架构解析:Dubbo3 应用级服务发现如何应对双11百万集群实例
继业务全面上云后,今年双11,阿里微服务技术栈全面迁移到以 Dubbo3 为代表的云上开源标准中间件体系。在业务上,基于 Dubbo3 首次实现了关键业务不停推、不降级的全面用户体验提升,从技术上,大幅提高研发与运维效率的同时地址推送等资源利用率在一些关键场景提升超 40%,基于三位一体的 Dubbo3 开源中间件体系打造了阿里在云上的单元化最佳实践和统一标准,同时将规模化实践经验与技术创新贡献开源社区,成为微服务开源技术与标准发展的核心源泉与推动力。
面对百万规模的集群实例,实现关键链路不停推、资源利用率大幅提升的关键即是 Dubbo3 中新引入的应用级服务发现。接下来我们着重讲解 Dubbo3 应用级服务发现的详细方案,同时通过饿了么案例来说明其升级迁移过程。
饿了么自去年 11月份启动 Dubbo3 相关的升级工作,在此之前饿了么的服务框架是用的 是 HSF2,从 HSF2 到 Dubbo3 的总体升级过程经历了半年,目前已基本完成,有近 2000 个应用、10w 个节点已经跑在 Dubbo3 之上。
通过这次分享,主要想给大家同步饿了么的 Dubbo3 升级经验,为什么升级 Dubbo3、升级的具体流程以及中间遇到的问题、尤其是饿了么重点关注的应用级服务发现模型,如何完成了地址发现模型的升级以及最终效果。当然在此之前,我们先对 Dubbo3 及应用级服务发现做一个全面的介绍。

关于 Dubbo3 的简介,期望通过这部分带大家了解 Dubbo3 到底是什么,与 2.7 架构的主要区别是什么,提供了哪些特性、可以解决哪些实际的问题等;其中也包括大家都关心兼容性、升级成本以及与 HSF2 的关系等。
我们定义 Dubbo3 是下一代的云原生服务框架,但 3.0 架构到底都包含哪些内容那?
我们先一起看看 3.0 的一些核心设计原则:首先,从架构层面 Dubbo 是面向云原生设计的,支持超大规模的微服务集群实践 - 百万实例级别,期望通过智能化流量调度系统提升系统稳定性与吞吐量;在策略层面,Dubbo3 的内核将是毫无保留开源的,它将成为国内公有云事实标准的服务框架,得到各大公有云厂商的支持,并通过灵活的 SPI 扩展机制支持不同部署场景的定制化需求;而在业务价值上,Dubbo3 将显著降低单机资源消耗,提升全链路资源利用率与服务治理效率。
这就是 3.0 设计过程中遵循的核心原则或目标,让我们从一个更高的层面认识了 Dubbo3。
具体到选型 Dubbo3 框架,大家一定关心 Dubbo3 提供了哪些新功能,如果是 Dubbo 老用户的话,还关心 Dubbo3 的兼容性,总结起来就是 Dubbo3 的迁移成本以及其能带来的核心价值。
