MySQL数据结构(索引)
一:MySQL索引与慢查询优化
1.什么是索引?
简单的理解为可以帮助你加快数据查询速度的工具
也可以把索引比喻成书的目录,它能让你更快的找到自己想要的内容
2.索引类型分类介绍
#===========B+树索引(等值查询与范围查询都快)
二叉树->平衡二叉树->B树->B+树
#===========HASH索引(等值查询快,范围查询慢)
将数据打散再去查询
#===========FULLTEXT:全文索引 (只可以用在MyISAM引擎)
通过关键字的匹配来进行查询,类似于like的模糊匹配
like + %在文本比较少时是合适的
但是对于大量的文本数据检索会非常的慢
全文索引在大量的数据面前能比like快得多,但是准确度很低
百度在搜索文章的时候使用的就是全文索引,但更有可能是ES
RTREE: R树索引
3.不同的存储引擎支持的索引类型也不一样
innDB存储引擎
支持事务,支持行级别锁定,支持 B-tree(默认)、Full-text 等索引,不支持 Hash 索引;
mylSAM存储引擎
不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
Memory存储引擎
不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
- 因为mysql默认的存储引擎是innodb,而innodb存储引擎的索引模型/结构是B+树,所以我们着重介绍B+树,那么大家最关注的问题来了:
B+树索引到底是如何加速查询的呢?
二:索引的数据结构
innodb存储引擎默认的索引结构为B+树,而B+树是由二叉树、平衡二叉树、B树再到B+树一路演变过来的
1.二叉树(每个节点只能分两个叉)
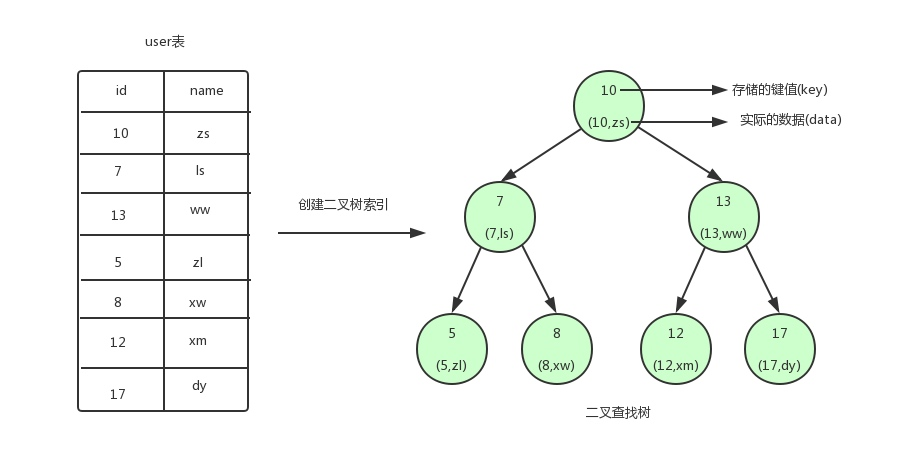
2.数据结构(B树)
b树 :精确查询 三次IO操作
案例:
select * from user where id=38
b树 :范围内查询 九次IO操作
案例:
select * from where id > 38 and id < 73;
总结b树:
b树查询的次数又b树的层次决定
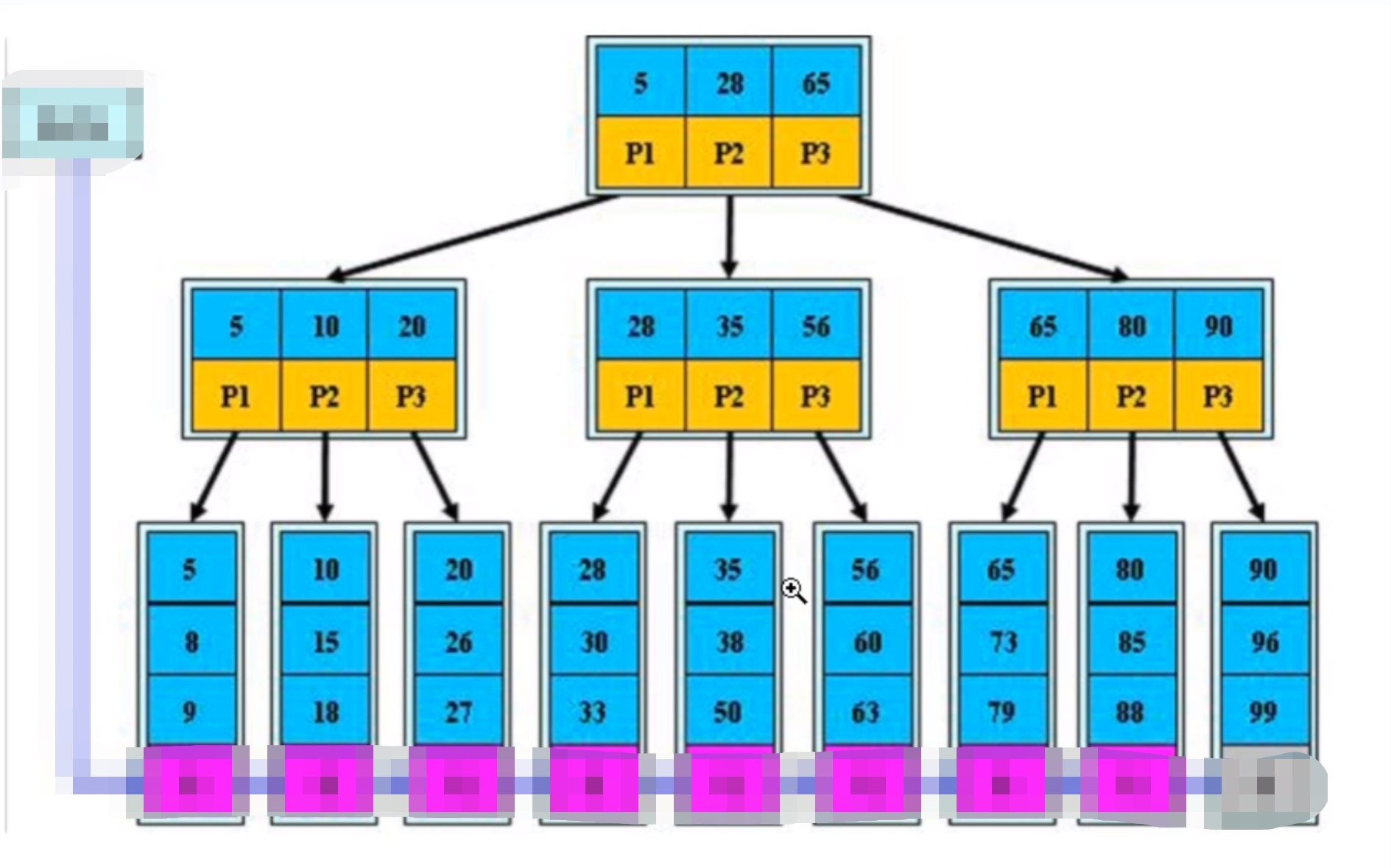
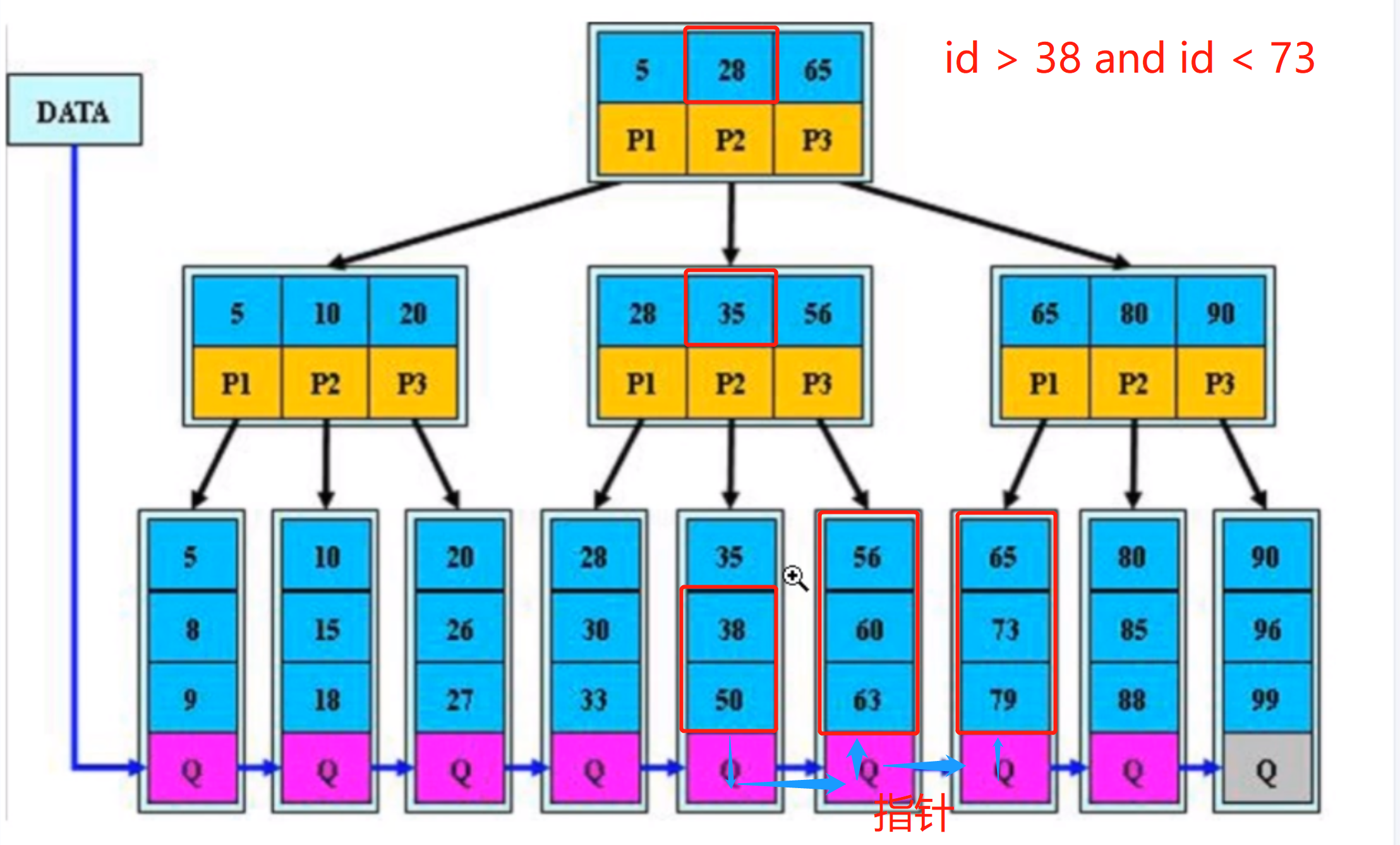
3.b+树 范围查询 五次IO操作(叶节点指针)
