ubuntu 20.04 基于kubeadm部署kubernetes 1.22.4集群及部署集群管理工具
一、环境准备:
集群版本:kubernetes 1.22.4
| 服务器系统 | 节点IP | 节点类型 | 服务器-内存/CUP | hostname |
| Ubuntu 20.04 | 192.168.1.101 | 主节点 | 2G/4核 | master |
| Ubuntu 20.04 | 192.168.1.102 | 工作节点1 | 2G/4核 | node1 |
| Ubuntu 20.04 | 192.168.1.104 | 工作节点2 | 2G/4核 | node2 |
二、安装检查:
注:在三台机器上执行------------------------开始----------------------------
1.3台机器网络连通
2.3台机器Hostname,MAC地址,product_uuid (可以通过sudo cat /sys/class/dmi/id/product_uuid查看)必须唯一
3.检查以下端口的连通性---我这里为了方便把防火墙直接关了,,生产环境不能这么做!!!
4.禁用swap(重要!!!)
检查swap
yang@master:/etc/docker$ sudo free -m
[sudo] password for yang:
total used free shared buff/cache available
Mem: 1959 1222 86 3 649 548
Swap: 2047 0 2047
临时禁用swap
yang@master:/etc/docker$ sudo swapoff -a
再次查看swap
yang@master:/etc/docker$ sudo free -m
[sudo] password for yang:
total used free shared buff/cache available
Mem: 1959 1222 86 3 649 548
Swap: 0 0 0
5.将文件系统设置为可读写
yang@master:/etc/docker$ sudo mount -n -o remount,rw /
6.将文件中的swap行使用#注释掉,永久关闭交换分区
swap分区:交换分区,从磁盘里分一块空间来充当内存使用,性能比真正的物理内存要差
docker容器在内存里运行 --》 k8s不允许容器到swap分区运行,要关闭swap分区–》所以关闭swap分区是k8s为了追求高性能
yang@master:/etc/docker$ sudo nano /etc/fstab
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
# <file system> <mount point> <type> <options> <dump> <pass>
# / was on /dev/sda2 during curtin installation
/dev/disk/by-uuid/7006dc64-4b4b-41e7-a1ea-857c98683977 / ext4 defaults 0 1
#/swap.img none swap sw 0 0
7.重启电脑
yang@master:/etc/docker$ sudo reboot
三、安装CRI-这里使用Docker
1.Ubuntu 20.04 server 安装docker最新版
# Install Docker Engine on Ubuntu
#卸载旧版本,旧版本的 Docker 被称为 docker、docker.io 或 docker-engine。如果安装了这些,请卸载它们
sudo apt-get remove docker docker-engine docker.io containerd runc
#设置存储库
#更新 apt 包索引并安装包以允许 apt 通过 HTTPS 使用存储库
sudo apt-get update
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-release
#添加Docker官方的GPG密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
#使用以下命令设置稳定存储库
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
#安装 Docker 引擎
#更新apt包索引,安装最新版本的Docker Engine和containerd,或者到下一步安装特定版本
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io #安装特定docker版本(本文用不到)
#查询存储库中可用版本
apt-cache madison docker-ce
使用第二列中的版本字符串安装特定版本,例如 5:18.09.1~3-0~ubuntu-xenial
#安装命令
sudo apt-get install docker-ce=<VERSION_STRING> docker-ce-cli=<VERSION_STRING> containerd.io
注:将<VERSION_STRING>,替换为特定版本即可安装。
2.使普通用户也可以执行docker命令
sudo groupadd docker #添加docker用户组
sudo gpasswd -a $USER docker #将登陆用户加入到docker用户组中
newgrp docker #更新用户组
3.检查docker安装情况
yang@master:/etc/docker$ docker version
Client: Docker Engine - Community
Version: 20.10.11
API version: 1.41
Go version: go1.16.9
Git commit: dea9396
Built: Thu Nov 18 00:37:06 2021
OS/Arch: linux/amd64
Context: default
Experimental: true Server: Docker Engine - Community
Engine:
Version: 20.10.11
API version: 1.41 (minimum version 1.12)
Go version: go1.16.9
Git commit: 847da18
Built: Thu Nov 18 00:35:15 2021
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.4.12
GitCommit: 7b11cfaabd73bb80907dd23182b9347b4245eb5d
runc:
Version: 1.0.2
GitCommit: v1.0.2-0-g52b36a2
docker-init:
Version: 0.19.0
GitCommit: de40ad0
4.检查套接字
检查套接字(kubernetes会在这个目录下搜索,从而识别到CRI)
yang@master:/etc/docker$ ls /var/run/docker.sock
/var/run/docker.sock
四、安装kubectl kubeadm kubelet
1.安装curl和apt-transport-https
sudo apt-get update && sudo apt-get install -y apt-transport-https curl
2.下载GPG
sudo wget https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg
3.添加GPG
sudo apt-key add apt-key.gpg
4.写入镜像源文件
注:没有此目录,直接在下面创建这个文件,并增加以下内容。
sudo cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main EOF
5.更新索引
sudo apt-get update
6.安装kubectl kubeadm kubelet
sudo apt-get install -y kubeadm
注:在三台机器上执行------------------------结束----------------------------
五、安装集群
注:master上执行
1.检查需要哪些镜像
yang@master:/etc/docker$ kubeadm config images list
k8s.gcr.io/kube-apiserver:v1.22.4
k8s.gcr.io/kube-controller-manager:v1.22.4
k8s.gcr.io/kube-scheduler:v1.22.4
k8s.gcr.io/kube-proxy:v1.22.4
k8s.gcr.io/pause:3.5
k8s.gcr.io/etcd:3.5.0-0
k8s.gcr.io/coredns/coredns:v1.8.4
2.下载镜像文件
创建一个脚本,给执行权限,方便操作
sudo nano pull
sudo chmod +x pull
#!/bin/sh
sudo docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.22.4
sudo docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.22.4
sudo docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.22.4
sudo docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.4
sudo docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5
sudo docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.0-0
sudo docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.4
./pull
3.查看镜像文件
yang@master:/etc/docker$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver v1.22.4 8a5cc299272d 11 days ago 128MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager v1.22.4 0ce02f92d3e4 11 days ago 122MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler v1.22.4 721ba97f54a6 11 days ago 52.7MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy v1.22.4 edeff87e4802 11 days ago 104MB
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd 3.5.0-0 004811815584 5 months ago 295MB
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns v1.8.4 8d147537fb7d 6 months ago 47.6MB
registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.5 ed210e3e4a5b 8 months ago 683kB
4.修改镜像tag
sudo nano tag
sudo chmod +x tag
#!/bin/sh
sudo docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.22.4 k8s.gcr.io/kube-apiserver:v1.22.4
sudo docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.22.4 k8s.gcr.io/kube-controller-manager:v1.22.4
sudo docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.22.4 k8s.gcr.io/kube-scheduler:v1.22.4
sudo docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.4 k8s.gcr.io/kube-proxy:v1.22.4
sudo docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5 k8s.gcr.io/pause:3.5
sudo docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.0-0 k8s.gcr.io/etcd:3.5.0-0
sudo docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.4 k8s.gcr.io/coredns/coredns:v1.8.4
./tag
5.查看修改后的镜像
yang@master:/etc/docker$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-apiserver v1.22.4 8a5cc299272d 11 days ago 128MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver v1.22.4 8a5cc299272d 11 days ago 128MB
k8s.gcr.io/kube-controller-manager v1.22.4 0ce02f92d3e4 11 days ago 122MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager v1.22.4 0ce02f92d3e4 11 days ago 122MB
k8s.gcr.io/kube-scheduler v1.22.4 721ba97f54a6 11 days ago 52.7MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler v1.22.4 721ba97f54a6 11 days ago 52.7MB
k8s.gcr.io/kube-proxy v1.22.4 edeff87e4802 11 days ago 104MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy v1.22.4 edeff87e4802 11 days ago 104MB
k8s.gcr.io/etcd 3.5.0-0 004811815584 5 months ago 295MB
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd 3.5.0-0 004811815584 5 months ago 295MB
k8s.gcr.io/coredns/coredns v1.8.4 8d147537fb7d 6 months ago 47.6MB
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns v1.8.4 8d147537fb7d 6 months ago 47.6MB
k8s.gcr.io/pause 3.5 ed210e3e4a5b 8 months ago 683kB
registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.5 ed210e3e4a5b 8 months ago 683kB
6. 配置集群
初始化主节点
master执行
kubeadm init --apiserver-advertise-address=192.168.1.101 --kubernetes-version=v1.22.4 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=all --v=6
初始化完成显示
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.101:6443 --token zbsafp.yliab4onvxpwdmxx \
--discovery-token-ca-cert-hash sha256:5e2e9d7c76cce5e14897138979d7b397311fd632a1618920a29582ca6d2523b3
照上面提示迁移配置
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
7.子节点(node)加入集群
注:
a.上传kube-proxy:v1.22.4,pause:3.5,coredns:v1.8.4 三个镜像,并修改tag
b.修改daemon.json
加入集群命令:
kubeadm join 192.168.1.101:6443 --token zbsafp.yliab4onvxpwdmxx \ --discovery-token-ca-cert-hash sha256:5e2e9d7c76cce5e14897138979d7b397311fd632a1618920a29582ca6d2523b3
添加node节点,报错1
注:可以提前在各node节点上修改好(无报错无需执行此项)
yang@node2:~$ sudo kubeadm join 192.168.1.101:6443 --token 6131nu.8ohxo1ttgwiqlwmp --discovery-token-ca-cert-hash sha256:9bece23d1089b6753a42ce4dab3fa5ac7d2d4feb260a0f682bfb06ccf1eb4fe2
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[kubelet-check] Initial timeout of 40s passed.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
error execution phase kubelet-start: error uploading crisocket: timed out waiting for the condition
To see the stack trace of this error execute with --v=5 or higher
原 因:
1.因为docker默认的Cgroup Driver是cgroupfs ,cgroupfs是cgroup为给用户提供的操作接口而开发的虚拟文件系统类型
它和sysfs,proc类似,可以向用户展示cgroup的hierarchy,通知kernel用户对cgroup改动
对cgroup的查询和修改只能通过cgroupfs文件系统来进行
2.Kubernetes 推荐使用 systemd 来代替 cgroupfs
因为systemd是Kubernetes自带的cgroup管理器, 负责为每个进程分配cgroups,
但docker的cgroup driver默认是cgroupfs,这样就同时运行有两个cgroup控制管理器,
当资源有压力的情况时,有可能出现不稳定的情况
解决办法:
①. 创建daemon.json文件,加入以下内容:
ls /etc/docker/daemon.json
{"exec-opts": ["native.cgroupdriver=systemd"]}
②. 重启docker
sudo systemctl restart docker
③. 重启kubelet
sudo systemctl restart kubelet
sudo systemctl status kubelet
④. 重新执行加入集群命令
首先清除缓存
sudo kubeadm reset
⑤. 加入集群
sudo kubeadm join 192.168.1.101:6443 --token 6131nu.8ohxo1ttgwiqlwmp --discovery-token-ca-cert-hash sha256:9bece23d1089b6753a42ce4dab3fa5ac7d2d4feb260a0f682bfb06ccf1eb4fe2
报错2
注:各node上需要有kube-proxy镜像
问题:
Normal BackOff 106s (x249 over 62m) kubelet Back-off pulling image "k8s.gcr.io/kube-proxy:v1.22.4"
原 因:
缺少k8s.gcr.io/kube-proxy:v1.22.4镜像
解决办法:
① 上传镜像
sudo docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.4
② 修改镜像tag
sudo docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.4 k8s.gcr.io/kube-proxy:v1.22.4
报错3
注:各node上需要有pause:3.5镜像
问题:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 17m default-scheduler Successfully assigned kube-system/kube-proxy-dv2sw to node2
Warning FailedCreatePodSandBox 4m48s (x26 over 16m) kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.5": Error response from daemon: Get "https://k8s.gcr.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
Warning FailedCreatePodSandBox 93s (x2 over 16m) kubelet Failed to create pod sandbox: rpc error: code = Unknown desc = failed pulling image "k8s.gcr.io/pause:3.5": Error response from daemon: Get "https://k8s.gcr.io/v2/": dial tcp 74.125.195.82:443: i/o timeout
原 因:
缺少k8s.gcr.io/pause:3.5镜像
解决办法:
① 上传镜像
sudo docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5
② 修改镜像tag
