152-技巧-Power Query 快速合并文件夹中表格之自定义函数 TableXlsxCsv
152-技巧-Power Query 快速合并文件夹中表格之自定义函数 TableXlsxCsv
附件下载地址:https://jiaopengzi.com/2602.html
一、背景
在我们使用 Power BI 或者 Power Pivot 做数据分析模型时,使用 Power Query 做数导入,经常会遇到如下场景:
- 同一文件夹下多个表格的合并。
- 同一个 Workbook 中有多个相同的字段的 WorkSheet 。
- Xlsx, Xls, Csv 并存。
- 字段的类型更改每次都要打开 Power Query 去修改。
- 字段增加和删除每次都要打开 Power Query 去修改。
- 字段重命名后要修改类型等多处操作。
- 合并的表格表头有多行不需要的信息,影响数据的读取。
- 有多个项目文件夹都是合并表格,要重复写 M 语句或者重复面板操作。
- 把文件名称按照规则添加列到对应的合并的表格里。
- Excel 文件筛选后,会出现数据变多的情况。
基于上述的场景,我们写好了一个能应对的自定义函数:TableXlsxCsv ,让我们来看一下函数的介绍。
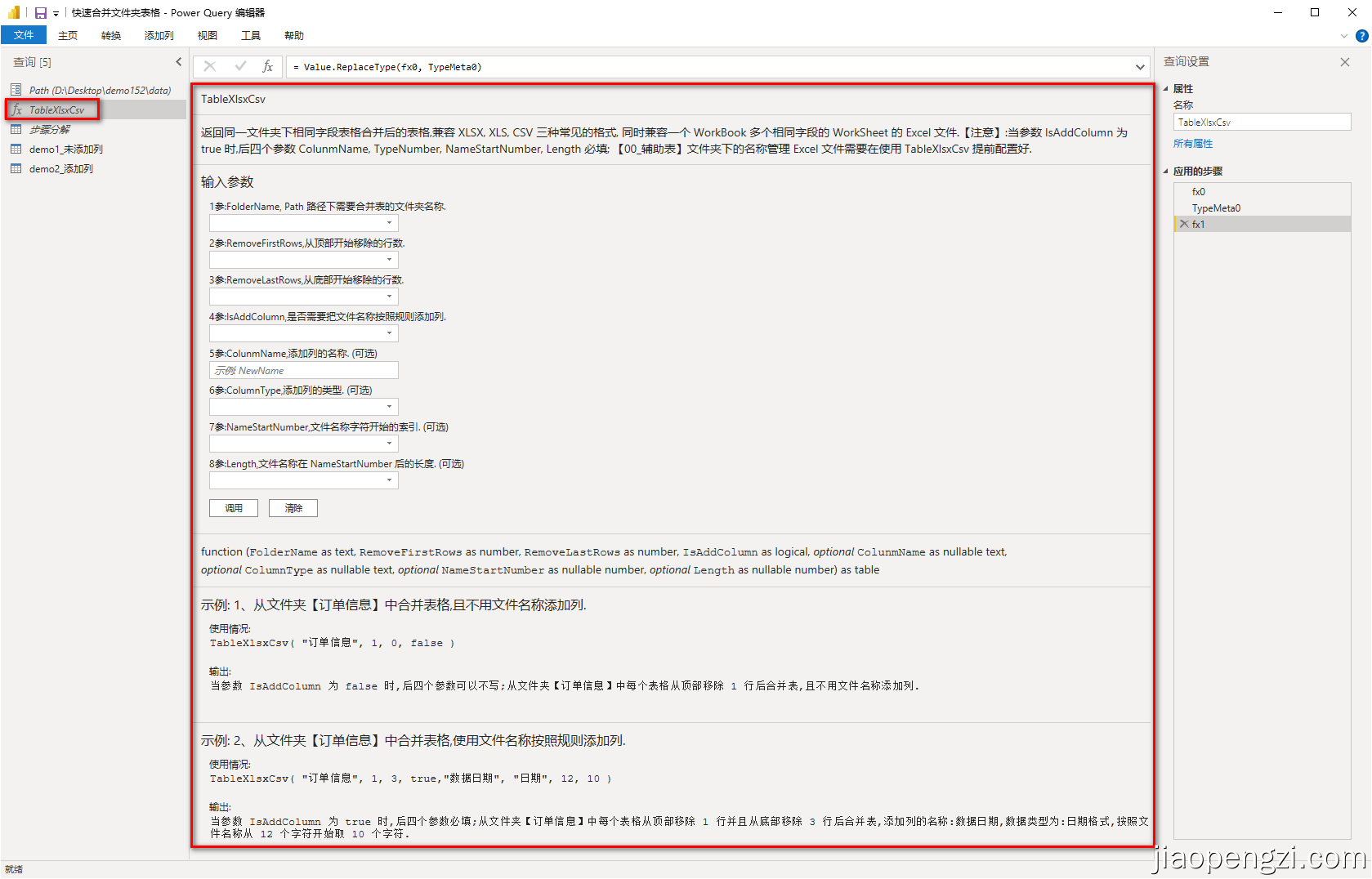
这个函数的提示和 Power Query 内置函数的提示是一样的,基本函数的使用和说明都清晰了。
二、TableXlsxCsv 的使用方法
1、参数介绍
Ⅰ、必填参数
1参:FolderName
data 文件夹下需要合并表的文件夹名称,比如demo中的文件夹:01_订单
2参:RemoveFirstRows
数据从顶部开始需要移除的行数,一般情况需要把标题及以前的数据都要移除,在名称管理中已经管理好了对应的标题。
3参:RemoveLastRows
数据从底部开始需要移除的行数,比如底部有类似汇总行的数据。
4参:IsAddColumn
是否需要把文件名称按照规则添加列,只能填写 true 或者 false 两个参数,true 表示需要添加列,false 表示不需要添加列。
注意:当 4 参 IsAddColumn 为 false,后面四个参数不用填写,为 true 时,后面四个参数必须填写。
Ⅱ、可选参数
5参:ColunmName
当 4 参 IsAddColumn 为 true 表示需要把文件名称按照规则添加列,ColunmName 即为新增列的名称,注意不要与合并表中的字段名称重复。
6参:ColumnType
5 参 ColunmName 添加列的数据类型,只能填写如下类型:
type text
type number
Int64.Type
type date
type datetime
type time
7参:NameStartNumber
文件名称字符开始的索引,比如文件名称:订单信息-2022-05-16;索引是从 0 开始的,需要取年与日的话索引的开始就是 5 。
8参:Length
文件名称在 6 参 NameStartNumber 后的长度,比如文件名称:订单信息-2022-05-16;索引是从 0 开始的,需要取年与日的话索引的开始就是 5 ,Length 就是 2022-05-16 的长度 10 个字符。
2、必要配置
Ⅰ、项目文件夹
项目新建一个文件夹,名称随意,我们当前的案例项目文件夹:demo152
Ⅱ、数据文件夹 data
项目文件夹建立好后,需要把项目文件和数据文件区分开,我们建立 data 文件夹来管理数据,当然这个文件夹的名称也是随意,根据自己的需求来即可。
Ⅲ、数据字段的名称管理