b+树 : 范围查询 五次IO操作(叶节点指针)
id > 38 and id < 73
指针分为两个部分:
pdata : 前面存数据
pnext : 存下面一个指针的位置
总结b+树:
b+树依靠指针比b树查询速度更快,也是MySQ目前L默认使用的索引
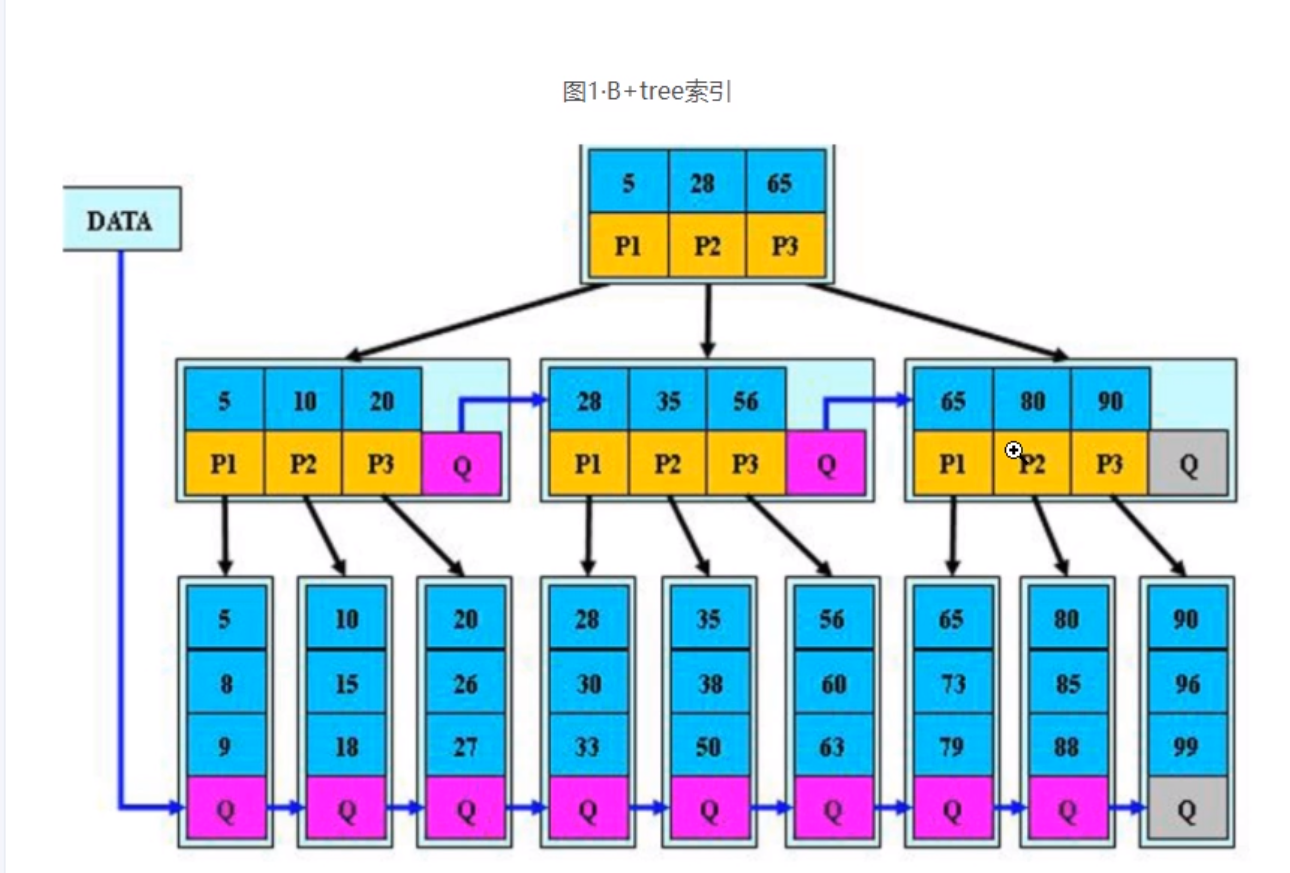
4.b*树(枝节点也添加了指针)
b*树(枝节点也添加了指针)
指针的作用:
添加指针是为了加快范围查询的速度
5.总结(索引)
索引的作用:
索引就是为了提供数据的查询速度
在计算机底层的表现形式就是一些数据结构(树)
数据结构:
二叉树 : 每个节点只能分两个叉
b树 : 枝节点和叶节点没有指针
b+树 : 叶节点添加指针
b*树 : 枝节点添加了指针(叶节点也有)
指针添加的作用:
指针的添加主要是为了解决范围查询的问题
精确查找取决于树的高度
索引的必要性:
将某个字段添加成索引就相当于依据该字段建立了一颗b+树从而加快查询速度
如果某个字段没有添加索引 那么依据该字段查询数据会非常的慢(一行行查找)
6.索引的分类
1.primary key
主键索引除了有加速查询的效果之外 还具有一定的约束条件
2.unique key
唯一键索引 除了有加速查询的效果之外 还具有一定的约束条件
3.index key
普通索引 只有加速查询的效果 没有额外约束
注意外键不是索引 它仅仅是用来创建表与表之间关系的
foreign key
三:操作索引
1.创建唯一索引需要提前排查是否有重复数据
select count(字段) from t1
select count(distinct(字段)) from t1
2.查看当前表内部索引值
show index from t1;

3.主键索引(指定索引)
alter table t1 add primary key pri_id(id); # 以id字段为索引
pri_id : 索引名<见名之意>
再次查看当前内部索引值
show index from t1\G;

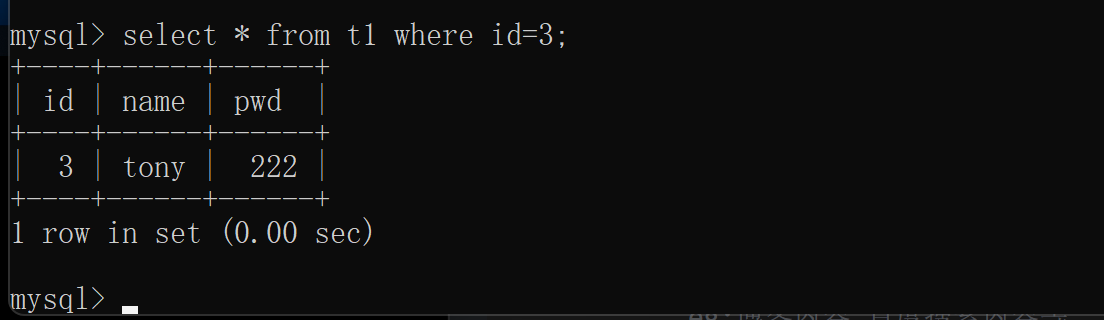
4.查询以id索引字段,此时加速查询(如果使用name字段查询,就还是一行一行查询)
select * from t1 where id=3
5.唯一索引
alter table t1 add unique key uni_pwd(pwd)
1.测试使用唯一索引

6.报错原因