sudo docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5 k8s.gcr.io/pause:3.5
报错4
注:各node上需要有coredns:v1.8.4镜像
问题:
Warning Failed 28m (x11 over 73m) kubelet Failed to pull image "k8s.gcr.io/coredns/coredns:v1.8.4"
: rpc error: code = Unknown desc = Error response from daemon: Get "https://k8s.gcr.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
这里是一个坑,镜像的tag是v1.8.4,而不是1.8.4,所以导致下载超时
查看官网images列表
yang@master:/etc/docker$ kubeadm config images list
k8s.gcr.io/kube-apiserver:v1.22.4
k8s.gcr.io/kube-controller-manager:v1.22.4
k8s.gcr.io/kube-scheduler:v1.22.4
k8s.gcr.io/kube-proxy:v1.22.4
k8s.gcr.io/pause:3.5
k8s.gcr.io/etcd:3.5.0-0
k8s.gcr.io/coredns/coredns:v1.8.4
解决办法:
① 上传镜像
sudo docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.4
② 修改镜像tag
sudo docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.4 k8s.gcr.io/coredns/coredns:v1.8.4
8.检查健康状态
此时controller-manager与scheduler异常
yang@master:/etc/docker$ kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager UnHealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true","reason":""}
scheduler UnHealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
9.修改两个配置文件,如下:
注释内容:# - --port=0
yang@master:/etc/docker$ sudo nano /etc/kubernetes/manifests/kube-controller-manager.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-controller-manager
tier: control-plane
name: kube-controller-manager
namespace: kube-system
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=127.0.0.1
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --cluster-cidr=10.244.0.0/16
- --cluster-name=kubernetes
- --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
- --cluster-signing-key-file=/etc/kubernetes/pki/ca.key
- --controllers=*,bootstrapsigner,tokencleaner
- --kubeconfig=/etc/kubernetes/controller-manager.conf
- --leader-elect=true
#- --port=0
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --root-ca-file=/etc/kubernetes/pki/ca.crt
- --service-account-private-key-file=/etc/kubernetes/pki/sa.key
- --service-cluster-ip-range=10.96.0.0/12
- --use-service-account-credentials=true
image: k8s.gcr.io/kube-controller-manager:v1.22.4
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
yang@master:/etc/docker$ sudo nano /etc/kubernetes/manifests/kube-scheduler.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-scheduler
tier: control-plane
name: kube-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
#- --port=0
image: k8s.gcr.io/kube-scheduler:v1.22.4
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /healthz
port: 10259
scheme: HTTPS
initialDelaySeconds: 10
10.再次查看健康状态
这时10251,10252端口就开启了,健康检查状态也正常了。
yang@master:/etc/docker$ kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
controller-manager Healthy ok
11.节点状态
yang@master:~$ kubectl get node NAME STATUS ROLES AGE VERSION master NotReady control-plane,master 21m v1.22.4 node1 NotReady <none> 15m v1.22.4 node2 NotReady <none> 14m v1.22.4
节点还是NotReady,检查Pod
yang@master:~$ kubectl get pod --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-78fcd69978-drgk6 0/1 pending 0 4d1h
kube-system coredns-78fcd69978-tz4kt 0/1 pending 0 4d1h
kube-system etcd-master 1/1 Running 1 (3d19h ago) 4d1h
kube-system kube-apiserver-master 1/1 Running 1 (3d19h ago) 4d1h
kube-system kube-controller-manager-master 1/1 Running 3 3d19h
kube-system kube-flannel-ds-ksn8l 1/1 Running 0 3d20h
kube-system kube-flannel-ds-ld5jr 1/1 Running 1 (3d19h ago) 3d20h
kube-system kube-flannel-ds-wf2t2 1/1 Running 0 3d20h
kube-system kube-proxy-dv2sw 1/1 Running 0 4d
kube-system kube-proxy-jl7f5 1/1 Running 0 4d
kube-system kube-proxy-xn96j 1/1 Running 2 (3d19h ago) 4d1h
kube-system kube-scheduler-master 1/1 Running 3 3d19h
kube-system rancher-6fbc899b67-mzcvb 1/1 Running 0 2d21h
原 因:coredns状态为pending,未运行,因为缺少网络组件
执行命令查看:journalctl -f -u kubelet
Nov 06 15:37:21 jupiter kubelet[86177]: W1106 15:37:21.482574 86177 cni.go:237] Unable to update cni config: no valid networks found in /etc/cni
Nov 06 15:37:25 jupiter kubelet[86177]: E1106 15:37:25.075839 86177 kubelet.go:2187] Container runtime network not ready: NetworkReady=false reaeady: cni config uninitialized
解决办法:
yang@master:/etc/docker$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
yang@master:~$ kubectl get pod --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-78fcd69978-drgk6 1/1 Running 0 4d1h
kube-system coredns-78fcd69978-tz4kt 1/1 Running 0 4d1h
kube-system etcd-master 1/1 Running 1 (3d19h ago) 4d1h
kube-system kube-apiserver-master 1/1 Running 1 (3d19h ago) 4d1h
kube-system kube-controller-manager-master 1/1 Running 3 3d19h
kube-system kube-flannel-ds-ksn8l 1/1 Running 0 3d20h
kube-system kube-flannel-ds-ld5jr 1/1 Running 1 (3d19h ago) 3d20h
kube-system kube-flannel-ds-wf2t2 1/1 Running 0 3d20h
kube-system kube-proxy-dv2sw 1/1 Running 0 4d
kube-system kube-proxy-jl7f5 1/1 Running 0 4d
kube-system kube-proxy-xn96j 1/1 Running 2 (3d19h ago) 4d1h
kube-system kube-scheduler-master 1/1 Running 3 3d19h
kube-system rancher-6fbc899b67-mzcvb 1/1 Running 0 2d21h
12.查看节点状态
yang@master:~$ kubectl get node
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 4d1h v1.22.4
node1 Ready <none> 4d v1.22.4
node2 Ready <none> 4d v1.22.4
至此,集群部署完毕!
