PCA原理及其代码实现
首先简述一下PCA的作用:
PCA是一种线性降维方法,它的目标i是通过某种线性投影,将高维的数据映射到低维空间中,并期望在所投影的维度上数据的信息量最大(方差最大),以此使用较少的数据维度,同时保留较多的原数据点的特性。
PCA降维的目的,就是为了尽量保证“信息量”不丢失的情况下,对原始特征进行降维,也就是尽可能将原始特征往具有最大投影信息量的维度上进行投影,将原始特征投影到这些维度上,使降维后信息量最小。
PCA算法主要步骤:
去除平均值
计算协方差矩阵
计算协方差矩阵的特征值和特征向量
将特征值进行排序
保留前N个最大的特征值对应的特征向量
将原始特征转换到上面得到的N个特征向量构建的新空间中
注:最后两步也就是实现了特征压缩
举个例子:
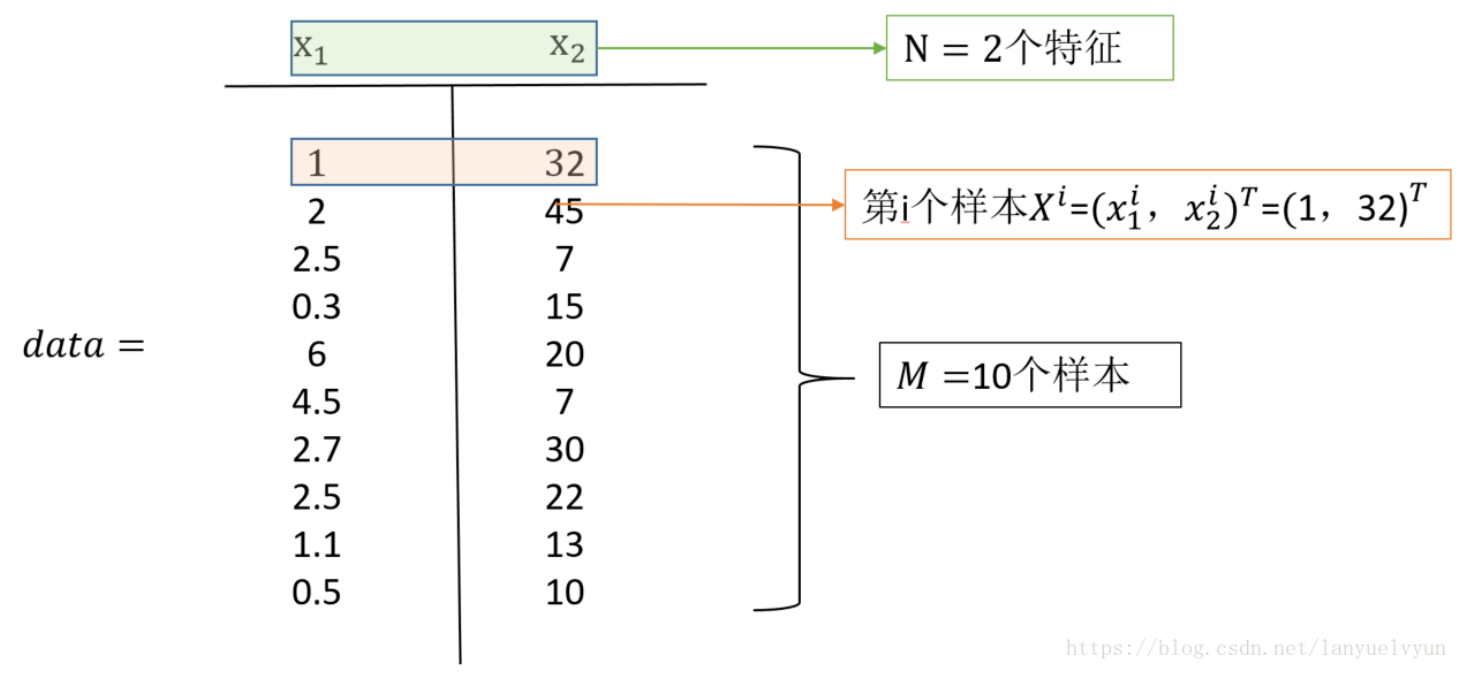
简单论述一下PCA相关的数学概念:
随机变量的数字特征:
均值:描述一维随机变量,表明信息是有限的
方差,标准差:描述一维随机变量的数据的“散布度”
协方差:度量两个随机变量关系的统计量
方差定义:
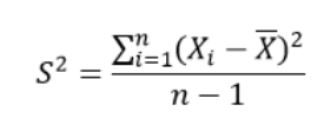
标准差定义:
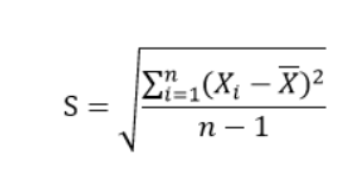
协方差定义:
度量两个随机变量的相似程度,
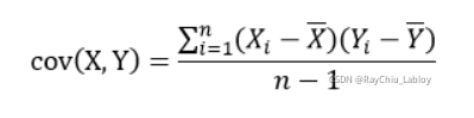
详细步骤说明:
求每一个特征的平均值,然后对于所有样本,每一个特征都减去自身的均值,经过去均值的处理之后,原始特征的值就变成了新的值,在这个新的数据的基础上,在进行接下来的操作
求协方差矩阵C
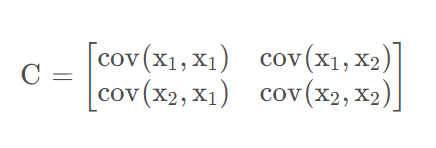
上述矩阵中,对角线上分别是特征x1和x2的方差,非对角线上的是协方差。协方差大于0,表示x1和x2正相关,小于0表示负相关,等于0,互相独立。协方差绝对值越大,两者对彼此的影响越大,反之越小。
之所以除n-1,是因为这样能使我们以较小的样本集更好的逼近总体的标准差,即统计上的“无偏估计”。
求协方差矩阵C的特征值和相对应的特征向量
同线性代数中求解特征向量步骤一样!!!!!
为什么样本在“协方差矩阵C的最大K个特征值所对应的特征向量”上的投影就是k维理想特征?
根据最大方差理论:方差越大,信息量就越大。协方差矩阵的每一个特征向量就是一个投影面,每一个特征向量所对应的特征值就是原始特征投影到这个投影面之后的方差。由于投影过去之后,要尽量保证信息不丢失,所以要选择具有较大方差的投影面对原始特征进行投影,也就是选择具有较大特征值的特征向量。然后,将原始特征投影在这些特征向量上,投影后的值就是新的特征值。每一个投影面生成一个新的特征,k个投影面就生成新k个新特征。
