GIL互斥锁与线程
GIL互斥锁与线程
GIL互斥锁验证是否存在
"""
昨天我们买票的程序发现很多个线程可能会取到同一个值进行剪除,证明了数据是并发的,但是我们为了证明在Cpython中证明是存在GIL那么我们就使用列表将他存起来,证明有GIL是串连而不是并发态
"""
from threading import Thread
count = 100
def task():
global count
count -= 1
t1_list = []
if __name__ == '__main__':
for i in range(100):
t = Thread(target=task)
t.start()
t1_list.append(t)
for t in t1_list:
t.join()
print(t1_list)
print(count) # 0
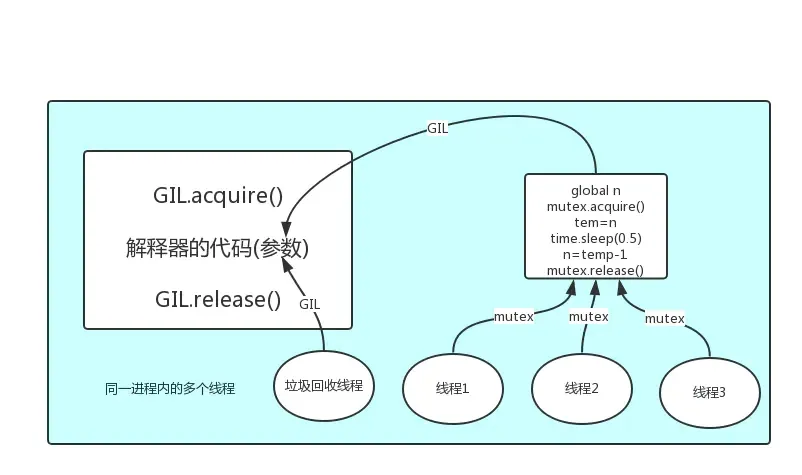
GIL互斥锁的特点
"""
我们在给它加一个IO操作的时候那么他就不会产生GIL,所以它不会影响程序层面的数据也不会保证他的修改是安全的想要保证就需要程序员手动给她加一把锁
"""
from threading import Thread
import time
count = 100
def task():
global count
num = count
time.sleep(0.1)
count = num - 1
t1_list = []
if __name__ == '__main__':
for i in range(100):
t = Thread(target=task)
t.start()
t1_list.append(t)
for t in t1_list:
t.join()
print(t1_list)
print(count) # 99
"""
自己给自己加锁来完成统计
"""
from threading import Thread,Lock
import time
count = 100
mutex = Lock()
def task():
mutex.acquire()
global count
num = count
time.sleep(0.1)
count = num - 1
mutex.release()
t1_list = []
if __name__ == '__main__':
for i in range(100):
t = Thread(target=task)
t.start()
t1_list.append(t)
for t in t1_list:
t.join()
print(t1_list)
print(count) # 0
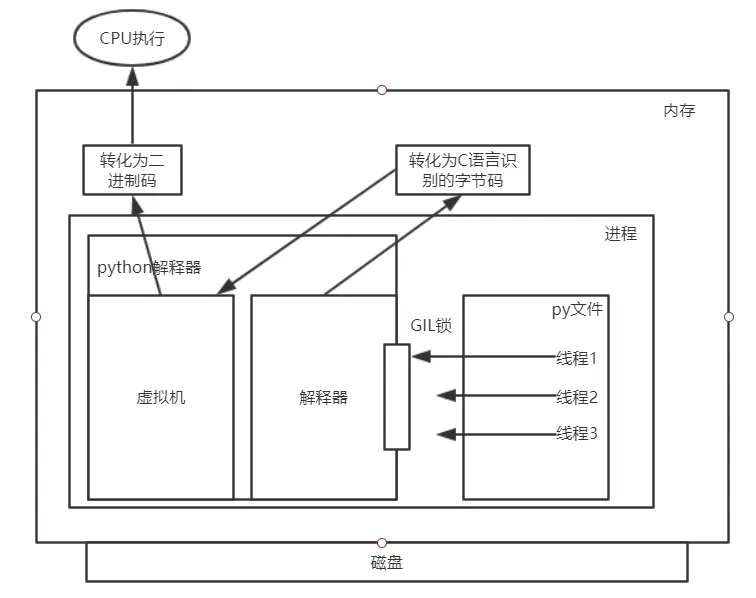
验证python多线程的作用
多种验证方法
- 条件1 单个cpu
- IO密集型操作
- 计算密集操作
- 条件2 多个cpu
- IO密集型操作
- 计算密集操作
- 条件1 单个cpu
单CPU操作
1.io密集型的多进程
