @volatile @transient private var value_ : R = initialValue // Current value on master
val zero = param.zero(initialValue) // Zero value to be passed to workers
private var deserialized = false Accumulators.register(this) /**
* If this [[Accumulable]] is internal. Internal [[Accumulable]]s will be reported to the driver
* via heartbeats. For internal [[Accumulable]]s, `R` must be thread safe so that they can be
* reported correctly.
*/
private[spark] def isInternal: Boolean = internal /**
* Add more data to this accumulator / accumulable
* @param term the data to add
*/
def += (term: T) { value_ = param.addAccumulator(value_, term) } /**
* Add more data to this accumulator / accumulable
* @param term the data to add
*/
def add(term: T) { value_ = param.addAccumulator(value_, term) } /**
* Merge two accumulable objects together
*
* Normally, a user will not want to use this version, but will instead call `+=`.
* @param term the other `R` that will get merged with this
*/
def ++= (term: R) { value_ = param.addInPlace(value_, term)} /**
* Merge two accumulable objects together
*
* Normally, a user will not want to use this version, but will instead call `add`.
* @param term the other `R` that will get merged with this
*/
def merge(term: R) { value_ = param.addInPlace(value_, term)} /**
* Access the accumulator's current value; only allowed on master.
*/
def value: R = {
if (!deserialized) {
value_
} else {
throw new UnsupportedOperationException("Can't read accumulator value in task")
}
} /**
* Get the current value of this accumulator from within a task.
*
* This is NOT the global value of the accumulator. To get the global value after a
* completed operation on the dataset, call `value`.
*
* The typical use of this method is to directly mutate the local value, eg., to add
* an element to a Set.
*/
def localValue: R = value_ /**
* Set the accumulator's value; only allowed on master.
*/
def value_= (newValue: R) {
if (!deserialized) {
value_ = newValue
} else {
throw new UnsupportedOperationException("Can't assign accumulator value in task")
}
} /**
* Set the accumulator's value; only allowed on master
*/
def setValue(newValue: R) {
this.value = newValue
} // Called by Java when deserializing an object
private def readObject(in: ObjectInputStream): Unit = Utils.tryOrIOException {
in.defaultReadObject()
value_ = zero
deserialized = true
// Automatically register the accumulator when it is deserialized with the task closure.
//
// Note internal accumulators sent with task are deserialized before the TaskContext is created
// and are registered in the TaskContext constructor. Other internal accumulators, such SQL
// metrics, still need to register here.
val taskContext = TaskContext.get()
if (taskContext != null) {
taskContext.registerAccumulator(this)
}
} override def toString: String = if (value_ == null) "null" else value_.toString
} /**
* Helper object defining how to accumulate values of a particular type. An implicit
* AccumulableParam needs to be available when you create [[Accumulable]]s of a specific type.
*
* @tparam R the full accumulated data (result type)
* @tparam T partial data that can be added in
*/
trait AccumulableParam[R, T] extends Serializable {
/**
* Add additional data to the accumulator value. Is allowed to modify and return `r`
* for efficiency (to avoid allocating objects).
*
* @param r the current value of the accumulator
* @param t the data to be added to the accumulator
* @return the new value of the accumulator
*/
def addAccumulator(r: R, t: T): R /**
* Merge two accumulated values together. Is allowed to modify and return the first value
* for efficiency (to avoid allocating objects).
*
* @param r1 one set of accumulated data
* @param r2 another set of accumulated data
* @return both data sets merged together
*/
def addInPlace(r1: R, r2: R): R /**
* Return the "zero" (identity) value for an accumulator type, given its initial value. For
* example, if R was a vector of N dimensions, this would return a vector of N zeroes.
*/
def zero(initialValue: R): R
} private[spark] class
GrowableAccumulableParam[R <% Growable[T] with TraversableOnce[T] with Serializable: ClassTag, T]
extends AccumulableParam[R, T] { def addAccumulator(growable: R, elem: T): R = {
growable += elem
growable
} def addInPlace(t1: R, t2: R): R = {
t1 ++= t2
t1
} def zero(initialValue: R): R = {
// We need to clone initialValue, but it's hard to specify that R should also be Cloneable.
// Instead we'll serialize it to a buffer and load it back.
val ser = new JavaSerializer(new SparkConf(false)).newInstance()
val copy = ser.deserialize[R](ser.serialize(initialValue))
copy.clear() // In case it contained stuff
copy
}
} /**
* A simpler value of [[Accumulable]] where the result type being accumulated is the same
* as the types of elements being merged, i.e. variables that are only "added" to through an
* associative operation and can therefore be efficiently supported in parallel. They can be used
* to implement counters (as in MapReduce) or sums. Spark natively supports accumulators of numeric
* value types, and programmers can add support for new types.
