4月18日 python学习总结 异常处理、网络编程
一、 异常
1、什么是异常
异常是错误发生的信号,程序一旦出错,如果程序中还没有相应的处理机制
那么该错误就会产生一个异常抛出来,程序的运行也随之终止
2、一个异常分为三部分:
1、异常的追踪信息
2、异常的类型
3、异常的值
3、异常的分类:
1、语法异常:
这类异常应该在程序执行前就改正
print('start....')
x=1
x+=1
if
print('stop....')
2、逻辑上的异常
#TypeError:int类型不可迭代
for i in 3:
pass
#ValueError
num=input(">>: ") #输入hello
int(num) #NameError
aaa #IndexError
l=['egon','aa']
l[3] #KeyError
dic={'name':'egon'}
dic['age'] #AttributeError
class Foo:pass
Foo.x #ZeroDivisionError:无法完成计算
res1=1/0
res2=1+'str' 2.逻辑错误
3、常用异常
AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x
IOError 输入/输出异常;基本上是无法打开文件
ImportError 无法引入模块或包;基本上是路径问题或名称错误
IndentationError 语法错误(的子类) ;代码没有正确对齐
IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5]
KeyError 试图访问字典里不存在的键
KeyboardInterrupt Ctrl+C被按下
NameError 使用一个还未被赋予对象的变量
SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了)
TypeError 传入对象类型与要求的不符合
UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,
导致你以为正在访问它
ValueError 传入一个调用者不期望的值,即使值的类型是正确的 常用异常
# IndexError
# l=['a','b']
# l[100] # KeyError
# d={'a':1}
# d['b'] # AttributeError:
# class Foo:
# pass
#
# Foo.x
# import os
# os.aaa # ZeroDivisionError
# 1 / 0 # FileNotFoundError
# f=open('a.txt','r',encoding='utf-8') # ValueError: I/O operation on closed file.
# f=open('a.txt','r',encoding='utf-8')
# f.close()
# f.readline() #ValueError: invalid literal for int() with base 10: 'aaaaa'
# int('aaaaa') # TypeError
# for i in 333:
# pass #NameError
# x
# func()
二、异常处理
为了保证程序的健壮性与容错性,即在遇到错误时程序不会崩溃,我们需要对异常进行处理,
如果错误发生的条件是可预知的,我们需要用if进行处理:在错误发生之前进行预防
AGE=10
while True:
age=input('>>: ').strip()
if age.isdigit(): #只有在age为字符串形式的整数时,下列代码才不会出错,该条件是可预知的
age=int(age)
if age == AGE:
print('you got it')
break
如果错误发生的条件是不可预知的,则需要用到try...except:在错误发生之后进行处理
语法:
try: ... #此处运行到抛出异常的地方,后续代码不继续执行 except ErrorType: # (匹配异常类型,若遇到与except 后的异常类型 一致的异常,则捕捉住,程序不会崩溃报错。可以有多个except,也可以联合使用) .... else: ... #(只有当程序没有异常的时候才运行else代码) finally: ... #(不论程序是否有异常,一定执行该代码。一般用于释放代码块内打开的资源)
1、单分支
#单分支
try:
print('start.....')
x=1
y
l=[]
l[3]
d={'a':1}
d['b']
print('end....')
except NameError:
print('变量名没有定义') print('other.....')
2、多分支
多分支
try:
print('start.....')
x=1
# y
l=[]
l[3]
d={'a':1}
d['b']
print('end....')
except NameError:
print('变量名没有定义')
except KeyError:
print('字典的key不存在')
except IndexError:
print('索引超出列表的范围') print('other.....')
3、多种异常采用同一段逻辑处理
多种异常采用同一段逻辑处理
try:
print('start.....')
x=1
# y
l=[]
# l[3]
d={'a':1}
d['b']
print('end....')
except (NameError,KeyError,IndexError):
print('变量名或者字典的key或者列表的索引有问题') print('other.....')
4、万能异常和获取异常的值
万能异常
try:
print('start.....')
x=1
# y
l=[]
# l[3]
d={'a':1}
# d['b']
import os
os.aaa
print('end....')
except Exception:
print('万能异常---》') print('other.....') 获取异常的值
try:
print('start.....')
x=1
y
l=[]
l[3]
d={'a':1}
d['b']
import os
os.aaa
print('end....')
except Exception as e:
print('万能异常---》',e) print('other.....')
5、try....else...
else: 不能单独使用,必须与except连用,意思是:else的子代码块会在被检测的代码没有出现过任何异常的情况下执行
try....else...
else: 不能单独使用,必须与except连用,意思是:else的子代码块会在被检测的代码没有出现过任何异常的情况下执行 try:
print('start.....')