需要在内存中多次申请额外的内存空间,需要消耗更多的时间和资源
2.io密集型的多线程
只需要在进程中申请自己所需要的代码即可,只需要通过多道的技术那么就可以实现多线程操作,消耗的资源和时间较少
3.计算密集型的多进程
同样需要在内存中申请额外的内存空间,然后消耗更多的时间和资源(总计算耗时和申请内存空间的时间,拷贝代码的时间再加上各个进程之间切换的时间)
4.计算密集型的多线程
只需要在进程中申请自己所需要的代码即可,并且通过多道技术直接执行(总计算消耗的时间和切换到各线程的时间)
5.总结
所以说在单cup中python的多线程还是非常有用的,即节省内存空间又速度较快
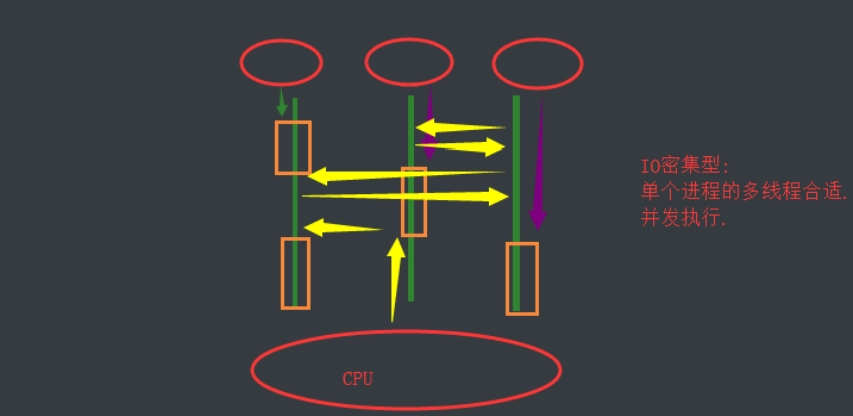
多CPU操作
1.io密集型的多进程
总耗时(单个进程的耗时+IO操作的耗时+申请内存空间的耗时+拷贝代码的耗时)
2.io密集型的多线程
总耗时(单个线程的耗时+IO操作的耗时)
3.计算密集型的多进程
总耗时(单个进程的耗时)
4.计算密集型的多线程
总耗时(多个进程的耗时总和,但是由于内部有优化代码,所以实际上没有那么长的时间进行计算)
5.总结
在多CUP进行密集型计算时由于多进程可以有多个核进行计算所以计算时间会非常短所以在多CPU多计算模型的情况下多进程占据主要又是,也可以称之为完胜,而多线程因为没有办法享用多cpu的好处所以只能一个CPU慢慢计算。

- 多CPU代码展示
1.小知识使用代码查看自己电脑是几核处理
import os
print(os.cpu_count()) # 12
2.展示多计算状态的运行
from threading import Thread
from multiprocessing import Process
import os
import time
def work():
res = 1
for i in range(1,100000):
res *= i
if __name__ == '__main__':
start_time = time.time()
p_list = []
for i in range(12):
p = Process(target=work)
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('总耗时:%s'%(time.time() - start_time)) # 总耗时:5.136746883392334
if __name__ == '__main__':
start_time = time.time()
t_list = []
for i in range(12):
t = Thread(target=work)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print('总耗时:%s' % (time.time() - start_time)) # 总耗时:27.33429765701294
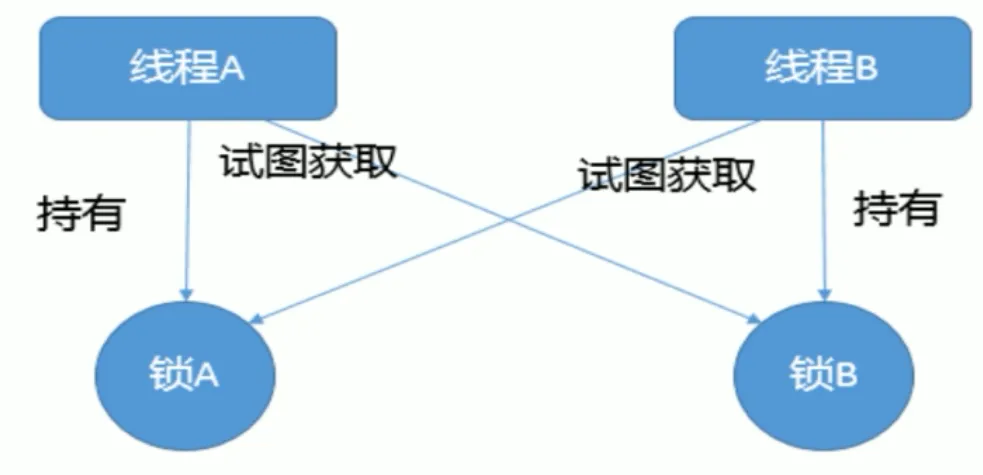
