Similarity calculation
推荐算法入门(相似度计算方法大全)
一、协同过滤算法简介
在推荐系统的众多方法之中,基于用户的协同过滤是诞最早的,原理也比较简单。基于协同过滤的推荐算法被广泛的运用在推荐系统中,比如影视推荐、猜你喜欢等、邮件过滤等。该算法1992年提出并用于邮件过滤系统,两年后1994年被 GroupLens 用于新闻过滤。一直到2000年,该算法都是推荐系统领域最著名的算法。
当用户A需要个性化推荐的时候,可以先找到和他兴趣详细的用户集群G,然后把G喜欢的并且A没有的物品推荐给A,这就是基于用户的协同过滤。
根据上述原理,我们可以将算法分为两个步骤:
找到与目标兴趣相似的用户集群
找到这个集合中用户喜欢的、并且目标用户没有听说过的物品推荐给目标用户。
二、常用的相似度计算方法
下面,简单的举例几个机器学习中常用的样本相似性度量方法:
- 欧式距离(Euclidean Distance)
- 余弦相似度(Cosine)
- 皮尔逊相关系数(Pearson)
- 修正余弦相似度(Adjusted Cosine)
- 汉明距离(Hamming Distance)
- 曼哈顿距离(Manhattan Distance)
欧式距离(Euclidean Distance)
欧式距离全称是欧几里距离,是最易于理解的一种距离计算方式,源自欧式空间中两点间的距离公式。
- 平面空间内的
与
间的欧式距离:
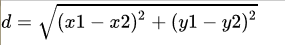
- 三维空间里的欧式距离:
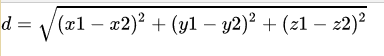
- Python 代码简单实现:
def EuclideanDistance(x,y):
d = 0
for a,b in zip(x,y):
d += (a-b)**2
return d**0.5
- 使用 numpy 简化:
import numpy as np
def EuclideanDistance(dataA,dataB):
# np.linalg.norm 用于范数计算,默认是二范数,相当于平方和开根号
return 1.0/(1.0 + np.linalg.norm(dataA - dataB))
余弦相似度(Cosine)
首先,样本数据的夹角余弦并不是真正几何意义上的夹角余弦,只不过是借了它的名字,实际是借用了它的概念变成了是代数意义上的“夹角余弦”,用来衡量样本向量间的差异。
夹角越小,余弦值越接近于1,反之则趋于-1。我们假设有x1与x2两个向量:
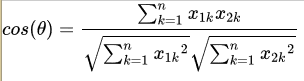
- Python 代码的简单按公式还原:
def Cosine(x,y):
sum_xy = 0.0;
normX = 0.0;
normY = 0.0;
for a,b in zip(x,y):
sum_xy += a*b
normX += a**2
normY += b**2
if normX == 0.0 or normY == 0.0:
return None
else:
return sum_xy / ((normX*normY)**0.5)
- 使用 numpy 简化夹角余弦
def Cosine(dataA,dataB):
sumData = dataA *dataB.T # 若列为向量则为 dataA.T * dataB
denom = np.linalg.norm(dataA) * np.linalg.norm(dataB)
# 归一化
return 0.5 + 0.5 * (sumData / denom)
我们引入一组特殊数据进行测试:
dataA = np.mat([1,2,3,3,2,1])
dataB = np.mat([2,3,4,4,3,2])
print(EuclideanDistance(dataA,dataB)) # 0.28
print(Cosine(dataA,dataB)) # 0.99
欧式距离和夹角余弦的区别:
对比以上的结果的 dataA 与 dataB 这两组数据,会发现 dataA 与 dataB 的欧式距离相似度比较小,而夹角余弦相似度比较大,即夹角余弦更能反映两者之间的变动趋势,两者有很高的变化趋势相似度,而欧式距离较大是因为两者数值有很大的区别,即两者拥有很高的数值差异。
皮尔逊相关系数(Pearson Correlation Coefficient)
假如之不先介绍夹角余弦的话,第一次接触你绝对会对皮尔逊相关系数一脸懵逼。那么现在,让我们再来理解一下皮尔逊相关系数的公式:
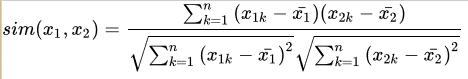
* 这里减去的 每个item被打分的均值
皮尔逊相关系数公式实际上就是在计算夹角余弦之前将两个向量减去各个样本的平均值,达到中心化的目的。从知友的回答可以明白,皮尔逊相关函数是余弦相似度在维度缺失上面的一种改进方法。
- Python 代码实现皮尔逊相关系数:
def Pearson(x,y):
sum_XY = 0.0
sum_X = 0.0
sum_Y = 0.0
normX = 0.0
normY = 0.0
