「学习笔记」字符串基础:Hash,KMP与Trie
「学习笔记」字符串基础:Hash,KMP与Trie
Hash
算法
为了方便处理字符串,我们可以把一个字符串转化成如下形式(\(s\) 为原字符串,\(l\) 为字符串长度,\(b\) 为进制,\(P\) 为防止溢出的大质数):
\]
其中,\(b\) 一般选取一个三位质数即可(建议用 \(233\)),而 \(P\) 一般要选一个大质数。
我们可以直接通过比较两个字符串的哈希值是否相等来比较它们是否一样,但是显然两个不一样字符串的哈希值也是有很小的概率相等的,这种 \(\operatorname{Hash}\) 函数值一样时原字符串却不一样的现象我们称为哈希碰撞。
我们可以通过双模数来降低哈希碰撞的概率,但是要注意尽量不要选取常用的质数(如 \(10^9+7,10^9+9,998244353\)),否则出题人会故意卡你。
我的建议是背几个不常用的质数(如 \(315716251,475262633\)),或者考场上现造质数。
咋现造啊
Linux终端有个指令叫factor,分解质因数用的。乱写一堆数然后分解一下选几个比较大的不越界的质数(一般用九位数就行,如果是哈希表这样用来开数组的选个八位数)即可。
嗯上边那俩质数就是这样干出来的。
处理一整个字符串的前缀的时间复杂度是 \(\Theta(\left|S\right|)\),直接用 \(\left(\operatorname{Hash}(i-1)+s_i*b^{i-1}\right)\) 得到 \(\operatorname{Hash}(i)\)即可。
如何快速求 \(S_l\sim S_r\) 的哈希值?直接用 \(\left(\operatorname{Hash}(r)-\operatorname{Hash}(l-1)\times b^{r-l+1}\right)\) 就可以算出,时间复杂度是 \(\Theta(1)\)。
代码
点击查看代码
class Hash{
public:
const ll P1=315716251,P2=475262633;
ll h1[N],h2[N],z1[N],z2[N];
inline void Init(char *s,ll k){
ll len=strlen(s+1);
ll b=233;
z1[0]=z2[0]=1;
_for(i,1,len){
z1[i]=z1[i-1]*b%P1;
z2[i]=z2[i-1]*b%P2;
h1[i]=(h1[i-1]*b+(s[i]-'A'+1)%P1)%P1;
h2[i]=(h2[i-1]*b+(s[i]-'A'+1)%P2)%P2;
}
return;
}
inline ll GetHash1(ll l,ll r){return (h1[r]-h1[l-1]*z1[r-l+1]%P1+P1)%P1;}
inline ll GetHash2(ll l,ll r){return (h2[r]-h2[l-1]*z2[r-l+1]%P2+P2)%P2;}
}a,b;
KMP
算法
(这里的代码都是直接从模板题粘过来的)
前置知识:\(\text{Border}\)
思路
先来几个定义:
\(Pre_i\) 一个字符串长为 \(i\) 的前缀。
一个字符串 \(s\) 的 \(\text{Border}\) 为一个同时是 \(s\) 前后缀的真子串。
例如abab和ab就是ababab的 \(\text{Border}\),而aba和a则不是 。\(nxt_i\) 表示当前字符串长为 \(i\) 的前缀最长的 \(\text{Border}\) 的长度。
\(nxt_i\) 数组的应用十分广泛,\(\text{KMP}\) 只是其中的应用之一。
这个数组可以 \(\Theta(n^2)\) 求,但效率太低了,那么如何 \(\Theta(n)\) 求这个东西呢?
首先给出一个字符串 \(s\),我们假设之前的 \(nxt_{1}\sim nxt_{11}\) 都已经求完了,现在要求 \(nxt_{12}\)(最后的那个)。
abcabdabcabc
00012012345?
\(nxt_{11}=5\),可以看出这个 \(\text{Border}\) 是 abcab:
abcab d abcab | c
[---]
[---] |
我们尝试把它往后推一位,但是 \(s_6\neq s_{12}\),也就是说失配了!
这个时候我们看一眼 \(nxt_{nxt_{11}}\),即 \(nxt_5=2\),\(\text{Border}\) 是 ab:
abcab | dabcabc
[] |
[] |
由于 \(s_1\sim s_5=s_7\sim s_{11}\),我们可以把 \(s_1\sim s_5\) 的 \(\text{Border}\) 推广到 \(s_7\sim s_{11}\)上,即 \(s_7\sim s_8=s_{10}\sim s_{11}\):
abcabdabcabc
[]-[]
[]-[]
\(s_1\sim s_5=s_7\sim s_{11}\),所以 \(s_1\sim s_2=s_{7}\sim s_{8}\) 且 \(s_4\sim s_5=s_{10}\sim s_{11}\),即 \(s_1\sim s_2=s_{10}\sim s_{11}\):
abcabdabcabc
[]
[]
这个时候我们再继续往后推,可以发现 \(s_3\neq s_{12}\),能够匹配上了!