Kubernetes正在不断加快在云原生环境的应用,但如何以统一、安全的方式对运行于任何地方的Kubernetes集群进行管理面临着挑战,而有效的管理工具能够大大降低管理的难度。如何管理集群呢?有什么图形化工具呢?
例如:
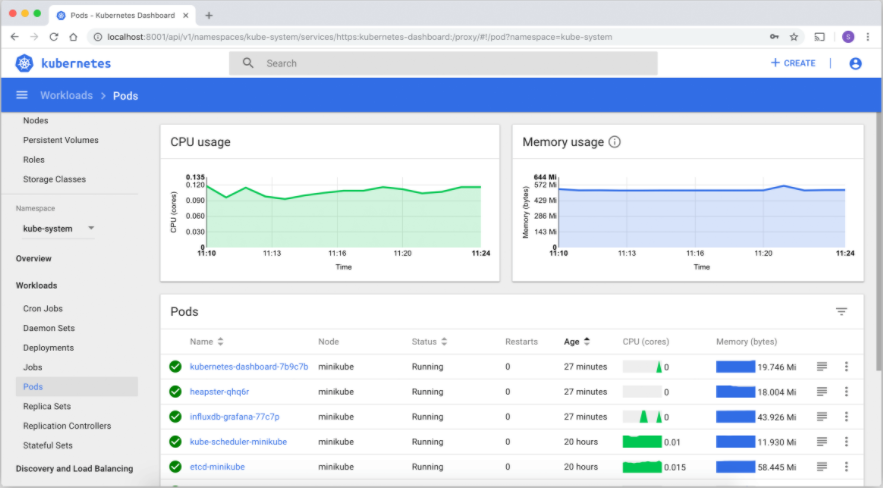
1. kubernetes-dashboard
Dashboard 是基于网页的 Kubernetes 用户界面。 你可以使用 Dashboard 将容器应用部署到 Kubernetes 集群中,也可以对容器应用排错,还能管理集群资源。 你可以使用 Dashboard 获取运行在集群中的应用的概览信息,也可以创建或者修改 Kubernetes 资源 (如 Deployment,Job,DaemonSet 等等)。 例如,你可以对 Deployment 实现弹性伸缩、发起滚动升级、重启 Pod 或者使用向导创建新的应用。
Dashboard 同时展示了 Kubernetes 集群中的资源状态信息和所有报错信息。
官网地址:https://kubernetes.io/zh/docs/tasks/access-application-cluster/web-ui-dashboard/
2.kuboard
Kuboard 是一款免费的 Kubernetes 管理工具,提供了丰富的功能,结合已有或新建的代码仓库、镜像仓库、CI/CD工具等,可以便捷的搭建一个生产可用的 Kubernetes 容器云平台,轻松管理和运行云原生应用。您也可以直接将 Kuboard 安装到现有的 Kubernetes 集群,通过 Kuboard 提供的 Kubernetes RBAC 管理界面,将 Kubernetes 提供的能力开放给您的开发/测试团队。Kuboard 提供的功能有:
- Kubernetes 基本管理功能
- Kubernetes 问题诊断
- Kubernetes 存储管理
- 认证与授权(收费)
- Kuboard 特色功能
官方有在线演示地址,可以不用安装先体验一下
官网地址:https://www.kuboard.cn/

3.kubesphere
KubeSphere 是在 Kubernetes 之上构建的面向云原生应用的分布式操作系统,支持多云与多集群管理,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。它的架构可以非常方便地使第三方应用与云原生生态组件进行即插即用 (plug-and-play) 的集成。
作为全栈化容器部署与多租户管理平台,KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。它拥有 Kubernetes 企业级服务所需的最常见功能,例如 Kubernetes 资源管理、DevOps、多集群部署与管理、应用生命周期管理、微服务治理、日志查询与收集、服务与网络、多租户管理、监控告警、事件审计、存储、访问控制、GPU 支持、网络策略、镜像仓库管理以及安全管理等。
官网地址:https://kubesphere.io/zh/
4.Rancher
Rancher 是为使用容器的公司打造的容器管理平台。Rancher 简化了使用 Kubernetes 的流程,开发者可以随处运行 Kubernetes(Run Kubernetes Everywhere),满足 IT 需求规范,赋能 DevOps 团队。
这几种是目前比较火的集群管理工具,可以任意选一种!
