DHorse日志收集原理
实现原理
基于k8s的日志收集主要有两种方案,一是使用daemoset,另一种是基于sidecar。两种方式各有优缺点,目前DHorse是基于daemoset实现的。如图1所示:
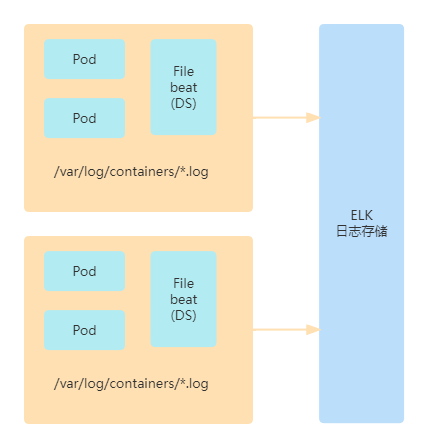
图1
在每个k8s集群中启动一个daemoset组件,即Filebeat的服务,监控/var/log/containers目录下的日志文件变动,然后把日志内容推送到ELK集群。
DHorse日志配置
在DHorse的安装目录conf子目录下,可以通过filebeat-k8s.yml文件进行日志收集的相关配置,如下:
---apiVersion: v1kind: ConfigMapmetadata:# 默认名称,不允许修改name: filebeat-config# 默认命名空间,不允许修改namespace: dhorse-systemlabels:# 默认标签名,不允许修改app: filebeatdata:filebeat.yml: |-filebeat.inputs:- type: containerpaths:- /var/log/containers/*.logprocessors:- add_kubernetes_metadata:host: ${NODE_NAME}matchers:- logs_path:logs_path: "/var/log/containers/"# To enable hints based autodiscover, remove `filebeat.inputs` configuration and uncomment this:#filebeat.autodiscover:# providers:# - type: kubernetes# node: ${NODE_NAME}# hints.enabled: true# hints.default_config:# type: container# paths:# - /var/log/containers/*${data.kubernetes.container.id}.logprocessors:- add_cloud_metadata:- add_host_metadata:cloud.id: ${ELASTIC_CLOUD_ID}cloud.auth: ${ELASTIC_CLOUD_AUTH}output.elasticsearch:hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']username: ${ELASTICSEARCH_USERNAME}password: ${ELASTICSEARCH_PASSWORD}---apiVersion: apps/v1kind: DaemonSetmetadata:# 默认名称,不允许修改name: filebeat# 默认命名空间,不允许修改namespace: dhorse-systemlabels:# 默认标签名,不允许修改app: filebeatspec:selector:matchLabels:# 默认标签名,不允许修改app: filebeattemplate:metadata:labels:# 默认标签名,不允许修改app: filebeatspec:terminationGracePeriodSeconds: 30hostNetwork: truednsPolicy: ClusterFirstWithHostNetcontainers:- name: filebeat# 替换成你自己的filebeat镜像image: docker.elastic.co/beats/filebeat:8.1.0args: ["-c", "/etc/filebeat.yml","-e",]#替换成你自己的es地址和账号env:- name: ELASTICSEARCH_HOSTvalue: 127.0.0.1- name: ELASTICSEARCH_PORTvalue: "9200"- name: ELASTICSEARCH_USERNAMEvalue: elastic- name: ELASTICSEARCH_PASSWORDvalue: changeme- name: ELASTIC_CLOUD_IDvalue:- name: ELASTIC_CLOUD_AUTHvalue:- name: NODE_NAMEvalueFrom:fieldRef:fieldPath: spec.nodeNamesecurityContext:runAsUser: 0# If using Red Hat OpenShift uncomment this:#privileged: trueresources:limits:memory: 200Mirequests:cpu: 100mmemory: 100MivolumeMounts:- name: configmountPath: /etc/filebeat.ymlreadOnly: truesubPath: filebeat.yml- name: datamountPath: /usr/share/filebeat/data- name: varlibdockercontainersmountPath: /var/lib/docker/containersreadOnly: true- name: varlogmountPath: /var/logreadOnly: true- name: hosttimemountPath: /etc/localtimereadOnly: truevolumes:- name: configconfigMap:defaultMode: 0640name: filebeat-config- name: varlibdockercontainershostPath:path: /var/lib/docker/containers- name: varloghostPath:path: /var/log- name: hosttimehostPath:path: /etc/localtime# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart- name: datahostPath:# When filebeat runs as non-root user, this directory needs to be writable by group (g+w).path: /var/lib/filebeat-datatype: DirectoryOrCreate
然后,需要开启目标集群的日志开关即可,如图2所示:
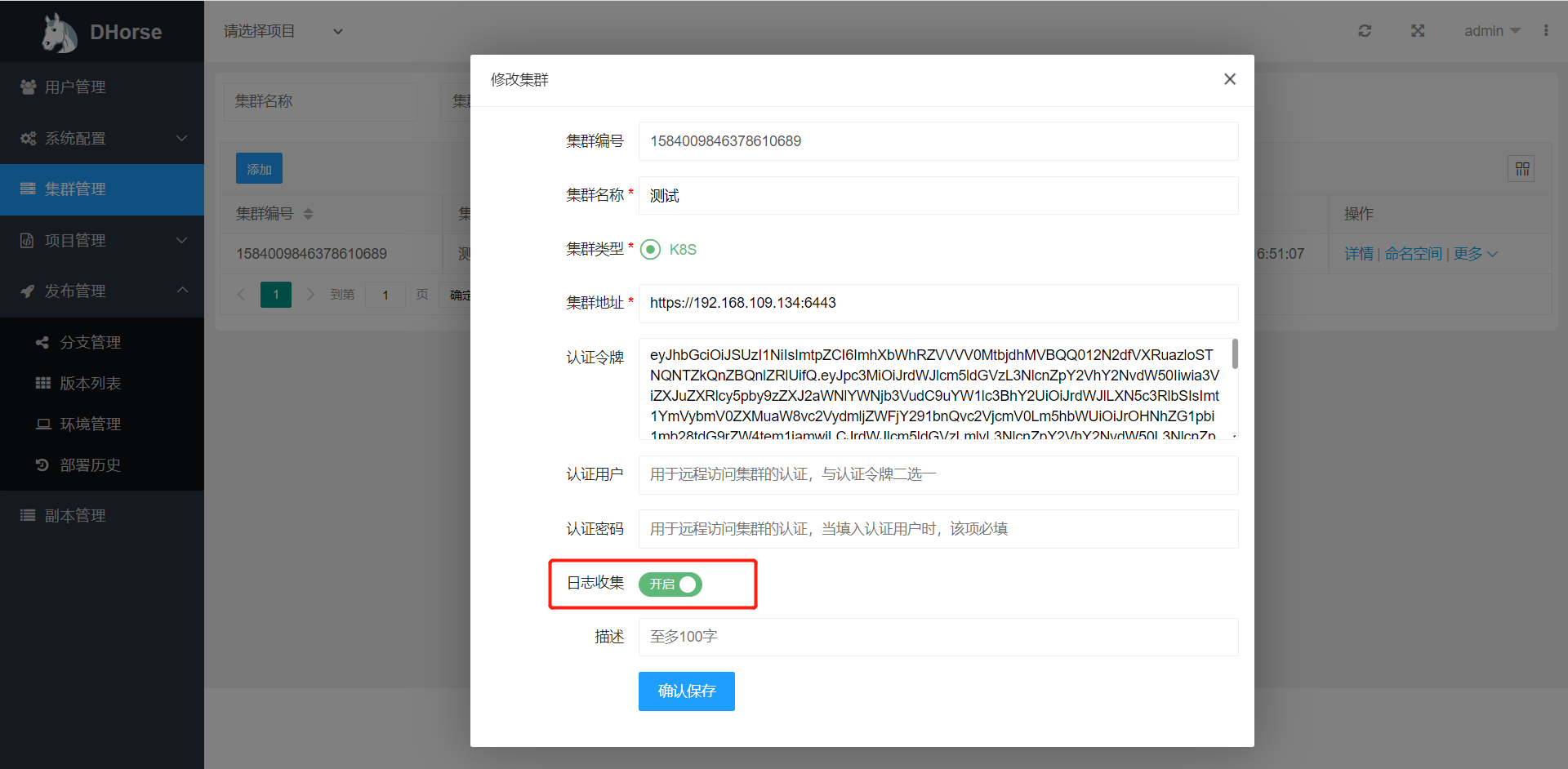
图2
DHorse日志收集原理的更多相关文章
- ELK分布式日志收集搭建和使用
大型系统分布式日志采集系统ELK全框架 SpringBootSecurity1.传统系统日志收集的问题2.Logstash操作工作原理3.分布式日志收集ELK原理4.Elasticsearch+Log ...
