强化学习-学习笔记7 | Sarsa算法原理与推导
Sarsa算法 是 TD算法的一种,之前没有严谨推导过 TD 算法,这一篇就来从数学的角度推导一下 Sarsa 算法。注意,这部分属于 TD算法的延申。
7. Sarsa算法
7.1 推导 TD target
推导:Derive。
这一部分就是Sarsa 最重要的内核。
折扣回报:$U_t=R_t+\gamma R_{t+1}+\gamma^2 R_{t+2}+\gamma^3 R_{t+3}+\cdots \ \quad={R_t} + \gamma \cdot U_{t+1} $
即 将\(R_{t+1}\)之后 都提出一个 \(\gamma\) 项,后面括号中的式子意义正为 \(U_{t+1}\)
通常认为奖励 \(R_t\)依赖于 t 时刻的状态 \(S_t\) 与 动作 \(A_t\) 以及 t+1 时刻的状态 \(S_{t+1}\)。
当时对于为什么依赖于 \(S_{t+1}\) 有疑问,我回去翻看了 学习笔记1:https://www.cnblogs.com/Roboduster/p/16442003.html ,发现并强调了以下这一点:
“值得注意的是,这个 r1 是什么时候给的?是在状态 state s2 的时候给的。”
状态价值函数 \(Q_\pi({s_t},{a_t}) = \mathbb{E}[U_t|{s_t},{a_t}]\) 是回报 \(U_t\) 的期望;
- 用折扣回报的变换式,把\(U_t\)替换掉:\(Q_\pi({s_t},{a_t}) = \mathbb{E}[{R_t} + \gamma \cdot U_{t+1} |{s_t}{a_t}]\)
- 有两项期望,分解开:\(= \mathbb{E}[{R_t} |{s_t},{a_t}] + \gamma \cdot\mathbb{E}[ U_{t+1} |{s_t},{a_t}]\)
下面研究上式的第二项:\(\mathbb{E}[ U_{t+1} |{s_t},{a_t}]\)
其等于 \(\mathbb{E}[ Q_\pi({s_{t+1}},{a_{t+1}}) |{s_t},{a_t}]\)
Q 是 U 的期望:所以 \(E(E[])=E()\),期望的期望还是原来的期望;这里是逆用这个性质。这么做是为了让等式两边都有 \(Q_\pi\) 函数,如下:
于是便得到: \(Q_\pi({s_t},{a_t}) =\mathbb{E}[{R_t} |{s_t},{a_t}] + \gamma\cdot\mathbb{E}[ Q_\pi({s_{t+1}},{a_{t+1}}) {s_t},{a_t}] \\ Q_\pi({s_t},{a_t})=\mathbb{E}[{R_t} + \gamma \cdot Q_\pi({S_{t+1}},{A_{t+1}})]\)
右侧有一个期望,但直接求期望很困难,所以通常是对期望求蒙特卡洛近似。
- \(R_t\) 近似为观测到奖励\(r_t\)
- \(Q_\pi({S_{t+1}},{A_{t+1}})\)用观测到的 \(Q_\pi({s_{t+1}},{a_{t+1}})\) 来近似
- 得到蒙特卡洛近似值\(\approx {r_t} + \gamma \cdot Q_\pi({s_{t+1}},{a_{t+1}})\)
- 将这个值表示为 TD target \(y_t\)
TD learning 目标:让 $Q_\pi({s_t},{a_t}) $ 来接近部分真实的奖励 \(y_t\)。
\(Q_\pi\) 完全是估计,而 \(y_t\) 包含了一部分真实奖励,所以 \(y_t\) 更可靠。
7.2 Sarsa算法过程
这是一种TD 算法。
a. 表格形式
如果我们想要学习动作价值 $Q_\pi({s_t},{a_t}) $,假设状态和动作都是有限的,可以画一个表来表示:
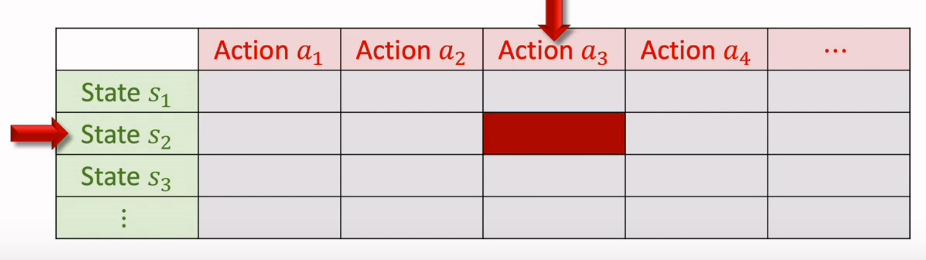
- 表每个元素代表一个动作价值;
- 用 Sarsa 算法更新表格,每次更新一个元素;
在表格形式中,每次观测到一个四元组\(({s_t},{a_t},{r_t},{s_{t+1}})\),称为一个 transition
