Android 12(S) 图像显示系统 - GraphicBuffer同步机制 - Fence
必读:
Android 12(S) 图像显示系统 - 开篇
一、前言
前面的文章中讲解Android BufferQueue的机制时,有遇到过Fence,但没有具体讲解。这篇文章,就针对Fence这种同步机制,做一些介绍。
Fence在Android图像显示系统中用于GraphicBuffer的同步。我们不禁有疑问:那它和其它的同步机制相比有什么特点呢?
Fence主要被用来处理跨硬件的情况,在我们关注的Android图像显示系统中即处理CPU,GPU和HWC之间的数据同步。
二、Fence的基本作用
在Android BufferQueue的机制中,GraphicBuffer在生产者--图形缓冲队列--消费者之间流转。每一个GraphicBuffer都有一个对应的BufferState标记其状态,详细可以参考:Android 12(S) 图像显示系统 - BufferQueue的工作流程(八)
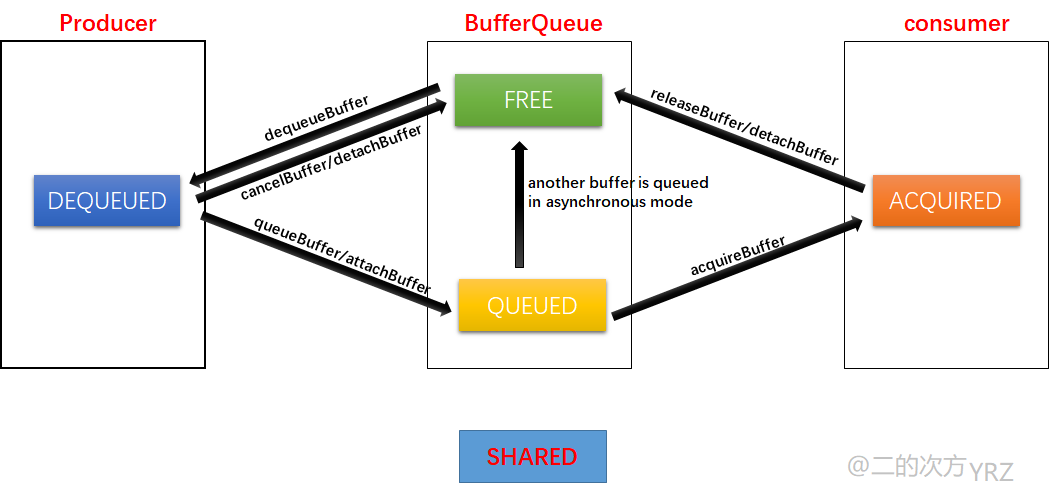
本文作者@二的次方 2022-05-20发布于博客园
通常这里的BufferState代表的仅仅是GraphicBuffer的所有权,即此刻它归谁所拥有;但这块缓存是否可以被所有者使用还需要等待同步信号到来,即使用权要等到相关的Fence信号发出才可获得。
在BufferState的各种状态的定义的解释中可以看到:
[/frameworks/native/libs/gui/include/gui/BufferSlot.h]
// DEQUEUED indicates that the buffer has been dequeued by the producer, but
// has not yet been queued or canceled. The producer may modify the
// buffer's contents as soon as the associated release fence is signaled.
// The slot is "owned" by the producer.
// QUEUED indicates that the buffer has been filled by the producer and
// queued for use by the consumer. The buffer contents may continue to be
// modified for a finite time, so the contents must not be accessed until
// the associated fence is signaled. The slot is "owned" by BufferQueue.
// ACQUIRED indicates that the buffer has been acquired by the consumer. As
// with QUEUED, the contents must not be accessed by the consumer until the
// acquire fence is signaled. The slot is "owned" by the consumer. DEQUEUED状态时,虽然GraphicBuffer被生产者拥有,但直到和这块缓存相关的release fence同步信号发出后,生产者才能修改GraphicBuffer的内容;
QUEUED状态时,虽然GraphicBuffer已经入队列被BufferQueue持有,但直到和这块缓存相关的fence同步信号发出前,生产者仍可能修改GraphicBuffer的内容,也即fence同步信号发出后,才能去访问其内容;
ACQUIRED状态时,虽然GraphicBuffer被生产者拥有,但是直到acquire fence同步信号发出后,消费者才可去消费缓存中的数据;
为什么要把所有权和使用权分开呢?