count = 0
for a,b in zip(x,y):
count += 1
sum_XY += a * b
sum_X += a
sum_Y += b
normX += a**2
normY += b**2
if count == 0:
return 0
# denominator part
denominator = (normX - sum_X**2 / count)**0.5 * (normY - sum_Y**2 / count)**0.5
if denominator == 0:
return 0
return (sum_XY - (sum_X * sum_Y) / count) / denominator
- numpy 简化实现皮尔逊相关系数
def Pearson(dataA,dataB):
# 皮尔逊相关系数的取值范围(-1 ~ 1),0.5 + 0.5 * result 归一化(0 ~ 1)
return 0.5 + 0.5 * np.corrcoef(dataA,dataB,rowvar = 0)[0][1]
用余弦相似度相同的方法实现皮尔逊:
# 余弦相似度、修正余弦相似度、皮尔逊相关系数的关系
# Pearson 减去的是每个item i 的被打分的均值
def Pearson(dataA,dataB):
avgA = np.mean(dataA)
avgB = np.mean(dataB)
sumData = (dataA - avgA) * (dataB - avgB).T # 若列为向量则为 dataA.T * dataB
denom = np.linalg.norm(dataA - avgA) * np.linalg.norm(dataB - avgB)
# 归一化
return 0.5 + 0.5 * (sumData / denom)
修正余弦相似度
- 为什么需要在余弦相似度的基础上使用修正余弦相似度
X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得到的结果是0.98,两者极为相似。但从评分上看X似乎不喜欢2这个 内容,而Y则比较喜欢,余弦相似度对数值的不敏感导致了结果的误差,需要修正这种不合理性
# 修正余弦相似度
# 修正cosine 减去的是对item i打过分的每个user u,其打分的均值
data = np.mat([[1,2,3],[3,4,5]])
avg = np.mean(data[:,0]) # 下标0表示正在打分的用户
def AdjustedCosine(dataA,dataB,avg):
sumData = (dataA - avg) * (dataB - avg).T # 若列为向量则为 dataA.T * dataB
denom = np.linalg.norm(dataA - avg) * np.linalg.norm(dataB - avg)
return 0.5 + 0.5 * (sumData / denom)
print(AdjustedCosine(data[0,:],data[1,:],avg))
汉明距离(Hamming distance)
汉明距离表示的是两个字符串(相同长度)对应位不同的数量。比如有两个等长的字符串 str1 = "11111" 和 str2 = "10001" 那么它们之间的汉明距离就是3(这样说就简单多了吧。哈哈)。汉明距离多用于图像像素的匹配(同图搜索)。
1.Python 的矩阵汉明距离简单运用:
def hammingDistance(dataA,dataB):
distanceArr = dataA - dataB
return np.sum(distanceArr == 0)# 若列为向量则为 shape[0]
曼哈顿距离(Manhattan Distance)
没错,你也是会曼哈顿计量法的人了,现在开始你和秦风只差一张刘昊然的脸了。想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,那么驾驶的最近距离并不是直线距离,因为你不可能横穿房屋。所以,曼哈顿距离表示的就是你的实际驾驶距离,即两个点在标准坐标系上的绝对轴距总和。
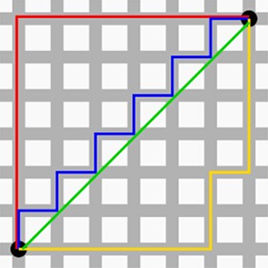
# 曼哈顿距离(Manhattan Distance)
def Manhattan(dataA,dataB):
return np.sum(np.abs(dataA - dataB))
print(Manhattan(dataA,dataB))
本文转自--->:https://zhuanlan.zhihu.com/p/33164335
(如有侵权,联系删除)
Similarity calculation的更多相关文章
- NLTK vs SKLearn vs Gensim vs TextBlob vs spaCy
Generally, NLTK is used primarily for general NLP tasks (tokenization, POS tagging, parsing, etc.) S ...