*
* An accumulator is created from an initial value `v` by calling [[SparkContext#accumulator]].
* Tasks running on the cluster can then add to it using the [[Accumulable#+=]] operator.
* However, they cannot read its value. Only the driver program can read the accumulator's value,
* using its value method.
*
* The interpreter session below shows an accumulator being used to add up the elements of an array:
*
* {{{
* scala> val accum = sc.accumulator(0)
* accum: spark.Accumulator[Int] = 0
*
* scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
* ...
* 10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
*
* scala> accum.value
* res2: Int = 10
* }}}
*
* @param initialValue initial value of accumulator
* @param param helper object defining how to add elements of type `T`
* @tparam T result type
*/
class Accumulator[T] private[spark] (
@transient private[spark] val initialValue: T,
param: AccumulatorParam[T],
name: Option[String],
internal: Boolean)
extends Accumulable[T, T](initialValue, param, name, internal) { def this(initialValue: T, param: AccumulatorParam[T], name: Option[String]) = {
this(initialValue, param, name, false)
} def this(initialValue: T, param: AccumulatorParam[T]) = {
this(initialValue, param, None, false)
}
} /**
* A simpler version of [[org.apache.spark.AccumulableParam]] where the only data type you can add
* in is the same type as the accumulated value. An implicit AccumulatorParam object needs to be
* available when you create Accumulators of a specific type.
*
* @tparam T type of value to accumulate
*/
trait AccumulatorParam[T] extends AccumulableParam[T, T] {
def addAccumulator(t1: T, t2: T): T = {
addInPlace(t1, t2)
}
} object AccumulatorParam { // The following implicit objects were in SparkContext before 1.2 and users had to
// `import SparkContext._` to enable them. Now we move them here to make the compiler find
// them automatically. However, as there are duplicate codes in SparkContext for backward
// compatibility, please update them accordingly if you modify the following implicit objects. implicit object DoubleAccumulatorParam extends AccumulatorParam[Double] {
def addInPlace(t1: Double, t2: Double): Double = t1 + t2
def zero(initialValue: Double): Double = 0.0
} implicit object IntAccumulatorParam extends AccumulatorParam[Int] {
def addInPlace(t1: Int, t2: Int): Int = t1 + t2
def zero(initialValue: Int): Int = 0
} implicit object LongAccumulatorParam extends AccumulatorParam[Long] {
def addInPlace(t1: Long, t2: Long): Long = t1 + t2
def zero(initialValue: Long): Long = 0L
} implicit object FloatAccumulatorParam extends AccumulatorParam[Float] {
def addInPlace(t1: Float, t2: Float): Float = t1 + t2
def zero(initialValue: Float): Float = 0f
} // TODO: Add AccumulatorParams for other types, e.g. lists and strings
} // TODO: The multi-thread support in accumulators is kind of lame; check
// if there's a more intuitive way of doing it right
private[spark] object Accumulators extends Logging {
/**
* This global map holds the original accumulator objects that are created on the driver.
* It keeps weak references to these objects so that accumulators can be garbage-collected
* once the RDDs and user-code that reference them are cleaned up.
*/
val originals = mutable.Map[Long, WeakReference[Accumulable[_, _]]]() private var lastId: Long = 0 def newId(): Long = synchronized {
lastId += 1
lastId
} def register(a: Accumulable[_, _]): Unit = synchronized {
originals(a.id) = new WeakReference[Accumulable[_, _]](a)
} def remove(accId: Long) {
synchronized {
originals.remove(accId)
}
} // Add values to the original accumulators with some given IDs
def add(values: Map[Long, Any]): Unit = synchronized {
for ((id, value) <- values) {
if (originals.contains(id)) {
// Since we are now storing weak references, we must check whether the underlying data
// is valid.
originals(id).get match {
case Some(accum) => accum.asInstanceOf[Accumulable[Any, Any]] ++= value
case None =>
throw new IllegalAccessError("Attempted to access garbage collected Accumulator.")
}
} else {
logWarning(s"Ignoring accumulator update for unknown accumulator id $id")
}
}
} } private[spark] object InternalAccumulator {
val PEAK_EXECUTION_MEMORY = "peakExecutionMemory"
val TEST_ACCUMULATOR = "testAccumulator" // For testing only.
// This needs to be a def since we don't want to reuse the same accumulator across stages.
private def maybeTestAccumulator: Option[Accumulator[Long]] = {
if (sys.props.contains("spark.testing")) {
Some(new Accumulator(
0L, AccumulatorParam.LongAccumulatorParam, Some(TEST_ACCUMULATOR), internal = true))
} else {
None
}
} /**
* Accumulators for tracking internal metrics.
*
* These accumulators are created with the stage such that all tasks in the stage will
* add to the same set of accumulators. We do this to report the distribution of accumulator
* values across all tasks within each stage.