死锁现象
"""
死锁的情况是因为,想要获取我们的想要获取的对象在对方手中而对象想要获取的锁在我们的手中那么就会出现死锁的情况,两方都想要对方的锁,但是自身都有锁
"""
from threading import Thread,Lock
import time
mutexA = Lock()
mutexB = Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print(f'子进程{self.name}获取A锁')
time.sleep(3)
mutexB.acquire()
print(f'子进程{self.name}获取B锁')
mutexB.release()
print(f'子进程{self.name}获取B锁')
mutexA.release()
print(f'子进程{self.name}获取A锁')
def func2(self):
mutexB.acquire()
print(f'子进程{self.name}获取B锁')
time.sleep(3)
mutexA.acquire()
print(f'子进程{self.name}获取A锁')
mutexA.release()
print(f'子进程{self.name}获取A锁')
mutexB.release()
print(f'子进程{self.name}获取B锁')
for i in range(10):
t = Thread()
t.start()
信号量
- 信号量其实本质上也是互斥锁,只不过他这个是多把锁我们可以定义他这个锁的个数,控制线程的最大运行量
- 信号量在不同的变成语言体系中代表的意思可能不太一样,在我们python的并发编程中代表的是多把互斥锁的意思,而在djangomouge中,他则是代表的是某个条件出发的中间件所以不能一概而论,听到信号量就下定论
- 信号量演示
from threading import Thread,Semaphore
import time
import random
SP = Semaphore(3) # 设置信号量为3也就是三把锁
class MyThread(Thread):
def run(self):
SP.acquire()
print(self.name)
time.sleep(random.randint(1,3))
SP.release()
for i in range(20):
t = MyThread()
t.start()
event事件
- 子进程之间可以互相彼此等彼此使用event就可以让一个进程等另一个进程发号师令然后开始运行
- 展示
from threading import Thread,Event
import time
import random
event = Event()
def light():
print('比赛准备开始,本场次有黑哨请所有人启动赛车听到自己的指令出发')
time.sleep(random.randint(1,5))
print('预备,鸣发动机,let GO!GO!GO!')