我这里使用了kuboard工具
在 K8S 中安装 Kuboard,主要考虑的问题是,如何提供 etcd 的持久化数据卷。建议的两个选项有:
- 使用 hostPath 提供持久化存储,将 kuboard 所依赖的 Etcd 部署到 Master 节点,并将 etcd 的数据目录映射到 Master 节点的本地目录;推荐
- 使用 StorageClass 动态创建 PV 为 etcd 提供数据卷;不推荐
1.安装
执行 Kuboard v3 在 K8S 中的安装
kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
# 您也可以使用下面的指令,唯一的区别是,该指令使用华为云的镜像仓库替代 docker hub 分发 Kuboard 所需要的镜像
# kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3-swr.yaml
2.等待 Kuboard v3 就绪
执行指令 watch kubectl get pods -n kuboard,等待 kuboard 名称空间中所有的 Pod 就绪,如下所示,
如果结果中没有出现 kuboard-etcd-xxxxx 的容器。
3.访问
在浏览器中打开链接 http://your-node-ip-address:30080
输入初始用户名和密码,并登录
- 用户名:
admin - 密码:
Kuboard123
- 用户名:
访问后,将创建一个集群,将部署的k8s加入到管理列表中,如下:
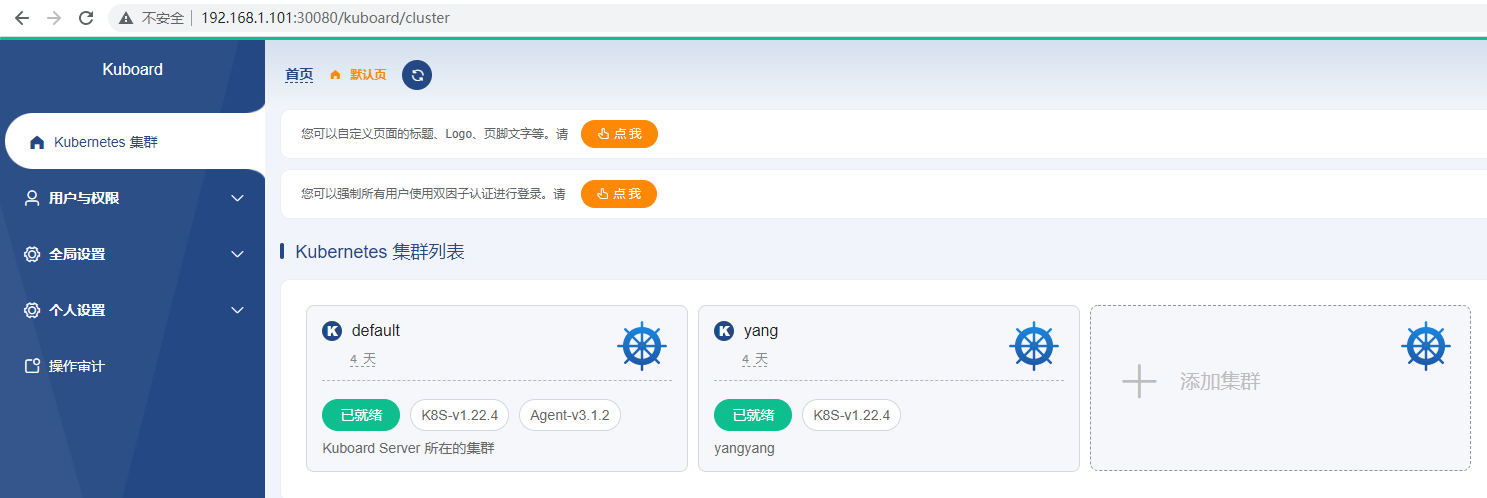
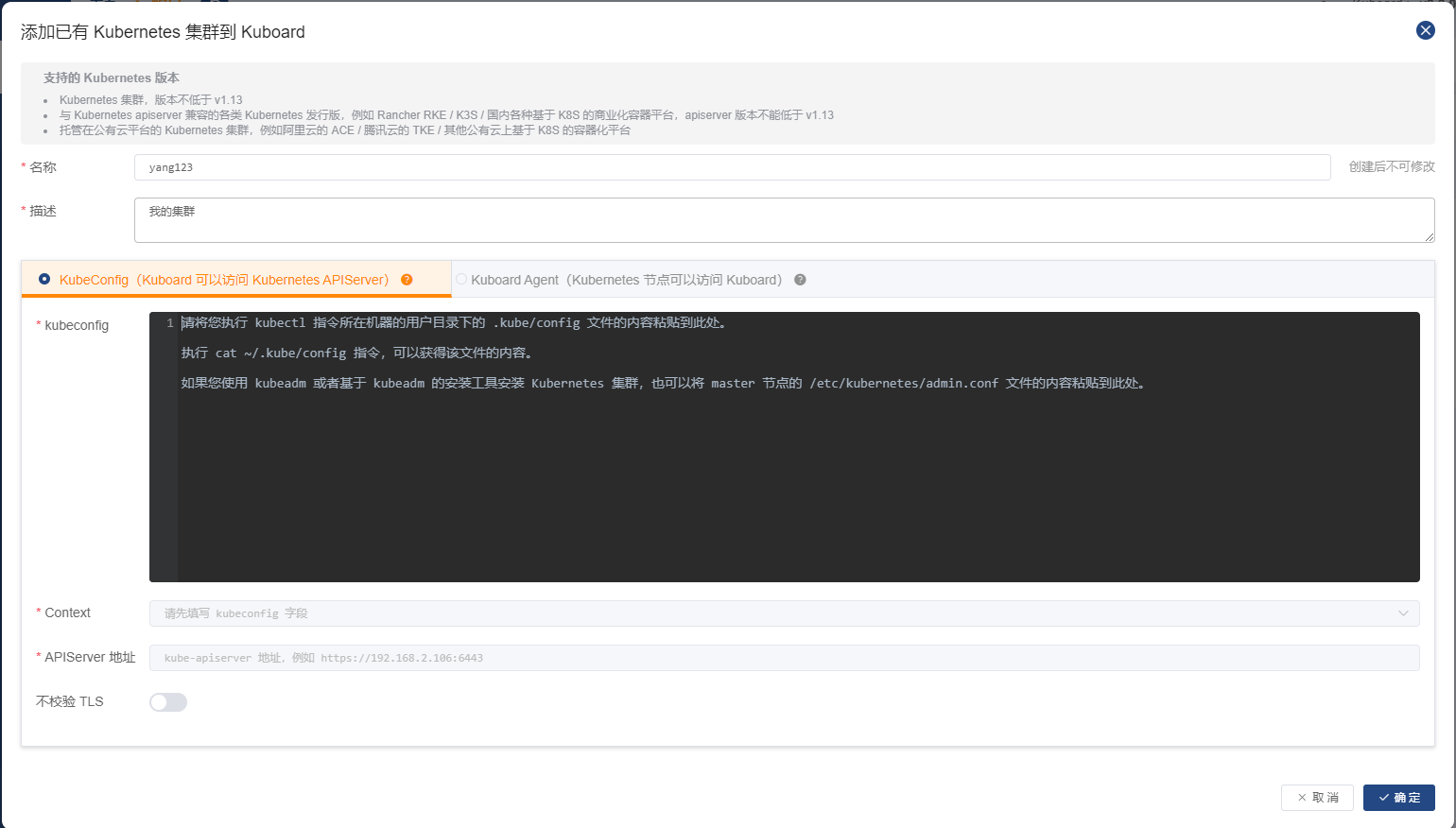
编写集群名称,描述,加入集群的指令(按提示框内操作),Context:kubernetes ,ApiServer地址为:http://masterIP:6443,然后确定即可将集群加入!
yang@master:~$ sudo cat /etc/kubernetes/admin.conf


部署一个rancher,调度到了node1上,并且可以正常访问!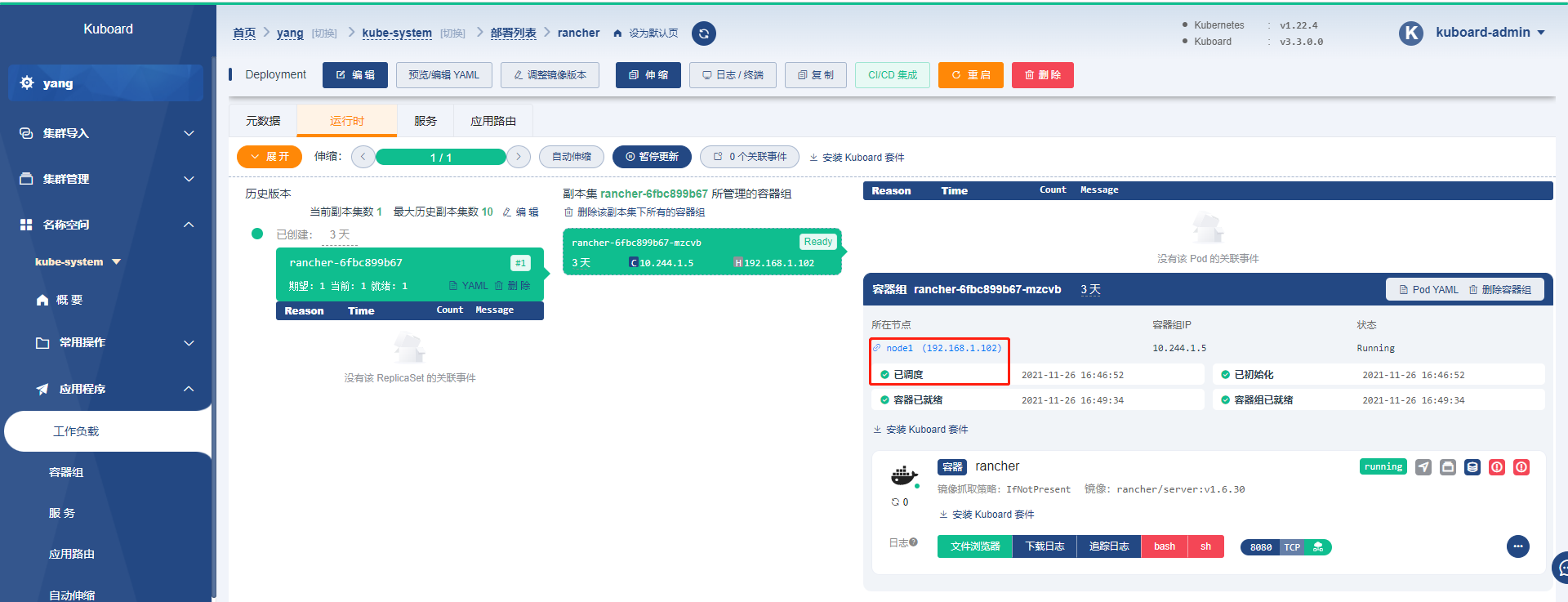


亦可进入容器,终端控制台,以及,日志的查询,显示如下:

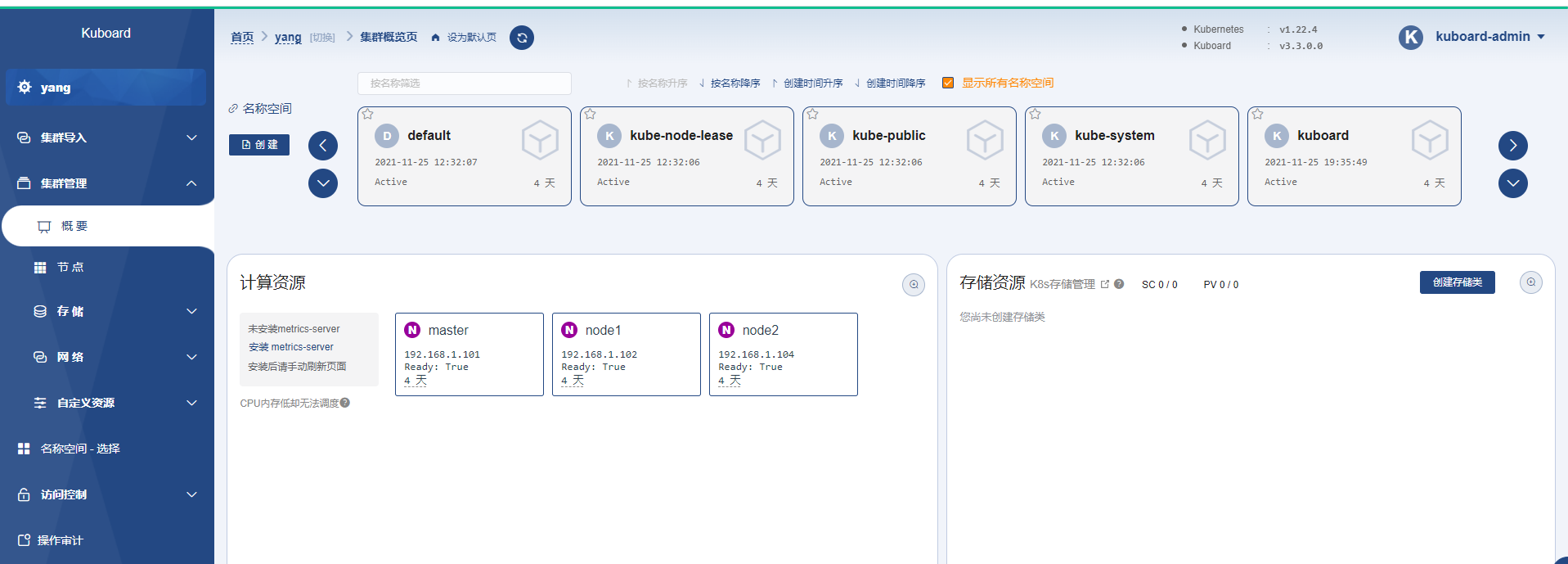
此时,我已经将部署的kubernetes集群加入到kuboard里面,并且显示正常运行,且可以正常调度!
浏览器兼容性
- 请使用 Chrome / FireFox / Safari / Edge 等浏览器
- 不兼容 IE 以及以 IE 为内核的浏览器