那么最后算出 \(nxt_{12}=3\)。
abcabdabcabc
[-]
[-]
最后总结一下求 \(nxt_{i}\) 的步骤:
令 \(j=nxt_{i-1}\)。
尝试匹配 \(s_{j+1}\) 和 \(s_i\) 如果失配则令 \(j=nxt_{j}\) 并不断循环此步,直到 \(j=0\) 或匹配成功。
令 \(nxt_i=j+[s_{j+1}=s_i]\)。
代码
inline void PreNxt(){
nxt[1]=0;ll k=0;
_for(i,2,m){
while(k&&t[i]!=t[k+1])k=nxt[k];
k+=(t[i]==t[k+1]),nxt[i]=k;
}
return;
}
\(\text{KMP}\) 匹配
$\text{Hot Knowlegde}$
该算法由 Knuth、Pratt 和 Morris 在 1977 年共同发布
[1]
。
思路
定义:
- 模式串是要查找的串。
- 文本串是被查找的串。
\(\text{KMP}\) 算法的思路其实和求 \(nxt\) 数组差不多,如果当前两个串失配了,那么我们在模式串中不断跳 \(nxt_{nxt_{nxt_{\cdots}}}\),直到匹配成功再继续往下。
(个人认为 \(nxt\) 数组更像一个指针,它指向位置的是失配后重新匹配的最优位置)
代码
下面这份代码中,文本串是 \(s\),模式串是 \(t\),在运行前需要已经求出 \(nxt\) 数组,输出的是模式串在文本串中每次出现的起始位置。
inline void Matching(){
ll k=0;
_for(i,1,n){
while(k&&s[i]!=t[k+1])k=nxt[k];
k+=(s[i]==t[k+1]);
if(k==m){
printf("%lld\n",i-m+1);
k=nxt[k];
}
}
}
Trie
TRIE=sTRIng+TReE
数据结构
Trie 就是把一堆字符串放到树上方便查找。
例如我们插入以下几个单词
apple
cat
copy
coffee
就会长出这样一棵 Trie:
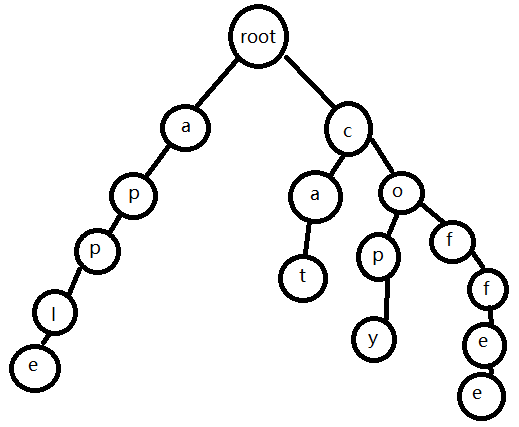
好像有点丑 确实有点丑。
01-Trie
指字符集为 \(\{0,1\}\) 的 Trie。
把数字换成二进制后塞到 Trie 里就得到了 01-Trie。
01-Trie 有很多应用,例如维护异或极值。
代码
class Trie{
private:
ll tot=1;
class{public:ll nx[26];bool end;}tr[N];
public:
inline void Add(char *s){
ll len=strlen(s+1),p=1;
_for(i,1,len){
if(!tr[p].nx[s[i]-'a'])tr[p].nx[s[i]-'a']=++tot;
p=tr[p].nx[s[i]-'a'];
}
tr[p].end=1;
return;
}
inline bool Find(char *s){
ll len=strlen(s+1),p=1;
_for(i,1,len){
if(!tr[p].nx[s[i]-'a'])return 0;
p=tr[p].nx[s[i]-'a'];
}
return tr[p].end;
}
}tr;
练习题
Hash
Bovine Genomics
思路
可以枚举左右端点暴力比较,确定好左右端点和要比较的两个字符串之后可以 \(\Theta(1)\) 哈希比较,但显然总复杂度 \(\Theta(n^4)\) 跑不动,考虑如何优化。
这道题让我们求最短区间长度,那么我们考虑二分答案这个长度。
但这样复杂度是 \(\Theta(n^3\log_2n)\) 的,依旧跑不动。
可以发现我没有必要将所有字符串都匹配一遍,只需要判断当前这个区间有没有重复出现,那么我们直接把哈希值丢进一个 map 里面维护即可,复杂度 \(\Theta(n^2\log_2^2n)\)。
但是不能直接把字符串丢进 map 里,因为这种情况 map 不是现哈希就是用 Trie,单次更改/查询复杂度都是 \(\Theta(n)\)。
代码
点击查看代码
const ll N=510,inf=1ll<<40;
ll n,m,ans,le,ri;
char s[N][N],t[N][N];
map<ll,bool>mp1,mp2;
class Hash{
public:
const ll P1=315716251,P2=475262633;
ll h1[N],h2[N],z1[N],z2[N];
inline void Init(char *s){
ll len=strlen(s+1);
z1[0]=z2[0]=1;
_for(i,1,m){
z1[i]=z1[i-1]*233%P1;
z2[i]=z2[i-1]*233%P2;
h1[i]=(h1[i-1]*233+(s[i]-'A'+1)%P1)%P1;
h2[i]=(h2[i-1]*233+(s[i]-'A'+1)%P2)%P2;
}
return;
}
inline ll GetHash1(ll l,ll r){return (h1[r]-h1[l-1]*z1[r-l+1]%P1+P1)%P1;}
inline ll GetHash2(ll l,ll r){return (h2[r]-h2[l-1]*z2[r-l+1]%P2+P2)%P2;}
}a[N],b[N];
namespace SOLVE{
inline ll rnt(){
ll x=0,w=1;char c=getchar();
while(!isdigit(c)){if(c=='-')w=-1;c=getchar();}
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=getchar();
return x*w;
}
inline bool Check(ll len){
_for(i,len,m){
bool bl=1;
mp1.clear(),mp2.clear();
_for(j,1,n){
mp1[a[j].GetHash1(i-len+1,i)]=1;
mp2[a[j].GetHash2(i-len+1,i)]=1;
}
_for(j,1,n){
if(mp1[b[j].GetHash1(i-len+1,i)])bl=0;
if(mp2[b[j].GetHash2(i-len+1,i)])bl=0;
}
if(bl)return 1;
}
return 0;
}
inline void In(){
n=rnt(),m=rnt();
_for(i,1,n)scanf("%s",s[i]+1),a[i].Init(s[i]);
_for(i,1,n)scanf("%s",t[i]+1),b[i].Init(t[i]);
ll l=1,r=m;
while(l<r){
bdmd;
if(Check(mid))r=mid;
else l=mid+1;
}
printf("%lld\n",l);
return;
}
}
[TJOI2018]碱基序列
思路
设 \(t_{i,j}\) 是 \(i\) 个氨基酸的第 \(j\) 种,\(f_{i,j}\) 表示第 \(i\) 个氨基酸的结尾放在 \(j\) 的方案数,则转移方程为:
\]
数组可以滚一下,但感觉没什么必要。
