带你读AI论文丨针对文字识别的多模态半监督方法
摘要:本文提出了一种针对文字识别的多模态半监督方法,具体来说,作者首先使用teacher-student网络进行半监督学习,然后在视觉、语义以及视觉和语义的融合特征上,都进行了一致性约束。
本文分享自华为云社区《一种针对文字识别的多模态半监督方法》,作者: Hint 。

摘要
直到最近,公开的真实场景文本图像的数量仍然不足以训练场景文本识别器。因此,当前大多数的训练方法都依赖于合成数据并以全监督的方式运行。然而,最近公开的真实场景文本图像的数量显着增加,包括大量未标记的数据。利用这些资源需要半监督方法;然而,这些方法不能直接适配文字识别这类视觉语言的多模态结构。因此,本文提出了半监督多模态文本识别器(SemiMTR),它在训练阶段中,利用每个模态的未标记数据。此外,本文的方法并不需要额外的训练阶段,保持了当前的三阶段多模态训练策略。
首先,在视觉模型方面,本文提出了一个将自监督预训练和强监督训练结合的单阶段训练模型。然后,语言模型是在一个大型文本语料库上进行自监督预训练。得到两个模态的预训练模型之后,对文字识别进行半监督训练。本文采用的是teacher-student的结构,具体来说,对一张文本图像分别进行弱数据扩增和强数据扩增,然后对两个网络不同模态的输出进行一致性约束。大量实验证实本文的方法优于当前的训练方案,并在多个场景文本识别基准上取得了最先进的结果。
方法
1. 识别模型框架:
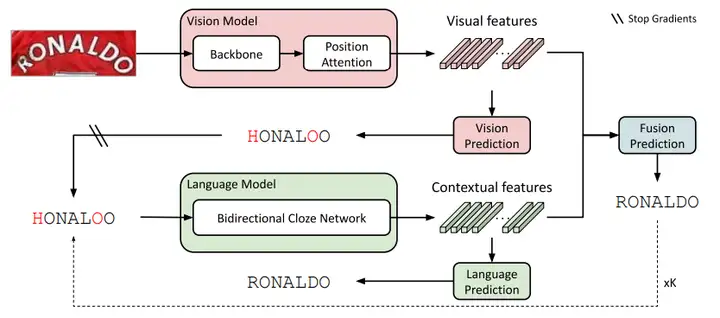
首先,本文的文字识别框架采用的是ABINet。大致流程如下:首先,视觉模型首先提取图像的特征序列并将其解码成字符序列;接着,将字符序列输入给语言模型,得到文本的语义特征;最后,使用一个融合模块,将视觉和语义特征进行融合,得到最终的识别结果。为了进一步提高识别性能,可以采用迭代的方式,多次对识别结果进行微调。
2. 视觉模型预训练
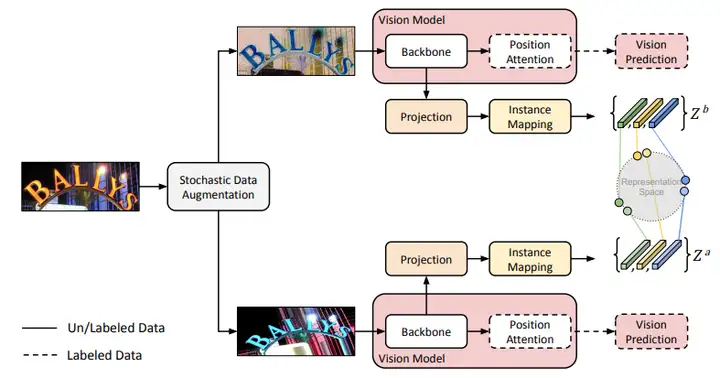
本文将自监督预训练与强监督预训练融合到了一个统一的框架下。自监督预训练采用的是基于对比学习的方法,在自监督的同时,也会对这些数据进行有标注的强监督预训练。
3. 基于一致性约束的半监督训练
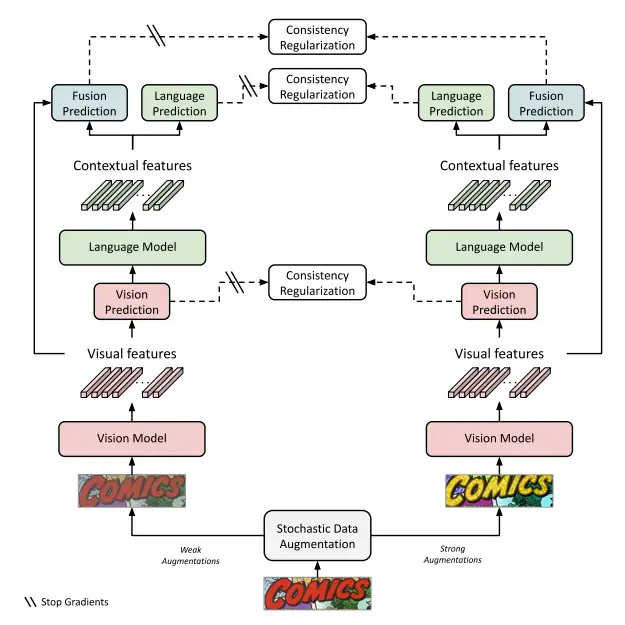
