让Apache Beam在GCP Cloud Dataflow上跑起来
简介
在文章《Apache Beam入门及Java SDK开发初体验》中大概讲了Apapche Beam的简单概念和本地运行,本文将讲解如何把代码运行在GCP Cloud Dataflow上。
本地运行
通过maven命令来创建项目:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.37.0 \
-DgroupId=org.example \
-DartifactId=word-count-beam \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
上面会创建一个目录word-count-beam,里面是一个例子项目。做一些简单修改就可以使用了。
先build一次,保证依赖下载成功:
$ mvn clean package
通过IDEA本地运行一下,添加入参如下:
--output=pkslow-beam-counts --inputFile=/Users/larry/IdeaProjects/pkslow-samples/README.md
处理的文件是README.md,输出结果前缀为pkslow-beam-counts:
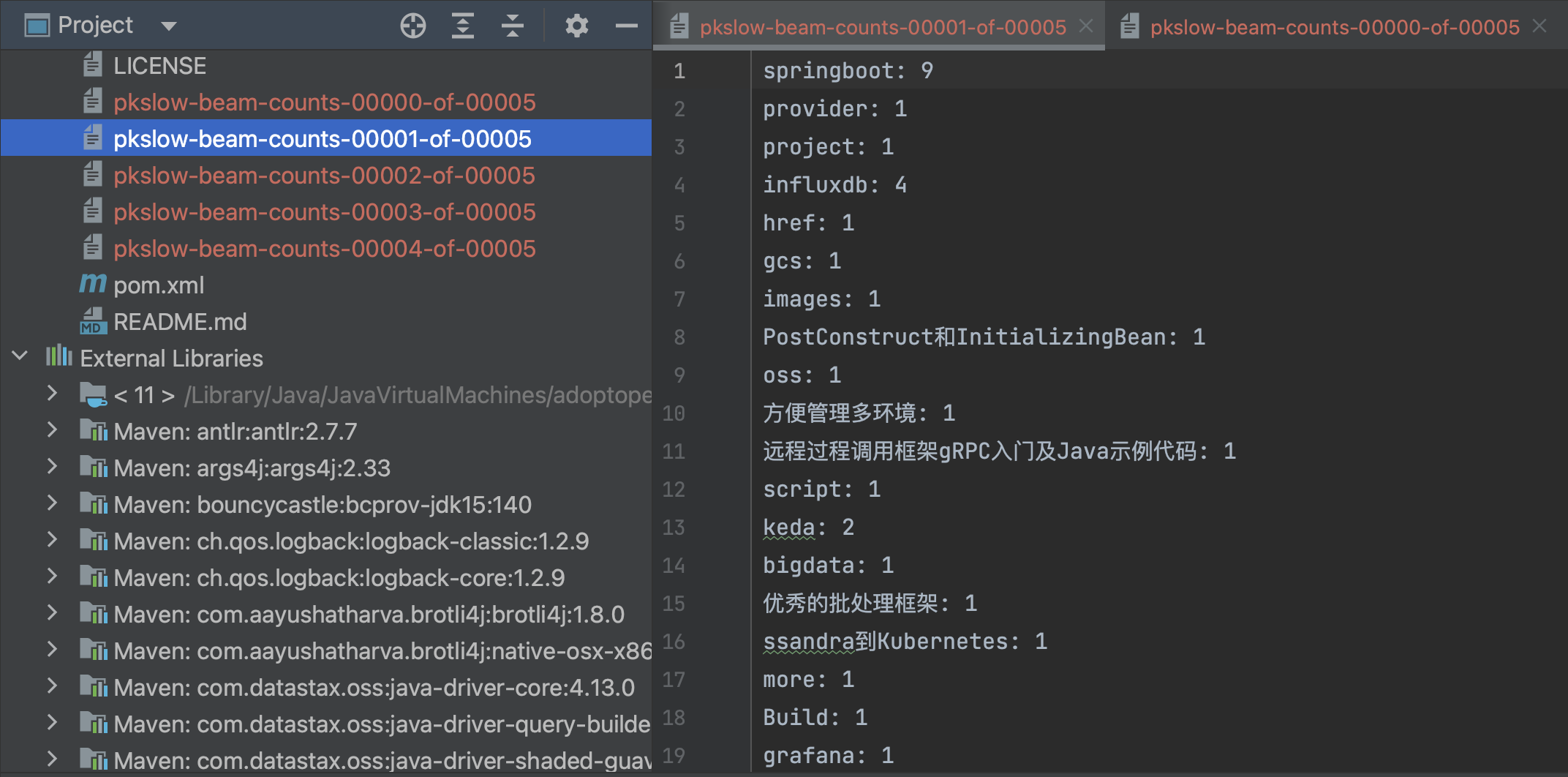
或者通过命令行来运行也可以:
mvn compile exec:java \
-Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--output=pkslow-beam-counts --inputFile=/Users/larry/IdeaProjects/pkslow-samples/README.md"
