Serverless Streaming:毫秒级流式大文件处理探秘
摘要:本文将以图片处理的场景作为例子详细描述当前的问题以及华为云FunctionGraph函数工作流在面对该问题时采取的一系列实践。
文章作者|旧浪:华为云Serverless研发专家、平山:华为云中间件Serverless负责人
一、背景
企业应用从微服务架构向 Serverless(无服务器)架构演进,开启了无服务器时代,面向无服务器计算领域的 Serverless 工作流也应运而生。许多Serverless 应用程序不是由单个事件触发的简单函数,而是由一系列函数多个步骤组成的,而函数在不同步骤中由不同事件触发。Serverless工作流用于将函数编排为协调的微服务应用程序。
Serverless工作流由于自身可编排、有状态、持久化、可视化监控、异常处理、云服务集成等特性,适用于很多应用场景,比如:
- 复杂度高需要抽象的业务(订单管理,CRM等)
- 业务需要自动中断/恢复能力,如多个任务之间需要人工干预的场景(人工审批,部署流水线等)
- 业务需要手动中断/恢复(数据备份/恢复等)
- 需要详细监控任务执行状态的场景
- 流式处理(日志分析,图片/视频处理等)
当前大部分Serverless Workflow平台更多关注控制流程的编排,忽视了工作流中数据流的编排和高效传输,上述场景1-4中,由于数据流相对简单,所以各大平台支持都比较好,但是对于文件转码等存在超大数据流的场景,当前各大平台没有给出很好的解决方案。华为云FunctionGraph函数工作流针对该场景,提出了Serverless Streaming的流式处理方案,支持毫秒级响应文件处理。本文将以图片处理的场景作为例子详细描述当前的问题以及华为云FunctionGraph函数工作流在面对该问题时采取的一系列实践。
二、问题描述
先以一个图片处理的场景举例,用户想要执行一个图片压缩并且加水印的任务,这个场景在典型的工作流系统中,可以用如图一所示的方式进行处理。
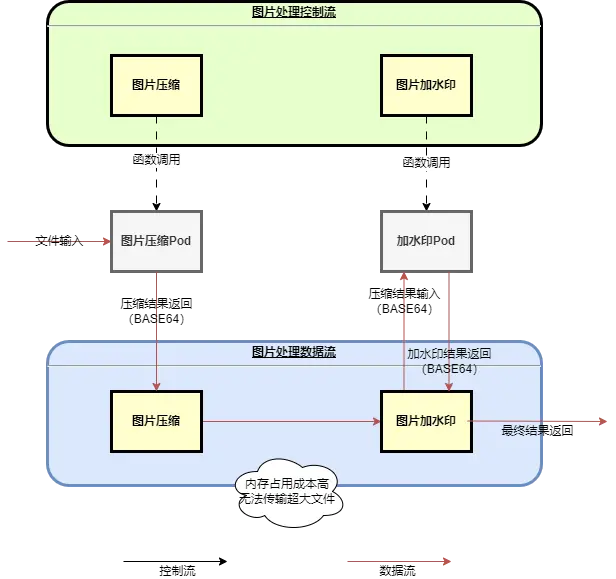
图1:一个典型的图片处理工作流
如上图所示,图片压缩和图片加水印的结果都是二进制文件格式,但是当前主流的Serverless Workflow平台在多个步骤之间传输上下文都只能支持文本格式传输,所以图片压缩和加水印的结果都需要经过BASE64或者其他转码方式转成文本进行数据流传输。
