集合篇-ConcurrentHashMap
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人。
文章不定期同步公众号,还有各种一线大厂面试原题、我的学习系列笔记。
jdk1.7和jdk1.8中ConcurrentHashMap的区别?
底层数据结构的区别
- jdk1.7中的ConcurrenHashMap的底层结构=Segment数组+HashEntry数组来实现,put过程使用了Synchronized,结构如下:
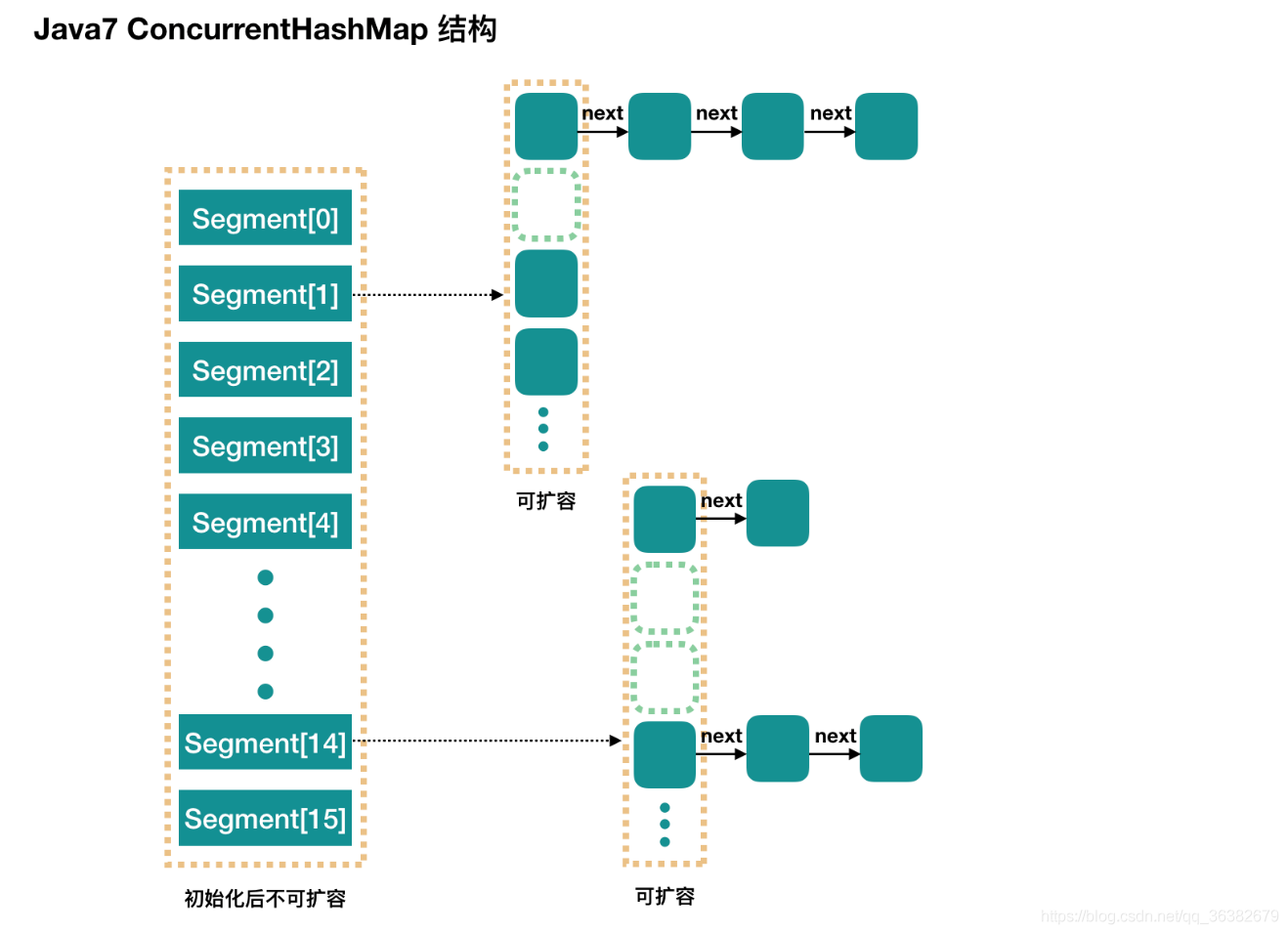
由上,jdk1.7中ConcurretHashMap=Segment类数组,每个Segment元素=HashEntry类数组=类似一个hashMap结构,每个HashEntry元素=链表;当多线程并发时,锁住的是单个Segment元素(Segment继承ReentrantLock,此处jdk1.7使用的是ReentrantLock的非公平锁),但即使是单个Segment元素,里面也含有一整个HashEntry数组(类似一个HashMap),所以锁住的是一整个HashEntry数组,故并发度也没有那么高 - jdk1.8中的ConcurrenHashMap的底层结构=Node数组+链表+红黑树,put过程使用了Synchronized+CAS(调用Unsafe类的cas方法),结构如下:
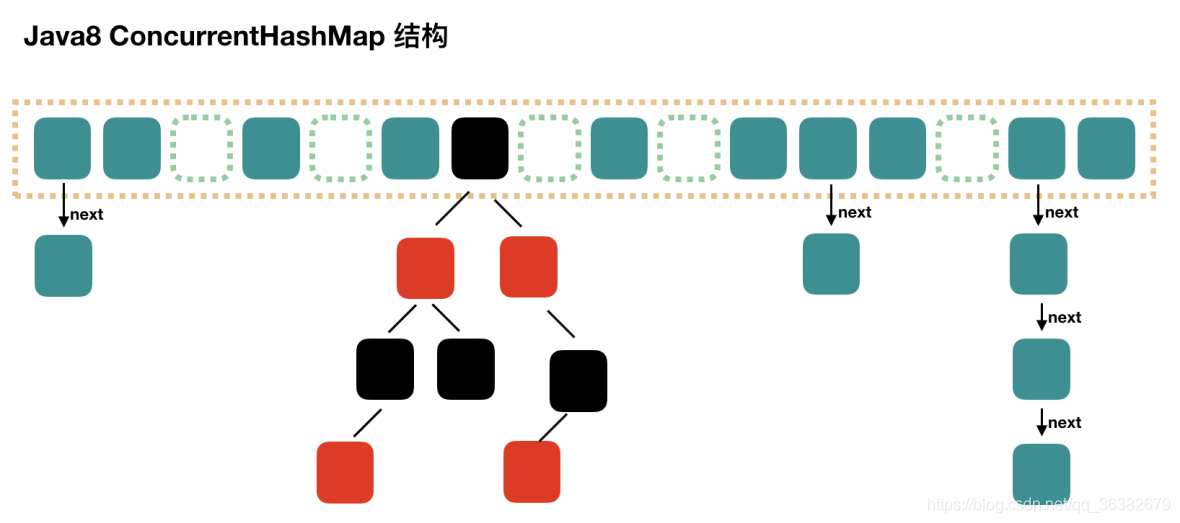
由上,jdk1.8中ConcurretHashMap类似于HashMap,它们都是数组+链表+红黑树,所有的操作都一样,唯一区别是ConcurretHashMap在具体某个桶的位置插入元素时,该位置的链表或红黑树会被同步访问【Synchronized(某桶的头节点)】,这样粒度比jdk1.7的更小了,锁住的是某个链表(或红黑树)
put方法的区别
jdk1.7中的put需定位两次:先定位要插入的元素在segment数组的下标,然后加锁去根据这个下标定位HashEntry数组的下标【key的hash值&HashEntry数组长度】,没有获得锁的线程做一些准备工作:
(1)提前找好HashEntry中桶的位置;
(2)遍历该桶有没有相同的key
进行(1)、(2)的同时不断自旋获取锁,超过64次还没获取到锁就挂起该线程jdk1.8中的put只需定位一次:
-->假如Node型table数组为空则初始化initTable()
-->table初始化完成,定位要插入元素所在的table[i]的位置,进一步判断table[i]为空则执行cas插入;
-->table[i]不为空且table[i].hash=-1,代表ConcurrentHashMap正在扩容,则加入扩容;
-->table[i].hash不为-1则直接插入,若是链表则插入到链表尾,若是红黑树则插入到红黑树
短时间内如何将大量数据高效地插入到ConcucurentHashMap?