首先,本文采用的是一个常见的teacher-student网络,进行半监督训练。具体来说,将前面得到的预训练模型作为teacher和student网络的初始化模型,然后对同一张输入图像进行弱数据扩增和强数据扩增,并分别输入到teacher和student网络中;将teacher网络的预测结果作为伪标签对student的输出进行监督。区别于一般的半监督学习,本文的方法对识别模型的各个模态都进行不同程度的一致性约束,比如视觉模型,语言模型和融合模型的输出。
实验
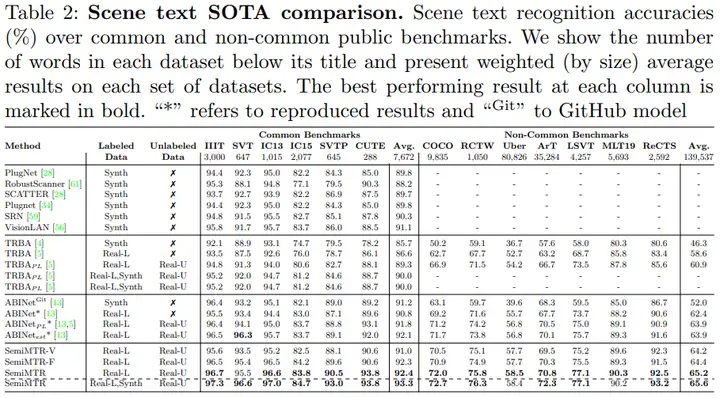
可以看到,本文的结果在多个数据集上取得了一致性的提升。

可以看到,在视觉预训练阶段,统一自监督预训练和强监督预训练比分阶段的训练效果要好。
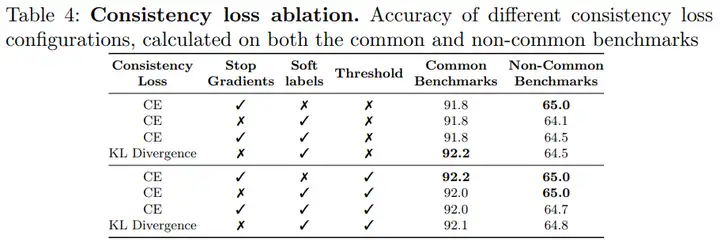
可以看到,使用交叉熵loss作为一致性约束loss效果最好。
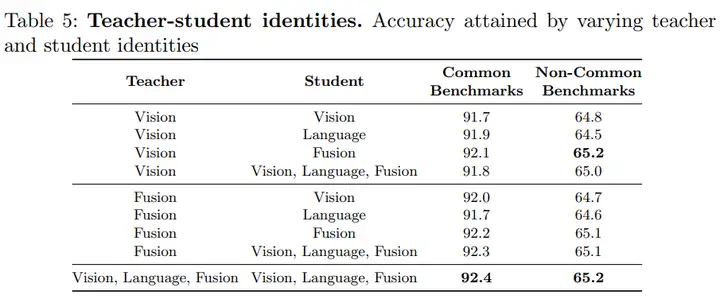
由于本文采用的识别模型,具有视觉、语言和融合的模态,所以在进行一致性约束的时候,teacher网络和student网络可以采用不同的特征分别进行对齐。从上表可以看到,当teacher和student网络中的vision,language和fusion模块分别进行对齐的时候,效果最好。
论文链接:[2205.03873] Multimodal Semi-Supervised Learning for Text Recognition (arxiv.org)
带你读AI论文丨针对文字识别的多模态半监督方法的更多相关文章
- 带你读AI论文丨ACGAN-动漫头像生成
摘要:ACGAN-动漫头像生成是一个十分优秀的开源项目. 本文分享自华为云社区<[云驻共创]AI论文精读会:ACGAN-动漫头像生成>,作者:SpiderMan. 1.论文及算法介绍 1. ...
- 带你读AI论文丨用于目标检测的高斯检测框与ProbIoU
摘要:本文解读了<Gaussian Bounding Boxes and Probabilistic Intersection-over-Union for Object Detection&g ...
- 带你读AI论文丨RAID2020 Cyber Threat Intelligence Modeling GCN
摘要:本文提出了基于异构信息网络(HIN, Heterogeneous Information Network)的网络威胁情报框架--HINTI,旨在建模异构IOCs之间的相互依赖关系,以量化其相关性 ...