比较直接哈希,时间复杂度 \(\Theta(ka_i\left|S\right|)\)。
代码
点击查看代码
const ll N=1e4+10,P=1e9+7,inf=1ll<<40;
ll n,a[N],l,f[110][N],ans;
char s[N],t[N];
vector<ll>pp;
class Hash{
public:
const ll P1=315716521,P2=475262633;
ll h1[N],h2[N],z1[N],z2[N];
inline void Init(char *s){
z1[0]=z2[0]=1;
ll length=strlen(s+1);
_for(i,1,length){
z1[i]=z1[i-1]*233%P1;
z2[i]=z2[i-1]*233%P2;
h1[i]=(h1[i-1]*233+(s[i]-'A'+1)%P1)%P1;
h2[i]=(h2[i-1]*233+(s[i]-'A'+1)%P2)%P2;
}
return;
}
inline ll GetHash1(ll l,ll r){return (h1[r]-h1[l-1]*z1[r-l+1]%P1+P1)%P1;}
inline ll GetHash2(ll l,ll r){return (h2[r]-h2[l-1]*z2[r-l+1]%P2+P2)%P2;}
}d;
namespace SOLVE{
inline ll rnt(){
ll x=0,w=1;char c=getchar();
while(!isdigit(c)){if(c=='-')w=-1;c=getchar();}
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=getchar();
return x*w;
}
inline ll GetS1(char *s){
ll s1=0;
_for(i,1,strlen(s+1))s1=(s1*233+s[i]-'A'+1)%d.P1;
return s1;
}
inline ll GetS2(char *s){
ll s2=0;
_for(i,1,strlen(s+1))s2=(s2*233+s[i]-'A'+1)%d.P2;
return s2;
}
inline void In(){
n=rnt();
scanf("%s",s+1);
l=strlen(s+1);d.Init(s);
_for(i,1,n){
ll a=rnt();
_for(j,1,a){
scanf("%s",t+1);
ll len=strlen(t+1);
ll s1=GetS1(t),s2=GetS2(t);
_for(k,len,l){
if(d.GetHash1(k-len+1,k)!=s1)continue;
if(d.GetHash2(k-len+1,k)!=s2)continue;
f[i][k]=(f[i][k]+f[i-1][k-len])%P;
if(i==1&&!f[i-1][k-len])++f[i][k];
}
}
}
_for(i,1,l)ans=(ans+f[n][i])%P;
printf("%lld\n",ans);
return;
}
}
[CQOI2014]通配符匹配
[NOI2017] 蚯蚓排队
思路
观察数据范围可以发现 \(k\le50\)。
那么就可以暴力去跑了,简单来说:
对于操作一:把在拼接处新拼接出的所有向后 \(k\) 字符串(\(1\le k\le50\))记录。
对于操作二:把在断开处层拼接出的所有向后 \(k\) 字符串(\(1\le k\le50\))去除。
对于操作三:暴力枚举 \(S\) 的每个长度为 \(k\) 的子串,累计出现次数。
那么如何记录呢?再看题面还可以发现我们不用去逐位比较,只要记录每个串出现次数即可。
我刚开始用的是 map,但自带一个 \(\log\) 会超时。
那么我们引入一个东西叫 哈希表,简单来说就是先对原串哈希值取个模得到 \(x\),然后开个链表存取模后得到 \(x\) 的所有哈希值。查找时直接把存取模后得到 \(x\) 的所有哈希值的链表全部遍历一遍来查找。因为哈希冲突概率本来就很小,所以用不了查找多久。
时间复杂度 \(\Theta(km+\sum\left|S\right|)\)。
代码
点击查看代码
const ll N=1e7+10,MOD=998244353,P=19491001,inf=1ll<<40;
ll n,m,ans,arry[110],ss[N];ull z[110],h[110];char t[N];
class lb{public:ll la,nx,va;}lb[N];
namespace Hash{
class HashTable{
public:
ll tot=0,hd[P]={0};
class Table{
public:
ull hv;ll cnt,nx;
inline void Add(ull a,ll b,ll c){hv=a,cnt=b,nx=c;}
}t[P*2];
inline void Add(ull val){
ll v=val%P;ll f=hd[v];
while(f&&t[f].hv!=val)f=t[f].nx;
if(!f)t[++tot].Add(val,1,hd[v]),hd[v]=tot;
else ++t[f].cnt;
return;
}
inline void Del(ull val){
ll v=val%P;ll f=hd[v];
while(f&&t[f].hv!=val)f=t[f].nx;
if(f)--t[f].cnt;
return;
}
inline ll Que(ull val){
ll v=val%P;ll f=hd[v];
while(f&&t[f].hv!=val)f=t[f].nx;
if(f)return t[f].cnt;
return 0;
}
}ha;
inline void Merge(ll a,ll b){
ll st=a,en=a,le=1,ri=0;
lb[a].nx=b,lb[b].la=a;
while(lb[st].la!=-1&&le<50)st=lb[st].la,++le;
_for(i,1,le)h[i]=h[i-1]*131+lb[st].va,st=lb[st].nx;
while(lb[en].nx!=-1&&ri<=50)en=lb[en].nx,++ri,h[le+ri]=h[le+ri-1]*131+lb[en].va;
_for(i,1,le)_for(j,le+1,min(ri+le,i+49))ha.Add(h[j]-h[i-1]*z[j-i+1]);
return;
}
inline void Divition(ll k){
ll st=k,en=k,le=1,ri=0;
while(lb[st].la!=-1&&le<50)st=lb[st].la,++le;
_for(i,1,le)h[i]=h[i-1]*131+lb[st].va,st=lb[st].nx;
while(lb[en].nx!=-1&&ri<=50)en=lb[en].nx,++ri,h[le+ri]=h[le+ri-1]*131+lb[en].va;
_for(i,1,le)_for(j,le+1,min(ri+le,i+49))ha.Del(h[j]-h[i-1]*z[j-i+1]);
lb[lb[k].nx].la=-1,lb[k].nx=-1;