主要还是CPU、GPU这种跨硬件编程同步处理的需要。GPU编程和纯CPU编程有一个很大的不同就是它是异步的,也就是说当我们调用GL command返回时这条命令并不一定真正执行完成了,只是把这个命令放在本地的command buffer里。具体什么时候这条GL command被真正执行完毕CPU是不知道的,除非CPU使用glFinish()等待这些命令执行完,另外一种方法就是基于同步对象的Fence机制。
而和GraphicBuffer相对应的BufferState状态一定程度上说明了该GraphicBuffer的归属,但只指示了CPU里的状态,而GraphicBuffer的真正使用者一般是GPU。比如当生产者把一个GraphicBuffer放入BufferQueue时,只是在CPU层面完成了归属的转移。但GPU说不定还在用,如果还在用的话消费者是不能拿去合成的。这时候GraphicBuffer和生产消费者的关系就比较暧昧了,消费者对GraphicBuffer具有拥有权,但无使用权,它需要等一个信号,告诉它GPU用完了,消费者才真正拥有使用权。
一个简化的模型如下: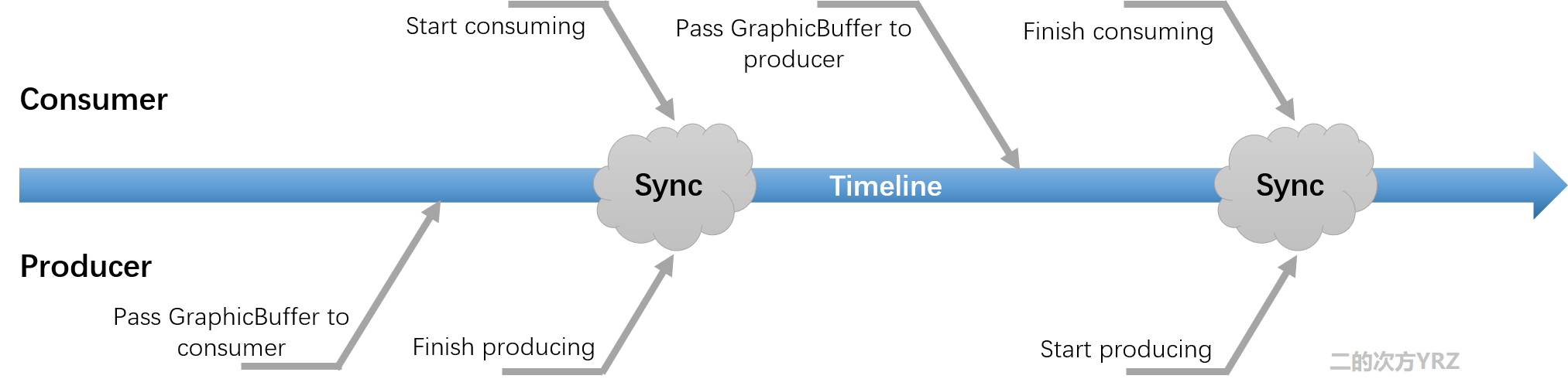
GraphicBuffer由一个使用者传递到下一个使用者,并通过Fence信号告知新的使用者什么时候可以开始使用它。Fence的存在非常单纯,从诞生开始就是为了在合适的时间发出一个信号。
另一个角度来说,为什么不在生产者把GraphicBuffer交给消费者时就调用glFinish()等GPU完成呢?这样拥有权和使用权就一并传递了,无需Fence。就功能上这样做是可以的,但性能会有影响,因为glFinish()是阻塞的,这时CPU为了等GPU自己也不能工作了。如果用Fence的话就可以等这个GraphicBuffer真正要被消费者用到时再阻塞,而那之前CPU和GPU是可以并行工作的。这样相当于实现了临界资源的lazy passing。
本文作者@二的次方 2022-05-20发布于博客园
三、简单介绍Fence的实现
Fence,顾名思义就是把先到的拦住,等后来的,两者步调一致了再往前走。抽象地说,Fence包含了同一或不同时间轴上的多个时间点,只有当这些点同时到达时Fence才会被触发。
更详细的介绍可以参考这篇文章Android Synchronization Fences – An Introduction
Fence可以由硬件实现(Graphic driver),也可以由软件实现(Android kernel中的sw_sync)。EGL中提供了同步对象的扩展KHR_fence_sync。其中提供了eglCreateSyncKHR (),eglDestroySyncKHR()产生和销毁同步对象。这个同步对象是往GL command队列中插入的一个特殊操作,当执行到它时,会发出信号指示队列前面的命令已全部执行完毕。函数eglClientWaitSyncKHR()可让调用者阻塞等待信号发生。