在 数据文件夹 data 下有一个 00_辅助表 的文件夹,这个文件名称不能更改,是和函数绑定的名称。
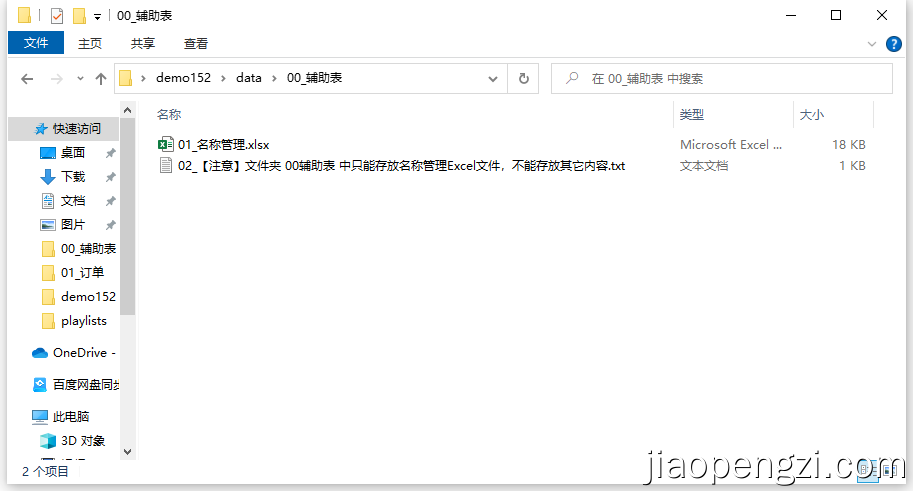
Ⅳ、需合并表格的名称管理
在辅助表文件夹中,有一个 Excel 文件: 01_名称管理,这个文件就是把需要合并的文件夹中的表格的重命名、数据类型、是否显示等都解耦出来,在这个 Excel 文件中操作即可。
具体配置如下图:
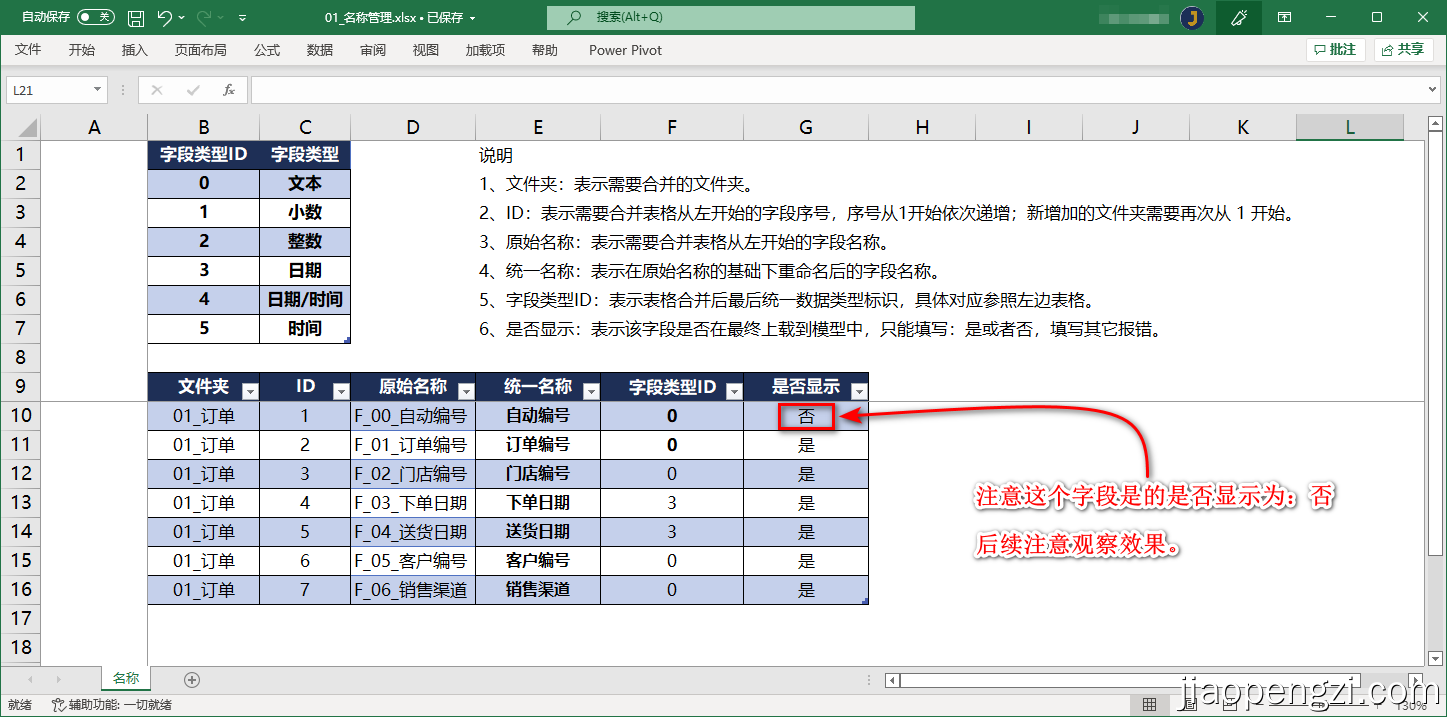
1、文件夹:表示需要合并的文件夹,比如当前的:01_订单 文件夹。
2、ID:表示需要合并表格从左开始的字段序号,序号从1开始依次递增,新增加的文件夹需要再次从 1 开始。
3、原始名称:表示需要合并表格从左开始的字段名称。
4、统一名称:表示在原始名称的基础下重命名后的字段名称,比如当前的配置就把所有字段都重命名了。
5、字段类型ID:表示表格合并后最后统一数据类型标识,具体对应参照左边表格。
6、是否显示:表示该字段是否在最终上载到模型中,只能填写:**是 ** 或者 否,填写其它会报错。
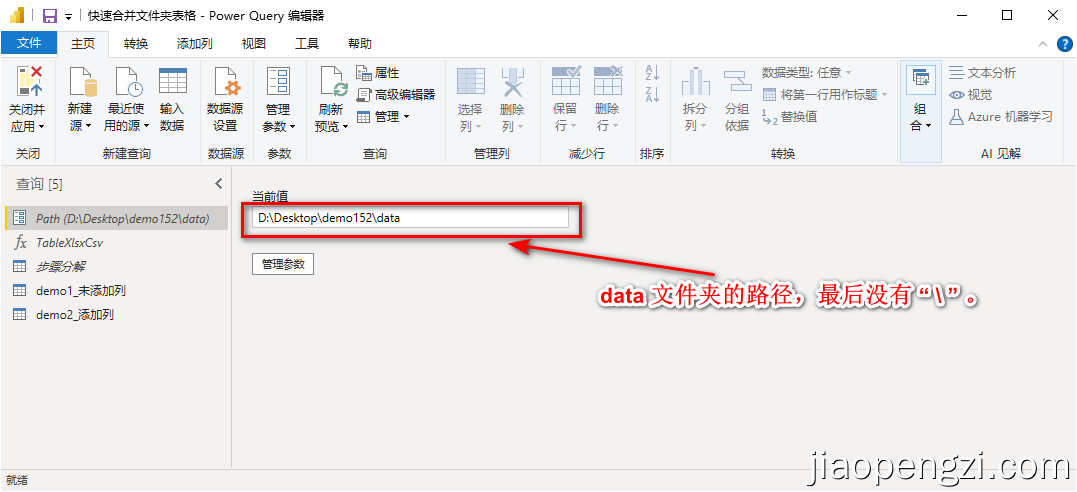
Ⅴ、Power Query 路径配置
打开项目文件把路径参数:Path 配置好,注意这个参数就是 前面 data 文件夹的路径。参数 Path 名称不能更改,,注意大小写。
Ⅵ、配置自定义函数 TableXlsxCsv
在 Path 下面 新建一个空白查询,点击高级编辑器,把 TableXlsxCsv 的 M 代码复制到编辑框里面保存,重命名查询为 TableXlsxCsv即可。
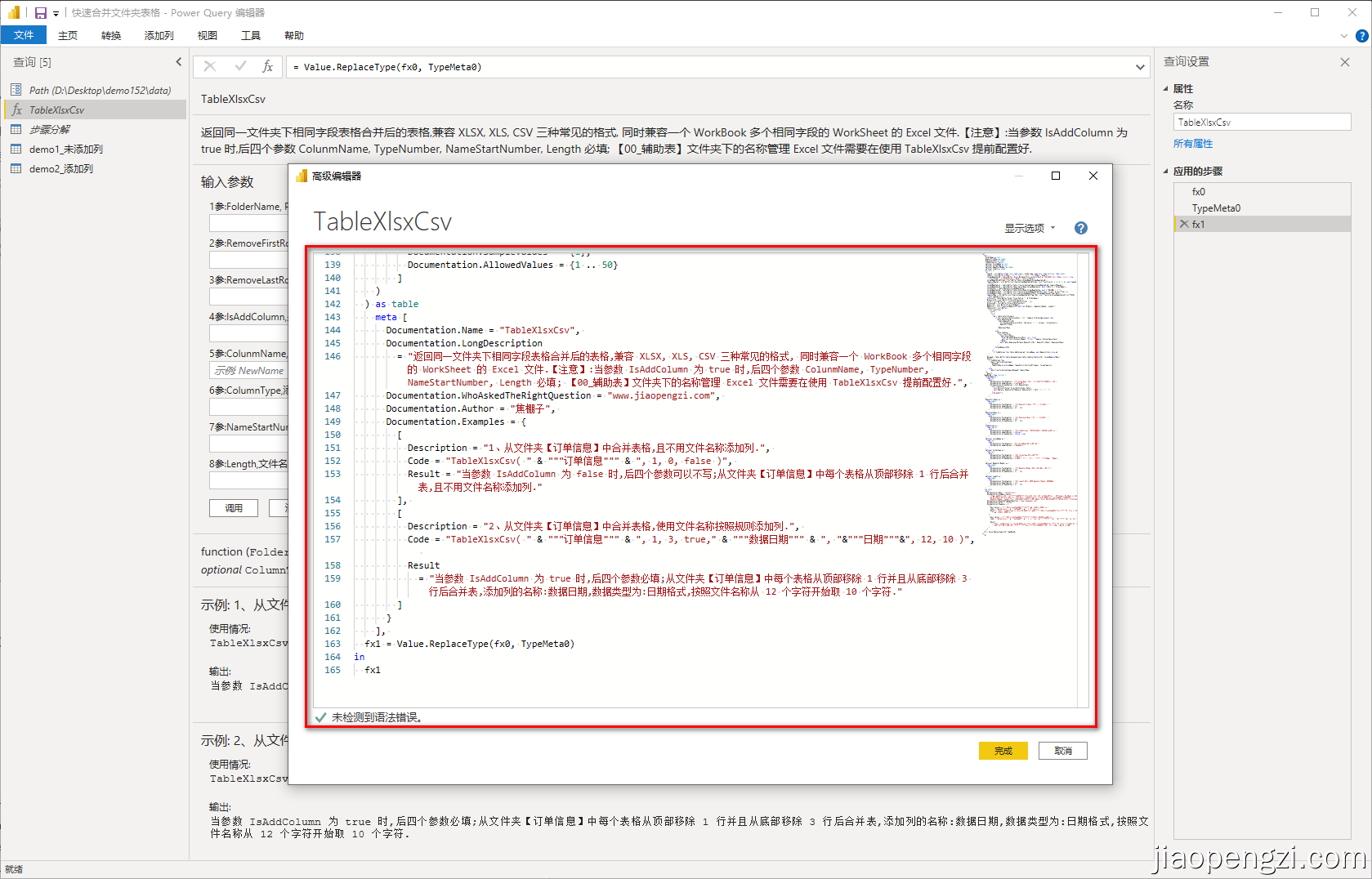
TableXlsxCsv 的 M 代码:
let
fx0 = (
FolderName as text,
RemoveFirstRows as number,
RemoveLastRows as number,
IsAddColumn as logical,
optional ColunmName as text,
optional ColumnType as text,
optional NameStartNumber as number,
optional Length as number
) as table =>
let
Types0 = List.Buffer({type text, type number, Int64.Type, type date, type datetime, type time}),
Types1 = List.Buffer({"文本", "小数", "整数", "日期", "日期时间", "时间"}),
ColumnNameTable0 = Table.Buffer( Excel.Workbook(File.Contents(Path & "\00_辅助表\01_名称管理.xlsx"), true, true){[Item = "ColumnNameTable", Kind = "Table"]}[Data]),
ColumnNameTable0Fileds = List.Buffer(Table.ColumnNames(ColumnNameTable0)),
TypeListNewjpz = List.Buffer(List.Zip({ColumnNameTable0Fileds, List.Transform({0, 2, 0, 0, 2, 0}, each Types0{_})})),