左边这部分是关于 Dubbo3 兼容性及来源的详细描述。首先 Dubbo3 是从其自身 2.0 架构演进而来,因此它继承了 2.0 几乎所有的特性,且保持了对 Dubbo2 的完全兼容,因此,老用户几乎可以零成本迁移到 Dubbo3。Dubbo3 是在企业实践经验的基础上演进而来,我们知道 Dubbo 最初是由阿里开源并贡献给 Apache 社区,而这一次,阿里也已将 Dubbo3 定位为其下一代服务框架,因此,Dubbo3 融合了 HSF2 的几乎所有服务治理特性,并且已经开始在阿里巴巴全面取代 HSF2 框架,这一点我们在后面企业实践部分还会讲到。
右边是 Dubbo3 提供的核心特性列表,主要包括四部分。
- 全新服务发现模型。应用粒度服务发现,面向云原生设计,适配基础设施与异构系统;性能与集群伸缩性大幅提升
- 下一代 RPC 协议 Triple。基于 HTTP/2 的 Triple 协议,兼容 gRPC;网关穿透性强、多语言友好、支持 Reactive Stream
- 统一流量治理模型。面向云原生流量治理,SDK、Mesh、VM、Container 等统一治理规则;支持更丰富的流量治理场景
- Service Mesh。Sidecar Mesh 与 Proxyless Mesh,更多架构选择,降低迁移、落地成本
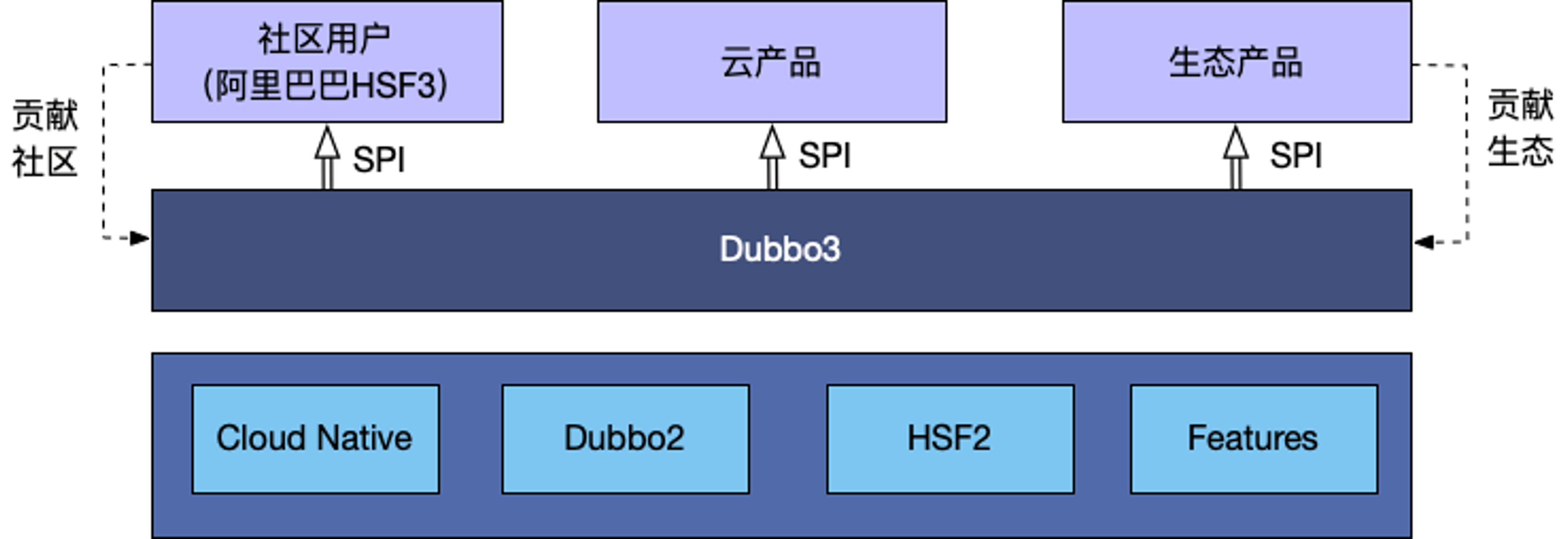
这张图更直观的反映了 Dubbo3 产生的背景以及与一些重要产品之间的关系。Dubbo3 诞生的基础是 Dubbo2、HSF2 两款产品,同时以云原生架构作为指导思想进行了大量重构,并规划一系列的功能特性;这些共同组成了 Dubbo3,也就是我们在 github 仓库及开源官网上看到的 Dubbo3;而在开源 Dubbo3 产品之上那,我们有基于 Dubbo3 的企业实践用户、生态产品以及公有云厂商的云产品。比如大家比较关心的 Dubbo3 典型用户阿里巴巴,阿里巴巴内部在此之前一直运行在自研 HSF2 框架,当然鉴于 HSF2 与 Dubbo2 的历史两者之间有很多相似之处,但实际却已经演进成两个不同的框架,在实现了 Dubbo3 的融合之后,阿里巴巴正在完全用开源 Dubbo3 取代 HSF2;在此,有些朋友可能会问,完全用开源的 Dubbo3 如何满足阿里自身特有的诉求?答案就是通过 SPI 扩展,所以在阿里内部现在还有一套 HSF3,而 HSF3 与以往的 HSF2 已经完全不同了,HSF3 完全就是基于标准 Dubbo3 的 SPI 扩展库,如注册中心扩展、路由组件扩展、监控组件扩展等,而其他配置组装、服务暴露、服务发现、地址解析等核心流程都是完全跑在 Dubbo3 之上;在这样的模式下,阿里巴巴的内部实践诉求都将完全体现在开源 Dubbo3 之上,包括内部开发人员也工作在开源 Dubbo3 之上。通过 SPI 扩展,同样也适用于公有云产品以及其他厂商的实践。
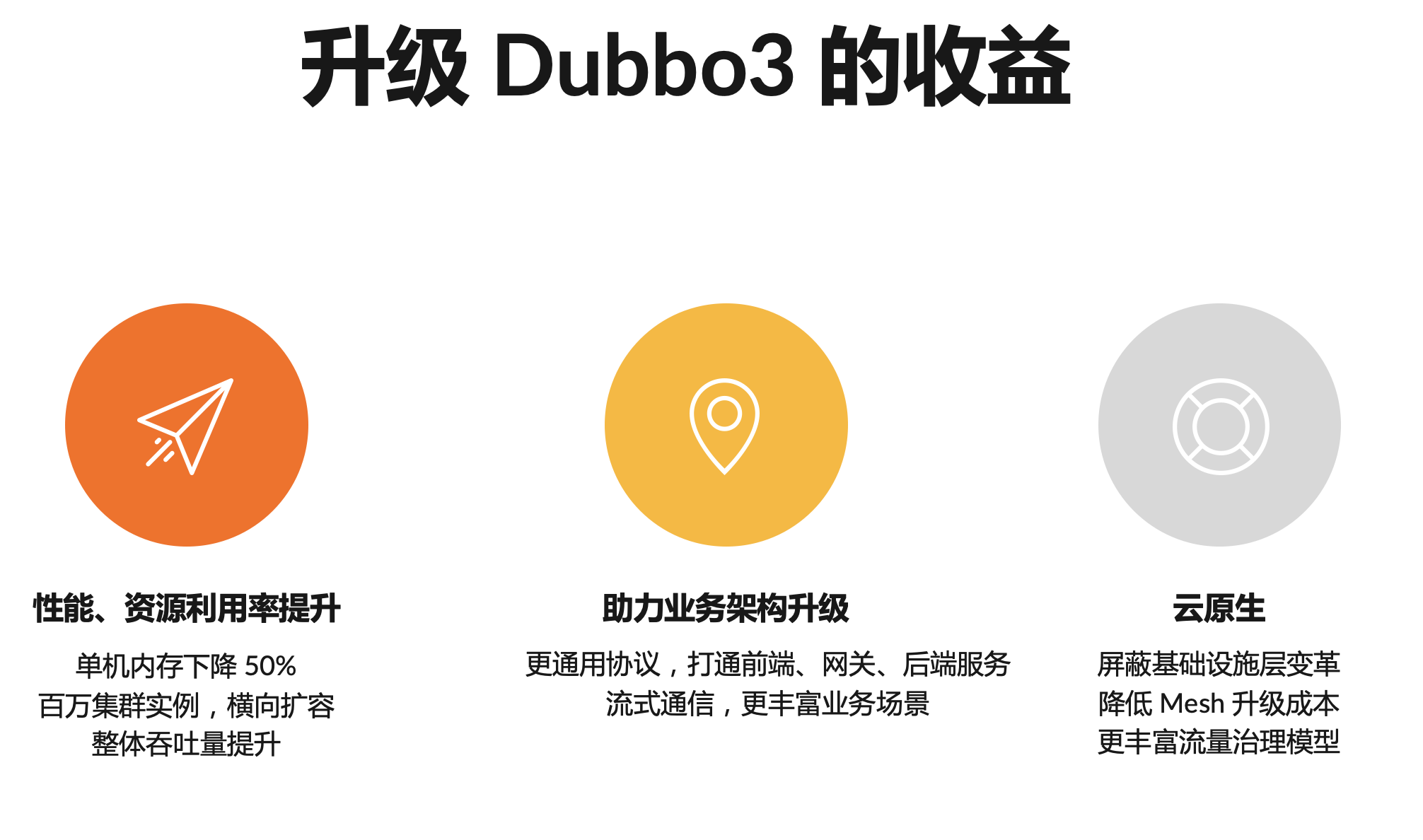