4.添加新的集群
- Kuboard v3 是支持 Kubernetes 多集群管理的,在 Kuboard v3 的首页里,点击 添加集群 按钮,在向导的引导下可以完成集群的添加;
- 向 Kuboard v3 添加新的 Kubernetes 集群时,请确保:
- 您新添加集群可以访问到当前集群 Master 节点
内网IP的30080 TCP、30081 TCP、30081 UDP端口; - 如果您打算新添加到 Kuboard 中的集群与当前集群不在同一个局域网,请咨询 Kuboard 团队,帮助您解决问题。
- 您新添加集群可以访问到当前集群 Master 节点
5.卸载
执行 Kuboard v3 的卸载
kubectl delete -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml清理遗留数据
在 master 节点以及带有
k8s.kuboard.cn/role=etcd标签的节点上执行rm -rf /usr/share/kuboard
常用命令:
1、查看集群信息node
kubuctl get node
2、查看所有pod
kubectl get pod --all-namespaces
3、查看pod详细信息
kubectl describe pod pod名称 --namespace=NAMESPACE
4、查看健康状态
kubectl get cs
5.查看指定namespace 下的pod
kubectl get pods --namespace=test
6.查看namespace:
kubectl get namespace
7.创建名为test的namespace
kubectl create namespace test
8.设置命名空间首选项
kubectl config set-context --current --namespace=test
9.在已创建的命名空间中创建资源
kubectl apply -f pod.yaml --namespace=test
10.进入k8s启动pod
kubectl exec -it admin-frontend-server-74497cb64f-8fxk8 --bash
11.查看各组件状态
kubectl get componentstatuses
12.master 节点也作为node节点
kubectl taint nodes --all node-role.kubernetes.io/master-
13.其他命令
kubectl get pods -n kube-system
kubectl get pod --all-namespaces
kubectl get csr