ColumnNameTable1 = Table.Buffer(Table.TransformColumnTypes(ColumnNameTable0, TypeListNewjpz)),
ColumnNameTable2 = Table.Buffer(Table.SelectRows(ColumnNameTable1, each ([文件夹] = FolderName))),
ColumnCount = Table.RowCount(ColumnNameTable2),
ColumnNameTableX = Table.Buffer(Table.SelectRows(ColumnNameTable2, each [是否显示] = "是")),
ColumnNameListOld = List.Buffer(List.Transform(ColumnNameTableX[ID], each "Column" & Text.From(_))),
ColumnNameListNew = List.Buffer(List.Zip({ColumnNameListOld, ColumnNameTableX[统一名称]})),
TypeListNew = List.Buffer(List.Zip({ColumnNameTableX[统一名称], List.Transform(ColumnNameTableX[字段类型ID], each Types0{_})})),
FileList0 = Table.Buffer(Folder.Files(Path & "\" & FolderName)),
BinaryList0 = List.Buffer(FileList0[Content]),
List0 = List.Buffer({0 .. List.Count(BinaryList0) - 1}),
Extension0 = List.Buffer(FileList0[Extension]),
NameList0 = List.Buffer(FileList0[Name]),
NameList1 = List.Transform(NameList0, each Text.Middle(_, NameStartNumber, Length)),
TableList0 = List.Buffer(
List.Transform(
List0,
(n) =>
let
wb = Table.SelectColumns(
if Text.Contains(Extension0{n}, "Csv", Comparer.OrdinalIgnoreCase) then
Table.RemoveLastN(
Table.RemoveFirstN(
Csv.Document(BinaryList0{n}, [Delimiter = ",", Columns = ColumnCount]),
RemoveFirstRows
),
RemoveLastRows
)
else
Table.Combine(
List.Transform(
Table.SelectRows(
Excel.Workbook(BinaryList0{n}, null, true),
each not Text.Contains([Name], "Filter", Comparer.OrdinalIgnoreCase)
)[Data],
each Table.RemoveLastN(Table.RemoveFirstN(_, RemoveFirstRows), RemoveLastRows)
)
),
ColumnNameListOld
)
in