- 日志收集系统ELK搭建
一.ELK简介 在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常低下.因此我们需要集中化的管理 ...
- ELK 日志收集系统
传统系统日志收集的问题 在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常底下. 通常,日志被分 ...
- 网站统计中的数据收集原理及实现(share)
转载自:http://blog.codinglabs.org/articles/how-web-analytics-data-collection-system-work.html 网站数据统计分析工 ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 用fabric部署维护kle日志收集系统
最近搞了一个logstash kafka elasticsearch kibana 整合部署的日志收集系统.部署参考lagstash + elasticsearch + kibana 3 + kafk ...
- 日志收集之kafka
日志收集之kafka http://www.jianshu.com/p/f78b773ddde5 一.介绍 Kafka是一种分布式的,基于发布/订阅的消息系统.主要设计目标如下: 以时间复杂度为O(1 ...
- Docker日志收集最佳实践
传统日志处理 说到日志,我们以前处理日志的方式如下: · 日志写到本机磁盘上 · 通常仅用于排查线上问题,很少用于数据分析 ·需要时登录到机器上,用grep.awk等工具分析 那么,这种方式有什么缺点 ...
- G1收集器的收集原理
G1收集器的收集原理 来源 http://blog.jobbole.com/109170/ JVM 8 内存模型 原文:https://blog.csdn.net/bruce128/article/d ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
随机推荐
- 记录一个奇葩的问题:k8s集群中master节点上部署一个单节点的nacos,导致master节点状态不在线
情况详细描述; k8s集群,一台master,两台worker 在master节点上部署一个单节点的nacos,导致master节点状态不在线(不论是否修改nacos的默认端口号都会导致master节 ...
- 使用pip的方式安装docker-compose
# 国内开启pip 下载加速:http://mirrors.aliyun.com/help/pypi mkdir ~/.pip/ cat > ~/.pip/pip.conf <<'E ...
- MySQL学习(1)---MySQL概述
什么是数据库 概述 数据库(Database)是长期存储在计算机内有组织.大量.共享的数据集合.它可以供各种用户共享,具有最小冗余度和较高的数据独立性.数据库管理系统DBMS(Database Man ...
- NSIS查找文本中是否包含某个字串
!include "textfunc.nsh"!include "logiclib.nsh"OutFile "find.exe"#文本文件a ...
- Linux 下搭建 Hadoop 环境
Linux 下搭建 Hadoop 环境 作者:Grey 原文地址: 博客园:Linux 下搭建 Hadoop 环境 CSDN:Linux 下搭建 Hadoop 环境 环境要求 操作系统:CentOS ...
- 『现学现忘』Git分支 — 39、Git中分支与对象的关系
目录 1.Git对象之间的关系 2.提交对象与分支的关系 (1)提交对象与分支的关系 (2)分支说明 (3)HEAD与分支的关系 1.Git对象之间的关系 我们之前学了Git的三个对象:提交对象.树对 ...
- Windows 环境搭建 PostgreSQL 逻辑复制高可用架构数据库服务
本文主要介绍 Windows 环境下搭建 PostgreSQL 的主从逻辑复制,关于 PostgreSQl 的相关运维文章,网络上大多都是 Linux 环境下的操作,鲜有在 Windows 环境下配置 ...
- Nginx配置-1
1.绑定nginx到指定cpu [root@nginx conf.d]# vim /apps/nginx/conf/nginx.conf worker_processes 2; worker_cpu_ ...
- 研发效能|DevOps 已死平台工程永存带来的焦虑
最近某位大神在推特上发了一个帖子,结果引来了国内众多卖课机构.培训机构的狂欢,开始贩卖焦虑,其实「平台工程」也不是什么特别高深莫测的东西.闲得无聊,把这位大神的几个帖子薅了下来,你看过之后就会觉得没啥 ...
- ES 客户端 RestHighLevelClient Connection reset by peer 亲测有效 2022-11-05
导读 最新公司ES集群老出现连接关闭,进而导致查询|写入ES时报错,报错日志显示如下 [2m2022-10-23 14:13:10.088[0;39m - [31mERROR[0;39m - [35m ...