使用唯一索引时,指定字段是唯一索引时,该字段如果有重复,使用唯一索引会报错。
四:解决字段重复
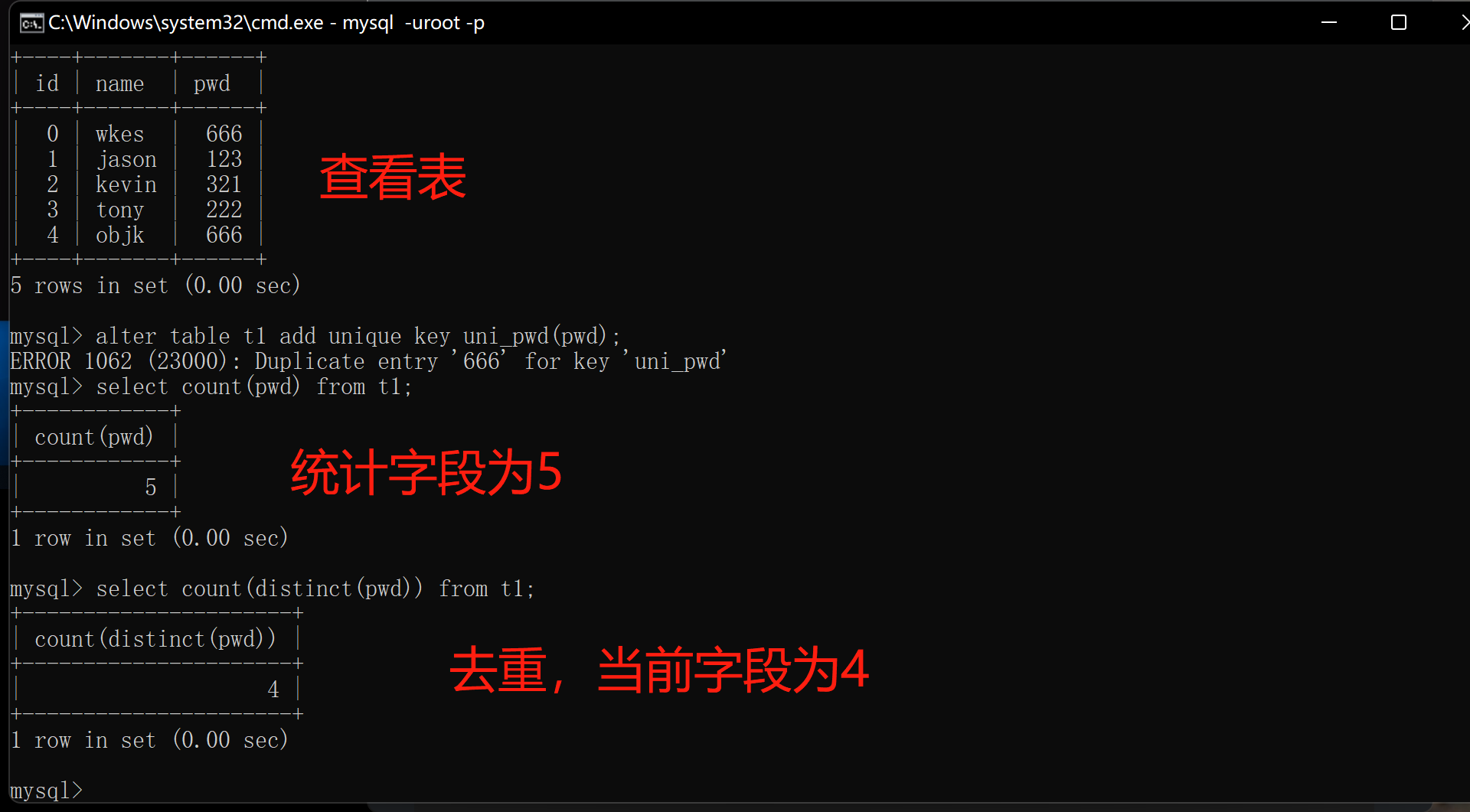
1.创建唯一索引需要提前排查是否有重复数据
1.统计当前字段个数
select count(pwd) from t1

2.去重pwd字段重复 排除重复数据(进行对比是否有重复数据)
select count(distinct(pwd)) from t1
3.删除重复数据
delete from t1 where id=4;
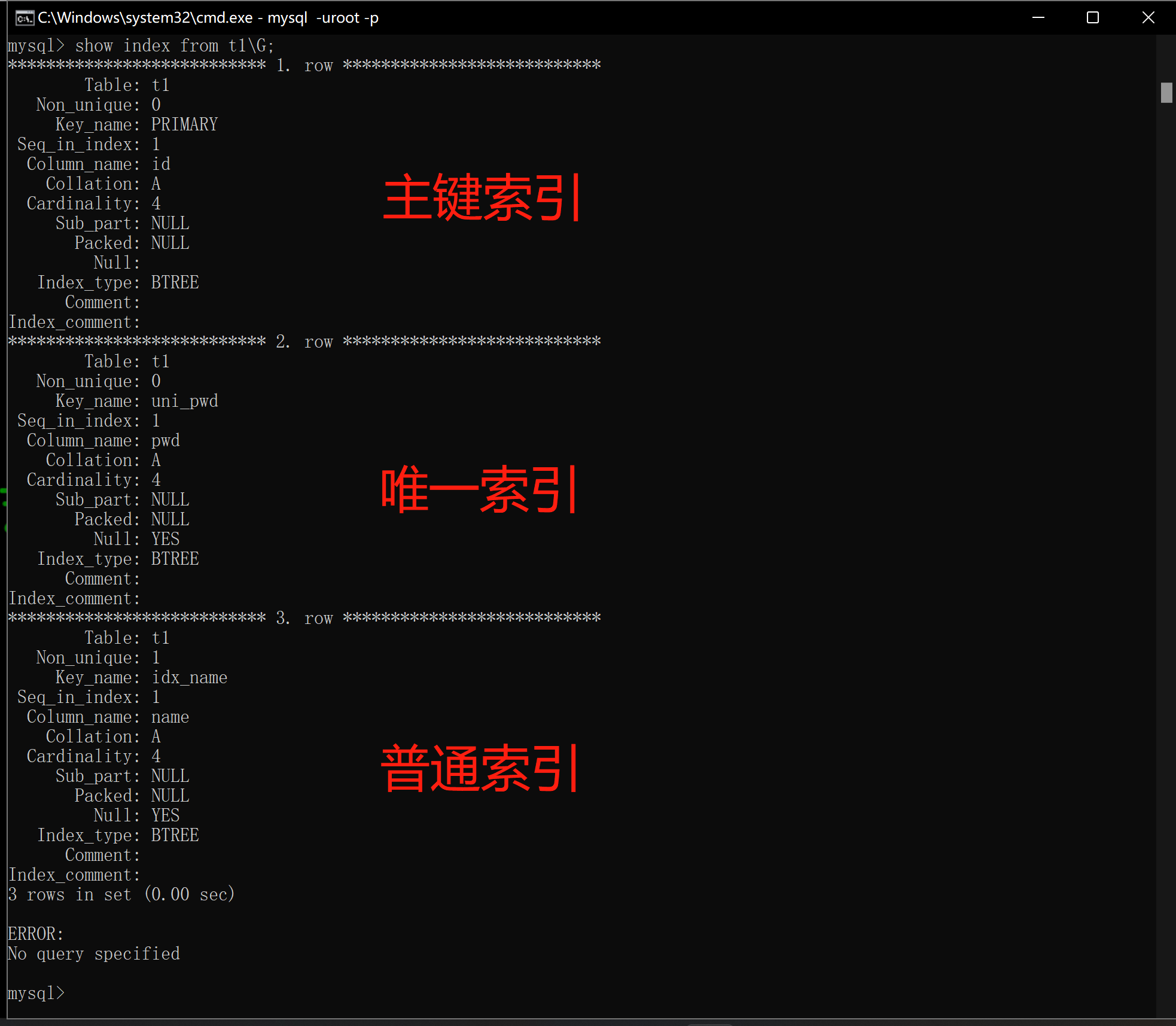
4.指定唯一索引(pwd字段索引)
alter table t1 add unique key uni_pwd(pwd);
5.查看当前所有索引
show index from t1\G;

6.普通索引(只能加速查询,没有其他约束条件)
alter table t1 add index idx_name(name)
7.删除索引
alter table 表名 drop index 索引名;
8.前缀索引(属于普通索引)
前缀索引的作用:
避免对大列建索引(数据很多情况),如果有就使用前缀索引
比如:
博客内容 百度搜索内容等
根据字段前N个字符建立索引
alter table t1 add index idx_name(name(10))
9.联合索引(属于普通索引)
联合索引作用:
相亲平台 搜索心仪对象的时候 《女,富婆,未婚,漂亮,1.69》
遵循:最左匹配原则
例:
where a.女生 and b.身高 and c.体重 and d.身材好
index(a.b.c)
特点: 前缀生效特性
a,ab,ac,abc,abcd 可以走索引或部分走索引
b bc bcd c d ba... 不走索引
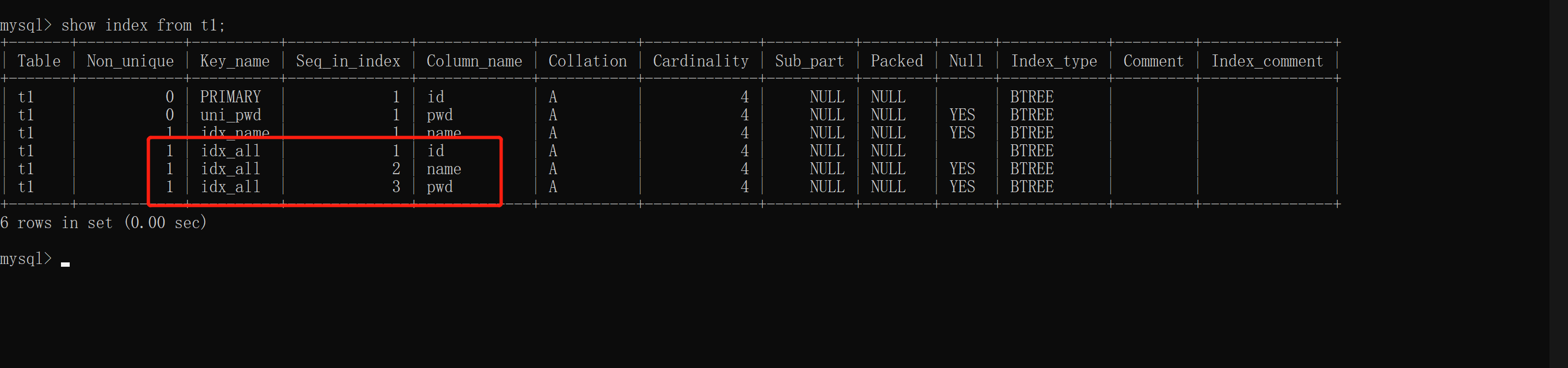
10.创建联合索引(前缀生效特性)
alter table t1 add index idx_all(id,name,pwd)
五:explain句式(全表扫描-索引扫描)
1.全表扫描与索引扫描区别
全表扫描(在explain语句结果中type为ALL)
不走索引 一行行查找数据 效率极低 生产环境下尽量不要书写类似SQL
索引扫描(const)
走索引 加快数据查询 建议书写该类型SQL
注意:
生成过程中,MySQL在使用全表扫描时的性能是极差的,所有MySQL尽量避免出现全表扫描。
explain就是帮助我们查看SQL语句属于那种扫描(全表扫描 还是 索引扫描)
2.explain命令使用格式:
explain select * from t1 where id=2;
3.使用explain验证全表扫描存在

4.使用explain验证索引扫描存在

5.什么时候出现全表扫描?
1.业务确实要获取所有数据
2.不走索引导致的全盘扫描
3.没索引
4.索引创建有问题
5.语句有问题
6.常见的索引扫描类型
1)index
2)range
3)ref
4)eq_ref
5)const
6)system
7)null
从上到下,性能从最差到最好,我们认为至少要达到range级别
7.索引扫描(内容解析)
index : index与ALL区别为index类型只遍历索引树
range : 索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行。显而易见的索引范围扫描是带有between或者where子句里带有<,>查询。<范围>
案例演示:
mysql> alter table city add index idx_city(population);
mysql> explain select * from city where population>30000000;
ref : 使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配某个单独值得记录 行。<精确>
案例演示:
mysql> alter table city drop key idx_code;
mysql> explain select * from city where countrycode='chn';
mysql> explain select * from city where countrycode in ('CHN','USA');
mysql> explain select * from city where countrycode='CHN' union all select * from city where countrycode='USA';
eq_ref : 类似ref,但不加前缀,区别就在使用得索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件A。
案例演示:
join B
on A.sid=B.sid
const,system : 当MySQL查询某部分进行优化,并转换为一个常量是,使用这些类型访问。
案例演示:
mysql> explain select * from city where id=1000;
NULL : MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
案例演示:
mysql> explain select * from city where id=1000000000000000000000000000;
8.在业务数据库中,特别是数据量比较大的表,是没有全表扫描这种需求。
1.对用户查看时非常痛苦的
2.对服务器来讲毁灭性的
3.SQL改写成以下语句:
| #情况1 | |
|---|---|
| #全表扫描 | |
| select * from table; | |
| #需要在price列上建立索引 | |
| selec * from tab order by price limit 10; | |
| #情况2 | |
| #name列没有索引 | |
| select * from table where name='zhangsan'; | |
| 1、换成有索引的列作为查询条件 | |
| 2、将name列建立索引 |
六:不走索引情况(起码记忆四条及以上)
1.没有查询条件,或者查询条件没有建立索引
全表扫描
select * from table;
select * from tab where 1=1;
2.查询结果集是原表中的大部分数据(25%以上)有可能不走索引
mysql> explain select * from city where population>3000 order by population;
1)如果业务允许,可以使用limit控制。
2)结合业务判断,有没有更好的方式。如果没有更好的改写方案就尽量不要在mysql存放这个数据了,放到redis里面。
3.索引本身失效,统计数据不真实
索引有自我维护的能力。
对于表内容变化比较频繁的情况下,有可能会出现索引失效。
重建索引就可以解决
4.查询条件使用函数在索引列上或者对索引列进行运算,运算包括(+,-,*等)
例子:
错误的例子: select * from test where id-1=9;
正确的例子: select * from test where id=10;