if IsAddColumn then Table.AddColumn(wb, ColunmName, each NameList1{n}) else wb
)
),
Rename0 = Table.Buffer(Table.RenameColumns(Table.Combine(TableList0), ColumnNameListNew)),
Result =
if IsAddColumn then
Table.TransformColumnTypes(
Rename0,
TypeListNew & {{ColunmName, Types0{List.PositionOf(Types1, ColumnType)}}}
)
else
Table.TransformColumnTypes(Rename0, TypeListNew)
in
Result,
TypeMeta0 = type function (
FolderName as (
type text
meta [
Documentation.FieldCaption = "1参:FolderName, Path 路径下需要合并表的文件夹名称.",
Documentation.SampleValues = {"订单信息"},
Documentation.AllowedValues = List.RemoveItems(
List.Transform(
List.Distinct(Folder.Files(Path)[Folder Path]),
each Replacer.ReplaceText(Replacer.ReplaceText(_, Path, ""), "\", "")
),
{"00_辅助表"}
)
]
),
RemoveFirstRows as (
type number
meta [
Documentation.FieldCaption = "2参:RemoveFirstRows,从顶部开始移除的行数.",
Documentation.SampleValues = {1},
Documentation.AllowedValues = {0 .. 50}
]
),
RemoveLastRows as (
type number
meta [
Documentation.FieldCaption = "3参:RemoveLastRows,从底部开始移除的行数.",
Documentation.SampleValues = {0},
Documentation.AllowedValues = {0 .. 50}
]
),
IsAddColumn as (
type logical
meta [
Documentation.FieldCaption = "4参:IsAddColumn,是否需要把文件名称按照规则添加列.",
Documentation.SampleValues = {false},
Documentation.AllowedValues = {false, true}
]
),
optional ColunmName as (
type text
meta [
Documentation.FieldCaption = "5参:ColunmName,添加列的名称.",
Documentation.SampleValues = {"NewName"}
]
),
optional ColumnType as (
type text
meta [
Documentation.FieldCaption = "6参:ColumnType,添加列的类型.",
Documentation.SampleValues = {"文本"},