代码实现:
import numpy as np class PCA():
# 计算协方差矩阵
def calc_cov(self, X):
m = X.shape[0]
# 数据标准化
X = (X - np.mean(X, axis=0)) / np.var(X, axis=0)
return 1 / m * np.matmul(X.T, X) def pca(self, X, n_components):
# 计算协方差矩阵
cov_matrix = self.calc_cov(X)
# 计算协方差矩阵的特征值和对应特征向量
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix)
# 对特征值排序
idx = eigenvalues.argsort()[::-1]
# 取最大的前n_component组
eigenvectors = eigenvectors[:, idx]
eigenvectors = eigenvectors[:, :n_components]
# Y=PX转换
return np.matmul(X, eigenvectors)
from sklearn import datasets
import matplotlib.pyplot as plt # 导入sklearn数据集
iris = datasets.load_iris()
X = iris.data
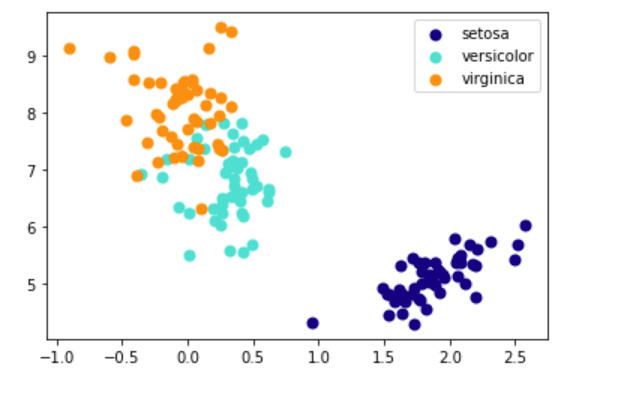
y = iris.target # 将数据降维到3个主成分
X_trans = PCA().pca(X, 3)
# 颜色列表
colors = ['navy', 'turquoise', 'darkorange'] # 绘制不同类别
for c, i, target_name in zip(colors, [0,1,2], iris.target_names):
plt.scatter(X_trans[y == i, 0], X_trans[y == i, 1],
color=c, lw=2, label=target_name)
# 添加图例
plt.legend()
plt.show()
结果:
PCA原理及其代码实现的更多相关文章
- Kernel PCA 原理和演示
Kernel PCA 原理和演示 主成份(Principal Component Analysis)分析是降维(Dimension Reduction)的重要手段.每一个主成分都是数据在某一个方向上的 ...
