flink-cdc同步mysql数据到kafka
本文首发于我的个人博客网站 等待下一个秋-Flink
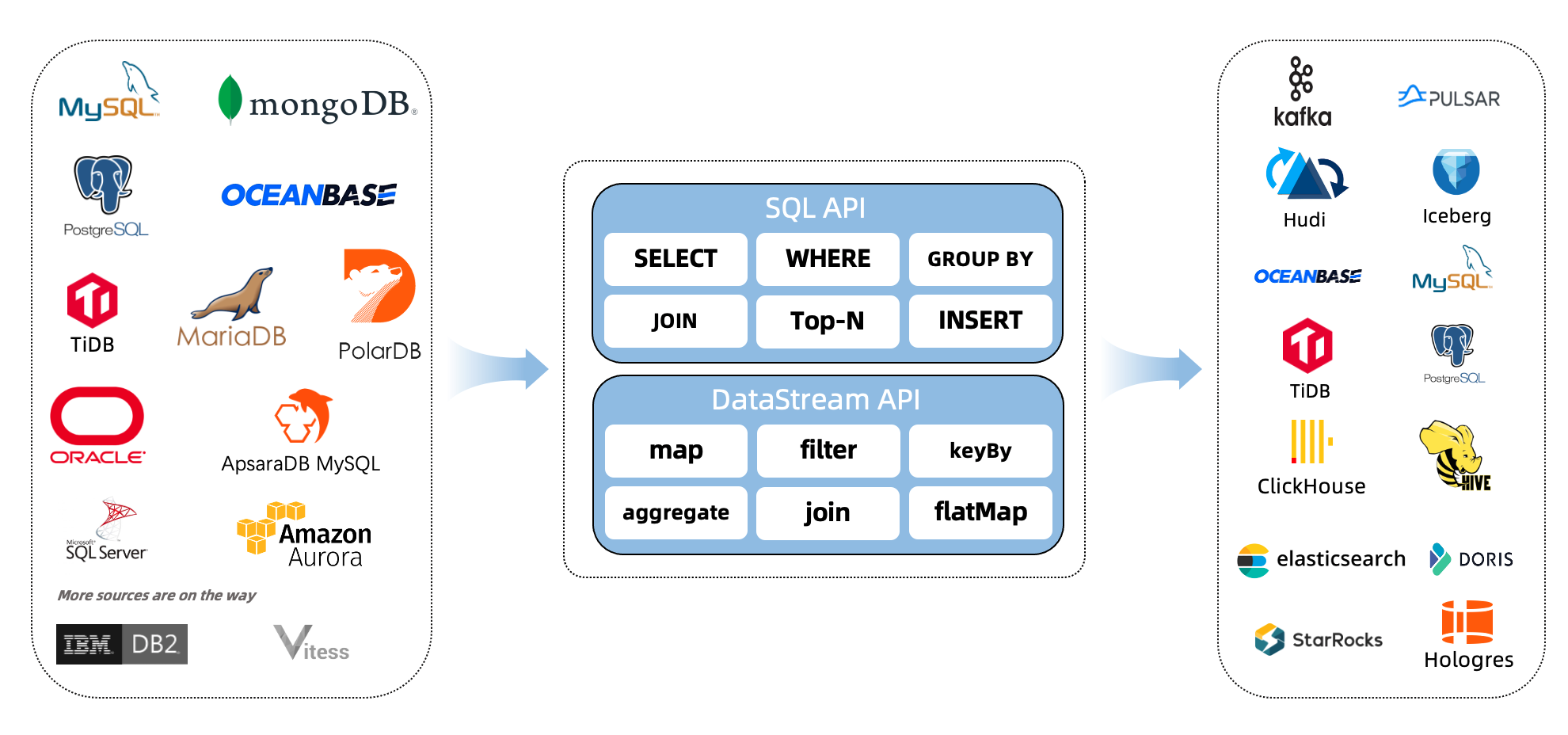
什么是CDC?