首先是性能、资源利用率的提升。升级 Dubbo3 的应用预期能实现单机内存 50% 的下降,对于越大规模的集群效果将越明显,Dubbo3 从架构上支持百万实例级别的集群横向扩展,同时依赖应用级服务发现、Triple协议等可以大大提供应用的服务治理效率和吞吐量。
其次,是 Dubbo3 让业务架构升级变得更容易、更合理。这个怎么理解那,其中值得重点关注的就是协议,在 2.x 版本中,web、移动端与后端的通信都要经过网关代理,完成协议转换、类型映射等工作,Triple 协议让这些变得更容易与自然;并通过流式通信模型满足更多的业务场景。
最后,得益于 Dubbo3 的完善云原生解决方案,Dubbo3 可以帮助业务屏蔽底层云原生基础设施细节,使得业务的迁移成本更低。
接下来我们着重讲解 Dubbo3 应用级服务发现的详细方案,也就是饿了么升级目标中最重要的一部分能力。
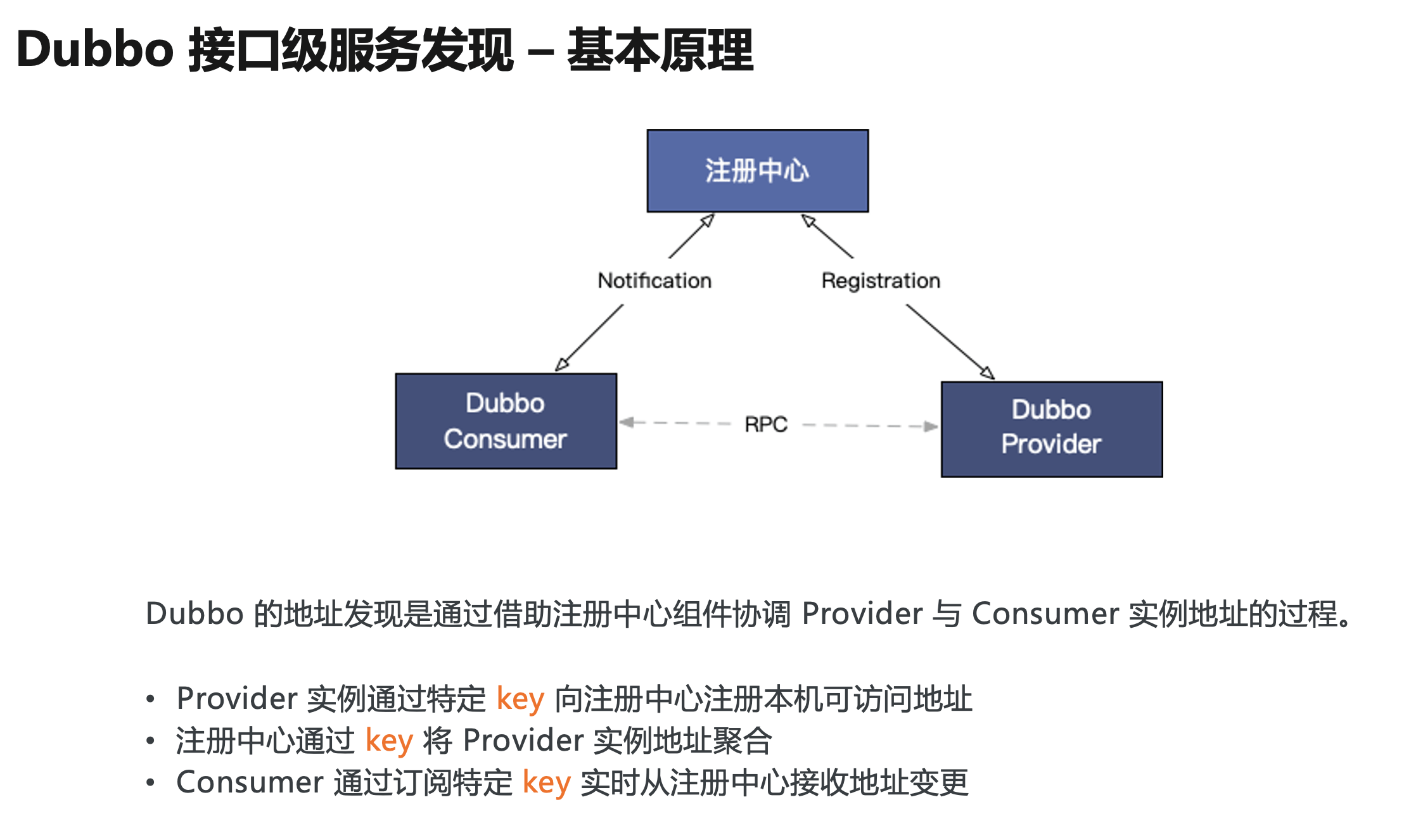
我们从 Dubbo 最经典的工作原理图说起,Dubbo 从设计之初就内置了服务地址发现的能力,Provider 注册地址到注册中心,Consumer 通过订阅实时获取注册中心的地址更新,在收到地址列表后,consumer 基于特定的负载均衡策略发起对 provider 的 RPC 调用。
在这个过程中
- 每个 Provider 通过特定的 key 向注册中心注册本机可访问地址;
- 注册中心通过这个 key 对 provider 实例地址进行聚合;
- Consumer 通过同样的 key 从注册中心订阅,以便及时收到聚合后的地址列表;
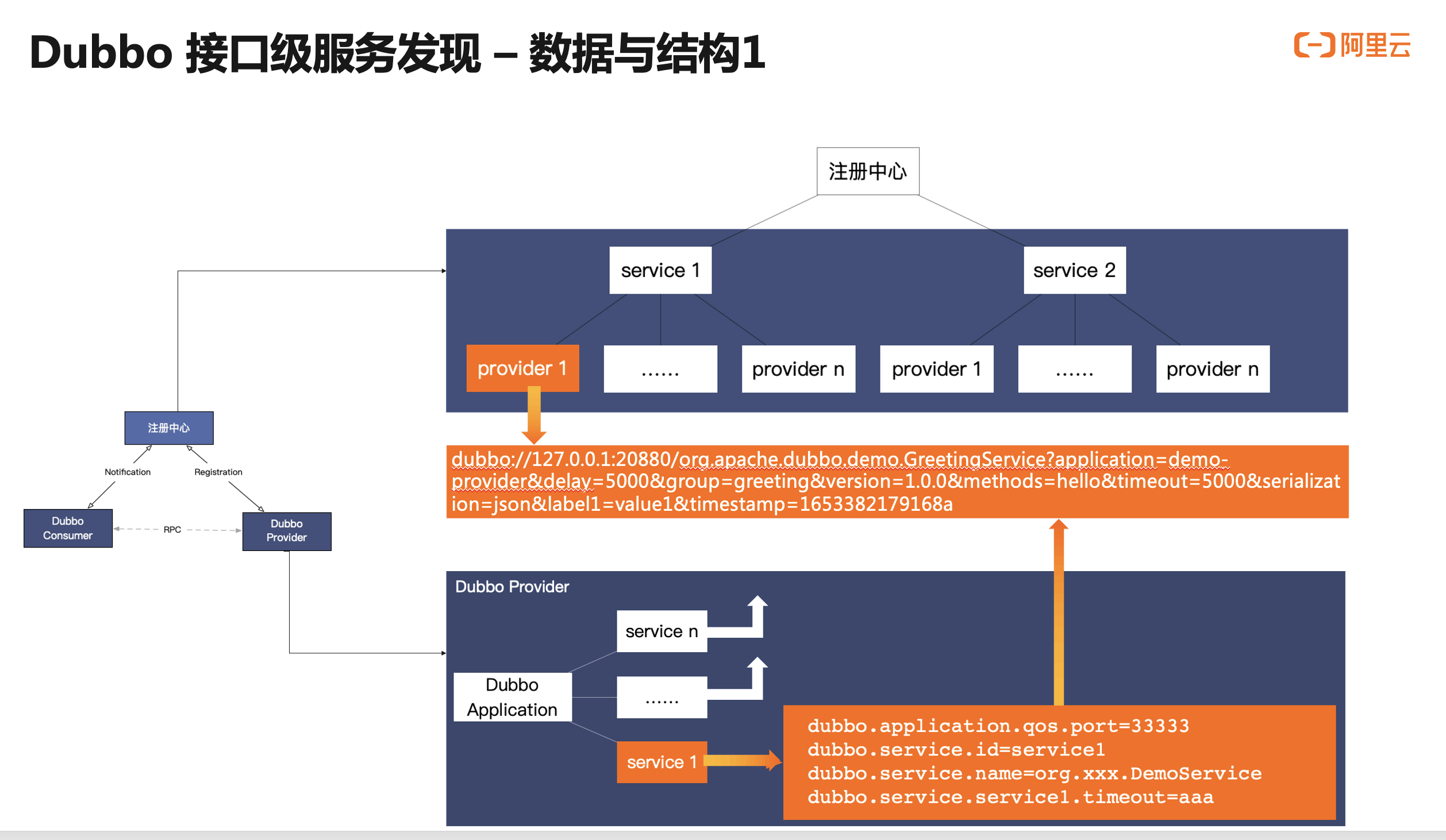
这里,我们对接口级地址发现的内部数据结构进行详细分析。
首先,看右下角 provider 实例内部的数据与行为。Provider 部署的应用中通常会有多个 Service,也就是 Dubbo2 中的服务,每个 service 都可能会有其独有的配置,我们所讲的 service 服务发布的过程,其实就是基于这个服务配置生成地址 URL 的过程,生成的地址数据如图所示;同样的,其他服务也都会生成地址。
然后,看一下注册中心的地址数据存储结构,注册中心以 service 服务名为数据划分依据,将一个服务下的所有地址数据都作为子节点进行聚合,子节点的内容就是实际可访问的ip地址,也就是我们 Dubbo 中 URL,格式就是刚才 provider 实例生成的。

我们再来看一下 URL 地址的详细格式,这里把 URL 地址数据划分成了几份:
- 首先是实例可访问地址,主要信息包含 ip port,是消费端将基于这条数据生成 tcp 网络链接,作为后续 RPC 数据的传输载体
- 其次是 RPC 元数据,元数据用于定义和描述一次 RPC 请求,一方面表明这条地址数据是与某条具体的 RPC 服务有关的,它的版本号、分组以及方法相关信息,另一方面表明