# x=1
# # y
# l=[]
# l[3]
# d={'a':1}
# d['b']
# import os
# os.aaa
print('end....')
except NameError as e:
print('NameError: ',e) except KeyError as e:
print('KeyError: ',e) except Exception as e:
print('万能异常---》',e) else:
print('在被检测的代码块没有出现任何异常的情况下执行')
print('other.....')
6、try...finally....
无论有没有异常发生,都会执行
try...finally....
try:
print('start.....')
# x=1
# # y
# l=[]
# l[3]
# d={'a':1}
# d['b']
# import os
# os.aaa
print('end....')
except NameError as e:
print('NameError: ',e) except KeyError as e:
print('KeyError: ',e) except Exception as e:
print('万能异常---》',e) else:
print('在被检测的代码块没有出现任何异常的情况下执行')
finally:
print('无论有没有异常发生,都会执行')
print('other.....') finally的子代码块中通常放回收系统资源的代码
try:
f=open('a.txt',mode='w',encoding='utf-8')
f.readline() finally:
f.close() print('other....')
7、主动触发异常
raise TypeError('类型错误')
class People:
def __init__(self,name):
if not isinstance(name,str):
raise TypeError('%s 必须是str类型' %name)
self.name=name
p=People(123)
8、断言
python assert断言是声明其布尔值必须为真的判定,如果发生异常就说明表达示为假。
可以理解assert断言语句为raise-if-not,用来测试表示式,其返回值为假,就会触发异常。
assert语句用来声明某个条件是真的。
如果你非常确信某个你使用的列表中至少有一个元素,而你想要检验这一点,并且在它非真的时候引发一个错误,那么assert语句是应用在这种情形下的理想语句。
当assert语句失败的时候,会引发一AssertionError。
print('part1........')
stus=['egon','alex','wxx','lxx']
# stus=[]
#if len(stus) <= 0:
# raise TypeError
assert len(stus) < 0
print('part2.........')
print('part2.........')
print('part2.........')
print('part2.........')
print('part2.........')
print('part2.........')
Traceback (most recent call last):
File "F:/python/object/days2/days24/异常处理.py", line 23, in <module>
assert len(stus) < 0
AssertionError
9、自定义异常
class RegisterError(BaseException):
def __init__(self,msg,user):
self.msg=msg
self.user=user def __str__(self):
return '<%s:%s>' %(self.user,self.msg) raise RegisterError('注册失败','teacher')
三、网络编程
1、C/S、B/S架构
B/S(Browser/Server)结 构, 即 浏 览 器 和 服 务 器 结 构。
C/S (Client/Server)结构,即 客 户 机 和 服 务 器 结 构
学习socket编程就是要编写一个客户端软件和服务端软件,然后实现服务端与客户端基于网络通信
2、什么是网络?
1、物理连接介质
2、互联网协议
互联网协议就是一堆标准。 比喻:互联网协议就是计算机界的英语
互联网协议
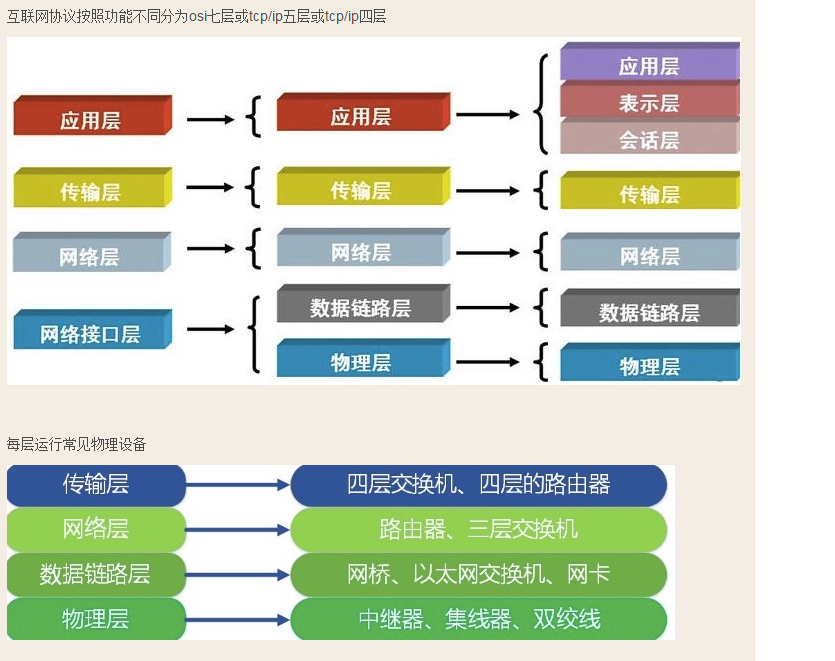
详见网络通信原理:http://www.cnblogs.com/linhaifeng/articles/5937962.html
tcp/ip五层模型讲解
我们将应用层,表示层,会话层并作应用层,从tcp/ip五层协议的角度来阐述每层的由来与功能,搞清楚了每层的主要协议
就理解了整个互联网通信的原理。
首先,用户感知到的只是最上面一层应用层,自上而下每层都依赖于下一层,所以我们从最下一层开始切入,比较好理解