在GCP Cloud Dataflow上运行
准备环境
要有对应的Service Account和key,当然还要有权限;
要打开对应的Service;
创建好对应的Bucket,上传要处理的文件。
运行
然后在本地执行命令如下:
$ mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--runner=DataflowRunner --gcpTempLocation=gs://pkslow-dataflow/temp \
--project=pkslow --region=us-east1 \
--inputFile=gs://pkslow-dataflow/input/README.md --output=gs://pkslow-dataflow//pkslow-counts" \
-Pdataflow-runner
日志比较长,它大概做的事情就是把相关Jar包上传到temp目录下,因为执行的时候要引用。如:
Nov 03, 2022 8:41:48 PM org.apache.beam.runners.dataflow.util.PackageUtil tryStagePackage
INFO: Uploading /Users/larry/.m2/repository/org/apache/commons/commons-compress/1.8.1/commons-compress-1.8.1.jar to gs://pkslow-dataflow/temp/staging/commons-compress-1.8.1-X8oTZQP4bsxsth-9F7E31Z5WtFx6VJTmuP08q9Rpf70.jar
Nov 03, 2022 8:41:48 PM org.apache.beam.runners.dataflow.util.PackageUtil tryStagePackage
INFO: Uploading /Users/larry/.m2/repository/org/codehaus/jackson/jackson-mapper-asl/1.9.13/jackson-mapper-asl-1.9.13.jar to gs://pkslow-dataflow/temp/staging/jackson-mapper-asl-1.9.13-dOegenby7breKTEqWi68z6AZEovAIezjhW12GX6b4MI.jar
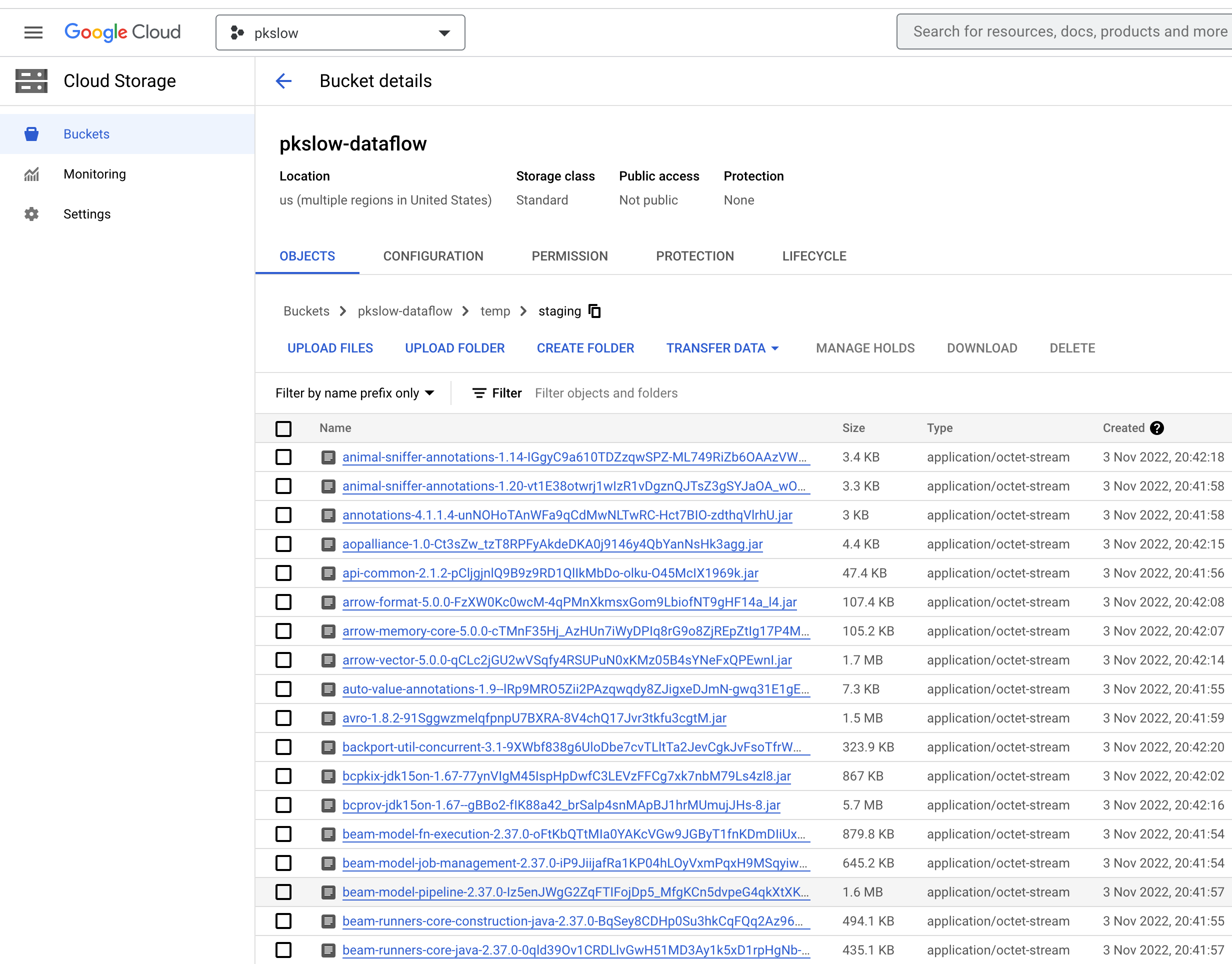
查看Bucket,确实有一堆jar包:
接着会创建dataflow jobs开始工作了。可以查看界面的Jobs如下:
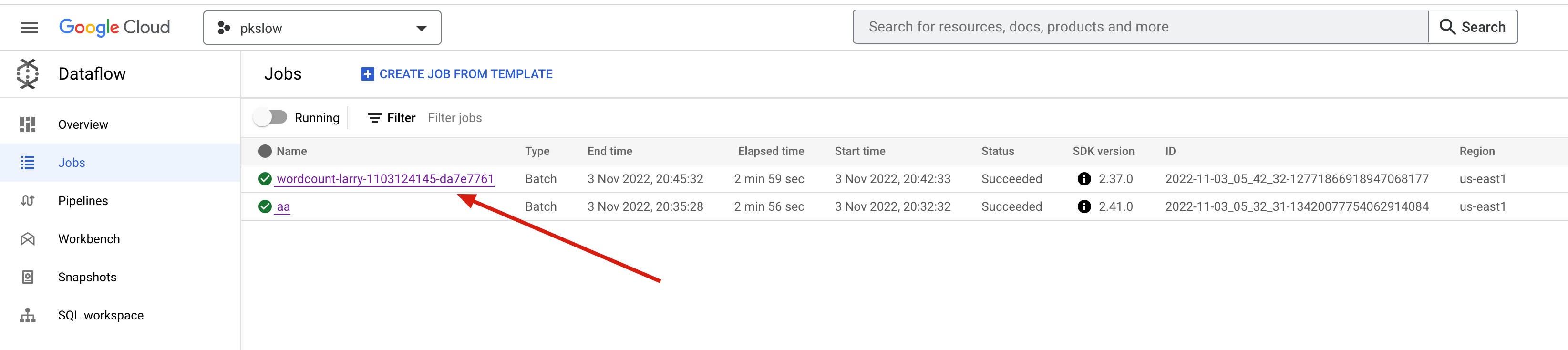
点进去可以看到流程和更多细节:

最后到Bucket查看结果也出来了:

代码
代码请看GitHub: https://github.com/LarryDpk/pkslow-samples
让Apache Beam在GCP Cloud Dataflow上跑起来的更多相关文章
- 初探Apache Beam
文章作者:luxianghao 文章来源:http://www.cnblogs.com/luxianghao/p/9010748.html 转载请注明,谢谢合作. 免责声明:文章内容仅代表个人观点, ...
- Apache Beam WordCount编程实战及源码解读
概述:Apache Beam WordCount编程实战及源码解读,并通过intellij IDEA和terminal两种方式调试运行WordCount程序,Apache Beam对大数据的批处理和流 ...