在此基础之上,Android对其进行了扩展 --- ANDROID_native_fence_sync ,新加了接口eglDupNativeFenceFDANDROID()。它可以把一个同步对象转化为一个文件描述符(反过来,eglCreateSyncKHR()可以把文件描述符转成同步对象)。这个扩展相当于让CPU中有了GPU中同步对象的句柄,文件描述符可以在进程间传递(通过Binder等IPC机制),这就为多进程间的同步提供了基础。我们知道Unix系统一切皆文件,因此,有个这个扩展以后Fence的通用性大大增强了。
Android还进一步丰富了Fence的software stack。主要分布在三部分:
- C++ Fence类位于/frameworks/native/libs/ui/Fence.cpp;
- C的libsync库位于/system/core/libsync/sync.c;
- Kernel driver部分
总得来说,kernel driver部分是同步的主要实现,libsync是对driver接口的封装,Fence是对libsync的进一步的C++封装。Fence会被作为GraphicBuffer的附属随着GraphicBuffer在生产者和消费间传输。另外Fence的软件实现位于/drivers/base/sw_sync.c。SyncFeatures用以查询系统支持的同步机制:/frameworks/native/libs/gui/SyncFeatures.cpp。
四、Fence在Android图像显示系统的具体用法
Fence的主要作用就是保证GraphicBuffer在App, GPU和HWC三者间流转时的数据读写同步(不同进程 or 不同硬件间的同步)。
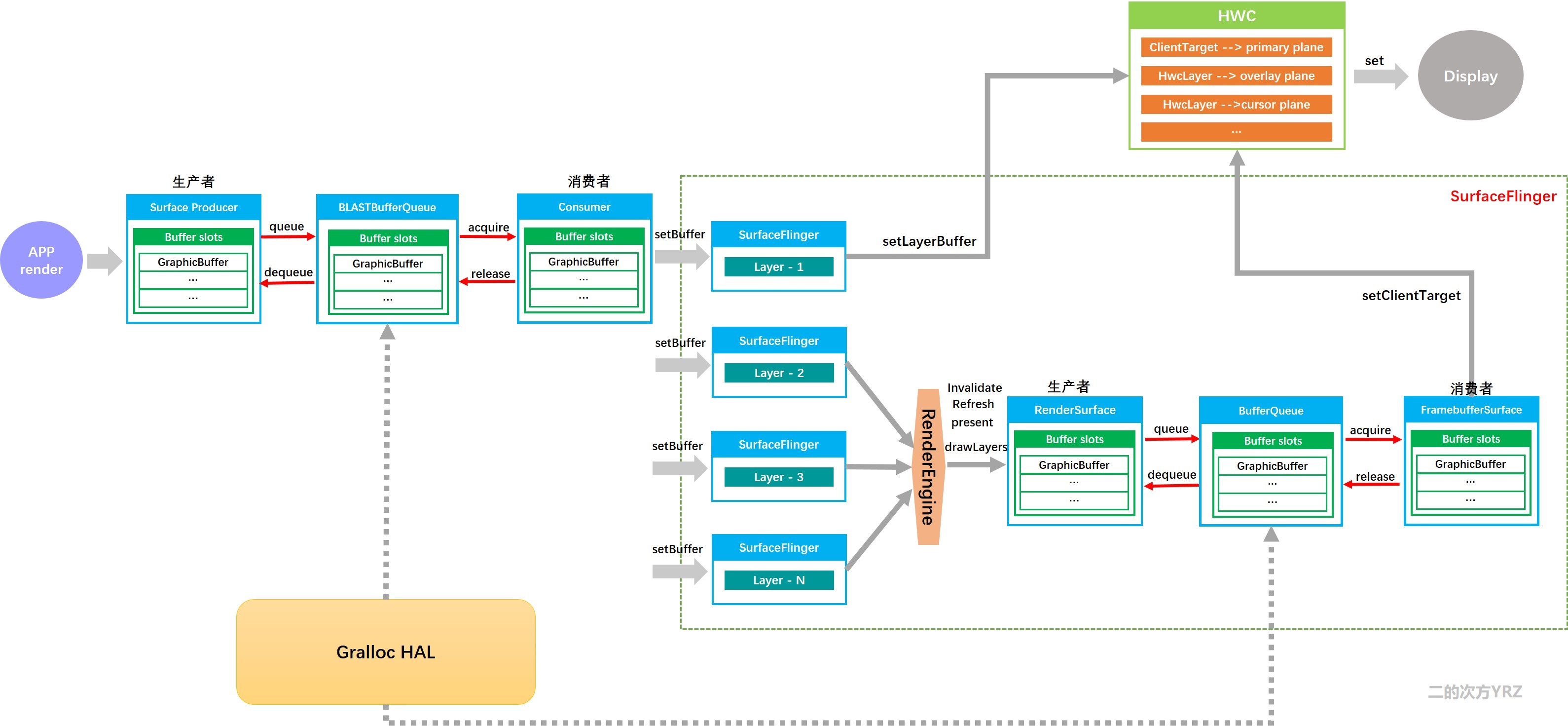
概述下从APP渲染图像写入GraphicBuffer经SurfaceFlinger处理最终呈现到Display的旅程:
1. GraphicBuffer先由App端作为生产者进行绘制,然后放入到BufferQueue,等待消费者取出作下一步的渲染合成;
2. SurfaceFlinger是Layer的管理者也是GraphicBuffer的消费者,画面更新时,SurfaceFlinger会收集所有可见的图层并询问HWC各个图层采用的合成方式;
3. 对于采用Device合成方式的图层,SurfaceFlinger会直接把该图层对应的GraphicBuffer的buffer handle通过调用setLayerBuffer放入HWC的Layer list;
4. 对于采用Client合成方式的图层,即需要GPU绘制的层(超出HWC处理层数或者有复杂变换的),SurfaceFlinger会将所有待合成的图层通过renderengine绘制到一块client target buffer中,然后通过调用setClientTarget传递给HWC,此时SF对于APP来说是消费者,它消费APP生成的图层数据,对于HWC来说SF是生产者,它生产target buffer给HWC消费;
参考:Android 12(S) 图像显示系统 - SurfaceFlinger GPU合成/CLIENT合成方式 - 随笔1
5. HWC最后叠加所有图层再往Display呈现出来,这时HWC是消费者。整个大致流程如图:
[/hardware/interfaces/graphics/composer/2.1/IComposerClient.hal]
/** Possible composition types for a given layer. */
enum Composition : int32_t {
INVALID = 0,
CLIENT = 1,
DEVICE = 2,
SOLID_COLOR = 3,
CURSOR = 4,
SIDEBAND = 5,
};可以看到,对于合成方式是CLIENT的图层来说,其GraphicBuffer先后经过两个生产消费者模型:
应用渲染时 == 生产者/消费者模型
SurfaceFlinger的GPU合成时 == 生产者/消费者模型
我们知道GraphicBuffer核心包含的是buffer_handle_t结构,它指向的native_handle_t包含了Gralloc中申请出来的图形缓冲区的文件描述符和其它基本属性,这个文件描述符会被同时映射到客户端和服务端,作为共享内存(跨进程的共享)。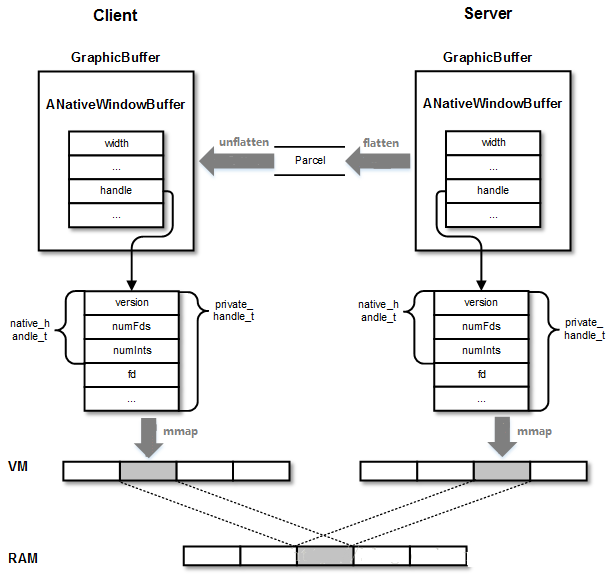
由于服务端进程和客户端进程都可以访问同一物理内存,因此不加同步的话会引起错误(读写冲突/混乱)。为了协调客户端和服务端不同进程下对同一共享内存的访问,在传输GraphicBuffer时,还带有Fence,标志了它是否被上一个使用者使用完毕。
Fence按作用大体分两种:acquireFence和releaseFence。前者用于生产者通知消费者生产已完成,后者用于消费者通知生产者消费已完成。下面分别看一下这两种Fence的产生和使用过程。首先是acquireFence的使用流程: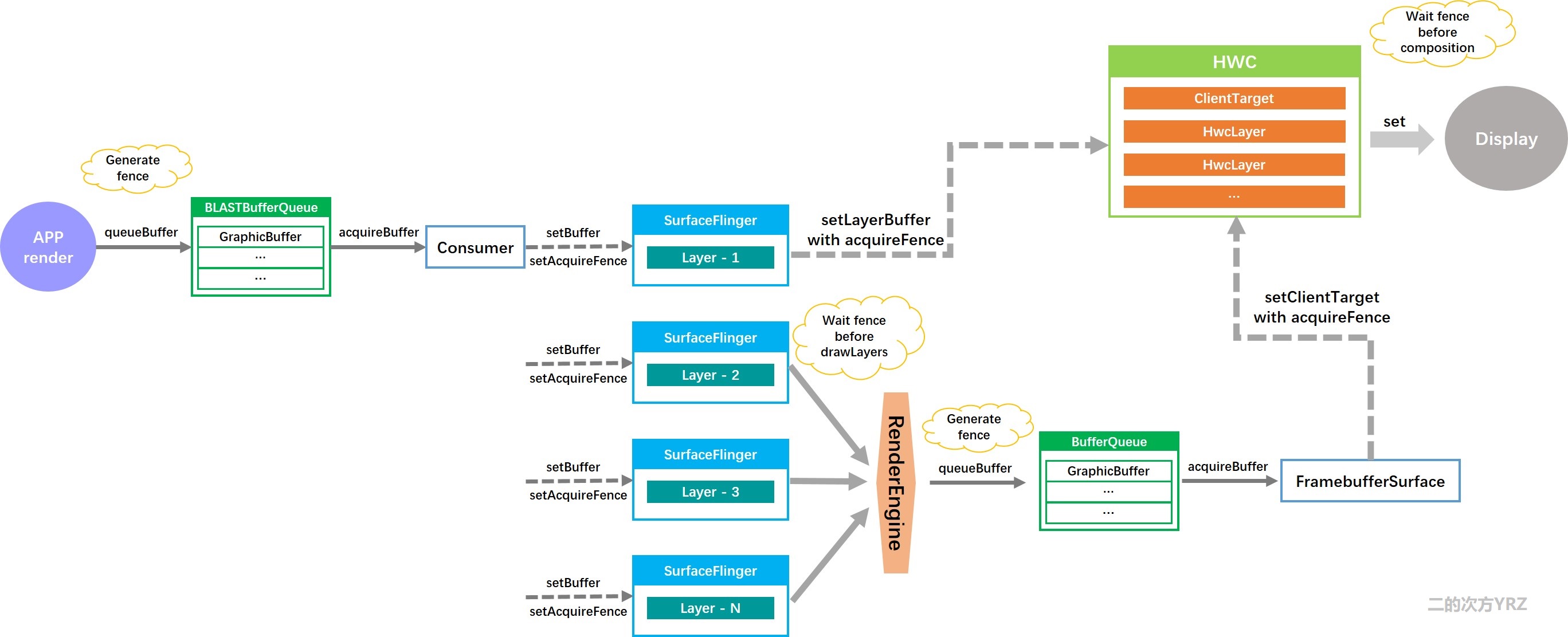
当App端通过queueBuffer()向BufferQueue插入GraphicBuffer时,会顺带一个Fence,这个Fence指示这个GraphicBuffer是否已被生产者用好。之后该GraphicBuffer被消费者通过acquireBuffer()拿走,同时也会取出这个acquireFence。之后消费者(也就是SurfaceFlinger)要把它拿来渲染时,需要等待Fence被触发,之后才可以处理这块缓存中的数据。
我们看一下相关流程中的关键代码片段:
生产端在queueBuffer时,传递进来Fence
[ /frameworks/native/libs/gui/Surface.cpp ]
int Surface::queueBuffer(android_native_buffer_t* buffer, int fenceFd) {
... // fenceFd即为生产者传递进来的,进一步封装为Fence Object,连同GraphicBuffer一块入队列
getQueueBufferInputLocked(buffer, fenceFd, mTimestamp, &input);
status_t err = mGraphicBufferProducer->queueBuffer(i, input, &output);
...