但是这种方案的限制和使用成本都比较高:
- 函数的Response Body通常有大小限制,所以这种方式无法处理超大文件。
- 执行结果转换为文本,需要消耗大量内存,内存成本比较高。
如何简单高效的进行文件处理,业界也给出了其他解决方案,如通过云存储进行中间结果转储、AWS的Lambda Object文件转换方案。下面给出了这两个方案的优缺点分析。
方案一:中间结果通过云存储进行转储
该方案如图2所示:
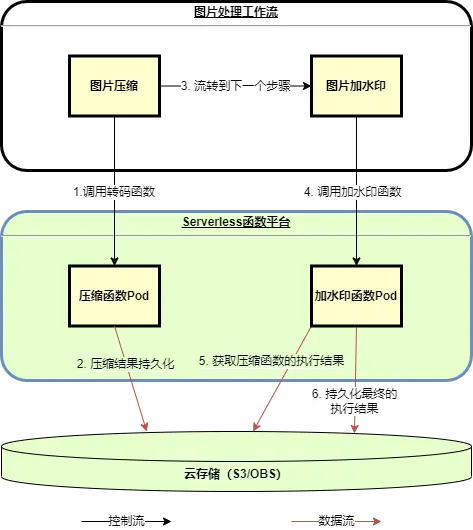
图2:云存储转储运行方式示意图
两个步骤之间的文件流通过云存储去传递,这种方案支持大文件流的传输,但是由于中间多了一次到云存储的网络传输,如果业务对时延要求不高,该方案问题不大,但是对于时延敏感类业务,这种多出的时延是无法接受的。另外云存储转储需要额外的成本,如果调用量比较大,使用成本较高。
方案二:AWS Lambda Object
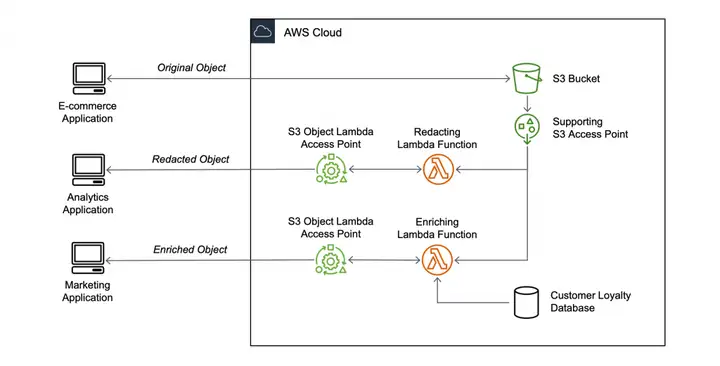
图3:AWS解决方案示意图[1]
AWS对于这种文件处理场景,提出了基于S3和Lambda的Lambda Object的方案,参考[1],简单来说,是支持为S3文件桶的getObject API提供Access Point,AccessPoint可以指向某一个Lambda函数,在函数中可以对原来的桶数据文件进行修改,比如可以将原始视频转码,得到转码后的结果返回到客户端。虽然解决了时延和大文件处理的问题,但是这个方案强依赖S3的API,用户无法进行流程编排,也无法通过事件触发,不是一个真正通用的方案。
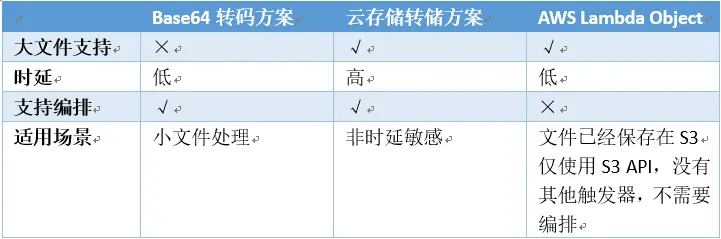
业界方案总结
简单总结如表1所示,当前业界提供的各个方案或多或少存在一些局限性,没有办法在同时满足低时延的情况下支持可编排的文件处理。然而低时延和可编排都是大量客户所追求的关键能力,如何解决这些关键痛点,提升客户体验,成为了当前我们重点想要攻克的难题。
表1:业界文件处理方案对比
三、华为云FunctionGraph的Serverless Streaming流式处理方案