5.隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误
eg:字段是字符类型 查询使用整型
| mysql> create table test (id int ,name varchar(20),telnum varchar(10)); | |
|---|---|
| mysql> insert into test values(1,'zs','110'),(2,'l4',120),(3,'w5',119),(4,'z4',112); | |
| mysql> explain select * from test where telnum=120; | |
| mysql> alter table test add index idx_tel(telnum); | |
| mysql> explain select * from test where telnum=120; | |
| mysql> explain select * from test where telnum=120; | |
| mysql> explain select * from test where telnum='120'; |
测试隐式转换导致失效(类型转错成int类型)

纠正隐式转换导致的失败(传入正确的 字符串类型)

6.<> ,not in 不走索引
单独的>,<,in 有可能走,也有可能不走,和结果集有关,尽量结合业务添加limit、or或in尽量改成union
7.like "%_" 百分号在最前面不走
| #走range索引扫描 | |
|---|---|
| EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '31%'; | |
| #不走索引 | |
| EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '%110'; |
8.单独引用联合索引里非第一位置的索引列(最多匹配原则,第一个不满足,剩下的就不满足了)
| CREATE TABLE t1 (id INT,NAME VARCHAR(20),age INT ,sex ENUM('m','f'),money INT); | |
|---|---|
| ALTER TABLE t1 ADD INDEX t1_idx(money,age,sex); | |
| DESC t1 | |