- 下一部分是 RPC 配置数据,部分配置用于控制 RPC 调用的行为,还有一部分配置用于同步 Provider 进程实例的状态,典型的如超时时间、数据编码的序列化方式等。
- 最后一部分是自定义的元数据,这部分内容区别于以上框架预定义的各项配置,给了用户更大的灵活性,用户可任意扩展并添加自定义元数据,以进一步丰富实例状态。
结合以上两页对于 Dubbo2 接口级地址模型的分析,以及最开始的 Dubbo 基本原理图,我们可以得出这么几条结论:
- 第一,地址发现聚合的 key 就是 RPC 粒度的服务
- 第二,注册中心同步的数据不止包含地址,还包含了各种元数据以及配置
- 得益于 1 与 2,Dubbo 实现了支持应用、RPC 服务、方法粒度的服务治理能力
这就是一直以来 Dubbo2 在易用性、服务治理功能性、可扩展性上强于很多服务框架的真正原因。
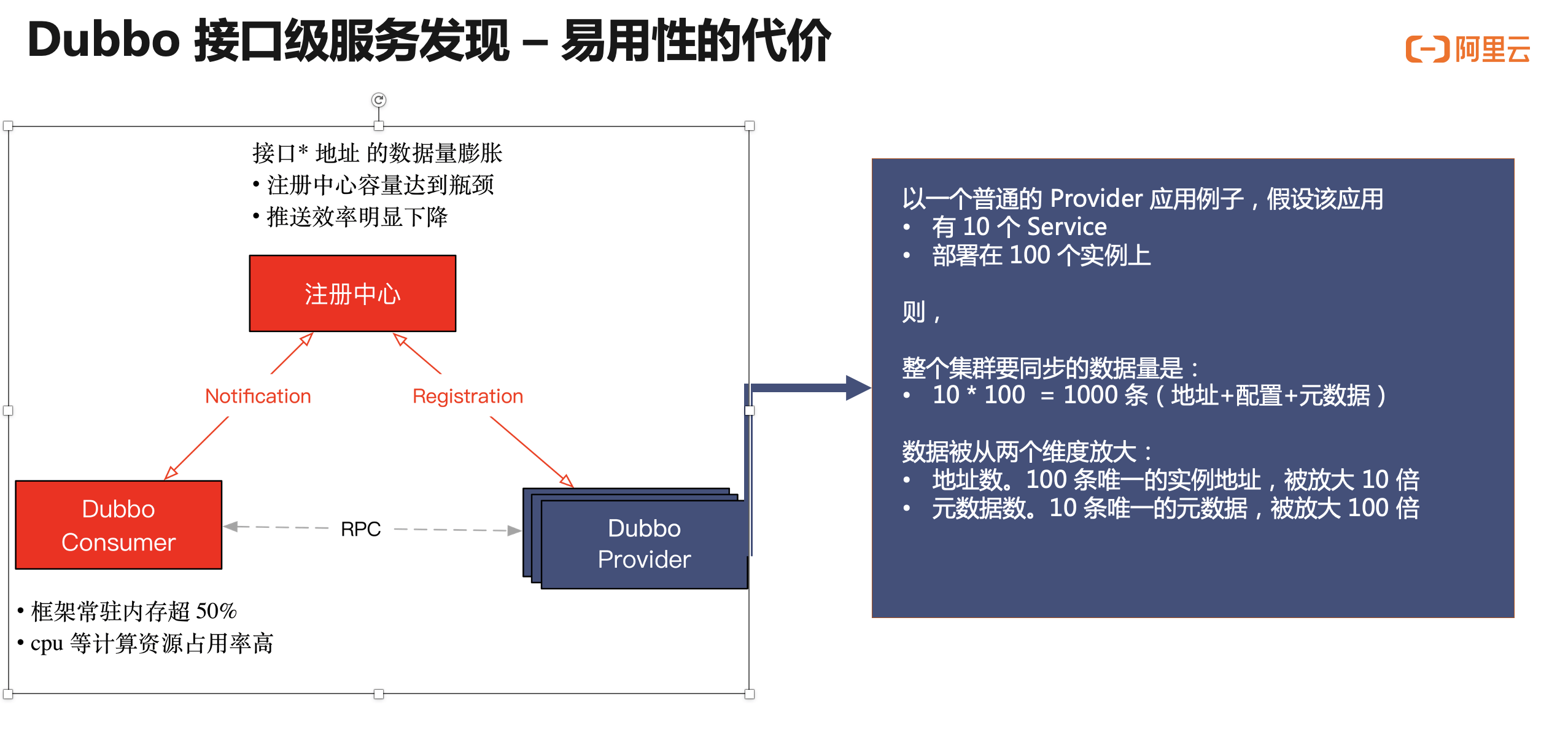
一个事物总是有其两面性,Dubbo2 地址模型带来易用性和强大功能的同时,也给整个架构的水平可扩展性带来了一些限制。这个问题在普通规模的微服务集群下是完全感知不到的,而随着集群规模的增长,当整个集群内应用、机器达到一定数量时,整个集群内的各个组件才开始遇到规模瓶颈。在总结包括阿里巴巴、工商银行等多个典型的用户在生产环境特点后,我们总结出以下两点突出问题(如图中红色所示):
- 首先,注册中心集群容量达到上限阈值。由于所有的 URL 地址数据都被发送到注册中心,注册中心的存储容量达到上限,推送效率也随之下降。
- 而在消费端这一侧,Dubbo2 框架常驻内存已超 40%,每次地址推送带来的 cpu 等资源消耗率也非常高,影响正常的业务调用。
为什么会出现这个问题?我们以一个具体 provider 示例进行展开,来尝试说明为何应用在接口级地址模型下容易遇到容量问题。
青蓝色部分,假设这里有一个普通的 Dubbo Provider 应用,该应用内部定义有 10 个 RPC Service,应用被部署在 100 个机器实例上。这个应用在集群中产生的数据量将会是 “Service 数 * 机器实例数”,也就是 10 * 100 = 1000 条。数据被从两个维度放大:
- 从地址角度。100 条唯一的实例地址,被放大 10 倍
- 从服务角度。10 条唯一的服务元数据,被放大 100 倍
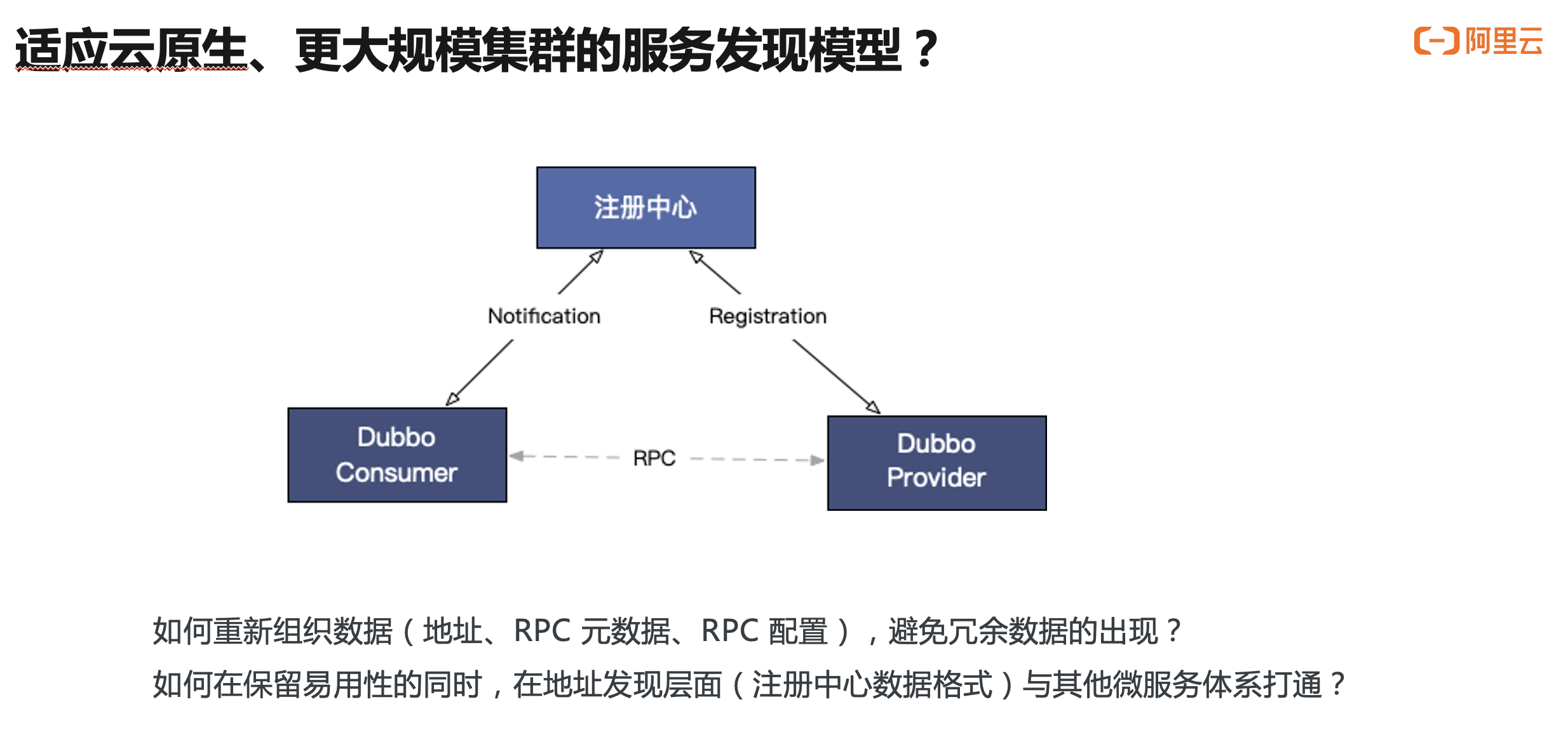
面对这个问题,在 Dubbo3 架构下,我们不得不重新思考两个问题:
- 如何在保留易用性、功能性的同时,重新组织 URL 地址数据,避免冗余数据的出现,让 Dubbo3 能支撑更大规模集群水平扩容?
- 如何在地址发现层面与其他的微服务体系如 Kubernetes、Spring Cloud 打通?