Documentation.AllowedValues = {"文本", "小数", "整数", "日期", "日期时间", "时间"}
]
),
optional NameStartNumber as (
type number
meta [
Documentation.FieldCaption = "7参:NameStartNumber,文件名称字符开始的索引.",
Documentation.SampleValues = {0},
Documentation.AllowedValues = {1 .. 50}
]
),
optional Length as (
type number
meta [
Documentation.FieldCaption = "8参:Length,文件名称在 NameStartNumber 后的长度.",
Documentation.SampleValues = {1},
Documentation.AllowedValues = {1 .. 50}
]
)
) as table
meta [
Documentation.Name = "TableXlsxCsv",
Documentation.LongDescription
= "返回同一文件夹下相同字段表格合并后的表格,兼容 XLSX, XLS, CSV 三种常见的格式, 同时兼容一个 WorkBook 多个相同字段的 WorkSheet 的 Excel 文件.【注意】:当参数 IsAddColumn 为 true 时,后四个参数 ColunmName, TypeNumber, NameStartNumber, Length 必填; 【00_辅助表】文件夹下的名称管理 Excel 文件需要在使用 TableXlsxCsv 提前配置好.",
Documentation.WhoAskedTheRightQuestion = "www.jiaopengzi.com",
Documentation.Author = "焦棚子",
Documentation.Examples = {
[
Description = "1、从文件夹【订单信息】中合并表格,且不用文件名称添加列.",
Code = "TableXlsxCsv( " & """订单信息""" & ", 1, 0, false )",
Result = "当参数 IsAddColumn 为 false 时,后四个参数可以不写;从文件夹【订单信息】中每个表格从顶部移除 1 行后合并表,且不用文件名称添加列."
],
[
Description = "2、从文件夹【订单信息】中合并表格,使用文件名称按照规则添加列.",
Code = "TableXlsxCsv( " & """订单信息""" & ", 1, 3, true," & """数据日期""" & ", "&"""日期"""&", 12, 10 )",
Result
= "当参数 IsAddColumn 为 true 时,后四个参数必填;从文件夹【订单信息】中每个表格从顶部移除 1 行并且从底部移除 3 行后合并表,添加列的名称:数据日期,数据类型为:日期格式,按照文件名称从 12 个字符开始取 10 个字符."
]
}
],
fx1 = Value.ReplaceType(fx0, TypeMeta0)
in
fx1
M 代码复制到高级编辑器后保存后,必要配置就算完毕了。
3、TableXlsxCsv 调用
Ⅰ、数据源
首先来看一下数据源,在函数说明中介绍到,我们的自定义函数 TableXlsxCsv ,可以兼容 Xlsx、Xls、Csv 三种常见的本地文件,我们直接通过一个函数就可以解决了,不用去考虑表格是否筛选,表头有多行,同一个 Workbook 有多个相同的 WorkSheet等问题了。