每层都运行特定的协议,越往上越靠近用户,越往下越靠近硬件
物理层:
物理层功能:主要是基于电器特性发送高低电压(电信号),高电压对应数字1,低电压对应数字0
数据链路层:
数据链路层由来:单纯的电信号0和1没有任何意义,必须规定电信号多少位一组,每组什么意思
数据链路层的功能:定义了电信号的分组方式
以太网协议:
早期的时候各个公司都有自己的分组方式,后来形成了统一的标准,即以太网协议ethernet
ethernet规定
- 一组电信号构成一个数据报,叫做‘帧’
- 每一数据帧分成:报头head和数据data两部分
| head | data |
head包含:(固定18个字节)
- 发送者/源地址,6个字节
- 接收者/目标地址,6个字节
- 数据类型,6个字节
data包含:(最短46字节,最长1500字节)
- 数据包的具体内容
head长度+data长度=最短64字节,最长1518字节,超过最大限制就分片发送
mac地址:
head中包含的源和目标地址由来:ethernet规定接入internet的设备都必须具备网卡,发送端和接收端的地址便是指网卡的地址,即mac地址
mac地址:每块网卡出厂时都被烧制上一个世界唯一的mac地址,长度为48位2进制,通常由12位16进制数表示(前六位是厂商编号,后六位是流水线号)
网络层由来:有了ethernet、mac地址、广播的发送方式,世界上的计算机就可以彼此通信了,问题是世界范围的互联网是由
一个个彼此隔离的小的局域网组成的,那么如果所有的通信都采用以太网的广播方式,那么一台机器发送的包全世界都会收到,
这就不仅仅是效率低的问题了,这会是一种灾难
IP协议、IP数据包、ARP协议
传输层:
TCP/UDP
传输层的由来:网络层的ip帮我们区分子网,以太网层的mac帮我们找到主机,然后大家使用的都是应用程序,你的电脑上可能同时开启qq,暴风影音,等多个应用程序,
那么我们通过ip和mac找到了一台特定的主机,如何标识这台主机上的应用程序,答案就是端口,端口即应用程序与网卡关联的编号。
传输层功能:建立端口到端口的通信
补充:端口范围0-65535,0-1023为系统占用端口
tcp协议:
可靠传输,TCP数据包没有长度限制,理论上可以无限长,但是为了保证网络的效率,通常TCP数据包的长度不会超过IP数据包的长度,以确保单个TCP数据包不必再分割。
| 以太网头 | ip 头 | tcp头 | 数据 |
udp协议:
不可靠传输,”报头”部分一共只有8个字节,总长度不超过65,535字节,正好放进一个IP数据包。
| 以太网头 | ip头 | udp头 | 数据 |
为何学习socket一定要先学习互联网协议:
1.首先:本节课程的目标就是教会你如何基于socket编程,来开发一款自己的C/S架构软件
2.其次:C/S架构的软件(软件属于应用层)是基于网络进行通信的
3.然后:网络的核心即一堆协议,协议即标准,你想开发一款基于网络通信的软件,就必须遵循这些标准。
4.最后:就让我们从这些标准开始研究,开启我们的socket编程之旅
socket是什么
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
所以,我们无需深入理解tcp/udp协议,socket已经为我们封装好了,我们只需要遵循socket的规定去编程,写出的程序自然就是遵循tcp/udp标准的。
也有人将socket说成ip+port,ip是用来标识互联网中的一台主机的位置,而port是用来标识这台机器上的一个应用程序,ip地址是配置到网卡上的,而port是应用程序开启的,ip与port的绑定就标识了互联网中独一无二的一个应用程序 而程序的pid是同一台机器上不同进程或者线程的标识
套接字发展史及分类
套接字起源于 20 世纪 70 年代加利福尼亚大学伯克利分校版本的 Unix,即人们所说的 BSD Unix。 因此,有时人们也把套接字称为“伯克利套接字”或“BSD 套接字”。一开始,套接字被设计用在同 一台主机上多个应用程序之间的通讯。这也被称进程间通讯,或 IPC。套接字有两种(或者称为有两个种族),分别是基于文件型的和基于网络型的。
基于文件类型的套接字家族
套接字家族的名字:AF_UNIX
unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信
基于网络类型的套接字家族
套接字家族的名字:AF_INET
(还有AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,或者是根本没有实现,所有地址家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以大部分时候我么只使用AF_INET)
4月18日 python学习总结 异常处理、网络编程的更多相关文章
- python学习之路网络编程篇(第四篇)
python学习之路网络编程篇(第四篇) 内容待补充
- 4月2日 python学习总结
昨天内容回顾: 1.迭代器 可迭代对象: 只要内置有__iter__方法的都是可迭代的对象 既有__iter__,又有__next__方法 调用__iter__方法==>得到内置的迭代器对象 调 ...