}消费端在acquireBuffer时,同时取得acquireFence,传递给最终的消费者SurfaceFlinger
[ /frameworks/native/libs/gui/BLASTBufferQueue.cpp ]
void BLASTBufferQueue::processNextBufferLocked(bool useNextTransaction) {
...
BufferItem bufferItem;
status_t status =
mBufferItemConsumer->acquireBuffer(&bufferItem, 0 /* expectedPresent */, false); //请求可用的buffer
...
auto buffer = bufferItem.mGraphicBuffer;
...
t->setBuffer(mSurfaceControl, buffer, releaseCallbackId, releaseBufferCallback); // 传递Buffer给SurfaceFlinger
t->setDataspace(mSurfaceControl, static_cast<ui::Dataspace>(bufferItem.mDataSpace));
t->setHdrMetadata(mSurfaceControl, bufferItem.mHdrMetadata);
t->setSurfaceDamageRegion(mSurfaceControl, bufferItem.mSurfaceDamage);
t->setAcquireFence(mSurfaceControl, // 传递fence给SurfaceFlinger
bufferItem.mFence ? new Fence(bufferItem.mFence->dup()) : Fence::NO_FENCE);
...
}SurfaceFlinger接受buffer与fence并设置到对应的Layer
[/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp]
uint32_t SurfaceFlinger::setClientStateLocked() {
...
if (what & layer_state_t::eAcquireFenceChanged) {
if (layer->setAcquireFence(s.acquireFence)) flags |= eTraversalNeeded; // 传递给Layer
}
...
if (layer->setBuffer(buffer, s.acquireFence, postTime, desiredPresentTime, isAutoTimestamp, // 传递给Layer
s.cachedBuffer, frameNumber, dequeueBufferTimestamp, frameTimelineInfo,
s.releaseBufferListener)) {
flags |= eTraversalNeeded;
}
...
}Layer把信息 Buffer & acquireFence保存到mDrawingState
mDrawingState.buffer = buffer;
mDrawingState.acquireFence = fence;合成阶段等待acquireFence触发后再去处理数据
SurfaceFlinger在对Layer进行重新绘制时,BufferLayer::latchBuffer中会先去判断mDrawingState记录的最新设置下来的GraphicBuffer的acquire fence是否已经signaled,没有的话会再继续SurfaceFlinger::signalLayerUpdate ==> invalidate尝试,直到acquire fence被触发,再去继续执行updateTexImage==>updateActiveBuffer等合成前的准备工作。
// invalidate
SurfaceFlinger::handleMessageInvalidate()
// pageflip
SurfaceFlinger::handlePageFlip()
// 然后调用到latchBuffer
BufferLayer::latchBuffer() {
...
// If the head buffer's acquire fence hasn't signaled yet, return and
// try again later
if (!fenceHasSignaled()) { // 等待acquire fence的逻辑
ATRACE_NAME("!fenceHasSignaled()");
mFlinger->signalLayerUpdate(); // 会再次触发invalidate
return false;
}
...
}注:上面的理解,我也只是根据代码来判断的,没有实际验证过,理解也许有错,仅供参考!
本文作者@二的次方 2022-05-20发布于博客园
如果图层是DEVICE合成方式渲染,那么不需要经过GPU,那就需要把这些层对应的acquireFence传到HWC中。这样,HWC在合成前就能确认这个buffer是否已被生产者使用完,因此一个正常点的HWC需要等这些个acquireFence全被触发才能去绘制。所以在向HWC设置setLayerBuffer时,也会把传递acquireFence
[/frameworks/native/services/surfaceflinger/DisplayHardware/ComposerHal.cpp]
Error Composer::setLayerBuffer(Display display, Layer layer,
uint32_t slot, const sp<GraphicBuffer>& buffer, int acquireFence)
{
mWriter.selectDisplay(display);
mWriter.selectLayer(layer);
const native_handle_t* handle = nullptr;
if (buffer.get()) {
handle = buffer->getNativeBuffer()->handle;
}
mWriter.setLayerBuffer(slot, handle, acquireFence);
return Error::NONE;
}我这里有一个疑问:如果上面BufferLayer::latchBuffer中分析的等待acquireFence的逻辑是正确的,那这个等待的逻辑看起来是直接传递给HWC合成的buffer也会经过这里,那是不是setLayerBuffer再传递acquireFence给HWC,其实HWC就无需再判断acquireFence是否被触发了呢?因为latchBuffer中的逻辑保证了传递给HWC的buffer肯定是可以直接操作的了
对于CLIENT合成方式的图层,因为HWC不需要直接这些层同步,它只要和这些CLIENT图层合成的结果FramebufferTarget同步就可以了。
GPU进程合成CLIENT图层前,会去RenderSurface::dequeueBuffer获取一块GraphicBuffer用来存储合成的结果,然后使用SkiaGLRenderEngine::drawLayers去把所有CLIENT图层画到这块图形缓存中。
[/frameworks/native/libs/renderengine/skia/SkiaGLRenderEngine.cpp]
status_t SkiaGLRenderEngine::drawLayers(const DisplaySettings& display,
const std::vector<const LayerSettings*>& layers,
const std::shared_ptr<ExternalTexture>& buffer,
const bool /*useFramebufferCache*/,
base::unique_fd&& bufferFence, base::unique_fd* drawFence) {
...