以jdk1.8为例,影响concurrentHashMap插入元素的效率主要有两点:插入时频繁地扩容+插入时并发地访问:
(1)解决‘插入时频繁地扩容’:需选择合适的初始化容量和扩容因子
(2)解决‘插入时并发地访问’:插入节点时会对Node链表头节点加锁,然而锁也有'偏向锁...重量级锁',只要控制锁不发生升级,尽量保持在偏向锁状态,这样每个桶就只有一个线程访问,不会发生高并发从而提高插入效率。如何保持每个头结点加锁之后都是'偏向锁'状态呢?利用concurrentHashMap的spread()方法求key的hash值(预处理数据),将存在哈希冲突的key都集中地插入某个桶(可能会有多个桶-多个哈希冲突),因为每个桶都用单线程去put,从而没有其他线程去竞争同一个桶的锁,锁就一直为‘偏向锁’。
jdk1.8的put源码
final V putVal(K key, V value, boolean onlyIfAbsent) { //onlyIfAbsent默认传入false
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode()); //求key的hash值=预处理hashcode:便于将存在哈希冲突的key集中地插入某个桶
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0) //如果table为空则初始化数组
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //如果table非空则检查插入位置table[i]处的位置是否为空,若是则用cas插入Node节点
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED) //如果插入位置table[i]的头结点f的【hash值=fh】为-1则代表concurrentHashMap正在扩容,则加入扩容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) { //以上情况都不是,则插入到链表或红黑树,该步直接把头结点synchronized加锁,这样锁住的就是单个链表或单个红黑树
if (tabAt(tab, i) == f) {
if (fh >= 0) {//判断该桶位置处是链表还是红黑树:头结点的hash值>=,代表该处是链表
binCount = 1;
for (Node<K,V> e = f;; ++binCount) { //binCount用于计算该链表的结点树,后面会用到判断binCount>8则转为红黑树
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {//key相同
oldVal = e.val;
if (!onlyIfAbsent) //onlyIfAbsent默认为false
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) { //插入到链表尾
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD) //TREEIFY_THRESHOLD默认8,判断链表结点数>=8则转为红黑树
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
//Node型数组table为空时,初始化
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
//sizeCtl默认为0,可有三种取值:-1代表table正被其他线程初始化;0代表table等待初始化;大于0代表table初始化完成
if ((sc = sizeCtl) < 0)
Thread.yield(); // -1代表table正被其他线程初始化,本线程让出时间片进入就绪状态
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { //SIZECTL默认为0:【this在SIZECTL偏移量处的值=默认0】与sc相比,若相等则将this在SIZECTL偏移量处的值置为-1,代表table正在被初始化【疑问:sizeCtl是不同于SIZECTL的,SIZECTL=-1但sizeCtl没有置-1,所以上面Thread.yield()应该永远执行不到?】
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;//sc默认为0,DEFAULT_CAPACITY=默认16
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2); //n=16,n >>> 2即n/4,所以sc=n-(n/4)=3n/4=0.75n=12
}
} finally {
sizeCtl = sc; //把sizeCtl置为12>0,代表table初始化完成
}
break;
}
}
return tab;
}
OK,如果文章哪里有错误或不足,欢迎各位留言。
创作不易,各位的「三连」是二少创作的最大动力!我们下期见!
集合篇-ConcurrentHashMap的更多相关文章
- JUC源码分析-集合篇(一)ConcurrentHashMap
JUC源码分析-集合篇(一)ConcurrentHashMap 1. 概述 <HashMap 源码详细分析(JDK1.8)>:https://segmentfault.com/a/1190 ...
- JUC源码分析-集合篇:并发类容器介绍
JUC源码分析-集合篇:并发类容器介绍 同步类容器是 线程安全 的,如 Vector.HashTable 等容器的同步功能都是由 Collections.synchronizedMap 等工厂方法去创 ...
- JUC源码分析-集合篇(四)CopyOnWriteArrayList
JUC源码分析-集合篇(四)CopyOnWriteArrayList Copy-On-Write 简称 COW,是一种用于程序设计中的优化策略.其基本思路是,从一开始大家都在共享同一个内容,当某个人想 ...