针对当前业界缺少高效,可编排的文件处理方案的痛点,华为云FunctionGraph函数工作流提出Serverless Streaming的流式可编排的文件处理解决方案,步骤与步骤之间通过数据流驱动,更易于用户理解。本章通过图片处理的例子解释该方案的实现机制。
如果需要驱动一个工作流执行,工作流系统需要处理两个部分:
- 控制流:控制工作流的步骤间流转,以及步骤对应的Serverless函数的执行。确保步骤与步骤之间有序执行。
- 数据流:控制整个工作流的数据流转,通常来说上一个步骤的输出是下一个步骤的输入,比如上述图片处理工作流中,图片压缩的结果是打水印步骤的输入数据。
在普通的服务编排中,由于需要精准控制各个服务的执行顺序,所以控制流是工作流的核心部分。然而在文件处理等流式处理场景中,对控制流的要求并不高,以上述图片处理场景举例,可以对大图片进行分块处理,图片压缩和加水印的任务不需要严格的先后顺序,图片压缩处理完一个分块可以直接流转到下一个步骤,而不需要等待图片压缩把所有分块处理完再开始加水印的任务。
基于上述理解,华为云FunctionGraph工作流的Serverless Streaming方案架构设计如图四所示:
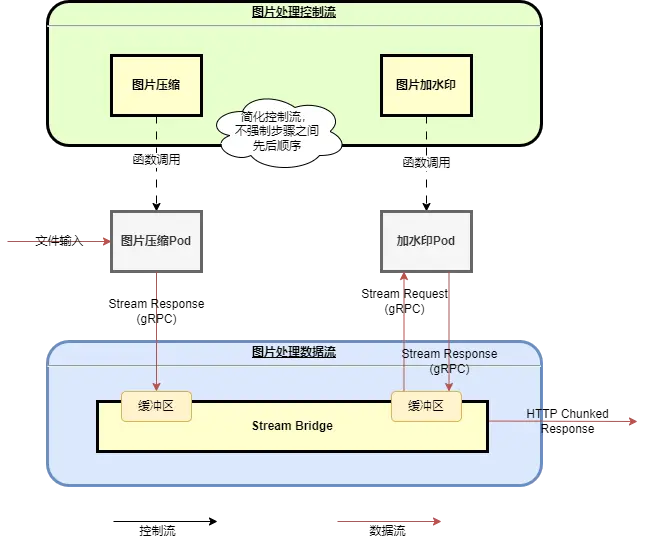
图4: Serverless Streaming流式处理架构图
在Serverless Streaming的流程中,弱化控制流中步骤之间的先后执行顺序,允许异步同时执行,步骤与步骤之间的交互通过数据流驱动。其中数据流的控制通过Stream Bridge组件来实现。
同时函数SDK增加流式数据返回接口,用户不需要将整个文件内容返回,而是通过gRPC Stream的方式将数据写入到Stream Bridge,Stream Bridge用来分发数据流到下一个步骤的函数Pod中。
这种方式存在如下优点:
- 由于控制流的弱化,完全通过数据流来驱动流程执行,不需要再强限制步骤之间完成的先后顺序,如图片处理场景中,压缩和加水印的步骤可以做到完全并行执行,这样可以加速整个流程的执行速度。
- 每次请求都开辟独立缓冲区,缓冲区限制大小,数据流仅在内网传输,保证整体数据传输的可靠性和安全性。
- 不依赖其他外部服务,使用成本低。
- 对于开发人员来讲,只需要关注数据流的处理,而不需要关心数据流如何转发,如何存储,降低开发难度。
- 底层流式传输通过gRPC进行,整体数据传输效率高