event.set() # 发送指令
def car(name):
print(f'{name}正在启动赛车')
event.wait() # 等待指令
print(f'{name}发动机轰鸣后出发了')
t = Thread(target=light)
t.start()
l1 = ['Joseph','Alice','Trump','kdi','jason']
for i in l1:
t = Thread(target=car,args=(f'选手{i}',))
t.start()

进程池与线程池和概念
- 在我们的进程和线程中既然我门做服务的时候可以产生很多的进程和线程同时运行的结果,那么我们可以无限制的开启进程和线程可以嘛
- 哒咩,肯定不行鉴于我们的科技水平和技术发展程度,都没有任何硬件可以支持我们进行无限制开启进程和线程,所以我们就需要在硬件的承受范围内创造一个阀值以防资源消耗过度使之损毁。那么产生了我们的进程池和线程池的作用
- 进程池和线程池都会帮我们在使用之前就创建好空的进程和线程,我们以后用的时候就会自动分配给你,不需要重新创建。
进程池与线程池的实际操作
"""
进程池和线程池本质上就是帮它定了一个阀值,让他只能在这个阀值内运行多了那么对不起,你等着吧
"""
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import current_thread
import os
import time
pool1 = ProcessPoolExecutor(3)
pool2 = ThreadPoolExecutor(3)
def task(n):
print(current_thread().name)
print(os.getpid())
print(os.getppid())
print(n)
time.sleep(1)
return '会返回什么呢'
def func(*args,**kwargs):
print('func',args,kwargs)
print(args[0].result())
if __name__ == '__main__':
for i in range(5):
res = pool1.submit(task,123)
print(res.result())
pool1.submit(task,123).add_done_callback(func)
if __name__ == '__main__':
for i in range(5):
res = pool2.submit(task,123)
print(res.result())
pool2.submit(task,123).add_done_callback(func)
pool2.submit(task,123).add_done_callback(func)
协程简介
- 进程:资源单位,需要从内存中开辟空间
- 线程:执行单位,只需要在进程中执行
- 协程:单线程下实现并发(携程:一款旅行软件,住酒店看携程)
- 协程其实就是在单线程下我们的线程进入IO状态的情况下欺骗CPU让它觉得没有遇到io操作继续运行代码,其实io被我们的代码检测出来一旦有的话就立即让cpu执行别的东西实现无缝连接,这个东西是程序员自己搞出来的,名字也是它起的(协调程序运行,黑心老板压榨cpu剩余劳动力)
from gevent import monkey;monkey.patch_all() # 就是这样写的,我也不知道为什么(猴子补丁)
from gevent import spawn
import time
def func1():
print('func1 正在执行')
time.sleep(3)
print('func1 执行完毕')
def func2():
print('func2 正在执行')
time.sleep(6)
print('func2 执行完毕')
if __name__ == '__main__':
start_time = time.time()
# func1()
# func2() # 9.022636413574219
s1 = spawn(func1) # 一旦遇到io操作那么就立即跳到别的地方执行,如果都在io那么久反复横跳
s2 = spawn(func2) # # 6.01244044303894
s1.join()
s2.join()
print(time.time() - start_time)

协程的实际作用简单实现单线程协程工作
1.服务端
import socket
from gevent import monkey;monkey.patch_all()
from gevent import spawn
def communication(sock):
while True:
data = sock.recv(1024)
print(data.decode('utf-8'))
sock.send(data.upper())
def get_server():
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
sock,address = server.accept()
spawn(communication,sock)
s1 = spawn(get_server)
s1.join()
2.客户端
import socket
from threading import Thread,current_thread
def get_client():
client = socket.socket()
client.connect(('127.0.0.1',8080))
while True:
client.send(f'good night {current_thread().name}'.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
for i in range(20):
t = Thread(target=get_client)
t.start()
论如何累死一头牛
- 在多进程的情况下使用多线程操作并且在多线程的情况下使用多协程操作,资本家看了都泪目的行为,纯纯的极致压迫和剥削。

GIL互斥锁与线程的更多相关文章
- python并发编程-进程间通信-Queue队列使用-生产者消费者模型-线程理论-创建及对象属性方法-线程互斥锁-守护线程-02
目录 进程补充 进程通信前言 Queue队列的基本使用 通过Queue队列实现进程间通信(IPC机制) 生产者消费者模型 以做包子买包子为例实现当包子卖完了停止消费行为 线程 什么是线程 为什么要有线 ...
- GIL全局解释器锁+GIL全局解释器锁vs互斥锁+定时器+线程queue+进程池与线程池(同步与异步)
以多线程为例写个互斥锁 from threading import Thread ,Lockimport timemutex = Lock() n = 100 def task(): global n ...
- python多线程编程(3): 使用互斥锁同步线程
问题的提出 上一节的例子中,每个线程互相独立,相互之间没有任何关系.现在假设这样一个例子:有一个全局的计数num,每个线程获取这个全局的计数,根据num进行一些处理,然后将num加1.很容易写出这样的 ...
- 8.12 day31 进程间通信 Queue队列使用 生产者消费者模型 线程理论 创建及对象属性方法 线程互斥锁 守护线程
进程补充 进程通信 要想实现进程间通信,可以用管道或者队列 队列比管道更好用(队列自带管道和锁) 管道和队列的共同特点:数据只有一份,取完就没了 无法重复获取用一份数据 队列特点:先进先出 堆栈特点: ...