return;
}
inline ll Query(ll k,ll len){
ll ans=1;ull val=0;
_for(i,1,len){
if(i>k)val-=z[k-1]*ss[i-k];
val=val*131+ss[i];
if(i>=k)ans=ans*ha.Que(val)%MOD;
}
return ans;
}
}
using namespace Hash;
namespace SOLVE{
char buf[1<<20],*p1,*p2;
#define gc()(p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<20,stdin),p1==p2)?EOF:*p1++)
inline ll rnt(){
ll x=0,w=1;char c=gc();
while(!isdigit(c)){if(c=='-')w=-1;c=gc();}
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=gc();
return x*w;
}
inline void In(){
n=rnt(),m=rnt(),z[0]=1;
_for(i,1,100)z[i]=z[i-1]*131;
_for(i,1,n){
lb[i].va=rnt()+'0';
lb[i].nx=lb[i].la=-1;
Hash::ha.Add(lb[i].va);
}
_for(i,1,m){
ll op=rnt();
if(op==1){
ll x=rnt(),y=rnt();
Merge(x,y);
}
else if(op==2){
ll x=rnt();
Divition(x);
}
else{
char c=gc();ll t=0;
while(!isdigit(c))c=gc();
while(isdigit(c))ss[++t]=c,c=gc();
ll k=rnt();
printf("%lld\n",Query(k,t));
}
}
return;
}
}
KMP
Seek the Name, Seek the Fame
思路
板子题,因为 \(\text{Border}\) 的 \(\text{Border}\) 还是 \(\text{Border}\),所以一路 \(nxt\) 下去就可以了。
代码
点击查看代码
inline void PreNxt(){
nxt[0]=0;ll j=0;
_for(i,2,n){
while(j&&s[i]!=s[j+1])j=nxt[j];
if(s[i]==s[j+1])++j;
nxt[i]=j;
}
return;
}
void Print(ll i){
if(i<1)return;
Print(nxt[i]-(bool)(nxt[i]==i));
printf("%lld ",i);
return;
}
inline void In(){
n=strlen(s+1);
PreNxt(),Print(n),puts("");
return;
}
[NOI2014] 动物园
思路
题目要求不重叠的 \(\text{Border}\) 数量,那么我们可以先求出一个 \(cnt\) 数组表示 可重叠的 \(\text{Border}\) 数量。
不难发现我们找到一个长度不超过 \(\tfrac{k}{2}\) 的最长的 \(\text{Border}\):\(Pre_k\),则 \(num_i=cnt_k\)。
而 \(cnt\) 的求法也很简单:\(cnt_i=cnt_{nxt_i}+1\),求 \(nxt\) 时顺便求一下就行了。
代码
代码里的 num 就是 cnt。
点击查看代码
inline void PreNxt(){
nxt[1]=0,num[1]=1;ll j=0;
_for(i,2,n){
while(j&&s[i]!=s[j+1])j=nxt[j];
if(s[i]==s[j+1])++j;
nxt[i]=j,num[i]=num[j]+1;
}
return;
}
inline void SolveNum(){
ans=1;ll k=0;
_for(i,2,n){
while(k&&s[i]!=s[k+1])k=nxt[k];
if(s[i]==s[k+1])++k;
while(k&&(k<<1)>i)k=nxt[k];
ans=ans*(num[k]+1)%P;
}
return;
}
inline void In(){
scanf("%s",s+1);
n=strlen(s+1);
PreNxt(),SolveNum();
printf("%lld\n",ans);
return;
}
[USACO15FEB] Censoring S
思路
本题的难点在于如何删除一个子串。
考虑用一个栈 st 维护当前剩下的串,每次匹配成功后把这个匹配成功的子串弹出去,再让下一个字符从栈顶继续匹配(即 j=nxt[st[top]])。因为之前已经将中间的匹配成功的串弹了出去,所以该算法正确。
代码
点击查看代码
const ll N=2e6+10,inf=1ll<<40;
ll n,m,nxt[N],f[N],st[N],top,ans;char s[N],t[N];
namespace SOLVE{
char buf[1<<20],*p1,*p2;
#define gc() (p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<20,stdin),p1==p2)?EOF:*p1++)
inline ll rnt(){
ll x=0,w=1;char c=gc();
while(!isdigit(c)){if(c=='-')w=-1;c=gc();}
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=gc();
return x*w;
}
inline void PreNxt(){
ll j=0;
_for(i,2,m){
while(j&&t[j+1]!=t[i])j=nxt[j];
if(t[j+1]==t[i])++j;
nxt[i]=j;
}
return;
}
inline void Machting(){
ll j=0;
_for(i,1,n){
st[++top]=i;
while(j&&t[j+1]!=s[i])j=nxt[j];
if(t[j+1]==s[i])++j;
f[i]=j;
if(j==m){
top-=m;
j=f[st[top]];
}
}
return;
}
inline void Print(){
_for(i,1,top)putchar(s[st[i]]);
return;
}
inline void In(){
scanf("%s%s",s+1,t+1);
n=strlen(s+1),m=strlen(t+1);
PreNxt(),Machting();
Print(),puts("");
return;
}
}
[POI2006] OKR-Periods of Words
思路
设一个字符串 \(s\) 长度为 \(L\),最长周期长度为 \(l\),可以发现 \(s_{l+1}\sim s_{L}\) 是第二遍循环的 \(Q\) 的前缀,也就是说 \(s_{l+1}\sim s_{L}\) 是 \(S\) 的一个 \(\text{Border}\)!