- Apache Beam实战指南 | 手把手教你玩转KafkaIO与Flink
https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247492538&idx=2&sn=9a2bd9fe2d7fd6 ...
- Apache beam中的便携式有状态大数据处理
Apache beam中的便携式有状态大数据处理 目标: 什么是 apache beam? 状态 计时器 例子&小demo 一.什么是 apache beam? 上面两个图片一个是正面切图,一 ...
- Apache Beam是什么?
Apache Beam 的前世今生 1月10日,Apache软件基金会宣布,Apache Beam成功孵化,成为该基金会的一个新的顶级项目,基于Apache V2许可证开源. 2003年,谷歌发布了著 ...
- Apache Beam: 下一代的大数据处理标准
Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后 ...
- Apache Beam的目标
不多说,直接上干货! Apache Beam的目标 统一(UNIFIED) 基于单一的编程模型,能够实现批处理(Batch processing).流处理(Streaming Processing), ...
- Apache Beam WordCount编程实战及源代码解读
概述:Apache Beam WordCount编程实战及源代码解读,并通过intellij IDEA和terminal两种方式调试执行WordCount程序,Apache Beam对大数据的批处理和 ...
- Apache Beam 传 大数据杂谈
1月10日,Apache软件基金会宣布,Apache Beam成功孵化,成为该基金会的一个新的顶级项目,基于Apache V2许可证开源. 2003年,谷歌发布了著名的大数据三篇论文,史称三驾马车:G ...
- Apache Beam 剖析
1.概述 在大数据的浪潮之下,技术的更新迭代十分频繁.受技术开源的影响,大数据开发者提供了十分丰富的工具.但也因为如此,增加了开发者选择合适工具的难度.在大数据处理一些问题的时候,往往使用的技术是多样 ...
随机推荐
- EasyPoi大数据导入导出百万级实例
EasyPoi介绍: 利用注解的方式简化了Excel.Word.PDF等格式的导入导出,而且是百万级数据的导入导出.EasyPoi官方网址:EasyPoi教程_V1.0 (mydoc.io).下面我写 ...
- 【深入浅出 Yarn 架构与实现】3-3 Yarn Application Master 编写
本篇文章继续介绍 Yarn Application 中 ApplicationMaster 部分的编写方法. 一.Application Master 编写方法 上一节讲了 Client 提交任务给 ...
- day22-web开发会话技术04
WEB开发会话技术04 14.Session生命周期 14.1生命周期说明 public void setMaxInactiveInterval(int interval):设置session的超时时 ...
- Git同步操作
同步github数据 先要进入仓库文件夹 新建仓库文件夹要初始化或将远程仓库clone下来 git init或git clone https://github.com/用户名称/仓库名称.git 新建 ...
- SQL注入绕waf思路总结
1.关键字大小写混合绕过 关键字大小写混合只针对于小写或大写的关键字匹配技术-正则表达式,如果在匹配时大小写不敏感的话,就无法绕过.这是最简单的一个绕过技术. 例如:将union select混写成U ...
- 提高python异步效率
uvloop #Python标准库中提供了asyncio模块,用于支持基于协程的异步编程. #uvloop是 asyncio 中的事件循环的替代方案,替换后可以使得asyncio性能提高.事实上,uv ...
- Java 中的接口还可以这样用,你知道吗?
Java 程序员都知道要面向接口编程,那 Java 中的接口除了定义接口方法之外还能怎么用你知道吗?今天阿粉就来带大家看一下 Java 中的接口还可以有哪些用法. 基本特性 我们先看一下接口的基本特性 ...
- mysql下载及环境配置
目录 mysql简介 mysql下载 启动mysql 系统mysql服务的启动 mysql虚拟环境配置 (可以直接看这个) 卸载说明 mysql简介 为什么是mysql? 虽然数据库软件有很多 但是操 ...
- 用 Java?试试国产框架 Solon v1.11.5(带视频)
一个更现代感的 Java 应用开发框架:更快.更小.更自由.没有 Spring,没有 Servlet,没有 JavaEE:独立的轻量生态.主框架仅 0.1 MB. @Controller public ...
- Jmeter 之提取多个值并引用
一.数值的提取 1.使用Json提取器随机提取返回结果中某几个值 2.使用Json提取器指定提取返回结果中的某几个值,如下,指定提取records中第一条数据中的flowType.id值 3.使用正则 ...