Dubbo3 的应用级服务发现方案设计本质上就是围绕以上两个问题展开。其基本思路是:地址发现链路上的聚合元素也就是我们之前提到的 Key 由服务调整为应用,这也是其名称叫做应用级服务发现的由来;另外,通过注册中心同步的数据内容上做了大幅精简,只保留最核心的 ip、port 地址数据。
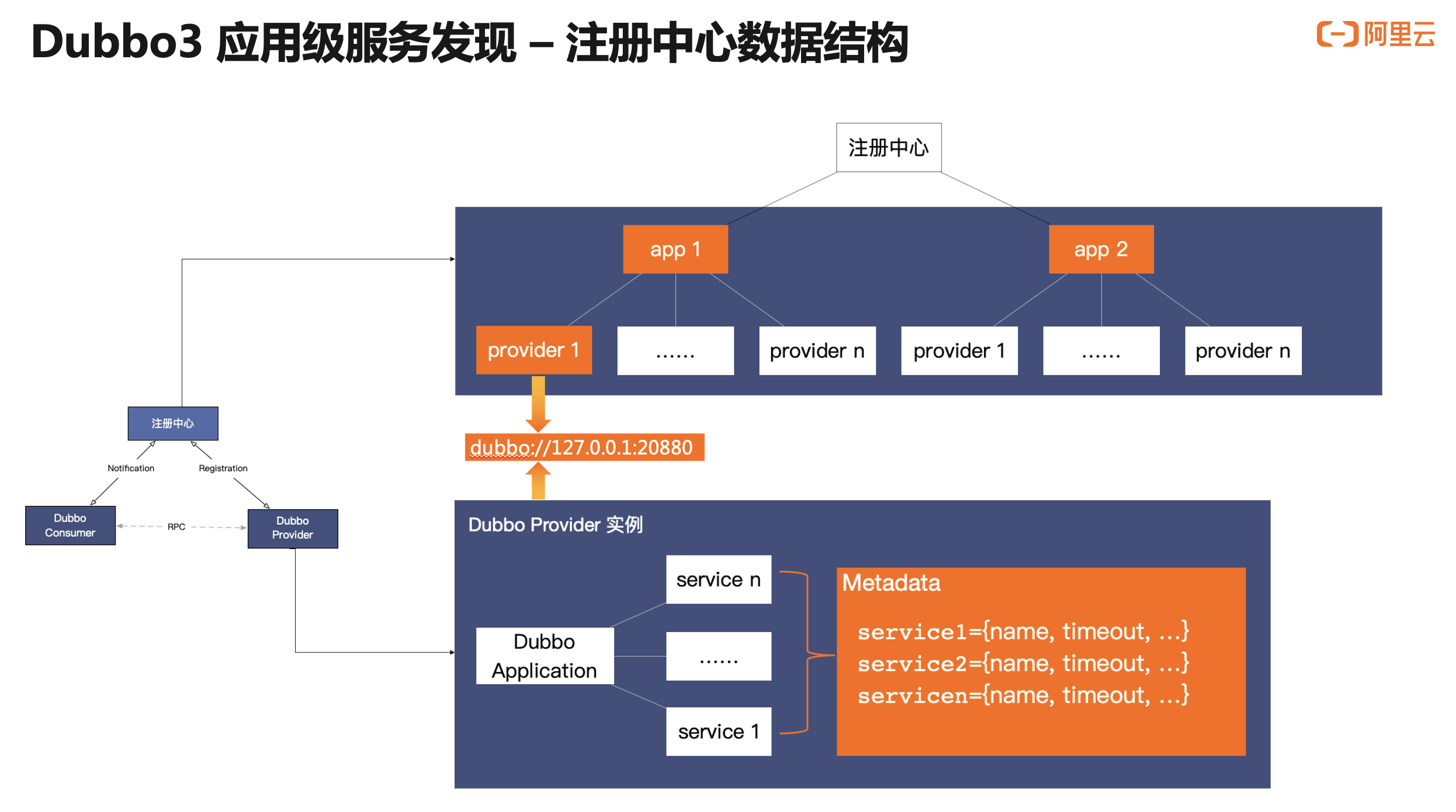
这是升级之后应用级地址发现的内部数据结构进行详细分析。
对比之前接口级的地址发现模型,我们主要关注橙色部分的变化。首先,在 provider 实例这一侧,相比于之前每个 RPC Service 注册一条地址数据,一个 provider 实例只会注册一条地址到注册中心;而在注册中心这一侧,地址以应用名为粒度做聚合,应用名节点下是精简过后的 provider 实例地址;

应用级服务发现的上述调整,同时实现了地址单条数据大小和总数量的下降,但同时也带来了新的挑战:我们之前 Dubbo2 强调的易用性和功能性的基础损失了,因为元数据的传输被精简掉了,如何精细的控制单个服务的行为变得无法实现。
针对这个问题,Dubbo3 的解法是引入一个内置的 MetadataService 元数据服务,由中心化推送转为 Consumer 到 Provider 的点对点拉取,在这个模式下,元数据传输的数据量将不在是一个问题,因此可以在元数据中扩展出更多的参数、暴露更多的治理数据。
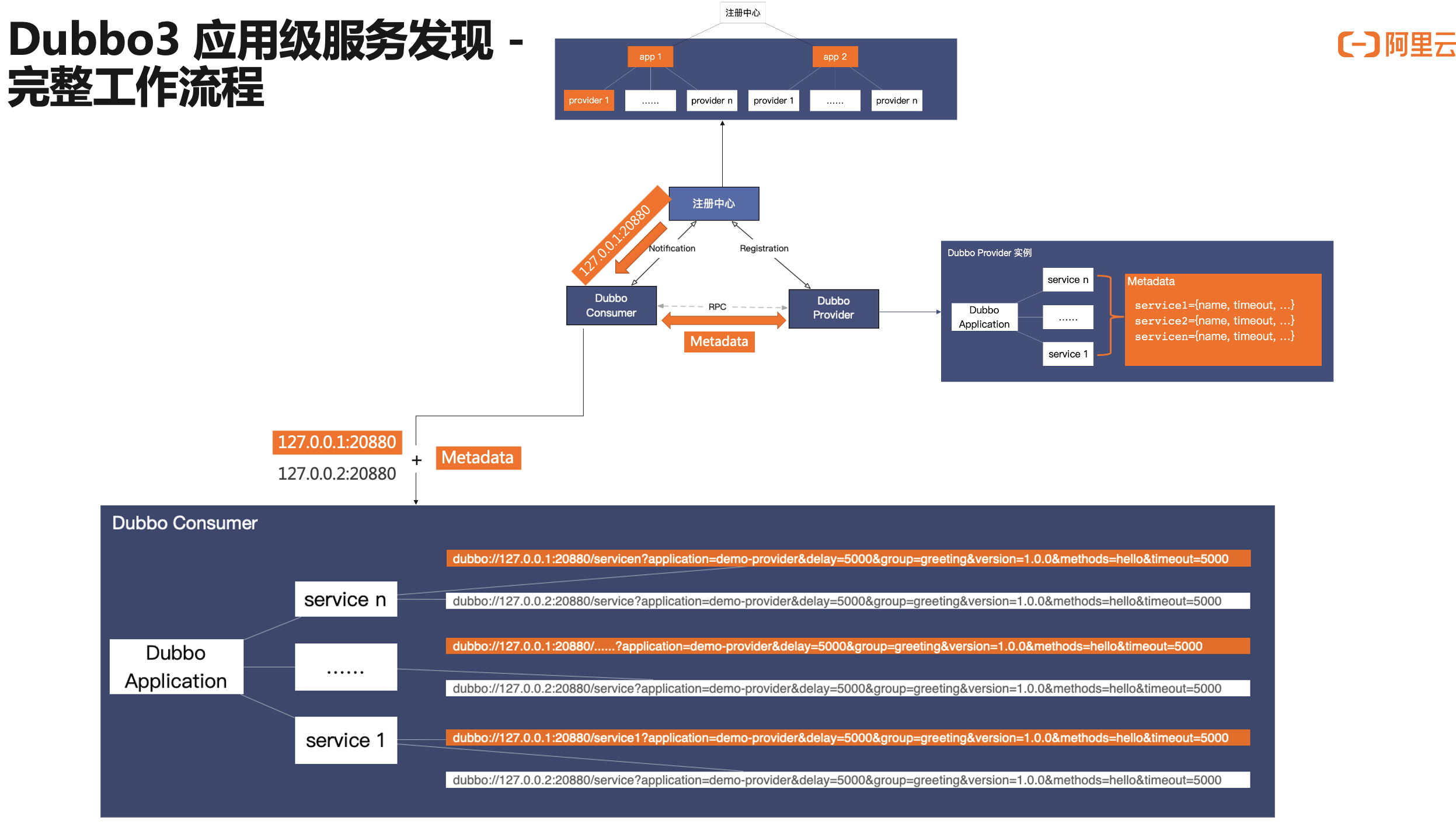
这里我们个重点看消费端 Consumer 的地址订阅行为,消费端从分两步读取地址数据,首先是从注册中心收到精简后的地址,随后通过调用 MetadataService 元数据服务,读取对端的元数据信息。在收到这两部分数据之后,消费端会完成地址数据的聚合,最终在运行态还原出类似 Dubbo2 的 URL 地址格式。因此从最终结果而言,应用级地址模型同时兼顾了地址传输层面的性能与运行层面的功能性。
以上就是的应用级服务发现背景、工作原理部分的所有内容,接下来我们看一下饿了么升级到 Dubbo3 尤其是应用级服务发现的过程。
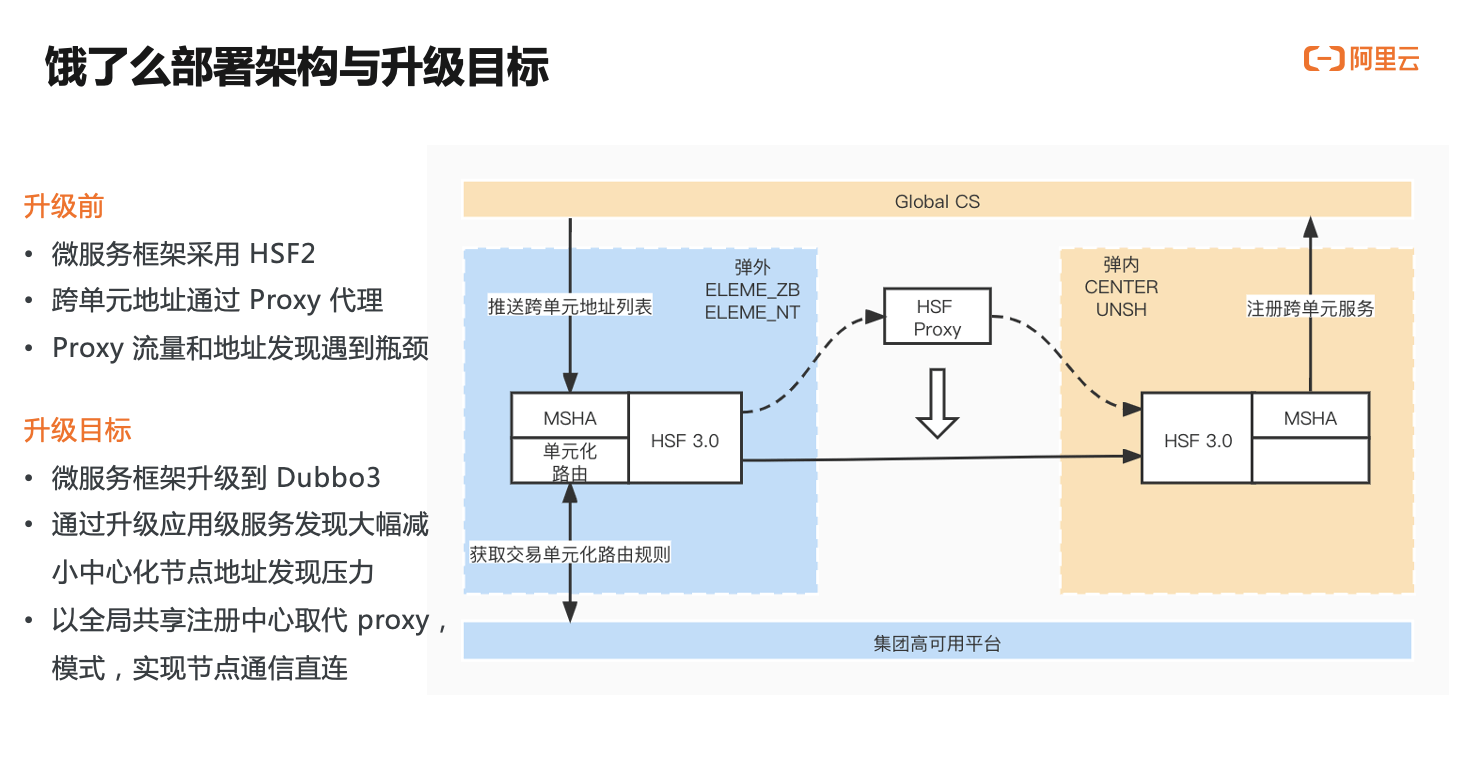
这里是饿了么的的基本部署架构图。在升级之前,饿了么的微服务框架采用的是 HSF2,跨单元的 RPC 调用是通过 proxy 中转代理,在这个过程中 proxy 所承载的机器数和流量迅速增长,比较突出的一点是 proxy 在订阅所有的地址数据后资源消耗和稳定性都收到严峻挑战。
通过全站升级 Dubbo3,业务线期望达到两个目标:
- 将地址模型切换到应用级服务发现大幅减轻中心化节点和消费端节点的资源消耗压力。
- 以应用级服务发现架构下的全局共享注册中心取代 proxy 模式,实现跨单元节点通信直连。
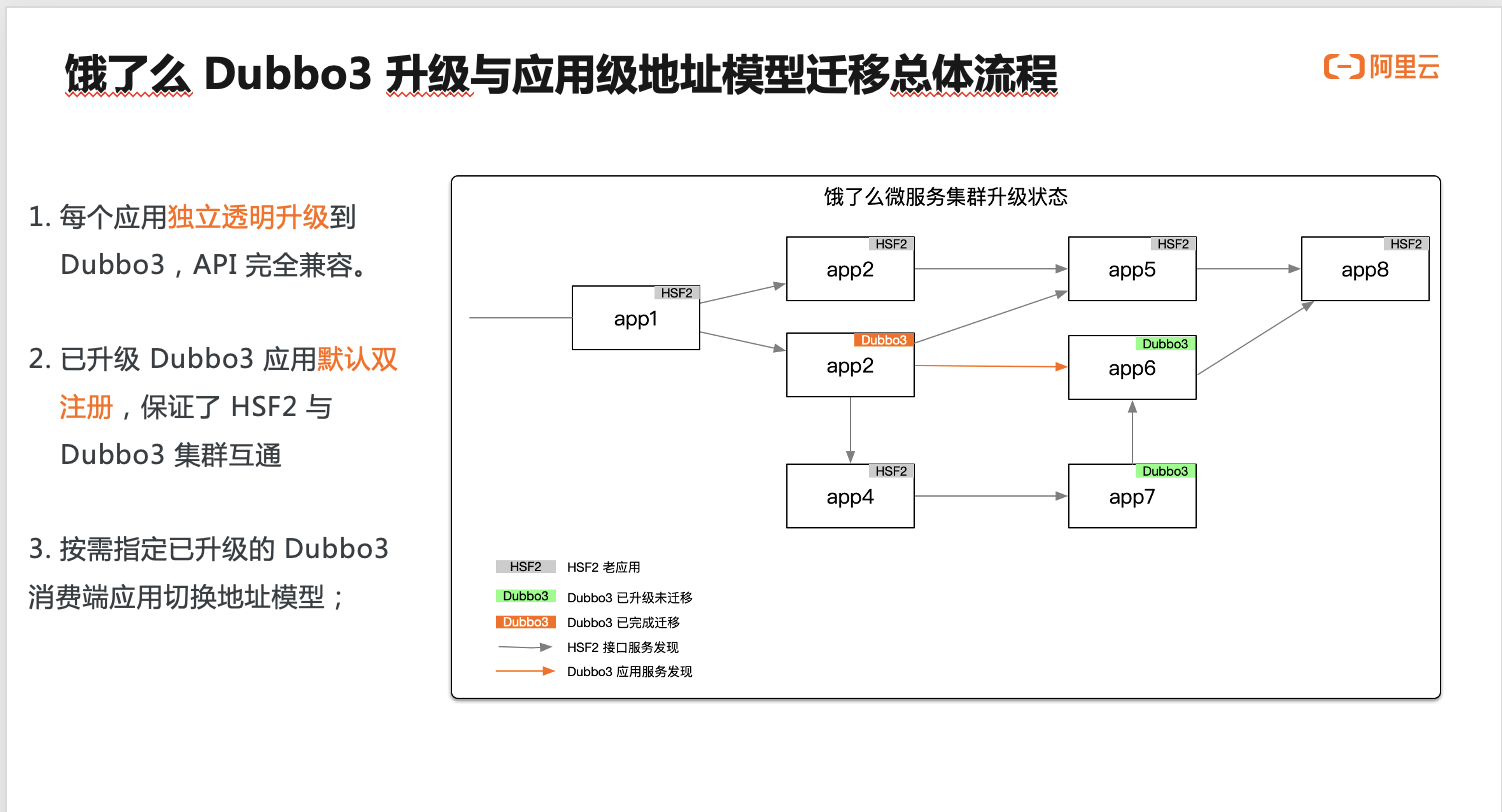