// wait on the buffer to be ready to use prior to using it
waitFence(bufferFence); // 等待buffer可用,这块buffer就是通过RenderSurface::dequeueBuffer获取的
...
if (drawFence != nullptr) {
*drawFence = flush(); // 这个drawFence用作同步HWC,告诉HWC: 我GPU画完了,你HWC消费吧
}
}GPU合成完CLIENT图层后,通过RenderSurface::queueBuffer()将GraphicBuffer放入对应的BufferQueue,包括对应的Fence == SkiaGLRenderEngine::drawLayers时产生的;然后消费端FramebufferSurface通过advanceFrame() --> nextBuffer() -> acquireBufferLocked()从BufferQueue中拿一个GraphicBuffer,附带拿到它的acquireFence。接着调用
[/frameworks/native/services/surfaceflinger/DisplayHardware/FramebufferSurface.cpp]
status_t FramebufferSurface::nextBuffer(uint32_t& outSlot,
sp<GraphicBuffer>& outBuffer, sp<Fence>& outFence,
Dataspace& outDataspace) {
...
status_t result = mHwc.setClientTarget(mDisplayId, outSlot, outFence, outBuffer, outDataspace);
...
}其中会把刚才acquire的GraphicBuffer连带acquireFence通过调用setClientTarget设到HWC的ClientTarget Layer。
综上,HWC进行最后合成处理的前提是CLIENT图层层的acquireFence及FramebufferTarget的acquireFence都被触发。
看完acquireFence,再看看releaseFence的使用流程:
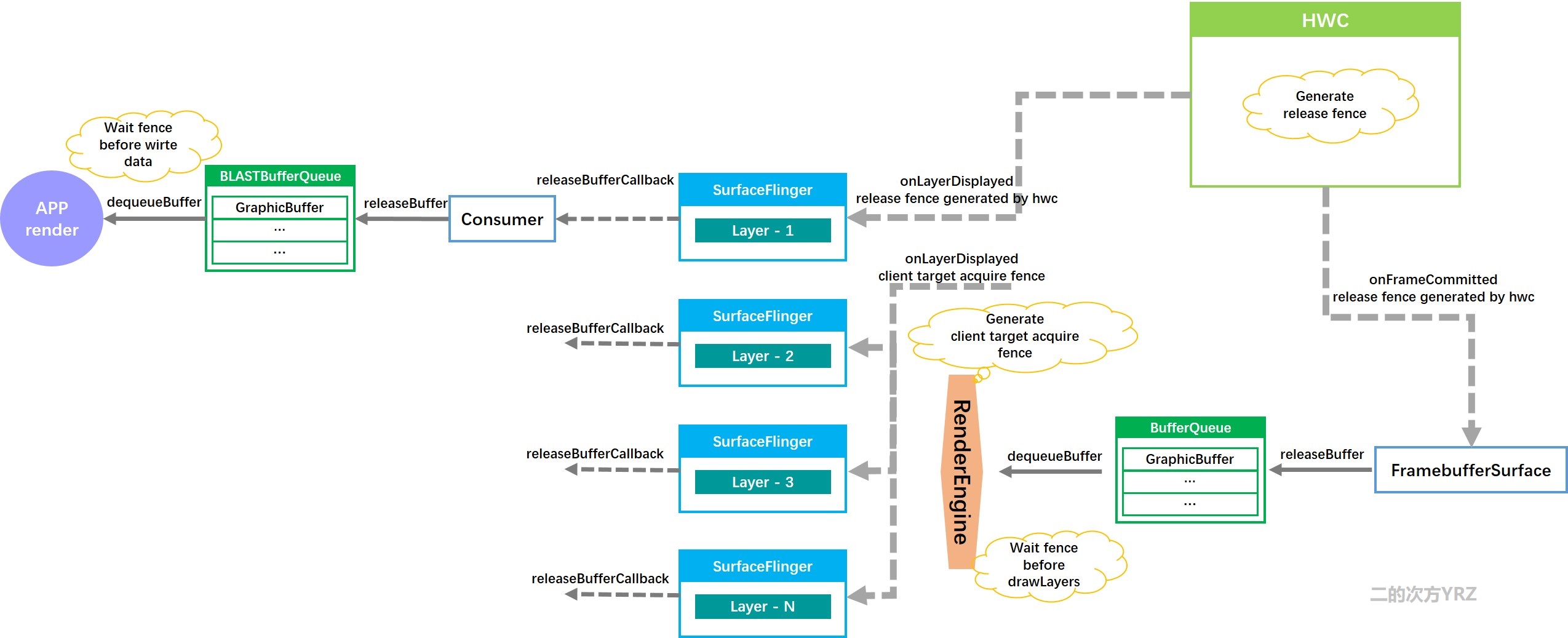
合成过程中,先是GPU工作,在Output::composeSurfaces()函数中对CLIENT合成方式的图层进行合成,结果放在framebuffer中(即RenderSurface::dequeueBuffer获得的GraphicBuffer)。然后SurfaceFlinger会调用Output::postFramebuffer()让HWC开始工作。postFramebuffer()中最主要是调用Display::presentAndGetFrameFences()最终会调用到HWC的方法present和getReleaseFences通知HWC合成显示并返回得到releaseFence。
HWC中产生的releaseFence主要是:同步DEVICE合成方式的Layer的GraphicBuffer的释放;
[/frameworks/native/services/surfaceflinger/CompositionEngine/src/Output.cpp]
void Output::postFramebuffer() {
...
auto& outputState = editState();
outputState.dirtyRegion.clear();
mRenderSurface->flip();
auto frame = presentAndGetFrameFences(); // 通知HWC合成显示并获取到releaseFence
mRenderSurface->onPresentDisplayCompleted(); // 通知FramebufferSurface进行release buffer ==>走到FramebufferSurface::onFrameCommitted()
for (auto* layer : getOutputLayersOrderedByZ()) {
// The layer buffer from the previous frame (if any) is released
// by HWC only when the release fence from this frame (if any) is
// signaled. Always get the release fence from HWC first.
sp<Fence> releaseFence = Fence::NO_FENCE;
if (auto hwcLayer = layer->getHwcLayer()) { // 获取Layer对应的releaseFence
if (auto f = frame.layerFences.find(hwcLayer); f != frame.layerFences.end()) {
releaseFence = f->second;
}
}
// If the layer was client composited in the previous frame, we
// need to merge with the previous client target acquire fence.