*/
def create(sc: SparkContext): Seq[Accumulator[Long]] = {
val internalAccumulators = Seq(
// Execution memory refers to the memory used by internal data structures created
// during shuffles, aggregations and joins. The value of this accumulator should be
// approximately the sum of the peak sizes across all such data structures created
// in this task. For SQL jobs, this only tracks all unsafe operators and ExternalSort.
new Accumulator(
0L, AccumulatorParam.LongAccumulatorParam, Some(PEAK_EXECUTION_MEMORY), internal = true)
) ++ maybeTestAccumulator.toSeq
internalAccumulators.foreach { accumulator =>
sc.cleaner.foreach(_.registerAccumulatorForCleanup(accumulator))
}
internalAccumulators
}
}
参考
DT大数据梦工厂
新浪微博:www.weibo.com/ilovepains/
微信公众号:DT_Spark
博客:http://.blog.sina.com.cn/ilovepains
TEL:18610086859
Email:18610086859@vip.126.com
参考链接:
http://blog.csdn.net/kxr0502/article/details/50574561
http://blog.csdn.net/happyanger6/article/details/46576831
http://blog.csdn.net/happyanger6/article/details/46552823
Spark RDD概念学习系列之rdd持久化、广播、累加器(十八)的更多相关文章
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- Spark RDD概念学习系列之RDD的操作(七)
RDD的操作 RDD支持两种操作:转换和动作. 1)转换,即从现有的数据集创建一个新的数据集. 2)动作,即在数据集上进行计算后,返回一个值给Driver程序. 例如,map就是一种转换,它将数据集每 ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD是什么?(四)
RDD是什么? 通俗地理解,RDD可以被抽象地理解为一个大的数组(Array),但是这个数组是分布在集群上的.详细见 Spark的数据存储 Spark的核心数据模型是RDD,但RDD是个抽象类 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark RDD概念学习系列之RDD的缺点(二)
RDD的缺点? RDD是Spark最基本也是最根本的数据抽象,它具备像MapReduce等数据流模型的容错性,并且允许开发人员在大型集群上执行基于内存的计算. 为了有效地实现容错,(详细见ht ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark RDD概念学习系列之RDD的创建(六)
RDD的创建 两种方式来创建RDD: 1)由一个已经存在的Scala集合创建 2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS.Cassandra.H ...
随机推荐
- windows下使用xampp一键安装apache+php运行环境
感谢浏览,欢迎交流=.= 想为我老爸开发一套库存管理系统,借此机会打算使用下ext+php+apache+linux环境尝尝鲜. 为了在windows搭建本地开发测试环境,官网下载xampp,一键安装 ...
- git push后修改错误的commit message
Easiest solution (but please read this whole answer before doing this): git rebase -i <hash-of-co ...
- Python httpsqs封装类
''' httpsqs队列封装 @author xp_go@qq.com a = HttpsqsClient('192.168.0.218','1218','httpsqsmmall.com') pr ...
- 和阿木聊Node.js
npm:node.js官方库 cnpm:taobao维护的库: WebStorm:Node.js的开发工具,但是收费: seajs:还有一款交requirjs,前者是遵循amd规范(一次性参数中加载要 ...
- bzoj 1200: [HNOI2005]木梳 DP
1200: [HNOI2005]木梳 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 266 Solved: 125[Submit][Status] ...
- Buying Feed, 2010 Nov (单调队列优化DP)
约翰开车回家,又准备顺路买点饲料了(咦?为啥要说"又"字?)回家的路程一共有 E 公里,这一路上会经过 K 家商店,第 i 家店里有 Fi 吨饲料,售价为每吨 Ci 元.约翰打算买 ...
- 【BZOJ 3926】 [Zjoi2015]诸神眷顾的幻想乡 (广义SAM)
3926: [Zjoi2015]诸神眷顾的幻想乡 Time Limit: 10 Sec Memory Limit: 512 MBSubmit: 974 Solved: 573 Descriptio ...
- ASP.NET多用户操作相同互斥的对象
[一篮饭特稀原创,转载请注明出自http://www.cnblogs.com/wanghafan/p/3574154.html ] 现象:公有静态变量不可用于ASP.NET多用户操作,否则该变量会被多 ...
- 关于在WIN32调用一些Zw系列的文件操作函数
转自:http://blog.csdn.net/cooblily/archive/2007/10/27/1848037.aspx 都好久沒上來写文章了,都不知道做什么好,結果还是学写了一下用Nativ ...
- NavigationDrawer+Fragment实现侧滑菜单效果
学习了NavigationDrawer 官方Support包中的SlidingMenu版本,练了下手.用到了ListView中item不同的布局 以后会升级加上ViewPager和GridView实现 ...