在 data 文件夹下新建文件夹来管理同一字段表格,案例中文件夹是:01_订单,在前面配置名称管理时也可以看。
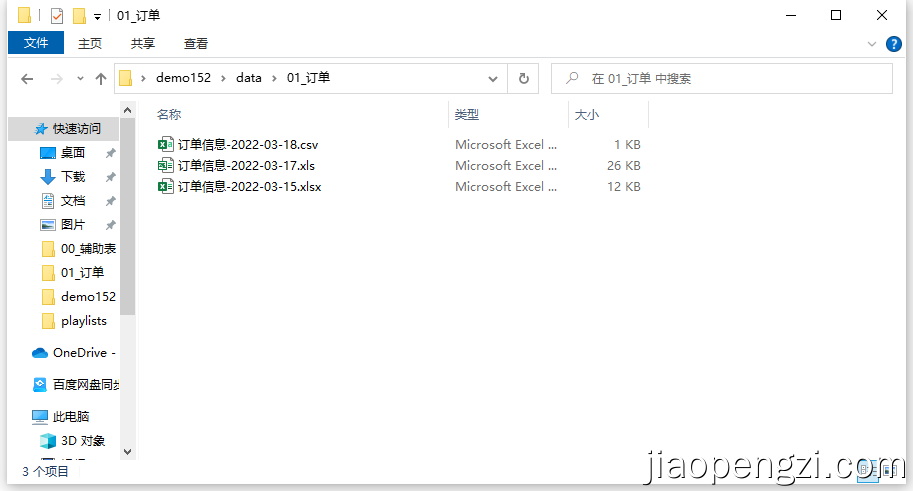
细心的朋友发现了,我们这个文件夹下是有三种数据类型。
我再看下具体的每个文件下的内容:
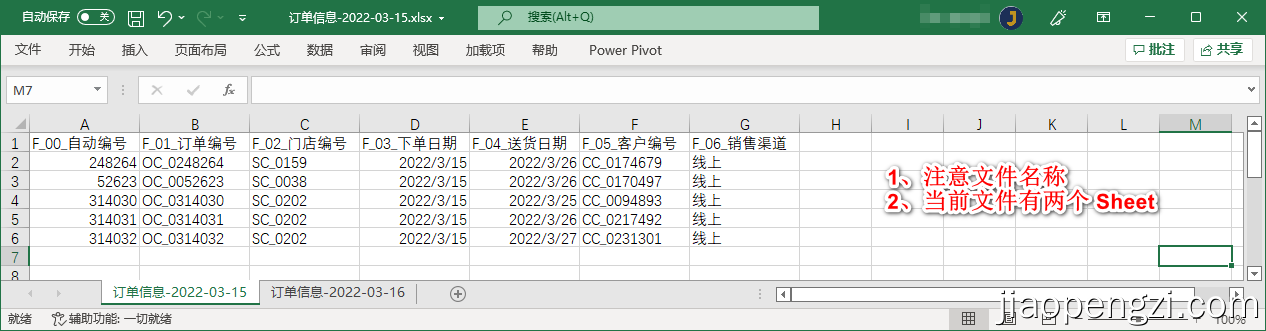
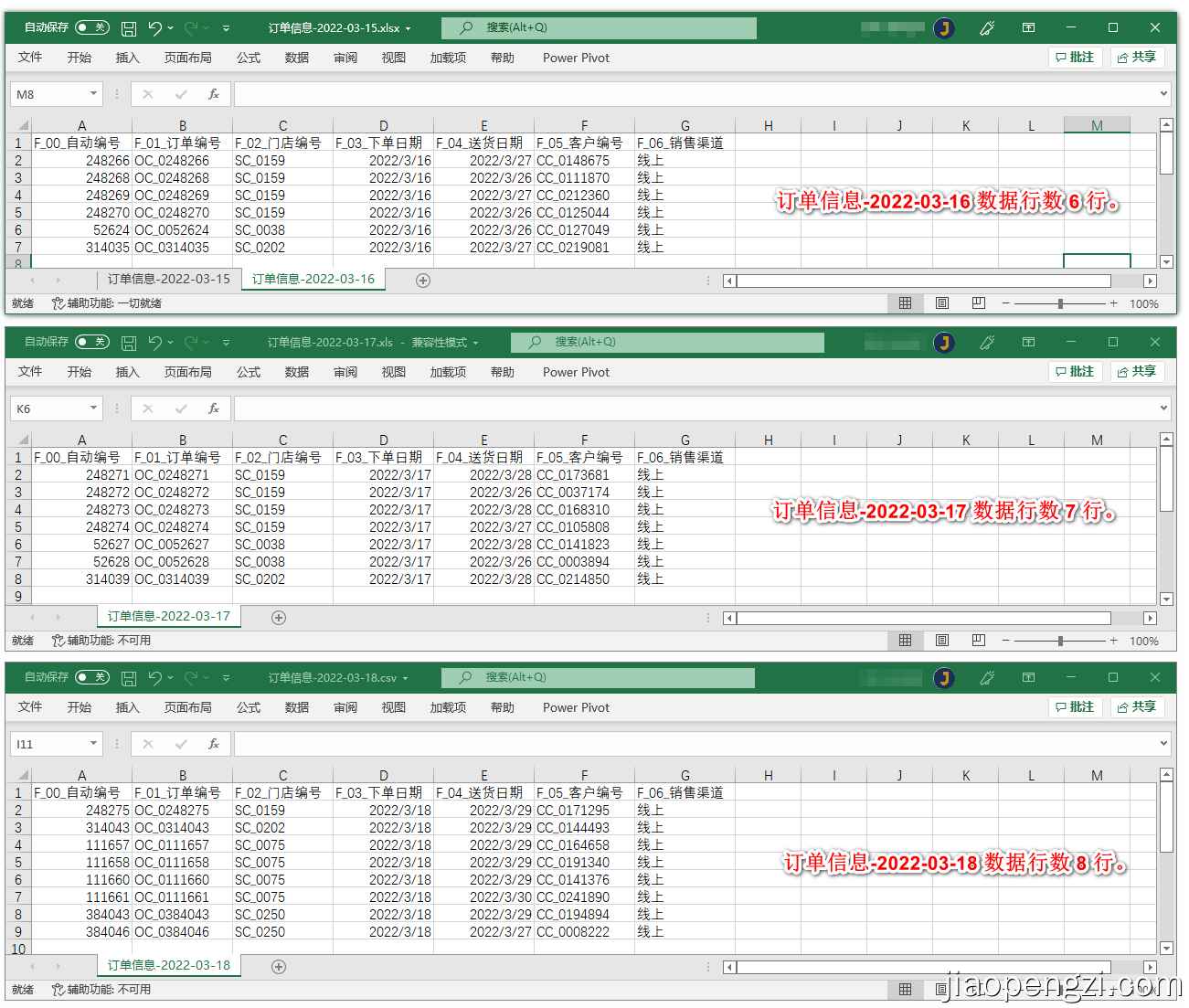
订单信息-2022-03-15 文件类型是 Xlsx,里面有 2 个Sheet 分别对应 15 号的数据和 16 号的数据,为了方便演示 15 号的 Sheet 中有 5 行数据, 16 号的 Sheet 中有 6 行数据。
订单信息-2022-03-17 文件类型是 Xls,里面只有 1 个Sheet 为了方便演示 17 号的文件中有 7 行数据。
订单信息-2022-03-15 文件类型是 Csv,为了方便演示 18 号的文件中有 8 行数据。
Ⅱ、函数调用
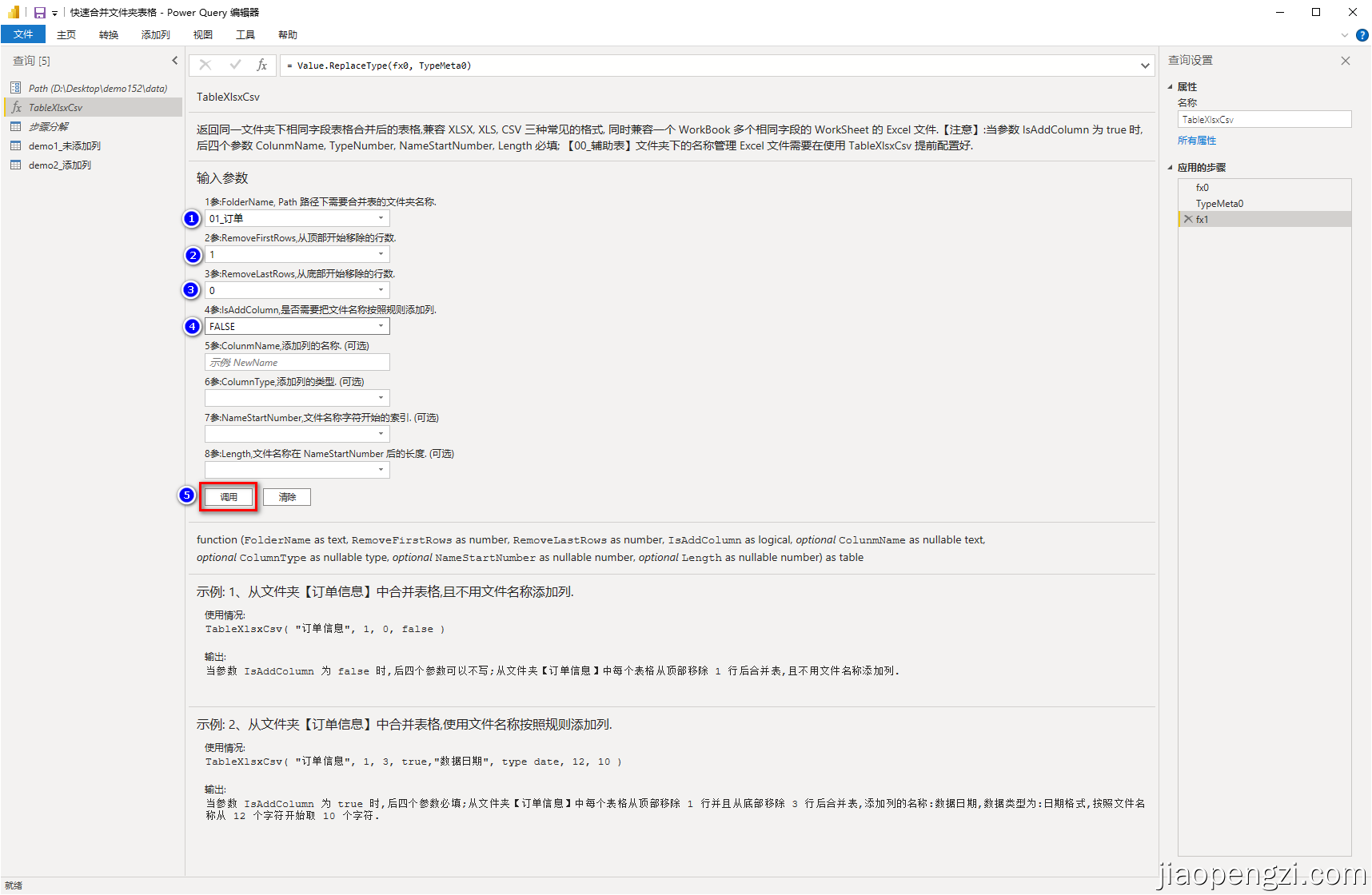
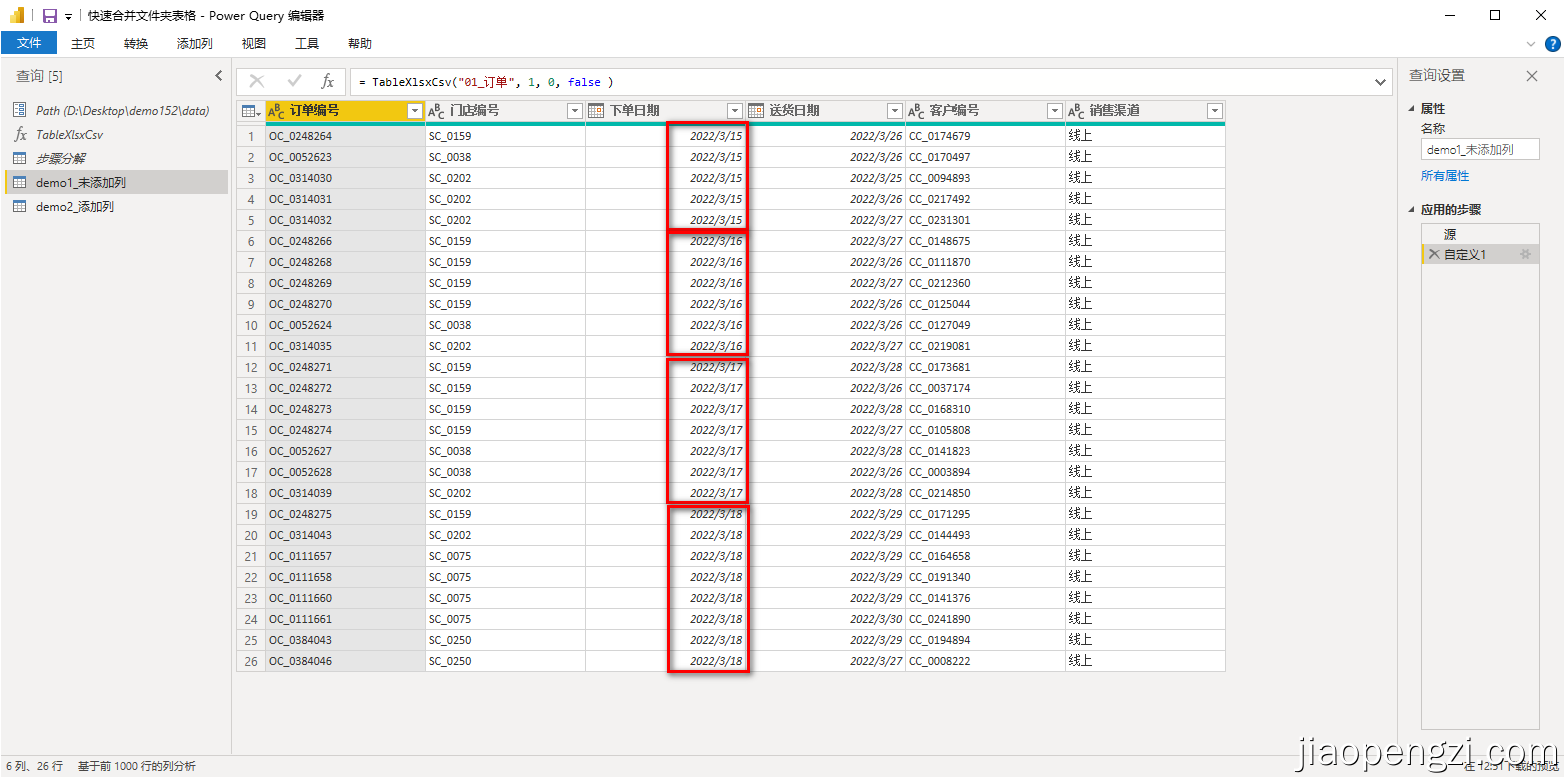
A、不添加列
按照图示输入信息后点击调用函数,即可得到新的查询,更改查询名称为自己需要的名称即可。
我们看到查询语句非常简单了,而且可以复用。
let
源 = TableXlsxCsv("01_订单", 1, 0, false )
in
源
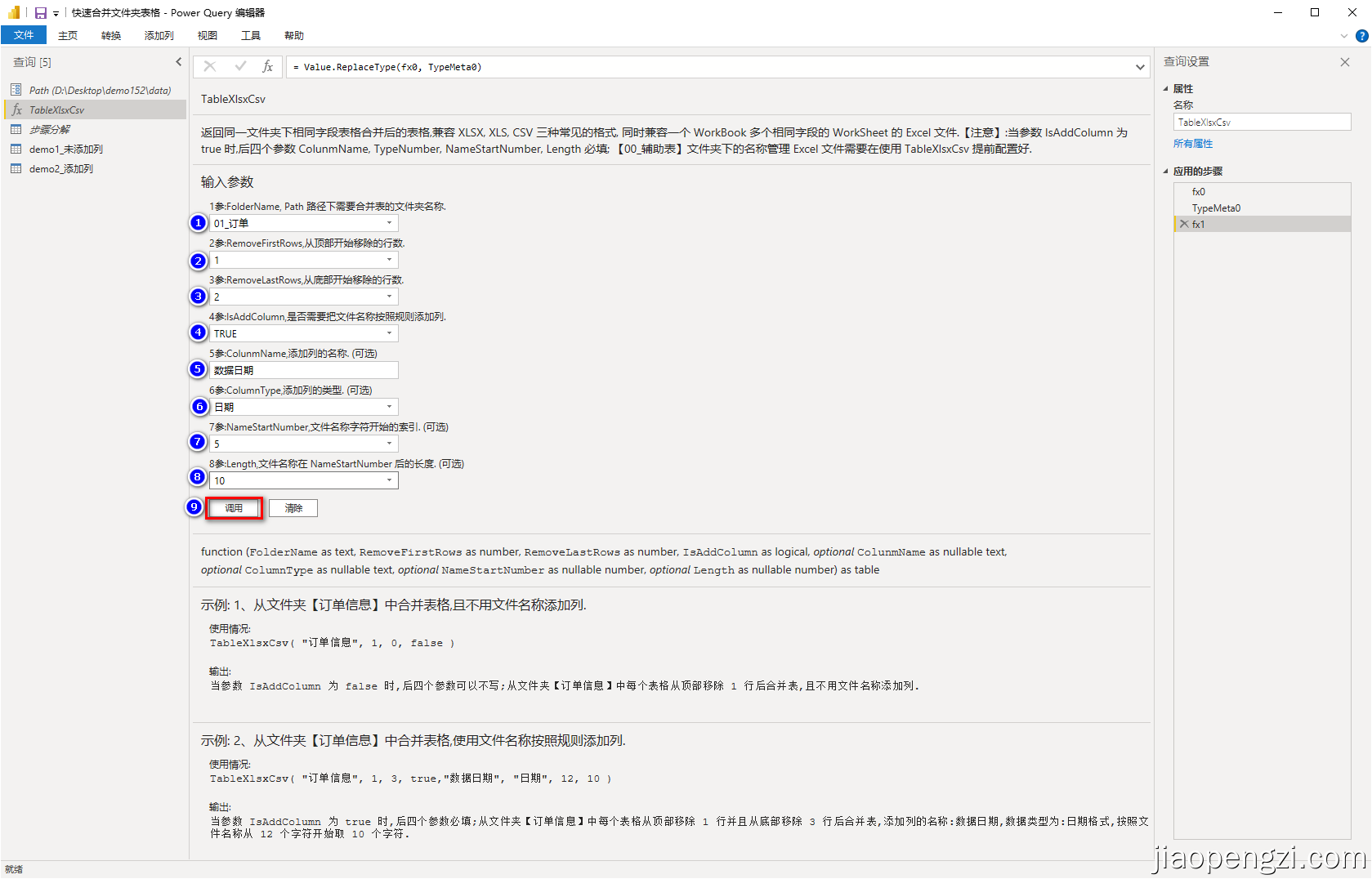
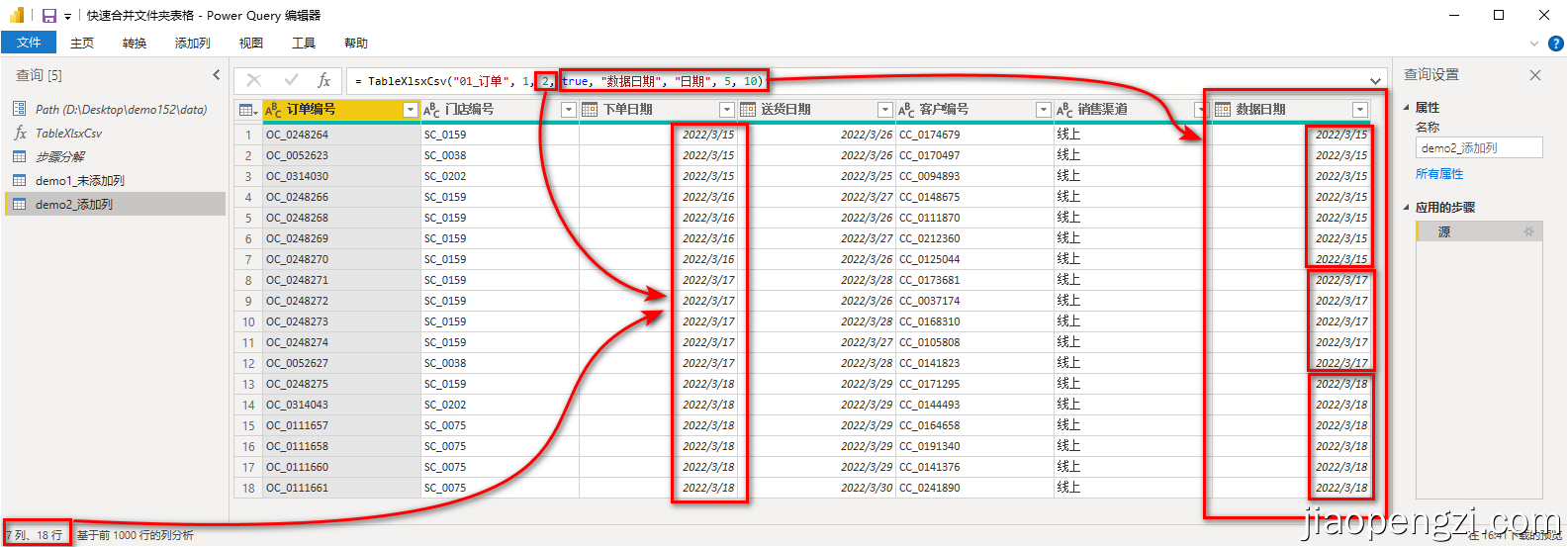
B、添加列
按照图示输入信息后点击调用函数,即可得到新的查询,更改查询名称为自己需要的名称即可。
注意:在需要添加列的情况下,后四个参数都是必填。
M 语句如下:
let
源 = TableXlsxCsv("01_订单", 1, 0, true, "数据日期", type date, 5, 10)
in
源
C、结果对比
- 结合前面的数据源,可以看到 Xlsx, Xls, Csv 在同一个文件夹中是可以通过一个我们写的自定义函数合并的。虽然我们做了三个中格式兼容,但从效率来讲我们更希望看到的是 Csv 格式。导出的平面文件 PQ 读取的效率高低顺序: Csv > Xlsx > Xls ,尽量不使用Xls, Xls 这种格式读取是比较慢。
- 看到下单日期,3 月 15 号和 3 月 16 号的数据在同一个 Workbook 的不同的 Sheet 里面,也是合并到了一起。
- 筛选的零时表也是剔除掉的。
- 每个字段的名称按照辅助表里名称管理的 Excel 配置的来重命名的。
- 每个字段的格式按照辅助表里名称管理的 Excel 配置的数据类型来设置的。
- 每个字段的显示按照辅助表里名称管理的 Excel 配置字段是否显示来显示的,如自动编号不显示,其它都显示出来了。
- 下图第一张是没有后四个参数的,也就没有添加列,第二张图片有后四个参数,在数据后添加了一列。需要注意的我的文件名称的格式:订单信息-2022-03-15 这个数据名称也是有将就的,年是四位数占位,月是和日都必须是两位数占位,比如这里的 3 月,就是 03 ;这里的规则其实使用的函数 Text.Middle 这个规则可以自己去修改。
- 最后的添加列,是对文件名称使用规则,而不是 Sheet 名称,比如这里的订单信息-2022-03-15 ,其中有两个 Sheet,最后添加列也是 3 月 15 号。