可以发现这个 \(\text{Border}\) 的长度越小 \(l\) 越大,那么我们就把问题转化成了 求一个字符串所有前缀的最小 \(\text{Border}\) 长度之和。
设 \(mn_i\) 表示 \(Pre_i\) 的最小 \(\text{Border}\) 长度,分情况讨论它的值:
- 如果 \(Pre_i\) 只有一个 \(\text{Border}\),那么 \(mn_i=nxt_i\)。
- 否则由于 \(\text{Border}\) 的 \(\text{Border}\) 是 \(\text{Border}\),直接令 \(mn_i=mn_{nxt_i}\)。
代码
注意:如果输入时要数字和字符串混输就不要用 fread,否则会把字符串读到缓冲区里,导致无法读入字符串。(也可以单独再写一个读入字符串的函数,但是太麻烦没必要)
点击查看代码
const ll N=1e6+10,inf=1ll<<40;
ll n,nxt[N],mn[N],ans;char s[N];
namespace SOLVE{
inline ll rnt(){
ll x=0,w=1;char c=getchar();
while(!isdigit(c)){if(c=='-')w=-1;c=getchar();}
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=getchar();
return x*w;
}
inline void PreNxt(){
ll j=0;
_for(i,2,n){
while(j&&s[i]!=s[j+1])j=nxt[j];
if(s[i]==s[j+1])++j;
nxt[i]=j;
if(j&&!nxt[j])mn[i]=j;
else mn[i]=mn[j];
if(mn[i])ans+=i-mn[i];
}
}
inline void In(){
n=rnt();
scanf("%s",s+1);
PreNxt();
printf("%lld\n",ans);
return;
}
}
字符串的匹配
思路
显然无法直接比较,因为需要求出在区间中的排名。
考虑用树状数组维护排名,但是直接维护任意区间的排名是很困难的。
再次像之前一样研究 \(\text{Border}\) 的性质。在求 \(nxt\) 数组时可以发现 每次失配时 \(\text{Border}\) 左端点都会减小,匹配成功后右端点加一,即这个区间是个整体不断右移的区间,且完全不会左移。
那么每次失配就可以把左边的数暴力去除贡献,总复杂度 \(\Theta(n)\)。
会算排名后就可以直接匹配了。
时间复杂度 \(\Theta(n\log_2n)\)。
代码
点击查看代码
const ll N=5e5+10,inf=1ll<<40;
ll n,m,s,rk1[N],rk2[N],nxt[N],a[N],b[N];vector<ll>ans;
class BIT{
public:
ll b[N]={0};
inline void Update(ll x,ll y){while(x>0&&x<=s)b[x]+=y,x+=(x&-x);return;}
inline ll Query(ll x){ll sum=0;while(x>0)sum+=b[x],x-=(x&-x);return sum;}
inline void Clear(){memset(b,0,sizeof(b));}
}r,bit;
namespace SOLVE{
char buf[1<<20],*p1,*p2;
#define gc() (p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<20,stdin),p1==p2)?EOF:*p1++)
inline ll rnt(){
ll x=0,w=1;char c=gc();
while(!isdigit(c)){if(c=='-')w=-1;c=gc();}
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=gc();
return x*w;
}
inline bool Check(ll a,ll b){
return bit.Query(a-1)==rk1[b]&&bit.Query(a)==rk2[b];
}
inline void PreRank(){
_for(i,1,m){
r.Update(b[i],1);
rk1[i]=r.Query(b[i]-1);
rk2[i]=r.Query(b[i]);
}
return;
}
inline void PreNxt(){
nxt[1]=0;
ll j=0;
_for(i,2,m){
bit.Update(b[i],1);
while(j&&!Check(b[i],j+1)){
_for(k,i-j,i-nxt[j]-1)bit.Update(b[k],-1);
j=nxt[j];
}
if(Check(b[i],j+1))++j;
nxt[i]=j;
}
return;
}
inline void Matching(){
bit.Clear();
ll j=0;
_for(i,1,n){
bit.Update(a[i],1);
while(j&&!Check(a[i],j+1)){
_for(k,i-j,i-nxt[j]-1)bit.Update(a[k],-1);
j=nxt[j];
}
if(Check(a[i],j+1))++j;
if(j==m){
ans.push_back(i-j+1);
_for(k,i-j+1,i-nxt[j])bit.Update(a[k],-1);
j=nxt[j];
}
}
return;
}
inline void In(){
n=rnt(),m=rnt(),s=rnt();
_for(i,1,n)a[i]=rnt();
_for(i,1,m)b[i]=rnt();
PreRank(),PreNxt(),Matching();
printf("%ld\n",ans.size());
far(i,ans)printf("%lld\n",i);
return;
}
}
[HNOI2008]GT考试
思路
设 \(f_{i,j}\) 表示准考证的后 \(i\) 位中的前 \(j\) 位匹配上了 \(A\) 的方案数。答案显然为:
\]
发现不好转移,那么我们再添加一个 \(g_{i,j}\) 表示匹配上前 \(i\) 位时通过加数字匹配上 \(j\) 位的方案数。
此时转移方程显然为:
\]
妈呀这不就是矩阵乘法吗?
妈呀这个 \(g\) 数组不是确定的吗?
妈呀这冲个矩阵快速幂不就行了吗?