- 主成分分析(PCA)原理与实现
主成分分析原理与实现 主成分分析是一种矩阵的压缩算法,在减少矩阵维数的同时尽可能的保留原矩阵的信息,简单来说就是将 \(n×m\)的矩阵转换成\(n×k\)的矩阵,仅保留矩阵中所存在的主要特性,从 ...
- flume原理及代码实现
转载标明出处:http://www.cnblogs.com/adealjason/p/6240122.html 最近想玩一下流计算,先看了flume的实现原理及源码 源码可以去apache 官网下载 ...
- Java Base64加密、解密原理Java代码
Java Base64加密.解密原理Java代码 转自:http://blog.csdn.net/songylwq/article/details/7578905 Base64是什么: Base64是 ...
- Base64加密解密原理以及代码实现(VC++)
Base64加密解密原理以及代码实现 转自:http://blog.csdn.net/jacky_dai/article/details/4698461 1. Base64使用A--Z,a--z,0- ...
- AC-BM算法原理与代码实现(模式匹配)
AC-BM算法原理与代码实现(模式匹配) AC-BM算法将待匹配的字符串集合转换为一个类似于Aho-Corasick算法的树状有限状态自动机,但构建时不是基于字符串的后缀而是前缀.匹配 时,采取自后向 ...
- Java基础知识强化之集合框架笔记47:Set集合之TreeSet保证元素唯一性和比较器排序的原理及代码实现(比较器排序:Comparator)
1. 比较器排序(定制排序) 前面我们说到的TreeSet的自然排序是根据集合元素的大小,TreeSet将它们以升序排列. 但是如果需要实现定制排序,比如实现降序排序,则要通过比较器排序(定制排序)实 ...
- PHP网站安装程序的原理及代码
原文:PHP网站安装程序的原理及代码 原理: 其实PHP程序的安装原理无非就是将数据库结构和内容导入到相应的数据库中,从这个过程中重新配置连接数据库的参数和文件,为了保证不被别人恶意使用安装文件,当安 ...
- 免费的Lucene 原理与代码分析完整版下载
Lucene是一个基于Java的高效的全文检索库.那么什么是全文检索,为什么需要全文检索?目前人们生活中出现的数据总的来说分为两类:结构化数据和非结构化数据.很容易理解,结构化数据是有固定格式和结构的 ...
随机推荐
- HTML 本地缓存
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="UTF-8" /> 5 & ...
- 多云部署多主模式的MGR集群,每个云一个MGR 节点,满足业务单元化改造的需求
欢迎来到 GreatSQL社区分享的MySQL技术文章,如有疑问或想学习的内容,可以在下方评论区留言,看到后会进行解答 GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 本 ...
- Java SE 9 新增特性
Java SE 9 新增特性 作者:Grey 原文地址: Java SE 9 新增特性 源码 源仓库: Github:java_new_features 镜像仓库: GitCode:java_new_ ...
- Java SE 13 新增特性
Java SE 13 新增特性 作者:Grey 原文地址:Java SE 13 新增特性 源码 源仓库: Github:java_new_features 镜像仓库: GitCode:java_new ...
- PostgreSQL 时间函数分类与特性
KingbaseES 时间函数有两大类:返回事务开始时间和返回语句执行时的时间.具体函数看以下例子: 1.返回事务开始时的时间 以下函数返回事务开始的时间(通过 begin .. end 两次调用结果 ...
- electron 起步
electron 起步 为什么要学 Electron,因为公司需要调试 electron 的应用. Electron 是 node 和 chromium 的结合体,可以使用 JavaScript,HT ...
- Windows DNS服务器策略
Windows 2016开始微软在Windows服务器中引入了针对DNS服务器的策略.可以方便灵活的控制DNS服务器响应客户端的请求.这里举个例子,阻止某个网段的DNS查询.思路是这样的,定义一个网段 ...
- 【To B产品怎么做?】泛用户体验
目录 - 什么是泛用户体验? - 如何做好泛用户体验? - 泛用户体验有什么用? *预计阅读时间15分钟 不知道你有没有过这种体验,客服妹子的声音软糯,氛围微妙,用词标准,张口就是:给你带来了不好的体 ...
- 使用django_registration框架实现用户的注册与激活
1.前言 本节内容是在以下环境中实现的. python version: 3.7 Django version: 3.1.1 Django-registration version: 3.1.1 如版 ...
- Django 创建 APP和目录结构介绍
一.通过pip安装Django 以windows 系统中使用pip命令安装为例 win+r,调出cmd,运行命令:pip install django自动安装PyPi 提供的最新版本.指定版本,可使用 ...