在FunctionGraph中开发文件处理工作流
当前FunctionGraph已经基于上述方案支持了在函数工作流中进行数据流处理,并且将结果通过流数据的方式返回到客户端,以构建一个图片处理工作流举例:
1、首先创建一个图片压缩的函数,其中代码在处理返回数据通过ctx.Write()函数将结果以流式数据的形式返回:
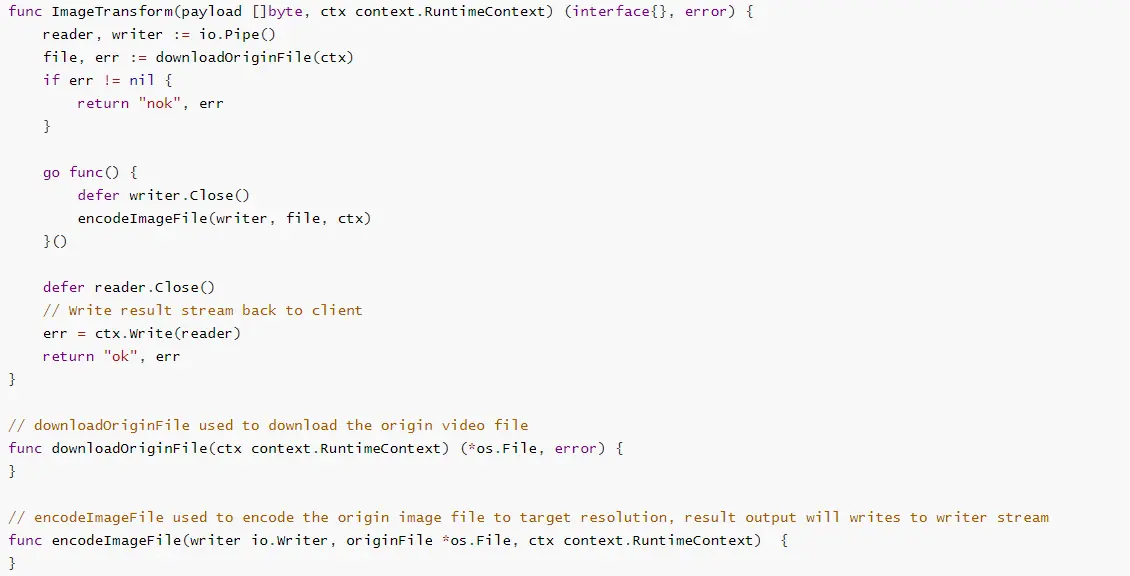
FunctionGraph通过ctx.Write()函数提供了流式返回的能力,对开发者来说,只需要将最终结果通过流的方式返回,而不需要关注网络传输的细节。
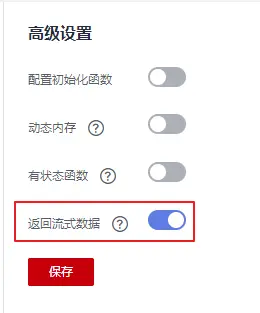
2、在函数控制台中启用该函数的流式返回能力
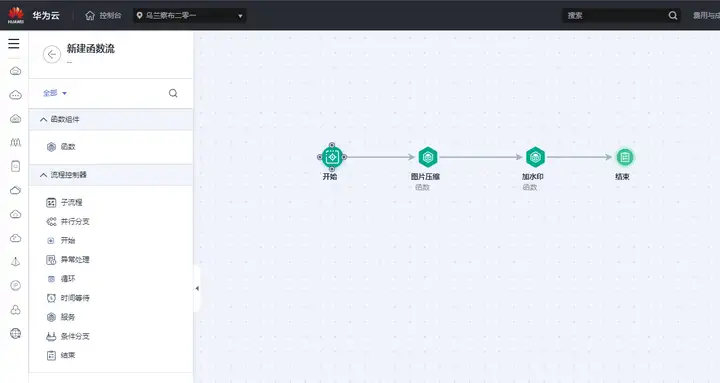
3、用上面的方式完成其他函数的编写,最后在FunctionGraph的函数流控制台完成工作流编排,举例如下:
4、调用工作流的同步执行接口,获取最终结果的文件流,数据将以chunked流式返回的方式返回到客户端
使用效果
针对图片处理的具体场景,我们测试对比了不同大小图片(333k、1m、4m、7m、10m、12m)进行图片切割和图片压缩的场景,由于BASE64转码方案无法支持大文件,AWS Lambda Object方案无法支持编排,所以这里只对比使用OBS转储方案和基于流式返回的Servlerss Streaming方案的时延数据。具体对比数据图表如下:
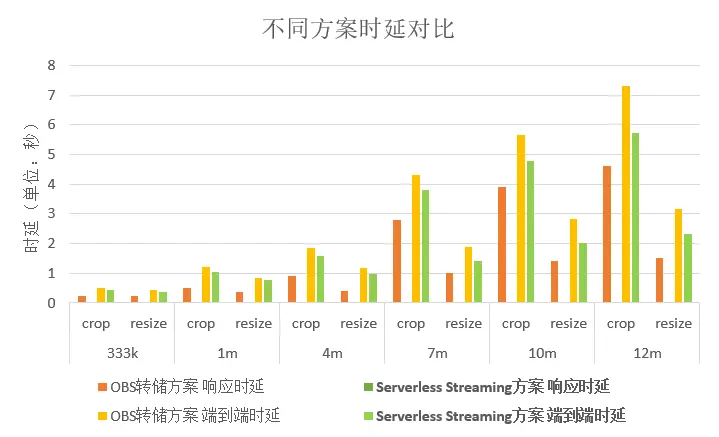
图5:测试数据对比
响应时延:指客户端发出请求到收到第一个字节消耗的时延(单位:秒)
端到端时延:指客户端发出请求到收到最后一个字节消耗的时延(单位:秒)
从测试数据可以看出,响应时延和端到端时延使用流式返回方案后都得到了不同程度的降低。其中响应时延降低幅度较大,OBS转储方案响应时延随着图片大小增大,响应时延呈线性上升,超过4M的图片响应时延就达到秒级,使用流式返回方案后,响应时延持续稳定在毫秒级的水平。从中可以发现,基于Serverless Streaming的流式返回方案不仅具备流式处理和可编排的能力,并且在文件处理场景中可以显著降低时延,从多个方面提升了用户使用体验。
四、总结与展望