不论是针对 Dubbo2 还是 HSF2,我们都做了全面的 API 兼容,因此 Dubbo3 基本可以做到零改造升级,并且每个应用都是独立透明升级,不需要关心它的上下游应用的升级状态,因为 Dubbo3 升级之后不论是从地址发现模型还是协议的默认行为都保持与 2.0 版本兼容,用户可以在任意时间点对任意应用按需切换 Dubbo3 行为。
如右图所示,我们模拟展示了饿了么集群 Dubbo3 升级过程的一个中间状态,其中灰色标记的是老版本 HSF2 应用,橙色和绿色标记的是已经升级 Dubbo3 的应用,橙色部分的应用及其调用链路代表不但已经升级到 Dubbo3,同时也完成了 Dubbo3 行为的切换,在这里是指已经切换到了应用级地址模型。这里的升级过程主要为了说明 Dubbo3 框架升级的兼容性和独立性。
接下来,我们详细分析一下橙色部分节点往 Dubbo3 应用级发现迁移的具体过程

首先看 Provider 侧,服务提供者在升级 Dubbo3 后会默认保持双注册行为,即同时注册接口级地址和应用级地址到注册中心,一方面保持兼容,另一方面为未来消费端迁移做好准备。双注册的开关可通过 -Ddubbo.application.register-mode=al/interface/interface控制,我们推荐保持双注册的默认行为以减少后续迁移成本。
大家可能担心双注册给注册中心带来的存储压力,实际上在应用级服务发现模型下这并不是一个问题,因为大家如果回想前面我们对应用级服务发现工作原理的分析,注册地址已经被大幅精简,根据我们实际推算,每多注册一条应用级服务发现 URL 地址,只会增加 0.1% ~ 1% 的额外开销。
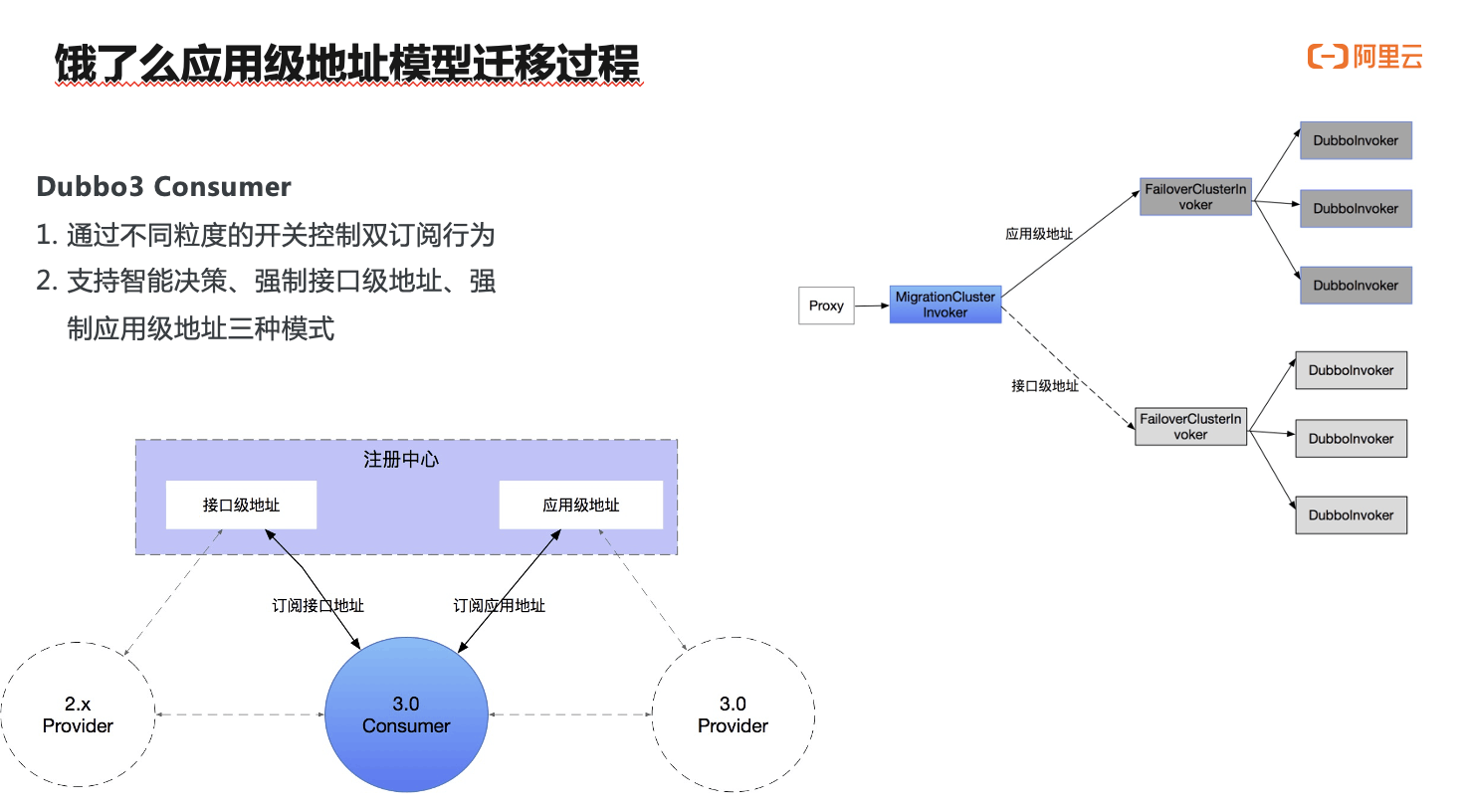
与提供端类似,要实现平滑迁移消费端也要经历双订阅的过程,流程上就不再赘述。消费端的双订阅行为也可通过规则或开关进行动态调整,控制消费端的消费的某个服务、应用迁移到应用级地址模型;除此之外,Dubbo3 还内置了自动决策机制,在发现应用级地址可用的情况下即会自动完成切换,并且这个行为是默认的。
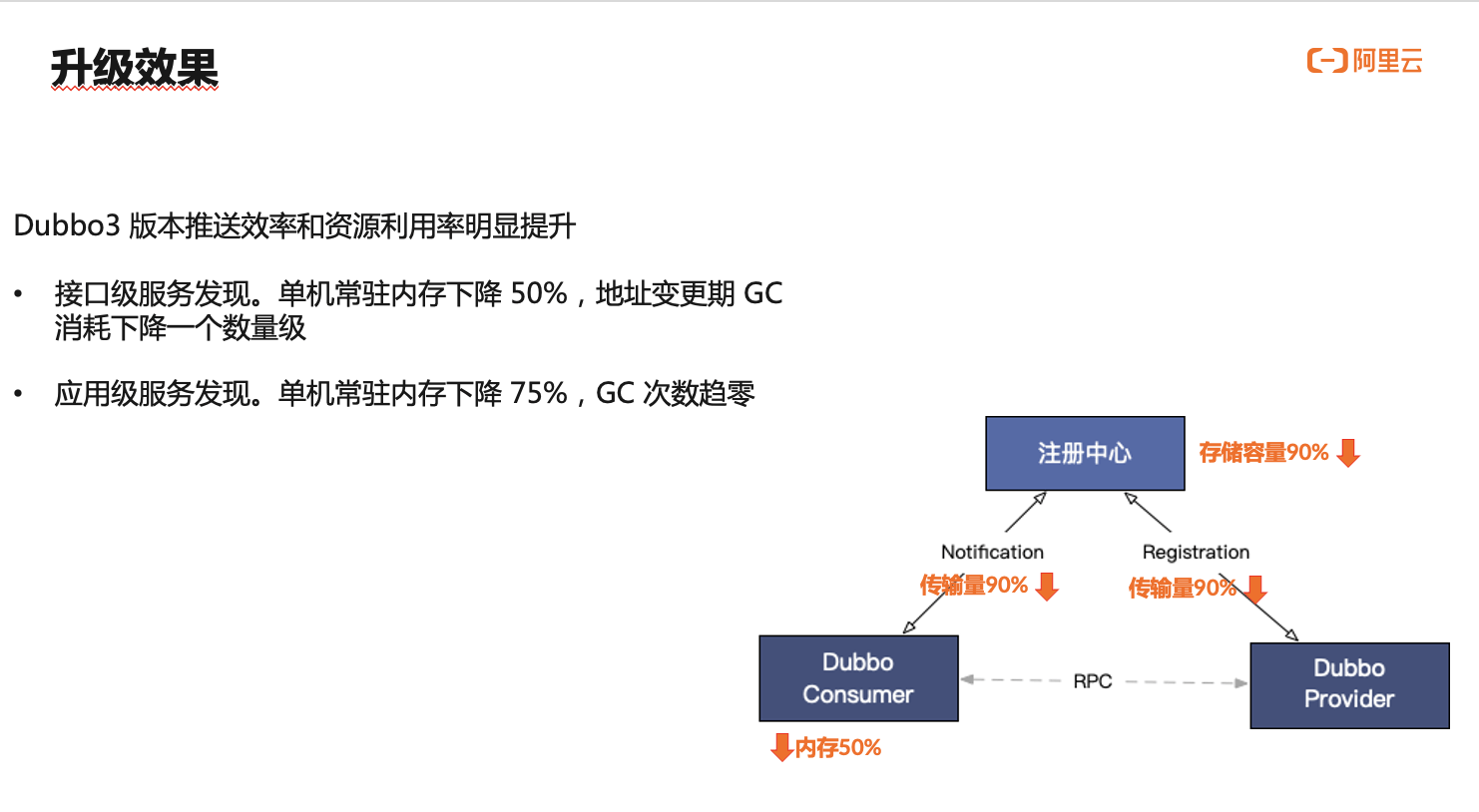
饿了么成功升级 Dubbo3 及应用级服务发现模型,实现了去 proxy 架构的目标,在我们关心的服务发现数据链路上:
- 数据注册与订阅的传输量下降 90%
- 注册中心数据存储的总体资源占用下降 90%
- 消费端服务框架自身的常驻内存消耗下降达 50%
集群总体的稳定性、性能都得到明显提升,也为未来容量扩展做好准备。
虽然饿了么的整体部署架构比较复杂,但我们对饿了么的 Dubbo3 升级过程的讲解还是非常简单直接的,因为服务发现的过程本身就是比较简单的,核心就是围绕提供者、消费者、注册中心三个节点的数据同步。其中重要的是三点,一个是对于应用级服务发现工作原理的整体讲解,第二点是 Dubbo3 的基本升级过程,Dubbo3 可以实现透明兼容升级,按需切换行为,第三点是 Dubbo3 在饿了么为代表的阿里巴巴内部真正意义上的实现了对 HSF2 的替换,除了个别 SPI 扩展实现了与开源版本保持了一致。