- 第二张第 4 参数为 2,每个表在合并前都移除了最后两行,可以和上述数据源作对比。
三、总结
1、我们自定义的这个函数,其实就是封装了 Excel.Workbook 和 Csv.Document 两个主要的函数。
2、当然如果自己写一个这样的函数的成本是很高的,我们写好的函数可以直接拿来用即可。
3、有了这函数以后,我们在做项目的时候就提高数据导入的效率,同时一张 Excel 来管理我们的数据字段。
4、有朋友可能会说直接使用数据库不更方便嘛,使用数据库也是完全可行的,但是更多的业务场景给的就是 Excel 、Csv 等文件,使用这个 PQ 自定义函数会更方便快捷。
5、这个函数的复用还体现在,我们的项目会多张,这样就有多个文件夹,我们通过名称管理的 Excel 文件,把需要的表格名称管理起来,同时建立好对应的文件夹,这样我们就可以直接快速的合并文件夹里面的内容了。比如如这样:

6、最后需要说明的一点,使用自定义函数合并的表格一定要自己校验。
7、附件中有详细的分解步骤,有兴趣的可以研究下。
by 焦棚子
152-技巧-Power Query 快速合并文件夹中表格之自定义函数 TableXlsxCsv的更多相关文章
- 【转载】C#代码开发过程中如何快速比较两个文件夹中的文件的异同
在日常的使用电脑的过程中,有时候我们需要比较两个文件夹,查找出两个文件夹中不同的文件以及文件中不同的内容信息,进行内容的校对以及合并等操作.其实使用Beyond Compare软件即可轻松比较,Bey ...
- PDF 补丁丁 0.4.1.804 测试版发布:合并文件夹的图片和PDF文件,自由生成多层次书签
新的测试版增强了合并文件的功能,可以合并文件夹内的图片和PDF文件,还可以在合并文件列表上直接指定与合并文件对应的PDF书签标题.通过拖放文件项目生成多层次的PDF书签.如下图所示: 另外,新的测试版 ...
- 运用CMD命令关于快速获取文件夹名称和快速建立文件夹
前些天头儿让我建立一本本的文件夹,让后交给我了几个命令,快速获取文件夹的名称和快速建立文件夹,省去了一个个的按F2,一个个的复制,粘贴,一个个的新建,再复制粘贴. 首先讲一下第一个问题,快速获取文件夹 ...
- [R语言]读取文件夹下所有子文件夹中的excel文件,并根据分类合并。
解决的问题:需要读取某个大文件夹下所有子文件夹中的excel文件,并汇总,汇总文件中需要包含的2部分的信息:1.该条数据来源于哪个子文件夹:2.该条数据来源于哪个excel文件.最终,按照子文件夹单独 ...
- C#合并文件夹图片列表 自定义排版顺序
本次程序编写主要为了将pdf word等文档转换为图片后设置不同的打印排版 前提 目标文件夹中的图片高宽都是一致的 /// <summary> /// 合并图片 /// </summ ...
- windows合并文件夹窗口
windows合并文件夹窗口 CreateTime--2017年7月26日16:28:14Author:Marydon 右击任务栏-->属性-->任务栏按钮选项-->选择“始终合 ...
- python 读取文件夹中所有同类型的文件 并用pandas合并
import globimport osimport pandas as pd read_path = 'D:/Data' # 要读取的文件夹的地址read_excel = glob.glob(os. ...
- Python win32com模块 合并文件夹内多个docx文件为一个docx