本文主要讨论了Serverless Workflow在大文件处理时碰到的问题,FunctionGraph通过简化数据传输链路,提升文件流处理效率, 给出了一种稳定高效、极低时延的大文件处理方法 Serverless Streaming,支持毫秒级的文件流式处理, 显著改善函数编排在文件处理等场景中的用户体验。
FunctionGraph作为华为元戎加持的下一代Serverless函数计算与编排服务,将围绕通用全场景 Serverless的前沿理论及案例实践,持续分享,回馈社区。
参考资料:
[1] Introducing Amazon S3 Object Lambda
https://aws.amazon.com/cn/blogs/aws/introducing-amazon-s3-object-lambda-use-your-code-to-process-data-as-it-is-being-retrieved-from-s3/
Serverless Streaming:毫秒级流式大文件处理探秘的更多相关文章
- Spark Streaming:大规模流式数据处理的新贵(转)
原文链接:Spark Streaming:大规模流式数据处理的新贵 摘要:Spark Streaming是大规模流式数据处理的新贵,将流式计算分解成一系列短小的批处理作业.本文阐释了Spark Str ...
- Spark Streaming:大规模流式数据处理的新贵
转自:http://www.csdn.net/article/2014-01-28/2818282-Spark-Streaming-big-data 提到Spark Streaming,我们不得不说一 ...
- 流式大数据计算实践(1)----Hadoop单机模式
一.前言 1.从今天开始进行流式大数据计算的实践之路,需要完成一个车辆实时热力图 2.技术选型:HBase作为数据仓库,Storm作为流式计算框架,ECharts作为热力图的展示 3.计划使用两台虚拟 ...
- 翻译-In-Stream Big Data Processing 流式大数据处理
相当长一段时间以来,大数据社区已经普遍认识到了批量数据处理的不足.很多应用都对实时查询和流式处理产生了迫切需求.最近几年,在这个理念的推动下,催生出了一系列解决方案,Twitter Storm,Yah ...