CDC是(Change Data Capture 变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的插入INSERT、更新UPDATE、删除DELETE等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
1. 环境准备
mysql
kafka 2.3
flink 1.13.5 on yarn
说明:如果没有安装hadoop,那么可以不用yarn,直接用flink standalone环境吧。
2. 下载下列依赖包
下面两个地址下载flink的依赖包,放在lib目录下面。
如果你的Flink是其它版本,可以来这里下载。
这里flink-sql-connector-mysql-cdc,前面一篇文章我用的mysq-cdc是1.4的,当时是可以的,但是今天我发现需要mysql-cdc-1.3.0了,否则,整合connector-kafka会有来冲突,目前mysql-cdc-1.3适用性更强,都可以兼容的。
如果你是更高版本的flink,可以自行https://github.com/ververica/flink-cdc-connectors下载新版mvn clean install -DskipTests 自己编译。
这是我编译的最新版2.2,传上去发现太新了,如果重新换个版本,我得去gitee下载源码,不然github速度太慢了,然后用IDEA编译打包,又得下载一堆依赖。我投降,我直接去网上下载了个1.3的直接用了。
我下载的jar包,放在flink的lib目录下面:
flink-sql-connector-kafka_2.11-1.13.5.jar
flink-sql-connector-mysql-cdc-1.3.0.jar
3. 启动flink-sql client
- 先在yarn上面启动一个application,进入flink13.5目录,执行:
bin/yarn-session.sh -d -s 1 -jm 1024 -tm 2048 -qu root.sparkstreaming -nm flink-cdc-kafka
- 进入flink sql命令行
bin/sql-client.sh embedded -s flink-cdc-kafka

4. 同步数据
这里有一张mysql表:
CREATE TABLE `product_view` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`product_id` int(11) NOT NULL,
`server_id` int(11) NOT NULL,
`duration` int(11) NOT NULL,
`times` varchar(11) NOT NULL,
`time` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `time` (`time`),
KEY `user_product` (`user_id`,`product_id`) USING BTREE,
KEY `times` (`times`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 样本数据
INSERT INTO `product_view` VALUES ('1', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('2', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('3', '1', '1', '3', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('4', '1', '1', '2', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('5', '8', '1', '1', '120', '120', '2020-05-14 13:14:00');