搜索关注官方微信公众号:Apache Dubbo,了解更多业界最新动态,掌握大厂面试必备 Dubbo 技能
架构解析:Dubbo3 应用级服务发现如何应对双11百万集群实例的更多相关文章
- 小白也能看懂的dubbo3应用级服务发现详解
搜索关注微信公众号"捉虫大师",后端技术分享,架构设计.性能优化.源码阅读.问题排查.踩坑实践. 本文已收录 https://github.com/lkxiaolou/lkxiao ...
- Dubbo 迈出云原生重要一步 - 应用级服务发现解析
作者 | 刘军(陆龟) Apache Dubbo PMC 概述 社区版本 Dubbo 从 2.7.5 版本开始,新引入了一种基于实例(应用)粒度的服务发现机制,这是我们为 Dubbo 适配云原生基础 ...
- dubbo 2.7应用级服务发现踩坑小记
本文已收录 https://github.com/lkxiaolou/lkxiaolou 欢迎star. 背景 本文记录最近一位读者反馈的dubbo 2.7.x中应用级服务发现的问题,关于dubbo应 ...
- 亿级Web系统搭建:单机到分布式集群
亿级Web系统搭建:单机到分布式集群 当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压 ...
- [转载] 关于“淘宝应对"双11"的技术架构分析”
微博上一篇最新的关于“淘宝应对"双11"的技术架构分析”.数据产品的一个最大特点是数据的非实时写入.
- Dubbo源码解析(一)服务发现
一.Dubbo源码模块 官网地址 源码地址 1.1 源码模块组织 Dubbo工程是一个Maven多Module的项目,以包结构来组织各个模块. 核心模块及其关系,如图所示: 1.2 模块说明 dubb ...
- .NET Core微服务之路:基于Consul最少集群实现服务的注册与发现(二)
重温Consul最少化集群的搭建
- [转]亿级Web系统搭建:单机到分布式集群
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
- 亿级 Web 系统搭建:单机到分布式集群
本文内容 Web 负载均衡 HTTP 重定向 反向代理 IP 负载均衡 DNS 负载均衡 Web 系统缓存机制的建立和优化 MySQL 数据库内部缓存 搭建多台 MySQL 数据库 MySQL 数据库 ...
- 亿级Web系统搭建:单机到分布式集群【转】
当一个Web系统从日访问量10万逐步增长到1000万,甚至超过1亿的过程中,Web系统承受的压力会越来越大,在这个过程中,我们会遇到很多的问题.为了解决这些性能压力带来问题,我们需要在Web系统架构层 ...
随机推荐
- Python——索引与切片