// Since we do not track that, always merge with the current
// client target acquire fence when it is available, even though
// this is suboptimal.
// TODO(b/121291683): Track previous frame client target acquire fence.
if (outputState.usesClientComposition) {
// 如果有GPU合成Layer(Client合成方式),做Fence::merge
// releaseFence -- HWC生成的
// clientTargetAcquireFence -- 本质是 RenderSurface::queueBuffer传入的 acquire fence,是在SkiaGLRenderEngine::drawLayers中生成的
releaseFence =
Fence::merge("LayerRelease", releaseFence, frame.clientTargetAcquireFence);
}
layer->getLayerFE().onLayerDisplayed(releaseFence); // 把releaseFence同步到各个Layer
}
...
}对于DEVICE合成的Layer,因为是HWC消费这些图层的GraphicBuffer数据。所以HWC产生的release fence来同步这些图形缓存的释放;
对于CLIENT合成的Layer,因为是GPU消费这些图层的GraphicBuffer数据并合成到client target中。所以当GPU完成合成时就意味着这些图层的缓存数据就不再被使用了,因此client target acquire fence作为release fence来同步这些图形缓存的释放;
client target acquire fence即表示GPU合成完了,HWC可以消费了,也意味着相关Layer的图像缓存可以释放了。
release fence需要同步到Layer。实现位于Layer的onLayerDisplayed()函数中:
[/frameworks/native/services/surfaceflinger/BufferStateLayer.cpp]
void BufferStateLayer::onLayerDisplayed(const sp<Fence>& releaseFence) {
...
sp<CallbackHandle> ch;
for (auto& handle : mDrawingState.callbackHandles) {
if (handle->releasePreviousBuffer) {
ch = handle;
break;
}
}
auto status = addReleaseFence(ch, releaseFence);
if (status != OK) {
ALOGE("Failed to add release fence for layer %s", getName().c_str());
}
mPreviousReleaseFence = releaseFence;
}中间还会有一些过程,然后经过Binder 回调,会通知到BLASTBufferQueue,我们在setBuffer时,有设置一个releaseBufferCallback,这个回调中会收到release fence,最终会调到 releaseBuffer 连同fence一块归还到缓存队列中,之后生产者就可以dequeueBuffer时取到这块缓存了
[/frameworks/native/libs/gui/BLASTBufferQueue.cpp]
void BLASTBufferQueue::processNextBufferLocked(bool useNextTransaction) {
auto releaseBufferCallback =
std::bind(releaseBufferCallbackThunk, wp<BLASTBufferQueue>(this) /* callbackContext */,
std::placeholders::_1, std::placeholders::_2, std::placeholders::_3,
std::placeholders::_4);
t->setBuffer(mSurfaceControl, buffer, releaseCallbackId, releaseBufferCallback); // 设置了releaseBufferCallback
}那对于存储GPU绘制结果的那一层呢?
Output::postFramebuffer() ==> RenderSurface::onPresentDisplayCompleted() ==>FramebufferSurface::onFrameCommitted()
[/frameworks/native/services/surfaceflinger/DisplayHardware/FramebufferSurface.cpp]
void FramebufferSurface::onFrameCommitted() {
if (mHasPendingRelease) {
sp<Fence> fence = mHwc.getPresentFence(mDisplayId); // 获取release fence
if (fence->isValid()) {
status_t result = addReleaseFence(mPreviousBufferSlot,
mPreviousBuffer, fence);
ALOGE_IF(result != NO_ERROR, "onFrameCommitted: failed to add the"
" fence: %s (%d)", strerror(-result), result);
}
status_t result = releaseBufferLocked(mPreviousBufferSlot, mPreviousBuffer); // release buffer
ALOGE_IF(result != NO_ERROR, "onFrameCommitted: error releasing buffer:"
" %s (%d)", strerror(-result), result);
mPreviousBuffer.clear();
mHasPendingRelease = false;
}
}此处拿到HWC生成的FramebufferTarget的releaseFence,设到FramebufferSurface中相应的GraphicBuffer Slot中。这样FramebufferSurface对应的GraphicBuffer也可以被释放回BufferQueue了。当将来EGL从中拿到这个buffer时,照例也要先等待这个releaseFence触发才能使用。
讲到这里,fence的内容就差不多了。不过好多细节的东西都没分析,也许还有理解错误。
本文作者@二的次方 2022-05-20发布于博客园
Fence在图形显示系统中,我觉得简单点讲,应该就概括为2个作用:
1. 生产者填充数据到GraphicBuffer,并附带产生一个acquire fence,这块buffer连同fence一块返回到BufferQueue,acquireBuffer后被消费者取走 --> 此时acquire fence的作用
// 消费者焦急的等待....
生产者:Hi, 消费者,我把数据都写到buffer了,你准备尽情消费吧!
消费者:收到,那我开始消费了哦!2. 消费者使用完GraphicBuffer中的数据,并附带产生一个release fence,这块buffer连同fence一块返回到BufferQueue,dequeueBuffer后被生产者取走 --> 此时release fence的作用
// 生产者焦急的等待....