- 流式大数据计算实践(6)----Storm简介&使用&安装
一.前言 1.这一文开始进入Storm流式计算框架的学习 二.Storm简介 1.Storm与Hadoop的区别就是,Hadoop是一个离线执行的作业,执行完毕就结束了,而Storm是可以源源不断的接 ...
- Java-使用IO流对大文件进行分割和分割后的合并
有的时候我们想要操作的文件很大,比如:我们想要上传一个大文件,但是收到上传文件大小的限制,无法上传,这是我们可以将一个大的文件分割成若干个小文件进行操作,然后再把小文件还原成源文件.分割后的每个小文件 ...
- Java中使用IO流实现大文件的分裂与合并
文件分割应该算一个比较实用的功能,举例子说明吧比如说:你有一个3G的文件要从一台电脑Copy到另一台电脑, 但是你的存储设备(比如SD卡)只有1G ,这个时候就可以把这个文件切割成3个1G的文件 ,分 ...
- Java缓冲流高效大文件的复制实例
public class BufferedDemo { public static void main(String[] args) throws FileNotFoundException { // ...
- 流式大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.本文将对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的 ...
- [转载]流式大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.本文将对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的 ...
随机推荐
- 06#Web 实战:实现可滑动的标签页
实现效果图 本随笔只是记录一下大概的实现思路,如果感兴趣的小伙伴可以通过代码和本随笔的说明去理解实现过程.我的 Gitee 和 GitHub 地址.注意哦:这个只是 PC 上的标签页,手机端的没用,因 ...
- NLP实践!文本语法纠错模型实战,搭建你的贴身语法修改小助手 ⛵
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 自然语言处理实战系列:https://www.showmeai.tech ...
- 记一次 .NET 某电子厂OA系统 非托管内存泄露分析
一:背景 1.讲故事 这周有个朋友找到我,说他的程序出现了内存缓慢增长,没有回头的趋势,让我帮忙看下到底怎么回事,据朋友说这个问题已经困扰他快一周了,还是没能找到最终的问题,看样子这个问题比较刁钻,不 ...
- node-sass报错(Node Sass could not find a binding for your current environment)
解决方案:参考 https://stackoverflow.com/questions/37986800/node-sass-couldnt-find-a-binding-for-your-curre ...
- Python开发Brup插件检测SSRF漏洞和URL跳转
作者:馒头,博客地址:https://www.cnblogs.com/mantou0/ 出身: 作为一名安全人员,工具的使用是必不可少的,有时候开发一些自己用的小工具在渗透时能事半功倍.在平常的渗透测 ...
- static_cast和dynamic_cast
C++的强制类型转换,除了继承自C语言的写法((目标类型)表达式)之外,还新增了4个关键字,分别是:static_cast.dynamic_cast.const_cast和reinterpret_ca ...
- 什么是django中间件?(七个中间件-自定义中间件)
目录 一:django中间件 1.什么是django中间件 2.django请求生命周期流程图 二:django自带七个中间件 1.研究django中间件代码规律 2.django支持程序员自定义中间 ...
- ExcelToObject.NPOI 两行代码导出Excel报表、读取Excel数据
简介 作为一个dotnet开发者,经常面对业务系统中大量报表导入导出,经常写了一堆的重复代码.最近发现一个操作excel的神器:ExcelToObject.NPOI,两行代码就能导出一个报表,两行代码 ...
- Ubuntu 22.04 LTS 安装 0.A.D 实时策略游戏 并汉化
众所周知,Linux生态中,能玩的正儿八经的大型游戏其实没几个,而 0.A.D 这个游戏就是这其中之一.这是一个类似于帝国时代的实时策略游戏,开源跨平台,这是其官方网站:https://play0ad ...
- 强化学习调参技巧二:DDPG、TD3、SAC算法为例:
1.训练环境如何正确编写 强化学习里的 env.reset() env.step() 就是训练环境.其编写流程如下: 1.1 初始阶段: 先写一个简化版的训练环境.把任务难度降到最低,确保一定能正常训 ...