#索引与切片 ##1.序列 序列:list,tuple,str 其中list是可变序列 typle,str是不可变序列 #修改序列的值 list = [3,4,5] tup = (3,4,5) str ...
- 小程序uni-app发起网络异步请求
// uni.request({ // url: 'api/boxs/search', // // 使用监听函数防止this指向改变 // success: res => { // // 判断是 ...
- 洛谷P3376 (最大流模板)
1 #include<bits/stdc++.h> 2 #define int long long 3 using namespace std; 4 const int maxn=5005 ...
- 分布式存储系统之Ceph集群RBD基础使用
前文我们了解了Ceph集群cephx认证和授权相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16748149.html:今天我们来聊一聊ceph集群的 ...
- 基于SqlSugar的开发框架循序渐进介绍(15)-- 整合代码生成工具进行前端界面的生成
在前面随笔<基于SqlSugar的开发框架循序渐进介绍(12)-- 拆分页面模块内容为组件,实现分而治之的处理>中我们已经介绍过,对于相关的业务表的界面代码,我们已经尽可能把不同的业务逻辑 ...
- (数据科学学习手札144)使用管道操作符高效书写Python代码
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,一些比较熟悉pandas的读者 ...
- Linux中CentOS 7的安装及Linux常用命令
1. 前言 什么是Linux Linux是一套免费使用和自由传播的操作系统.说到操作系统,大家比较熟知的应该就是Windows和MacOS操作系统,我们今天所学习的Linux也是一款操作系统. 为什么 ...
- React + Springboot + Quartz,从0实现Excel报表自动化
一.项目背景 企业日常工作中需要制作大量的报表,比如商品的销量.销售额.库存详情.员工打卡信息.保险报销.办公用品采购.差旅报销.项目进度等等,都需要制作统计图表以更直观地查阅.但是报表的制作往往需要 ...
- linux 自动备份mysql数据库
今天一早打开服务器.13W个木马.被爆破成功2次,漏洞3个.数据库被删.这是个悲伤的经历 还好之前有备份,服务器也升级了安全机制,只是备份是上个月的备份.所以想写个脚本,试试自动备份数据库. 1. 先 ...
- etcd实现分布式锁
转载自:etcd实现分布式锁 当并发的访问共享资源的时候,如果没有加锁的话,无法保证共享资源安全性和正确性.这个时候就需要用到锁 1.需要具备的特性 需要保证互斥访问(分布式环境需要保证不同节点.不同 ...