根据策略函数 \(\pi\) 随机采样计算下一个动作,记作\({a_{t+1}}\sim\pi(\cdot|{s_{t+1}})\);
计算TD target: \(y_t = {r_t} + \gamma \cdot Q_\pi({s_{t+1}},{a_{t+1}})\),
前一部分是观测到的奖励,后面一部分是对未来动作的打分,\(Q_\pi({s_{t+1}},{a_{t+1}})\) 可以通过查表得知。
表最开始是通过一定方式初始化的(比如随机),然后通过不断计算来更新表格。
通过查表,还知道\(Q_\pi({s_{t}},{a_{t}})\)的值,可以计算:
TD error:\(\delta_t = Q_\pi({s_{t}},{a_{t}}) -y_t\);
最后用 \(\delta_t\) 来更新:\(Q_\pi({s_{t}},{a_{t}}) \leftarrow Q_\pi({s_{t}},{a_{t}}) - \alpha \cdot \delta_t\),并写入表格相应的位置
$\alpha $是学习率。通过TD error 更新,可以让 Q 更好的接近 \(y_t\)。
每一步中,Sarsa 算法用 \((s_t,a_T,r_t,s_{t+1},a_{t+1})\) 来更新 \(Q_\pi\),sarsa,这就是算法名字的由来。
b. 神经网络形式
值得留意的是表格形式的假设:假设状态和动作都是有限的,而当状态和动作很多,表格就会很大,很难学习。
用神经网络-价值网络 \(q({s},{a};w)\) 来近似\(Q_\pi({s},{a})\),Sarsa算法可以训练这个价值网络。
- actor-critic 那篇用过 Sarsa 算法,想不起来往下看:
- q 和 Q 都与 策略函数 \(\pi\) 有关。
- 网络参数 \(\omega\) 初始时随机初始化,后续不断更新。
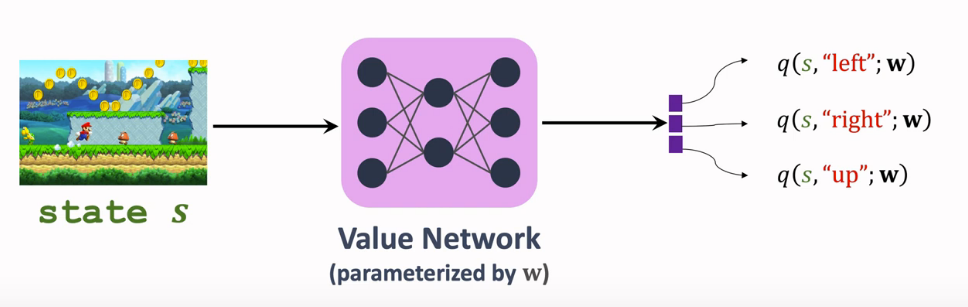
输入状态是 s ,输出就是所有动作的价值
- actor-critic 方法中,q 作为 critic 用来评估 actor;用 sarsa 这一 TD 学习算法更新的价值网络。
- TD target: \(y_t = {r_t} + \gamma \cdot q({s_{t+1}},{a_{t+1}};w)\)
- TD error:\(\delta_t = q({s_{t}},{a_{t}};w) - y_t\)
- Loss: \(\delta_t ^2/2\),我们的目的是通过更新网络参数 w 来降低 Loss;
- 梯度:\(\frac{\partial\delta_t ^2/2}{\partial w} = \delta_t \cdot \frac{\partial q({s_{t}},{a_{t}};w)}{\partial w}\)
- 梯度下降更新 w:$$w \leftarrow w - \alpha \cdot \delta_t \cdot \frac{\partial q({s_{t}},{a_{t}};w)}{\partial w}$$
7.3 一些解惑 / 有什么不同
这一篇跟第二篇价值学习内容看似很接近,甚至在第四篇 actor-critic 中也有提及,可能会困惑 这个第七篇有什么特别的,我也困惑了一会儿,然后我发现是自己的学习不够仔细:
第二篇和第四篇的 价值网络 学习方法并不同。虽然都用到了 以TD target 为代表的TD 算法。但是两者的学习函数并不相同!
Sarsa算法 学习动作价值函数 \(Q_\pi(s,a)\)
Actor-Critic 中的价值网络j就是用 Sarsa 训练的
而第二篇 DQN 中的 TD 学习 是训练最优动作价值函数:
$Q ^*( s , a ) $而这种方法在下一篇中很快会提及,这就是 Q-learning 方法。
参考:
强化学习-学习笔记7 | Sarsa算法原理与推导的更多相关文章
- 深度学习课程笔记(九)VAE 相关推导和应用
深度学习课程笔记(九)VAE 相关推导和应用 2018-07-10 22:18:03 Reference: 1. TensorFlow code: https://jmetzen.github.io/ ...