INSERT INTO `product_view` VALUES ('6', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');
INSERT INTO `product_view` VALUES ('7', '8', '1', '3', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('8', '8', '1', '3', '120', '120', '2020-04-23 13:14:00');
INSERT INTO `product_view` VALUES ('9', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');
- 创建数据表关联mysql
CREATE TABLE product_view_source (
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.1.2',
'port' = '3306',
'username' = 'bigdata',
'password' = 'bigdata',
'database-name' = 'test',
'table-name' = 'product_view'
);
这样,我们在flink sql client操作这个表相当于操作mysql里面的对应表。
- 创建数据表关联kafka
CREATE TABLE product_view_kafka_sink(
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'flink-cdc-kafka',
'properties.bootstrap.servers' = '192.168.1.2:9092',
'properties.group.id' = 'flink-cdc-kafka-group',
'key.format' = 'json',
'value.format' = 'json'
);
这样,kafka里面的flink-cdc-kafka这个主题会被自动创建,如果想指定一些属性,可以提前手动创建好主题,我们操作表product_view_kafka_sink,往里面插入数据,可以发现kafka中已经有数据了。
- 同步数据

建立同步任务,可以使用sql如下:
insert into product_view_kafka_sink select * from product_view_source;
这个时候是可以退出flink sql-client的,然后进入flink web-ui,可以看到mysql表数据已经同步到kafka中了,对mysql进行插入,kafka都是同步更新的。
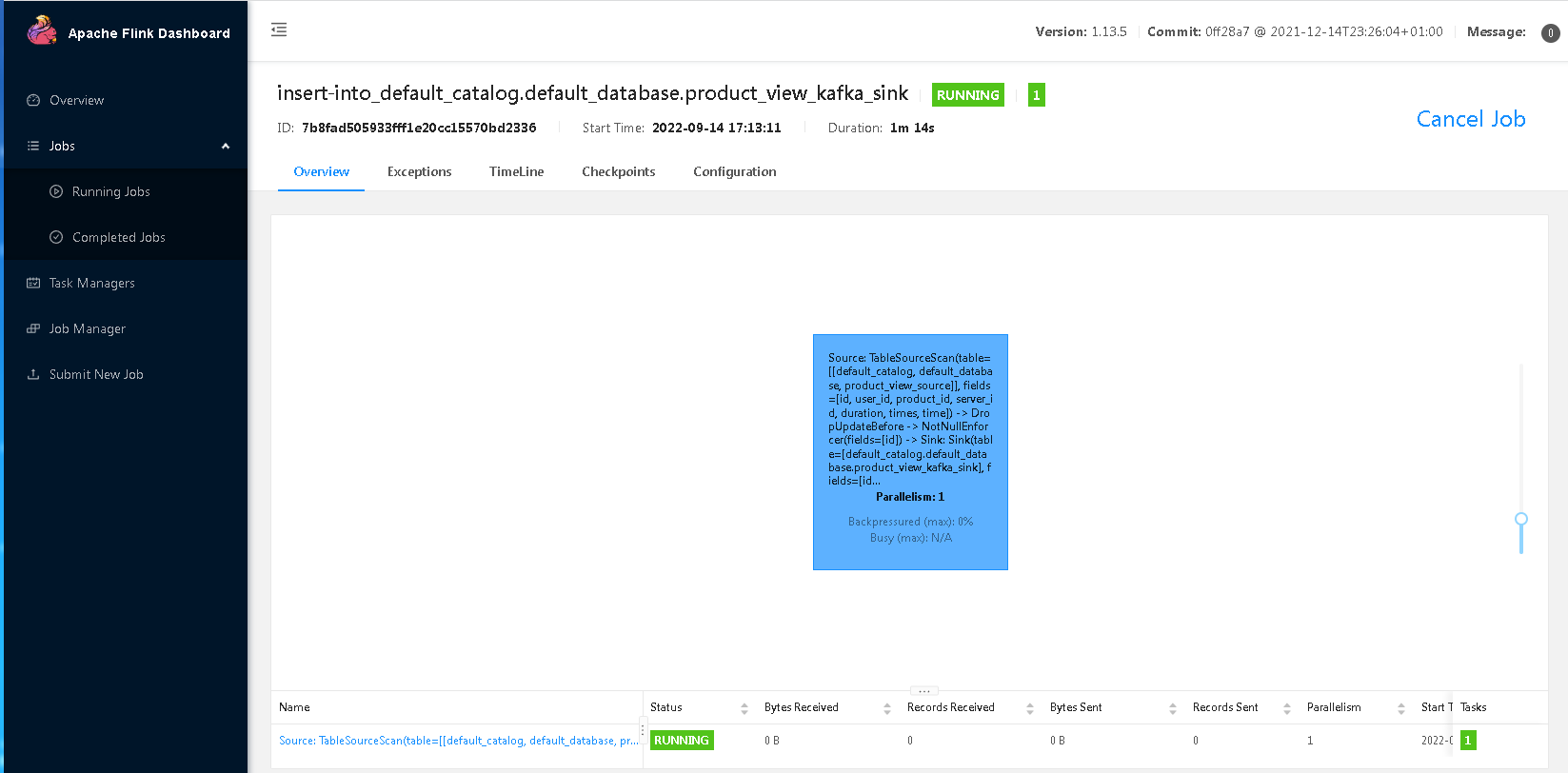
通过kafka控制台消费,可以看到数据已经从mysql同步到kafka了:

参考资料
https://ververica.github.io/flink-cdc-connectors/master/content/about.html
flink-cdc同步mysql数据到kafka的更多相关文章
- 使用maxwell实时同步mysql数据到kafka
一.软件环境: 操作系统:CentOS release 6.5 (Final) java版本: jdk1.8 zookeeper版本: zookeeper-3.4.11 kafka 版本: kafka ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- 使用Logstash来实时同步MySQL数据到ES
上篇讲到了ES和Head插件的环境搭建和配置,也简单模拟了数据作测试 本篇我们来实战从MYSQL里直接同步数据 一.首先下载和你的ES对应的logstash版本,本篇我们使用的都是6.1.1 下载后使 ...