- OpenCASCADE Curve Length Calculation
OpenCASCADE Curve Length Calculation eryar@163.com Abstract. The natural parametric equations of a c ...
- 机器学习中的相似性度量(Similarity Measurement)
机器学习中的相似性度量(Similarity Measurement) 在做分类时常常需要估算不同样本之间的相似性度量(Similarity Measurement),这时通常采用的方法就是计算样本间 ...
- cosine similarity
Cosine similarity is a measure of similarity between two non zero vectors of an inner product space ...
- [SimHash] find the percentage of similarity between two given data
SimHash algorithm, introduced by Charikarand is patented by Google. Simhash 5 steps: Tokenize, Hash, ...
- 自定义评分器Similarity,提高搜索体验(转)
文章转自:http://blog.csdn.net/duck_genuine/article/details/6257540 首先说一下lucene对文档的评分规则: score(q,d) = ...
- jaccard similarity coefficient 相似度计算
Jaccard index From Wikipedia, the free encyclopedia The Jaccard index, also known as the Jaccard ...
- hdu4965 Fast Matrix Calculation (矩阵快速幂 结合律
http://acm.hdu.edu.cn/showproblem.php?pid=4965 2014 Multi-University Training Contest 9 1006 Fast Ma ...
- 1063. Set Similarity (25)
1063. Set Similarity (25) 时间限制 300 ms 内存限制 32000 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue Given ...
随机推荐
- java中接口和抽象类有什么区别,举例!
2)接口和抽象类有什么区别?答:马克-to-win:抽象类里可以有实现的方法,接口里不能有,所以相对来讲各方面实现都简单(尤其动态方法调度).另外:类可以实现多个接口.反过来说,也正是抽象类一个致命伤 ...
- Java中重载的应用
学习目标: 掌握Java方法的重载 学习内容: 1.重载定义 参数列表: 参数的类型 + 参数的个数 + 参数的顺序 方法签名: 方法名称 + 方法参数列表,在同一个类中,方法签名是唯一的,否则编译报 ...
- DOS控制台
:win+r--cmd--回车* A:d: 回车 盘符切换* B:dir(directory):列出当前目录下的文件以及文件夹* C:cd (change directory)改变指定目录(进入指定目 ...
- WebSocket学习笔记
参考文章链接:http://www.ruanyifeng.com/blog/2017/05/websocket.html 简单示例:https://www.yiibai.com/websocket/p ...
- 接口和抽象类的区别(不讲废话,干货满满,JDK1.8最新整理)
接口和抽象类的区别(不讲废话,干货满满,JDK1.8最新整理) 1.抽象类 以下说辞可能不太准确,但是会让你醍醐灌顶 抽象类是把一些具有共同属性(包括行为)的东西抽象出来,比如: 小狗有身高,体重,颜 ...
- Vue整合Quill富文本编辑器
Quill介绍 Quill是一款开源的富文本编辑器,基于可扩展的架构设计,提供丰富的 API 进行定制.截止2021年1月,在github上面已有28.8k的star. Quill项目地址:https ...
- Java学习day15
File是文件和目录路径名的抽象表示 文件和目录可以通过File封装成对象 对于File而言,封装的不是一个真正存在的文件,只是一个路径名,它可以存在,也可以不存在,要通过后续操作把路径的内容转换为具 ...
- Divan and bitwise operations
这是一道比较综合的数学题目,光是吧题目看懂就花了我好一会儿时间,先看看题目吧: 题目分析:对于m段给定连续段的或值,要求出n个数的序列子序列的异或值之和: 题解: 这道题,我们先不要把它当作一个数一个 ...
- jointJS初使用随记
jointJs使用随记 1.下载与安装 前提:一个健康良好且干净的vue脚手架项目. 还是普遍的安装方式 yarn:yarn add jointjs npm:npm install jointjs 还 ...
- 前台主页搭建、后台主页轮播图接口设计、跨域问题详解、前后端互通、后端自定义配置、git软件的初步介绍
今日内容概要 前台主页 后台主页轮播图接口 跨域问题详解 前后端打通 后端自定义配置 git介绍和安装 内容详细 1.前台主页 Homeviwe.vue <template> <di ...