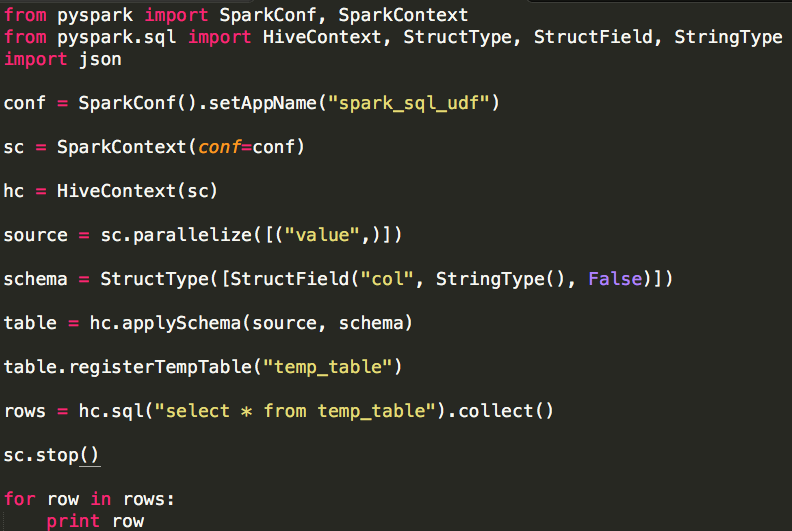
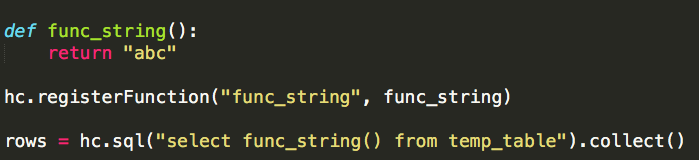
Spark(Hive) SQL中UDF的使用(Python)
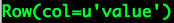
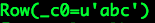





Spark(Hive) SQL中UDF的使用(Python)的更多相关文章
- Spark(Hive) SQL中UDF的使用(Python)【转】
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- Spark(Hive) SQL数据类型使用详解(Python)
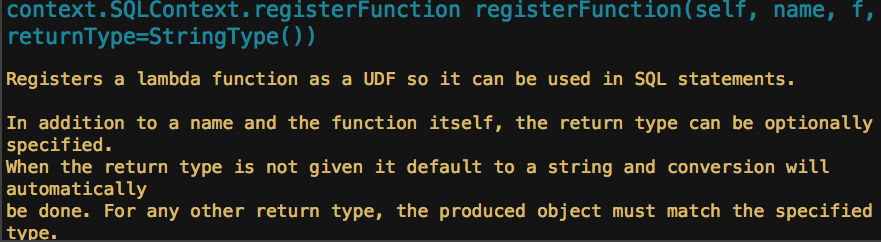
Spark SQL使用时需要有若干“表”的存在,这些“表”可以来自于Hive,也可以来自“临时表”.如果“表”来自于Hive,它的模式(列名.列类型等)在创建时已经确定,一般情况下我们直接通过Spar ...