| SHOW INDEX FROM t1 | |
| #走索引的情况测试 | |
| EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30 AND sex='m'; | |
| #部分走索引 | |
| EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30; | |
| EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND sex='m'; | |
| #不走索引 | |
| EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=20 | |
| EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=30 AND sex='m'; | |
| EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE sex='m'; |
索引的创建会加快数据的查询速度 但是一定程度会拖慢数据的插入和删除速度。
MySQL数据结构(索引)的更多相关文章
- mysql 松散索引与紧凑索引扫描(引入数据结构)
这一篇文章本来应该是放在 mysql 高性能日记中的,并且其优化程度并不高,但考虑到其特殊性和原理(索引结构也在这里稍微讲一下) 一,mysql 索引结构 (B.B+树) 要问到 mysql 的索引用 ...
- MySQL存储索引InnoDB数据结构为什么使用B+树,而不是其他树呢?
InnoDB的一棵B+树可以存放多少行数据? 答案:约2千万 为什么是这么多? 因为这是可以算出来的,要搞清楚这个问题,先从InnoDB索引数据结构.数据组织方式说起. 计算机在存储数据的时候,有最小 ...
- 浅谈MYSQL的索引以及它的数据结构
什么是索引 mysql的数据是持久化到磁盘的,写SQL查询数据也就是在磁盘的某个位置查找符合条件的数据,但是磁盘IO比起内存效率是极慢的,特别是数据量大的时候,这时候就需要引入索引来提高查询效率: 在 ...
- 视图 触发器 事务 MVCC 存储过程 MySQL函数 MySQL流程控制 索引的数据结构 索引失效 慢查询优化explain 数据库设计三范式