- 死磕 java集合之ConcurrentHashMap源码分析(三)
本章接着上两章,链接直达: 死磕 java集合之ConcurrentHashMap源码分析(一) 死磕 java集合之ConcurrentHashMap源码分析(二) 删除元素 删除元素跟添加元素一样 ...
- 【JAVA秒会技术之秒杀面试官】秒杀Java面试官——集合篇(一)
[JAVA秒会技术之秒杀面试官]秒杀Java面试官——集合篇(一) [JAVA秒会技术之秒杀面试官]JavaEE常见面试题(三) http://blog.csdn.net/qq296398300/ar ...
- JUC源码分析-集合篇(十)LinkedTransferQueue
JUC源码分析-集合篇(十)LinkedTransferQueue LinkedTransferQueue(LTQ) 相比 BlockingQueue 更进一步,生产者会一直阻塞直到所添加到队列的元素 ...
- JUC源码分析-集合篇(九)SynchronousQueue
JUC源码分析-集合篇(九)SynchronousQueue SynchronousQueue 是一个同步阻塞队列,它的每个插入操作都要等待其他线程相应的移除操作,反之亦然.SynchronousQu ...
- JUC源码分析-集合篇(八)DelayQueue
JUC源码分析-集合篇(八)DelayQueue DelayQueue 是一个支持延时获取元素的无界阻塞队列.队列使用 PriorityQueue 来实现. 队列中的元素必须实现 Delayed 接口 ...
- JUC源码分析-集合篇(七)PriorityBlockingQueue
JUC源码分析-集合篇(七)PriorityBlockingQueue PriorityBlockingQueue 是带优先级的无界阻塞队列,每次出队都返回优先级最高的元素,是二叉树最小堆的实现. P ...
随机推荐
- cookies、sessionStorage和localStorage的区别
cookies.sessionStorage和localStorage的区别 对比 特性 Cookie LocalStorage SessionStorage 数据的生命周期 ...
- Python中将字典转为成员变量
技术背景 当我们在Python中写一个class时,如果有一部分的成员变量需要用一个字典来命名和赋值,此时应该如何操作呢?这个场景最常见于从一个文件(比如json.npz之类的文件)中读取字典变量到内 ...
- java中遗留的小问题
一.类型转换 short s = 1; s = s + 1; //false,因为1是int类型,会损失精度 short s = 1; s += 1; //true,因为+=有自带强转 二.逻辑运算符 ...
- Kafka消息是采用Pull模式,还是Push模式?
Kafka最初考虑的问题是,customer应该从brokes拉取消息还是brokers将消息推送到consumer,也就是pull还push.在这方面,Kafka遵循了一种大部分消息系统共同的传统的 ...
- CSS 网站布局
Flex:https://www.html.cn/archives/8629 Grid:https://www.html.cn/archives/8510/ http://www.ruanyif ...
- jQuery--文档处理案例
需求 如上图,实现左右两边的选择菜单可以左右移动,'>'按钮一次只能移动被选中的一个菜单,'>>'按钮一次移动所有被选择的菜单,'>>>'按钮 将所有菜单进行移动, ...
- 5. Git初始化及仓库创建和操作
4. Git初始化及仓库创建和操作 基本信息设置 1. 设置用户名 git config --global user.name 'itcastphpgit1' 2. 设置用户名邮箱 git confi ...
- 51单片机头文件reg51.h详解
转自:http://www.51hei.com/mcu/2670.html 我们在用c语言编程时往往第一行就是头文件,51单片机为reg51.h或reg52.h,51单片机相对来说比较简单,头文件里面 ...
- led指示灯电路图大全(八款led指示灯电路设计原理图详解)
led指示灯电路图大全(八款led指示灯电路设计原理图详解) led指示灯电路图(一) 图1所示电路中只有两个元件,R选用1/6--1/8W碳膜电阻或金属膜电阻,阻值在1--300K之间. Ne为氖泡 ...
- 二、cadence焊盘与封装制作操作步骤详细说明
一.焊盘制作 1.打开Pad Designer软件,新建文件--设置保存路径和焊盘名称(规范命名) 2.Parameters--设置单位--过孔类型--是否镀金 3.Layers--single la ...