Python win32com模块 合并文件夹内多个docx文件为一个docx #!/usr/bin/env python # -*- coding: utf-8 -*- from win32com. ...
- 【C#操作Excel】同名Excel放入同一文件夹中,然后合并为同一个Excel文件
近期有对Excel操作的需求,由于都是重复劳动,故分享代码如下,本人也是技术菜鸟没有考虑性能,如果有大牛能够指教就再好不过了 事先电脑中需要安装Excel,然后Vs中引用Microsoft.Offic ...
随机推荐
- Altium design使用日常故障总结
1.altiumdesigner09如何将不同的板子拼在一起发给工厂?打开这两个图,其中一个图ctrl+a,ctrl+c,打开另一个图pastespecial.放置时选取一边对齐.制版时告诉厂家做个V ...
- Slog71_选取、上传和显示本地图片GET !(微信小程序之云开发-全栈时代3)
ArthurSlog SLog-71 Year·1 Guangzhou·China Sep 12th 2018 ArthurSlog Page GitHub NPM Package Page 掘金主页 ...
- 【uniapp 开发】文字缩略css
文字超出两行后显示省略号 display: -webkit-box; overflow: hidden; text-overflow: ellipsis; word-wrap: break-word; ...
- 使用 ssm 实现登录日志记录
使用 ssm 实现登录日志记录 学习总结 一.基础准备 1. 实现效果 2. 数据表 2.1 登陆日志信息表 2.3 员工表 二.代码实现 1. SysLogLogin 实体类 2. LogAspec ...
- 虚拟机安装linux
https://blog.csdn.net/wujiele/article/details/92803655https://www.cnblogs.com/yunwangjun-python-520/ ...
- android软件简约记账app开发day06-将记账条目添加到数据库并且绘制备注页面
android软件简约记账app开发day06-将记账条目添加到数据库并且绘制备注页面 首先写添加到数据库 在DBOpenHelper中添加创建记账表的语句 //创建记账表 sql = "c ...
- Java语言学习day07--7月6日
今日内容介绍1.流程控制语句switch2.数组 ###01switch语句解构 * A:switch语句解构 * a:switch只能针对某个表达式的值作出判断,从而决定程序执行哪一段代码. * ...
- 2021.08.09 P7238 迷失森林(树的直径)
2021.08.09 P7238 迷失森林(树的直径) P7238 「DCOI」迷失森林 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 重点: 1.树的直径两种求法:两次dfs.树 ...
- RecyclerView + SQLite 简易备忘录-----下
最后就是添加备忘录的界面了.同时也是显示备忘录内容的界面. 1.activity_add_info.xml 也是比较简陋的一个页面设计. 顶部是一个自定义的Toolbar,剩下的部分都是ScrollV ...
- 使用vscode编辑markdown文件(可粘贴截图)
使用markdown粘贴截图时,操作步骤比较多: 1)截取图片: 2)将图片存在特定位置: 3)记住图片路径,在markdown文件中编写代码: 4)预览效果: 而word之类的文档编辑器,只需要截图 ...