消费者:Hi,生产者,这块buffer中的数据我消费完了,不再使用了哦!
生产者:收到,那我就向这块buffer中填充新的数据了也许理解不正确,谨慎阅读,就先这样吧
----
本文参考了很多有价值的文章,并据此修改来理解Android 12 中的逻辑,站在巨人的肩膀上可以看的更远。本篇仅供学习参考,理解上难免有错误!
https://blog.csdn.net/jinzhuojun/article/details/39698317
https://zhuanlan.zhihu.com/p/68782630
https://www.jianshu.com/p/3c61375cc15b
Android 12(S) 图像显示系统 - GraphicBuffer同步机制 - Fence的更多相关文章
- Android 12(S) 图像显示系统 - SurfaceFlinger GPU合成/CLIENT合成方式 - 随笔1
必读: Android 12(S) 图像显示系统 - 开篇 一.前言 SurfaceFlinger中的图层选择GPU合成(CLIENT合成方式)时,会把待合成的图层Layers通过renderengi ...
- Android 12(S) 图像显示系统 - 基础知识之 BitTube
必读: Android 12(S) 图像显示系统 - 开篇 一.基本概念 在Android显示子系统中,我们会看到有使用BitTube来进行跨进程数据传递.BitTube的实现很简洁,就是一对&quo ...
- Android 12(S) 图像显示系统 - SurfaceFlinger之VSync-上篇(十六)
必读: Android 12(S) 图像显示系统 - 开篇 一.前言 为了提高Android系统的UI交互速度和操作的流畅度,在Android 4.1中,引入了Project Butter,即&quo ...
- Android 12(S) 图像显示系统 - SurfaceFlinger 之 VSync - 中篇(十七)
必读: Android 12(S) 图像显示系统 - 开篇 1 前言 这一篇文章,将继续讲解有关VSync的知识,前一篇文章 Android 12(S) 图像显示系统 - SurfaceFlinger ...
- Android 12(S) 图像显示系统 - HWC HAL 初始化与调用流程
必读: Android 12(S) 图像显示系统 - 开篇 接口定义 源码位置:/hardware/interfaces/graphics/composer/ 在源码目录下可以看到4个版本的HIDL ...
- Android 12(S) 图像显示系统 - drm_hwcomposer 简析(上)
必读: Android 12(S) 图像显示系统 - 开篇 前言 Android源码中有包含drm_hwcomposer:/external/drm_hwcomposer/ drm_hwcompose ...
- Android 12(S) 图像显示系统 - drm_hwcomposer 简析(下)
必读: Android 12(S) 图像显示系统 - 开篇 合成方式 合成类型的定义:/hardware/interfaces/graphics/composer/2.1/IComposerClien ...
- Android中的GraphicBuffer同步机制-Fence
Fence是一种同步机制,在Android里主要用于图形系统中GraphicBuffer的同步.那它和已有同步机制相比有什么特点呢?它主要被用来处理跨硬件的情况.尤其是CPU.GPU和HWC之间的同步 ...
- Android 12(S) 图形显示系统 - 解读Gralloc架构及GraphicBuffer创建/传递/释放(十四)
必读: Android 12(S) 图形显示系统 - 开篇 一.前言 在前面的文章中,已经出现过 GraphicBuffer 的身影,GraphicBuffer 是Android图形显示系统中的一个重 ...
随机推荐
- Numpy怎样给数组增加一个维度
Numpy怎样给数组增加一个维度 背景:很多数据计算都是二维或三维的,对于一维的数据输入为了形状匹配,经常需升维变成二维 需要:在不改变数据的情况下,添加数组维度:(注意观察这个例子,维度变了,但数据 ...
- s函数中积分程序更改
function [sys,x0,str,ts,simStateCompliance] = int_hyo(t,x,u,flag) switch flag, case 0, [sys,x0,str,t ...
- 5_终值定理和稳态误差_Final Value Theorem & Steady State Error
- PCB产业链、材料、工艺流程详解(1)
PCB知识大全 1.什么是pcb,用来干什么? PCB( Printed Circuit Board),中文名称为印制电路板,又称印刷线路板,是重要的电子部件,是电子元器件的支撑体,是电子元器件电气连 ...
- html5不熟悉的标签全称
<dl></dl> 定义列表(英文全称:DefinitionList) <dt> 放在每个定义术语词前(定义术语.英文全称:DefinitionTerm) 名称 & ...
- 【Android开发】【第三方SDK】蒲公英摇一摇
摇一摇用户信息反馈功能:用户通过摇晃手机或者触发按钮,弹出反馈信息界面,填写个人意见,上传服务器的功能. 1. 蒲公英官网注册应用,获取AppId作为唯一标识: 2. 下载sdk,获取pgyer_sd ...
- video踩坑
查看以及修改video控件样式,原文地址:https://blog.csdn.net/z2181745/article/details/82531686 chrome浏览器,F12调出控制台左上角三点 ...
- dev分支代码覆盖master分支代码
将develop分支上的代码完全覆盖master分支, 1. 切换到master分支 git checkout master 2. 执行以下命令 git reset --hard origin/dev ...
- python---反转链表
class Node: def __init__(self, data): self.data = data self.next = None class Solution: "" ...
- MongoDB 数据库开发规范
MongoDB 数据库开发规范 转载自-落雨_ https://developer.aliyun.com/article/255536 简介: mongoDB库的设计 mongodb数据库命名规范:d ...