kubectl get deployments
kubectl get pods -n kube-system -o wide --watch
kubectl describe pods weave-net-87t7g -n kube-system
14.创建pod
kubectl create -f deployment.yaml
15.创建server文件
kubectl create -f services.yaml
16.查看文件创建情况
kubectl discribe service **
kubectl discribe deployment **
17.删除 secret, deployment
kubectl delete secret **
kubectl delete deployment **
18. 匹配特定服务;
kubectl get po | grep display
kubectl get svc | grep data
19.查看服务日志
kubectl logs ** -f —tail=20
kubectl logs ** --since=1h
20。卸载集群
# 想要撤销kubeadm做的事,首先要排除节点,并确保在关闭节点之前要清空节点。
# 在主节点上运行:
kubectl drain <node name> --delete-local-data --force --ignore-daemonsets
kubectl delete node <node name>
21. 然后在需要移除的节点上,重置kubeadm的安装状态:
kubeadm reset
# 重置Kubernetes
# 参考https://www.jianshu.com/p/31f7dda9ccf7
sudo kubeadm reset
# 重置后删除网卡等信息
rm -rf /etc/cni/net.d
# 重置iptables
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
sysctl net.bridge.bridge-nf-call-iptables=1
# 清楚网卡
sudo ip link del cni0
sudo ip link del flannel.1
ubuntu 20.04 基于kubeadm部署kubernetes 1.22.4集群及部署集群管理工具的更多相关文章
- Ubuntu 20.04安装Docker
Docker学习系列文章 入门必备:十本你不容错过的Docker入门到精通书籍推荐 day1.全面的Docker快速入门教程 day2.CentOS 8.4安装Docker day3.Windows1 ...