- 带你读AI论文丨LaneNet基于实体分割的端到端车道线检测
摘要:LaneNet是一种端到端的车道线检测方法,包含 LanNet + H-Net 两个网络模型. 本文分享自华为云社区<[论文解读]LaneNet基于实体分割的端到端车道线检测>,作者 ...
- 带你读AI论文:NDSS2020 UNICORN: Runtime Provenance-Based Detector
摘要:这篇文章将详细介绍NDSS2020的<UNICORN: Runtime Provenance-Based Detector for Advanced Persistent Threats& ...
- 我的AI之路 —— OCR文字识别快速体验版
OCR的全称是Optical Character Recoginition,光学字符识别技术.目前应用于各个领域方向,甚至这些应用就在我们的身边,比如身份证的识别.交通路牌的识别.车牌的自动识别等等. ...
- 给OCR文字识别软件添加图像的方法
ABBYY FineReader 12是一款OCR图片文字识别软件,而且强大的它现在还可使用快速扫描窗口中的快速打开.扫描并保存为图像或任务自动化任务,在没有进行预处理和OCR的ABBYY FineR ...
- PHP百度AI的OCR图片文字识别
第一步可定要获取百度的三个东西 要到百度AI网站(http://ai.baidu.com/)去注册 然后获得 -const APP_ID = '请填写你的appid'; -const API_KEY ...
- 如何精准实现OCR文字识别?
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由云计算基础发表于云+社区专栏 前言 2018年3月27日腾讯云云+社区联合腾讯云智能图像团队共同在客户群举办了腾讯云OCR文字识别-- ...
- 百度OCR 文字识别 Android安全校验
百度OCR接口使用总结: 之前总结一下关于百度OCR文字识别接口的使用步骤(Android版本 不带包名配置 安全性弱).这边博客主要介绍,百度OCR文字识别接口,官方推荐使用方式,授权文件(安全模式 ...
随机推荐
- 我的 Kafka 旅程 - 文件存储机制
存储机制 Topic在每个Broker下存储所属的Partition,Partition下由 Index.Log 两类文件组成. 写入 Log 由多个Segment文件组成,每个Segment文件容量 ...
- [题解] Atcoder ABC 225 H Social Distance 2 生成函数,分治FFT
题目 首先还没有安排座位的\(m-k\)个人之间是有顺序的,所以先把答案乘上\((m-k)!\),就可以把这些人看作不可区分的. 已经确定的k个人把所有座位分成了k+1段.对于第i段,如果我们能求出这 ...
- POJ2686 Traveling by Stagecoach (状压DP)
将车票的使用情况用二进制表示状态,对其进行转移即可. 但是我一开始写的代码是错误的(注释部分),看似思路是正确的,但是暗藏很大的问题. 枚举S,我们要求解的是dp[S][v],这个是从u转移过来的,不 ...
- 学习ASP.NET Core Blazor编程系列六——新增图书(上)
学习ASP.NET Core Blazor编程系列一--综述 学习ASP.NET Core Blazor编程系列二--第一个Blazor应用程序(上) 学习ASP.NET Core Blazor编程系 ...
- 前端框架Vue------>第一天学习(3)
文章目录 8 .使用Axios实现异步通信 9 .表单输入绑定 9.1 . 什么是双向数据绑定 9.2 .为什么要实现数据的双向绑定 9.3 .在表单中使用双向数据绑定 8 .使用Axios实现异步通 ...
- go-zero docker-compose 搭建课件服务(一):编写服务api和proto
0.转载 go-zero docker-compose 搭建课件服务(一):编写服务api和proto 0.1源码地址 https://github.com/liuyuede123/go-zero-c ...
- 记一次 .NET 某医疗器械 程序崩溃分析
一:背景 1.讲故事 前段时间有位朋友在微信上找到我,说他的程序偶发性崩溃,让我帮忙看下怎么回事,上面给的压力比较大,对于这种偶发性崩溃,比较好的办法就是利用 AEDebug 在程序崩溃的时候自动抽一 ...
- 4.httprunner-参数化和数据驱动
前言 参数化在config中使用parameters关键字 httprunner2.x 是在testsuite中实现参数化 httprunner3.x 是在testcase中的config实现参数化 ...
- Dapr实现.Net Grpc服务之间的发布和订阅,并采用WebApi类似的事件订阅方式
大家好,我是失业在家,正在找工作的博主Jerry,找工作之余,总结和整理以前的项目经验,动手写了个洋葱架构(整洁架构)示例解决方案 OnionArch.其目的是为了更好的实现基于DDD(领域驱动分析) ...
- 文盘Rust -- 把程序作为守护进程启动
当我们写完一个服务端程序,需要上线部署的时候,或多或少都会和操作系统的守护进程打交道,毕竟谁也不希望shell关闭既停服.今天我们就来聊聊这个事儿. 最早大家部署应用的通常操作是 "nohu ...