所以现在我们只需要考虑如何求 \(g\) 数组即可。
其实这个也很简单,我们只需要枚举下一个数字,找到长度为 \(j\) 的前缀失配后跳到那个前缀上才能匹配成功即可。
时间复杂度 \(\Theta(m^3\log_2n)\)。
代码
点击查看代码
const ll N=30,inf=1ll<<40;
ll n,m,P,nxt[N],ans;char s[N];
class Matrix{
public:
ll a[N][N];
inline ll* operator[](ll x){return a[x];}
inline void Clear(){memset(a,0,sizeof(a));}
inline void One(){_for(i,1,m)a[i][i]=1;}
inline Matrix operator*(Matrix mat){
Matrix ans;ans.Clear();
_for(i,1,m)_for(j,1,m)_for(k,1,m)
ans[i][j]=(ans[i][j]+a[i][k]*mat[k][j]%P)%P;
return ans;
}
}f,g;
namespace SOLVE{
inline ll rnt(){
ll x=0,w=1;char c=getchar();
while(!isdigit(c)){if(c=='-')w=-1;c=getchar();}
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=getchar();
return x*w;
}
inline void GetNxt(){
ll j=0;
_for(i,2,m){
while(j&&s[j+1]!=s[i])j=nxt[j];
if(s[j+1]==s[i])++j;
nxt[i]=j;
}
return;
}
inline void Pre(){
_for(i,0,m-1){
_for(j,'0','9'){
ll k=i;
while(k&&s[k+1]!=j)k=nxt[k];
if(s[k+1]==j)++k;
++g[i+1][k+1],g[i+1][k+1]%=P;
}
}
return;
}
inline Matrix fpow(Matrix a,ll b){
Matrix ans;ans.Clear(),ans.One();
while(b){
if(b&1)ans=ans*a;
a=a*a,b>>=1;
}
return ans;
}
inline ll GetAnswer(){
f.Clear(),f[1][1]=1;
g=fpow(g,n),f=f*g;
_for(i,1,m)ans=(ans+f[1][i])%P;
return ans;
}
inline void In(){
n=rnt(),m=rnt(),P=rnt();
scanf("%s",s+1);
GetNxt(),Pre();
printf("%lld\n",GetAnswer());
return;
}
}
Trie
Phone List
思路
模板题。
代码
点击查看代码
const ll N=1e6+10,inf=1ll<<40;
ll T,n,ans;char s[N];
class Trie{
private:
ll tot=1;
class TRIE{public:ll nx[20];bool en=0;}tr[N];
public:
inline void Clear(){tot=1,memset(tr,0,sizeof(tr));return;}
inline bool Add(char *s){
ll len=strlen(s+1),q1=0,q2=0;
ll p=1;
_for(i,1,len){
ll c=s[i]-'0';
if(!tr[p].nx[c])q1=1,tr[p].nx[c]=++tot;
p=tr[p].nx[c],q2|=tr[p].en;
}
tr[p].en=1;
return (!q1)||(q2);
}
}tr;
namespace SOLVE{
inline ll rnt(){
ll x=0,w=1;char c=getchar();
while(!isdigit(c)){if(c=='-')w=-1;c=getchar();}
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=getchar();
return x*w;
}
inline void In(){
n=rnt(),ans=0;
_for(i,1,n){
scanf("%s",s+1);
ans|=tr.Add(s);
}
puts(ans?"NO":"YES");
tr.Clear();
return;
}
}
The XOR Largest Pair
思路
01-Trie 模板题。
首先我们把所有数化成二进制数,从高位到低位塞进 01-Trie 里。
然后计算答案,有如下两种方式:
法一(较为通用):
对于每个数,我们都在根据它的二进制数在 01-Trie 上尽量反着走,异或出的结果一定是包含它的所有数对中最大的,再取个 \(\max\) 就能得到答案了。
时间复杂度是稳的 \(\Theta(n\log_2n)\)。
法二(自创,不通用):递归实现。传入两个节点,然后分情况讨论:
- 两个节点都没有儿子了:直接退出并返回当前算出的答案。
- 两个节点都只有一个儿子且都指向 \(0\) 或都指向 \(1\):都往这个儿子处走,且这一二进制位答案为 \(0\)。
- 两个节点中有一个有儿子指向 \(1\),另一个节点有一个有儿子指向 \(0\):往这两个儿子处走,且这一二进制位答案为 \(1\)。
最后返回的答案就是了(见代码)。
可以发现最坏情况下要跑满整棵树,但很多情况下跑不满,而且树也填不到 \(\Theta(n\log_2n)\) 级别,所以时间复杂度严格小于 \(\Theta(n\log_2n)\),跑得飞快。
代码
点击查看代码
const ll N=5e6+10,inf=1ll<<40;
ll n,a[N];
class Trie{
public:
ll tot=1;
class TRIE{public:ll nx[2];}tr[N];
inline void Add(ll num){
stack<bool>st;
_for(i,1,31)st.push(num&1),num>>=1;
ll p=1;
while(!st.empty()){
if(!tr[p].nx[st.top()])tr[p].nx[st.top()]=++tot;
p=tr[p].nx[st.top()];
st.pop();
}
return;
}
inline ll Solve(ll lp,ll rp,ll num){
ll ans=0;
if(!tr[lp].nx[0]&&!tr[lp].nx[1]&&!tr[rp].nx[0]&&!tr[rp].nx[1])ans=num;
if(!tr[lp].nx[0]&&tr[lp].nx[1]&&!tr[rp].nx[0]&&tr[rp].nx[1])ans=Solve(tr[lp].nx[1],tr[rp].nx[1],num<<1);
if(tr[lp].nx[0]&&!tr[lp].nx[1]&&tr[rp].nx[0]&&!tr[rp].nx[1])ans=Solve(tr[lp].nx[0],tr[rp].nx[0],num<<1);
if(tr[lp].nx[0]&&tr[rp].nx[1])ans=max(ans,Solve(tr[lp].nx[0],tr[rp].nx[1],num<<1|1));
if(tr[lp].nx[1]&&tr[rp].nx[0])ans=max(ans,Solve(tr[lp].nx[1],tr[rp].nx[0],num<<1|1));
return ans;
}
}tr;
namespace SOLVE{
char buf[1<<20],*p1,*p2;
#define gc() (p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<20,stdin),p1==p2)?EOF:*p1++)
inline ll rnt(){