- Logstash使用jdbc_input同步Mysql数据时遇到的空时间SQLException问题
今天在使用Logstash的jdbc_input插件同步Mysql数据时,本来应该能搜索出10条数据,结果在Elasticsearch中只看到了4条,终端中只给出了如下信息 [2017-08-25T1 ...
- 推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭. 例如:某记录内容为"aaa|bbb|ccc",将其按 ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- flume实时采集mysql数据到kafka中并输出
环境说明 centos7(运行于vbox虚拟机) flume1.9.0(flume-ng-sql-source插件版本1.5.3) jdk1.8 kafka(版本忘了后续更新) zookeeper(版 ...
- flink-cdc同步mysql数据到hive
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的 ...
- canal同步MySQL数据到ES6.X
背景: 最近一段时间公司做一个技术架构的更改,由于之前使用的solr和目前的业务不太匹配,具体原因不多说啦.所以要把数据放到Elasticsearch中进行快速的搜索,这是便产生了一个数据迁移的需求, ...
随机推荐
- java请求登录接口代码示例
前言 近期研究如何利用java代码如何获取其他系统中所需的数据,自己总结的方法如下: 1.工具类代码 /** * <pre> * 方法体说明:向远程接口发起请求,返回字符串类型结果 * @ ...
- NC17400 gpa
NC17400 gpa 题目 题目描述 Kanade selected n courses in the university. The academic credit of the i-th cou ...
- 问题:CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://mirrors.tuna.tsinghua.edu.cn/anaconda/pk
使用anaconda安装tensorflow (windows10环境) 遇到的问题:CondaHTTPError: HTTP 000 CONNECTION FAILED for url <ht ...
- labview从入门到出家8(进阶篇)--简单好用的状态机
labview的状态机类似于一个软件框架的基本单元,好的软件框架和软件思路采用一个好的状态机,就如虎添翼了.这章给大家讲一个本人常用的一个状态机,基本上以前的项目都是建立在这个状态机上完成的,当然网上 ...
- HashSet存储自定义类型元素和LinkedHashSet集合
HashSet集合存储自定义类型元素 HashSet存储自定义类型元素 set集合报错元素唯一: ~存储的元素(String,Integer,-Student,Person-)必须重写hashCode ...
- 如何用WebGPU流畅渲染百万级2D物体?
大家好~本文使用WebGPU和光线追踪算法,从0开始实现和逐步优化Demo,展示了从渲染500个2D物体都吃力到流畅渲染4百万个2D物体的优化过程和思路 目录 需求 成果 1.选择渲染的算法 2.实现 ...
- Go语言基础五:引用类型-切片和映射
切片 Go的数组长度不可以改变,在某些特定的场景中就不太适用了.对于这种情况Go语言提供了一种由数组建立的.更加灵活方便且功能强大的包装(Wapper),也就是切片.与数组相比切片的长度不是固定的,可 ...
- Lambda表达式无参数无返回值的练习和Lambda表达式有参数有返回值的练习
题目: 给定一个厨子Cook接口,内容唯一的抽象方法makeFood,且无参数.无返回值.如下: public interface Cook{ void makeFood(); } 在下面的代碼中,使 ...
- 从零开始Blazor Server(2)--整合数据库
开篇 上一篇文章我们留了个尾巴,没有把freesql整合进去,这篇文章我们来整合. 目前的思路呢,是做一个简单的四不像的RABC,也有用户.角色. 权限三部分. 但是其中每个用户只有一个角色,即用户和 ...
- mysql 经典案例
MySQL多表联合查询是MySQL数据库的一种查询方式,下面就为您介绍MySQL多表联合查询的语法,供您参考学习之用. MySQL多表联合查询语法: SELECT * FROM 插入表 LEFT JO ...