- 4月12日 python学习总结 继承和派生
一.继承 什么是继承: 继承是一种新建类的方式,在python中支持一个子类继承多个父类 新建类称为子类或派生类 父类可以称之为基类或者超类 子类会遗传父类的属性 2. 为什么继承 ...
- 4月11日 python学习总结 对象与类
1.类的定义 #类的定义 class 类名: 属性='xxx' def __init__(self): self.name='enon' self.age=18 def other_func: pas ...
- 4月8日 python学习总结 模块与包
一.包 #官网解释 Packages are a way of structuring Python's module namespace by using "dotted module n ...
- python学习笔记11 ----网络编程
网络编程 网络编程需要知道的概念 网络体系结构就是使用这些用不同媒介连接起来的不同设备和网络系统在不同的应用环境下实现互操作性,并满足各种业务需求的一种粘合剂.网络体系结构解决互质性问题彩是分层方法. ...
- python学习之路网络编程篇(第二篇)
新课程知识的引入:python作用域 #python中无块级别作用域 if 1 == 1 : name = 'alex' print(name) for i in range(10): name = ...
- python学习笔记10 ----网络编程
网络编程 网络编程需要知道的概念 网络体系结构就是使用这些用不同媒介连接起来的不同设备和网络系统在不同的应用环境下实现互操作性,并满足各种业务需求的一种粘合剂.网络体系结构解决互质性问题彩是分层方法. ...
- Python学习之==>Socket网络编程
一.计算机网络 多台独立的计算机通过网络通信设备连接起来的网络.实现资源共享和数据传递.在同一台电脑上可以将D盘上的一个文件传到C盘,但如果想从一台电脑传一个文件到另外一台电脑上就要通过计算机网络 二 ...
随机推荐
- 《PHP程序员面试笔试宝典》——如何回答系统设计题?
如何巧妙地回答面试官的问题? 本文摘自<PHP程序员面试笔试宝典> 应届生在面试时,偶尔也会遇到一些系统设计题,而这些题目往往只是测试求职者的知识面,或者测试求职者对系统架构方面的了解,一 ...
- Lesson11——Pandas去重函数:drop_duplicates()
pandas目录 "去重"通过字面意思不难理解,就是删除重复的数据.在一个数据集中,找出重复的数据删并将其删除,最终只保存一个唯一存在的数据项,这就是数据去重的整个过程.删除重复数 ...
- 搭建sock5代理
安装 下载脚本 wget --no-check-certificate https://raw.github.com/Lozy/danted/master/install.sh -O install. ...
- css文字超出指定行数显示省略号
display: -webkit-box; overflow: hidden; word-break: break-all; /* break-all(允许在单词内换行.) */ text-overf ...
- 图片隐写之Image Steganography软件的使用
CTF_论剑场 MISC 坏掉的图像 writeup 把图片丢进winhex里,发现头部的 0D 1A 0A 1A是不正确的,正确的应该为 0D 0A 1A 0A,所以需要更改. 更改完成后打开图片可 ...
- [theHunterCOTW] 猎人荒野的召唤-一点资料
游戏介绍 购买建议 [2020-12-17] theHunter 现在有三个捆绑包 2019 Edition,2021 Edition,Complete Collection 单独购买,目前steam ...
- c# 编程学习(四)
逻辑AND(逻辑与)操作符(用&&表示)和逻辑OR(逻辑或) 操作符(用||表示).这两个操作符统称条件逻辑操作符.只有作为操作数的两个布尔表达式都为 true.操作符&&am ...
- 【C#】String| StringBuilder 字符
原文链接:https://www.cnblogs.com/huameitang/p/10528646.html 字符串是用于表示文本的字符的有序集合. String对象是对象的有序集合 System. ...
- 第九周shell脚本编程练习
转至:http://www.178linux.com/88838 1.写一个脚本,判断当前系统上所有用户的shell是否为可登录shell(即用户的shell不是/sbin/nologin):分别这两 ...
- 安卓Java主页面的编写
1 package com.example.first; 2 3 import androidx.appcompat.app.AppCompatActivity; 4 5 import android ...