- 【机器学习】算法原理详细推导与实现(六):k-means算法
[机器学习]算法原理详细推导与实现(六):k-means算法 之前几个章节都是介绍有监督学习,这个章解介绍无监督学习,这是一个被称为k-means的聚类算法,也叫做k均值聚类算法. 聚类算法 在讲监督 ...
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- 深入学习主成分分析(PCA)算法原理(Python实现)
一:引入问题 首先看一个表格,下表是某些学生的语文,数学,物理,化学成绩统计: 首先,假设这些科目成绩不相关,也就是说某一科目考多少分与其他科目没有关系,那么如何判断三个学生的优秀程度呢?首先我们一眼 ...
- ng-深度学习-课程笔记-7: 优化算法(Week2)
1 Mini-batch梯度下降 在做梯度下降的时候,不选取训练集的所有样本计算损失函数,而是切分成很多个相等的部分,每个部分称为一个mini-batch,我们对一个mini-batch的数据计算代价 ...
- 分布式系列文章——Paxos算法原理与推导
Paxos算法在分布式领域具有非常重要的地位.但是Paxos算法有两个比较明显的缺点:1.难以理解 2.工程实现更难. 网上有很多讲解Paxos算法的文章,但是质量参差不齐.看了很多关于Paxos的资 ...
- 【转载】分布式系列文章——Paxos算法原理与推导
转载:http://linbingdong.com/2017/04/17/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E5%88%97%E6%96%87%E7%AB%A0 ...
- 多层神经网络BP算法 原理及推导
首先什么是人工神经网络?简单来说就是将单个感知器作为一个神经网络节点,然后用此类节点组成一个层次网络结构,我们称此网络即为人工神经网络(本人自己的理解).当网络的层次大于等于3层(输入层+隐藏层(大于 ...
- AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法. 1.AdaBoost算法介绍 AdaBoost是Boosting方法中最优代表性的提升算法.该方法通过在每轮降低分对样例的权重 ...
随机推荐
- 6.1 SHELL脚本
6.1 SHELL脚本元素 第一行的脚本声明(#!)用来告诉系统使用哪种Shell解释器来执行该脚本: 第二行的注释信息(#)是对脚本功能和某些命令的介绍信息,使得自己或他人在日后看到这个脚本内容时, ...
- lab_0 清华大学ucore实验环境配置详细步骤!(小白入)
实验步骤 1.下载项目 从github上 的https://github.com/kiukotsu/ucore下载 ucore lab实验: git clone https://github.com/ ...
- 修复Arch Linux和Manjaro Linux无法显示emoji的问题
安装好Arch Linux或Manjaro Linux系统后默认没办法正常显示emoji,通常会变成方框或者带有unicode码的方块: 这是因为缺失字体以及相关的字体配置导致的. 当然也有一小部分应 ...
- 一行代码如何隐藏 Linux 进程?
开源Linux 长按二维码加关注~ 上一篇:IPv6技术白皮书(附PDF下载) 总有朋友问隐藏Linux进程的方法,我说你想隐藏到什么程度,是大隐于内核,还是小隐于用户.网上通篇论述的无外乎 hook ...
- ts中 any、unknown、never 、void的区别
any.unknown.never .void的区别 any 表示任意类型,设置为any相当于对该变量关闭了TS的类型检测.不建议使用 let a;(隐式any) //声明变量不赋值,就是any 等效 ...
- 【Java面试】Spring中 BeanFactory和FactoryBean的区别
一个工作了六年多的粉丝,胸有成竹的去京东面试. 然后被Spring里面的一个问题卡住,唉,我和他说,6年啦,Spring都没搞明白? 那怎么去让面试官给你通过呢? 这个问题是: Spring中Bean ...
- Numpy的一些操作
1.什么是Numpy 简单来说: Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组. Numpy支持常见的数组和矩阵操作.对于同样的数值计算 ...
- Ceph集群搭建记录
环境准备 基础环境 node00 192.168.247.144 node00 node01 192.168.247.135 node01 node02 192.168.247.143 node02 ...
- 看看CabloyJS是如何实现编辑页面脏标记的
应用场景 我们在使用Word.Excel时,当修改了内容之后在标题栏会显示脏标记,从而可以明确的告知用户内容有变动.此外,如果在没有保存的情况下关闭窗口,系统会弹出提示框,让用户选择是否放弃修改 那么 ...
- vue大型电商项目尚品汇(后台篇)day04
昨天太晚就没来得及更新,今天是spu管理界面,这个界面一共有三个界面需要切换,完成了两个界面,而且今天的难度在于最后两个章节,富有一定的逻辑性,当然中间也有很多需要注意的,比如ElementUI的照片 ...