- Spark SQL中UDF和UDAF
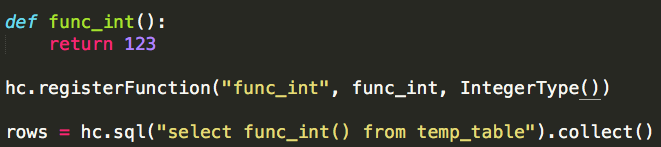
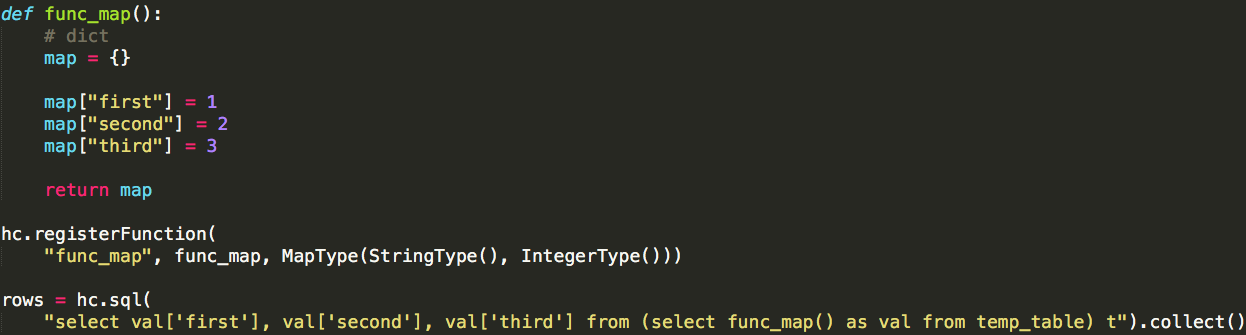
转载自:https://blog.csdn.net/u012297062/article/details/52227909 UDF: User Defined Function,用户自定义的函数,函数 ...
- 两种方式— 在hive SQL中传入参数
第一种: sql = sql.format(dt=dt) 第二种: item_third_cate_cd_list = " 发发发 " ...... ""&qu ...
- Hive SQL 编译过程
转自:http://www.open-open.com/lib/view/open1400644430159.html Hive跟Impala貌似都是公司或者研究所常用的系统,前者更稳定点,实现方式是 ...
- 【转】Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程
文章转自:http://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是 ...
- 转:Hive SQL的编译过程
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析.Hive的稳定性和 ...
- Hive SQL的编译过程[转载自https://tech.meituan.com/hive-sql-to-mapreduce.html]
https://tech.meituan.com/hive-sql-to-mapreduce.html Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用.美团数据仓库也是基于Hi ...
随机推荐
- PHP四种传参方式
test1界面: <html> <head> <title>testPHP</title> <meta http-equiv = "co ...
- jquery 提示信息显示后自动消失的具体实现
方法一: 复制代码 代码如下: $("#errormsg").html("您的信息输入错误,请重试!").show(300).delay(3000).hide( ...
- YesNo列
比较,注意两边类型是否一致,以及boolean类型tostring之后的值 if(item["IsShow"].ToString() == "True")
- 简单登录案例(SharedPreferences存储账户信息)&联网请求图片并下载到SD卡(文件外部存储)
新人刚学习Android两周,写一个随笔算是对两周学习成果的巩固,不足之处欢迎各位建议和完善. 这次写的是一个简单登录案例,大概功能如下: 注册的账户信息用SharedPreferences存储: 登 ...
- SET NOCOUNT 的意义.
SET NOCOUNT 使返回的结果中不包含有关受 Transact-SQL 语句影响的行数的信息. 语法 SET NOCOUNT { ON | OFF } 当 SET NOCOUNT 为 ON 时, ...
- Mysql DB2等数据库分页的实现
一.Mysql的分页 (一).MySQL分页的实现,使用关键字:Limit 语法:select * from tableName Limit A,B; 注释:tableName:表名 A:查询的 ...
- iOS与Android通用AES加密
找了很久才成功的aes 加密 服务器java写的 下载地址 https://pan.baidu.com/s/1nvi1zjr
- O-C相关04:类方法的概述与定义和调用
类方法的概述与定义和调用 1, 类方法的概述 类方法(class method)在其他编程语言中常常称为静态方法(例如 Java 或 C# 等). 与实例方法不同的是,类方法只需要使用类名即可调用, ...
- 【elasticsearch】(1)centos7 使用yum安装elasticsearch 2.X
前言 elasticsearch(下面称为ES)是一个基于Lucene的搜索服务器(By 百度百科:查看).所以他需要java的环境即jdk,这里提供懒人一键安装方式 # yum install ja ...
- 简易的highcharts公共绘图模块封装--基于.net mvc
运行效果: 之所以选择这个图表插件,是因为它较其他同类插件轻量且中文文档详细完整,Demo丰富,配置使用简单.具体内容请登录中文官网:http://www.hcharts.cn/ 项目详细: 项目环境 ...