- OpenCV4.4.0 安装测试 Installation & Examination (Ubuntu18.04, Ubuntu 20.04)
OpenCV4.4.0 安装测试 Installation & Examination (Ubuntu18.04, Ubuntu 20.04) 单纯简单的 OpenCV 安装配置方法,在这个地 ...
- Pangolin 安装测试 Installation & Examination (Ubuntu 20.04)
Pangolin 安装测试 Installation & Examination (Ubuntu 20.04) 如题所述,这是一个比较轻松的 Pangolin 安装配置方法,同样是基于 WSL ...
- 内网 Ubuntu 20.04 搭建 docusaurus 项目(或前端项目)的环境(mobaxterm、tigervnc、nfs、node)
内网 Ubuntu 20.04 搭建 docusaurus 项目(或前端项目)的环境 背景 内网开发机是 win7,只能安装 node 14 以下,而 spug 的文档项目采用的是 Facebook ...
- Ubuntu 20.04下源码编译安装ROS 2 Foxy Fitzroy
ROS 2 Foxy Fitzroy(以下简称Foxy)于2020年6月5日正式发布了,是LTS版本,支持到2023年5月.本文主要根据官方的编译安装教程[1]完成,并记录编译过程中遇到的问题. 1. ...
- win10 + Ubuntu 20.04 LTS 双系统 引导界面美化
版权声明:本文为CSDN博主「ZChen1996」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明. 原文链接:https://blog.csdn.net/ZChen1 ...
- Windows10 + Ubuntu 20.04 LTS 双系统安装 (UEFI + GPT)(图文,多图预警)
版权声明:本文为CSDN博主「ZChen1996」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明. 原文链接:https://blog.csdn.net/ZChen1 ...
- Ubuntu 20.04.1 安装软件和系统配置脚本
#!/bin/bash # https://launchpad.net/ubuntu # https://www.easyicon.net # https://download-chromium.ap ...
- Ubuntu 20.04 手动安装 sublime_text 并建立搜索栏图标(解决 Ubuntu 20.04 桌面图标无法双击打开问题)
下载sublime_text_3离线程序包 wget https://download.sublimetext.com/sublime_text_3_build_3211_x64.tar.bz2 #x ...
- Ubuntu 20.04上通过Wine 安装微信
没有想过会在一个手机软件上花这么多心思,好在今天总算安装成功,觉得可以记录下这个过程,方便他人方便自己. 首先介绍下我使用过的其他方法,希望可以节省大家一些时间: Rambox Pro:因为原理是网页 ...
随机推荐
- 使用yum快速安装mysql-5.7(用于测试)
1)CentOS 7 下安装 MySQL 5.7 下载并安装MySQL官方的 Yum Repository [wget -i -c http://dev.mysql.com/get/mysql57-c ...
- .NET CORE-通过内置IOC容器IServiceCollection进行服务注册
第一种方式: 在Startup中的ConfigureServices方法中注册服务: services.AddTransient<ITestServiceA, TestServiceA>( ...
- ECDSA签名验证
using System; using System.IO; using System.Text; using Org.BouncyCastle.Crypto; using Org.BouncyCas ...
- Spark 中三种数据处理对象的区别: RDD-Dataset-Dataframe
1,对比表: RDD Dataframe Dataset 版本 1.0 1.3 1.6 描述 分布式数据集合 行列化的分布式数据集合 RDD 和 DataFrame的结合 数据格式 结构化和非结 ...
- centos7.8 安装 redis5.0.2
1.安装gcc依赖 redis是由C语言开发,因此安装之前必须要确保服务器已经安装了gcc,可以通过如下命令查看机器是否安装: gcc -v 如果没有安装则通过以下命令安装: yum install ...
- 各种工具点评以供选择使用 + 开发工具秘籍(git, webpack。。。。)
git最佳实践: https://gist.github.com/fandean/ca29cd2f326f66c659951d7ab356cefb ========================== ...
- php实现无限极分类
1.无限极分类 //处理父子级 private function getChildBak($data,$parent_id = 0){ $arr=array(); $i = 0; foreach($d ...
- 计算机科学导论-第三版-学习笔记-chapter2-数字系统
原本看答案的网站被上保护了,我没账号看不了,开摆. 猜测是那边的学生做作业用chatGPT,部分教师觉得不行,禁止使用的同时把答案都上锁了. 也可能是单纯因为我没报课就没账号. 复习题 1.定义一个数 ...
- DELL服务器升级BIOS,做RAID磁盘阵列
dell服务器BIOS升级.LSI集成整列卡驱动安装 1.下载启动盘rufus,安装linux系统到U盘 1.准备两个U盘,插入启动U盘进入系统,进入centos7选择页面,插入另一个U盘用于安装li ...
- NDK 减少 so 库体积方法总结
. 使用 strip 使用 NDK toolchain 可以把调试的 C++ 符号表(Symbol Table)中数据删除,我们一般我们打成 APK 会自动帮我们做这个工作,当然也可以手动设置: 手动 ...