- python中上双互斥锁的线程执行流程
import threading def sing(): print('进入sing -----------------') for i in range(3): print('进入sing循环 -- ...
- 并发编程 - 线程 - 1.互斥锁/2.GIL解释器锁/3.死锁与递归锁/4.信号量/5.Event事件/6.定时器
1.互斥锁: 原理:将并行变成串行 精髓:局部串行,只针对共享数据修改 保护不同的数据就应该用不用的锁 from threading import Thread, Lock import time n ...
- 【python】-- GIL锁、线程锁(互斥锁)、递归锁(RLock)
GIL锁 计算机有4核,代表着同一时间,可以干4个任务.如果单核cpu的话,我启动10个线程,我看上去也是并发的,因为是执行了上下文的切换,让看上去是并发的.但是单核永远肯定时串行的,它肯定是串行的, ...
- OpenMP 线程互斥锁
OpenMP是跨平台的多核多线程编程的一套指导性的编译处理方案(Compiler Directive),指导编译器将代码编译为多线程程序. 多线程编程中肯定会涉及到线程之间的资源共享问题,就可以使用互 ...
- Python 开启线程的2中方式,线程VS进程(守护线程、互斥锁)
知识点一: 进程:资源单位 线程:才是CPU的执行单位 进程的运行: 开一个进程就意味着开一个内存空间,存数据用,产生的数据往里面丢 线程的运行: 代码的运行过程就相当于运行了一个线程 辅助理解:一座 ...
随机推荐
- netty系列之:我有一个可扩展的Enum你要不要看一下?
目录 简介 enum和Enum netty中可扩展的Enum:ConstantPool 使用ConstantPool 总结 简介 很多人都用过java中的枚举,枚举是JAVA 1.5中引用的一个新的类 ...
- LOJ数列分块 9 题解
\(1.\) 题意 给定一个长度 \(n\) 序列,每次查询区间 \(l, r\) 的众数. \(2.\) 思路 如果边界是 \([l,r]\),\(l\) 在第 \(a\) 块,\(r\) 在第 \ ...
- Improved Security for a Ring-Based Fully Homomorphic Encryption Scheme-2013:解读
本文记录阅读此论文的笔记 摘要 (1)1996年,HPS三人提出一个格上的高效加密方案,叫做NTRUEncrypt,但是没有安全性证明:之后2011年,SS等人修改此方案,将其安全规约到标准格上的困难 ...
- 面向对象的封装(粘贴Markdown代码解决缩进问题)
直接粘贴idea的代码会导致缩进错乱,建议先粘贴到记事本再粘贴到笔记!!! 1.先将属性私有化,再对外提供简单的接口可以访问内部.如set.get方法 2.set方法:修改年龄 public void ...
- linux配置svn
1.安装 yum install subversion 2.测试安装是否成功: svnserve --version 3.创建目录并配置 建立版本库目录 mkdir -pv /data/svn/svn ...
- 从20s优化到500ms,我用了这三招
前言 接口性能问题,对于从事后端开发的同学来说,是一个绕不开的话题.想要优化一个接口的性能,需要从多个方面着手. 其实,我之前也写过一篇接口性能优化相关的文章<聊聊接口性能优化的11个小技巧&g ...
- manjaro 安装后的基本配置
第一步:设置官方镜像源 sudo pacman-mirrors -i -c China -m rank # 输入以上命令后会有弹出框,选择一个国内镜像(推荐 https://mirrors.ustc. ...
- java。多态
package Demo.oop.APP.Demo05; public class application { public static void main(String[] args) { //一 ...
- Grid属性太多记不住?【Grid栅格布局可视化编辑器】直观易懂高效,拖拉拽,有手就行!
手把手教你通过拖拉拽可视化的方式带你练习[Grid栅格布局]的各个属性,直观易懂!再也不愁记不住繁多的Grid属性了.整个过程在众触应用平台进行,不用手写一行CSS代码. grid-auto-flow ...
- GET 请求和 POST 请求的区别和使用
作为前端开发, HTTP 中的 POST 请求和 GET 请求是经常会用到的东西,有的人可能知道,但对其原理和如何使用并不特别清楚,那么今天来浅谈一下两者的区别与如何使用. GET请求和POST请求的 ...