ll x=0,w=1;char c=gc();
while(!isdigit(c)){if(c=='-')w=-1;c=gc();}
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=gc();
return x*w;
}
inline void In(){
n=rnt();
_for(i,1,n)a[i]=rnt(),tr.Add(a[i]);
printf("%lld\n",tr.Solve(1,1,0));
return;
}
}
The XOR-longest Path
思路
异或和有一个重要性质:\(a\oplus b\oplus b=a\)。
那么两个节点 \(u\) 和 \(v\) 之间的路径异或和就相当于 \(u\) 到根的异或和异或上 \(v\) 到根的异或和(因为这两次中 \(u\) 和 \(v\) 的 \(\text{LCA}\) 到根的异或和会被异或没)。
于是问题就转化成了:找到两个节点 \(u\) 和 \(v\),使它们到根的异或和的异或和最大。
那么把每个点到根的异或和预处理出来,就变成上一道题了。
代码
点击查看代码
const ll N=1e6+10,inf=1ll<<40;
ll n,a[N],ans;vector<pair<ll,ll> >tu[N];
class Trie {
private:
ll tot=1;
class TRIE{public:ll nx[2];}tr[N];
public:
#define nx(p,i) tr[p].nx[i]
inline void Add(ll num){
ll p=1;stack<ll>st;
_for(i,1,31)st.push(num&1),num>>=1;
while(!st.empty()){
if(!nx(p,st.top()))nx(p,st.top())=++tot;
p=nx(p,st.top()),st.pop();
}
return;
}
ll Solve(ll lp,ll rp,ll num){
ll ans=0;
if(!nx(lp,0)&&!nx(lp,1)&&!nx(rp,0)&&!nx(rp,1))ans=num;
if(nx(lp,0)&&!nx(lp,1)&&nx(rp,0)&&!nx(rp,1))ans=Solve(nx(lp,0),nx(rp,0),num<<1);
if(!nx(lp,0)&&nx(lp,1)&&!nx(rp,0)&&nx(rp,1))ans=Solve(nx(lp,1),nx(rp,1),num<<1);
if(nx(lp,0)&&nx(rp,1))ans=max(ans,Solve(nx(lp,0),nx(rp,1),num<<1|1));
if(nx(lp,1)&&nx(rp,0))ans=max(ans,Solve(nx(lp,1),nx(rp,0),num<<1|1));
return ans;
}
#undef nx
}tr;
namespace SOLVE {
char buf[1<<20],*p1,*p2;
#define gc() (p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<20,stdin),p1==p2)?EOF:*p1++)
inline ll rnt(){
ll x=0,w=1;char c=gc();
while(!isdigit(c)){if(c=='-')w=-1;c=gc();}
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=gc();
return x*w;
}
void Dfs(ll u,ll fa,ll num){
tr.Add(num);
far(pr,tu[u]){
ll v=pr.first,w=pr.second;
if(v==fa)continue;
Dfs(v,u,num^w);
}
}
inline void In(){
n=rnt();
_for(i,1,n-1){
ll u=rnt(),v=rnt(),w=rnt();
tu[u].push_back(make_pair(v,w));
tu[v].push_back(make_pair(u,w));
}
Dfs(1,0,0);
printf("%lld\n",tr.Solve(1,1,0));
return;
}
}
Nikitosh 和异或
思路
刚开始由于我只会我的非主流最大异或对写法,想了好久都不会,后来看了眼题解学会了主流写法,瞬间就会做了……
设 \(l_i\) 表示 \(1\sim i\) 中异或和最大的一段区间,\(r_i\) 表示 \(i\sim n\) 中异或和最大的一段区间(注意:\(i\) 不必须是左/右端点)。
答案显然是:
\]
那么如何求 \(l_i\) 和 \(r_i\) 呢?
一段区间的异或和一定是该区间左右端点各自的前缀/后缀异或和的异或和,那么我们预处理出所有前/后缀异或和,再对每一个左/右端点查找包含它自己的最大异或对即可。
代码
点击查看代码
const ll N=4e5+10,M=N<<5,inf=1ll<<40;
ll n,a[N],sum1[N],sum2[N],l[N],r[N],ans;
class Trie{
private:
ll tot=1;
class TRIE{public:ll nx[2];}tr[M];
public:
inline void Add(ll num){
stack<ll>st;ll p=1;
_for(i,1,31)st.push(num&1),num>>=1;
while(!st.empty()){
if(!tr[p].nx[st.top()])tr[p].nx[st.top()]=++tot;
p=tr[p].nx[st.top()],st.pop();
}
return;
}
inline ll Find(ll num){
stack<ll>st;ll p=1,ans=0;
_for(i,1,31)st.push(num&1),num>>=1;
while(!st.empty()){
if(tr[p].nx[st.top()^1])p=tr[p].nx[st.top()^1],ans=ans<<1|(st.top()^1);
else p=tr[p].nx[st.top()],ans=ans<<1|st.top();
st.pop();
}
return ans;
}
}tr1,tr2;
namespace SOLVE{
char buf[1<<20],*p1,*p2;
#define gc() (p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<20,stdin),p1==p2)?EOF:*p1++)
inline ll rnt(){
ll x=0,w=1;char c=gc();
while(!isdigit(c)){if(c=='-')w=-1;c=gc();}
while(isdigit(c))x=(x<<3)+(x<<1)+(c^48),c=gc();
return x*w;
}
inline void In(){
n=rnt(),tr1.Add(0),tr2.Add(0);
_for(i,1,n)a[i]=rnt();
_for(i,1,n){
sum1[i]=sum1[i-1]^a[i],tr1.Add(sum1[i]);
l[i]=max(l[i-1],tr1.Find(sum1[i])^sum1[i]);
}
for_(i,n,1){
sum2[i]=sum2[i+1]^a[i],tr2.Add(sum2[i]);
r[i]=max(r[i+1],tr2.Find(sum2[i])^sum2[i]);
}
_for(i,1,n-1)ans=max(ans,l[i]+r[i+1]);
printf("%lld\n",ans);
return;
}
}
\]
「学习笔记」字符串基础:Hash,KMP与Trie的更多相关文章
- 「学习笔记」Treap
「学习笔记」Treap 前言 什么是 Treap ? 二叉搜索树 (Binary Search Tree/Binary Sort Tree/BST) 基础定义 查找元素 插入元素 删除元素 查找后继 ...
- 「学习笔记」Min25筛
「学习笔记」Min25筛 前言 周指导今天模拟赛五分钟秒第一题,十分钟说第二题是 \(\text{Min25}\) 筛板子题,要不是第三题出题人数据范围给错了,周指导十五分钟就 \(\text{AK ...
- 「学习笔记」FFT 之优化——NTT
目录 「学习笔记」FFT 之优化--NTT 前言 引入 快速数论变换--NTT 一些引申问题及解决方法 三模数 NTT 拆系数 FFT (MTT) 「学习笔记」FFT 之优化--NTT 前言 \(NT ...
- 「学习笔记」FFT 快速傅里叶变换
目录 「学习笔记」FFT 快速傅里叶变换 啥是 FFT 呀?它可以干什么? 必备芝士 点值表示 复数 傅立叶正变换 傅里叶逆变换 FFT 的代码实现 还会有的 NTT 和三模数 NTT... 「学习笔 ...
- 「学习笔记」wqs二分/dp凸优化
[学习笔记]wqs二分/DP凸优化 从一个经典问题谈起: 有一个长度为 \(n\) 的序列 \(a\),要求找出恰好 \(k\) 个不相交的连续子序列,使得这 \(k\) 个序列的和最大 \(1 \l ...
- 「刷题笔记」哈希,kmp,trie
Bovine Genomics 暴力 str hash+dp 设\(dp[i][j]\)为前\(i\)组匹配到第\(j\)位的方案数,则转移方程 \[dp[i][j+l]+=dp[i-1][j] \] ...
- 「学习笔记」ST表
问题引入 先让我们看一个简单的问题,有N个元素,Q次操作,每次操作需要求出一段区间内的最大/小值. 这就是著名的RMQ问题. RMQ问题的解法有很多,如线段树.单调队列(某些情况下).ST表等.这里主 ...
- 「学习笔记」递推 & 递归
引入 假设我们想计算 \(f(x) = x!\).除了简单的 for 循环,我们也可以使用递归. 递归是什么意思呢?我们可以把 \(f(x)\) 用 \(f(x - 1)\) 表示,即 \(f(x) ...
- 「学习笔记」Fast Fourier Transform
前言 快速傅里叶变换(\(\text{Fast Fourier Transform,FFT}\) )是一种能在\(O(n \log n)\)的时间内完成多项式乘法的算法,在\(OI\)中的应用很多,是 ...
随机推荐
- AcWing-1022
题解借鉴两位大佬的解析 墨染空 && 野生铅笔 本题是一道 01背包 的扩展题 -- 二维费用01背包问题 把 野生宝可梦 看做物品,则捕捉他需要的 精灵球 个数就是第一费用,战斗皮神 ...
- .NET中检测文件是否被其他进程占用
更新记录 本文迁移自Panda666原博客,原发布时间:2021年7月2日. 一.检测文件是否被进程占用的几种方式 在.NET中主要有以下方式进行检测文件是否被进程占用的几种方式: 通过直接打开文件等 ...
- VR技术赋能五大领域,不止高级,更高效!
除了VR游戏.VR影视作品,究竟还有哪些产业领域会应用到VR技术并为生活带来改变呢?今天就帮大家好好梳理一下~ VR赋能交通,不只是高级 最近在网上看到了VR考驾照的新闻,网友都赞叹,现在学车都这么高 ...
- Opentelemetry SDK的简单用法
Opentelemetry SDK的简单用法 概述 Opentelemetry trace的简单架构图如下,客户端和服务端都需要启动一个traceProvider,主要用于将trace数据传输到reg ...
- centos服务器安全技巧
系统管理员都应该烂熟于心的: 务必保证系统是 最新的 经常更换密码 - 使用数字.字母和非字母的符号组合 给予用户 最小 的权限,满足他们日常使用所需即可 只安装那些真正需要的软件包 1. 更改默认的 ...
- MySQL数据检索时,sql查询的结果如何加上序号
1.sql语法 @i:类型java定义的变量 @i:=0:这里类似给i初始化值为0 @i:=@i+1 :每次从0开始递增+1 SELECT (@i:=@i+1) as id,TDLINE FROM Y ...
- Django数据库性能优化之 - 使用Python集合操作
前言 最近有个新需求: 人员基础信息(记作人员A),10w 某种类型的人员信息(记作人员B),1000 要求在后台上(Django Admin)分别展示:已录入A的人员B列表.未录入的人员B列表 团队 ...
- echart图表中y轴小数位数过长展示效果不佳
业务中后端返回的精密数据,小数过长,导致所有数据差距不大,在图表中显示重合为一条直线 解决方法设置echart的min属性 min: "dataMin", 但是设置了以后又出现了问 ...
- 【Python爬虫技巧】快速格式化请求头Request Headers
你好,我是 @马哥python说 . 我们在写爬虫时,经常遇到这种问题,从目标网站把请求头复制下来,粘贴到爬虫代码里,需要一点一点修改格式,因为复制的是字符串string格式,请求头需要用字典dict ...
- 2022-07-11 第六组 润土 JavaScript01学习笔记
1.JS的数据类型: 数字 字符串 布尔型 空(null) unefined(未定义) 2.定义变量 var let(不可重复) const(常量不可更改) 3.复杂的数据类型: 数组:一个变量对应多 ...