目录 视图 create view ... as 触发器 简介 创建触发器的语法 create trigger 触发器命名有一定的规律 临时修改SQL语句的结束符 delimiter 触发器的实际运用 ...
- 【夯实Mysql基础】MySQL性能优化的21个最佳实践 和 mysql使用索引
本文地址 分享提纲: 1.为查询缓存优化你的查询 2. EXPLAIN 你的 SELECT 查询 3. 当只要一行数据时使用 LIMIT 1 4. 为搜索字段建索引 5. 在Join表的时候使用相当类 ...
- MySQL中索引和优化的用法总结
1.什么是数据库中的索引?索引有什么作用? 引入索引的目的是为了加快查询速度.如果数据量很大,大的查询要从硬盘加载数据到内存当中. 2.InnoDB中的索引原理是怎么样的? InnoDB是Mysql的 ...
- 小白学习mysql之索引初步
导语 索引在数据库中的地位是及其的重要,同时要想完全的掌握索引并不是一件容易的事,需要对数据的查询原理以及计算机操作系统有深刻的认识,当然相关的算法和数据结构也是必须的.因此,这篇文章感到了一些压力, ...
- MySQL使用索引的场景及真正利用索引的SQL类型
1. 为什么使用索引 在无索引的情况下,MySQL会扫描整张表来查找符合sql条件的记录,其时间开销与表中数据量呈正相关.对关系型数据表中的某些字段建索引可以极大提高查询速度(当然,不同字段是否sel ...
- MySQL的索引
MySQL索引 索引:是一种特殊的文件(InnoDB 数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针.其可以加快数据读操作,但会使数据写操作变慢:应该构建在被用作查询条 ...
随机推荐
- ELasticsearch忘记密码后重置超级用户密码
创建一个临时的超级用户TestSuper: [root@cfeea elasticsearch]# ./bin/elasticsearch-users useradd TestSuper -r sup ...
- ElastAlert监控日志告警Web攻击行为---tomcat和nginx日志json格式
一.ELK安装 1.2 elk配置 logstash自定义配置文件,取名为filebeat_log.conf : input { beats { port => 5044 client_inac ...
- SQL的事务
一.基本概念 事务是数据库区别于文件系统的重要特性之一,当有了事务,就可以让数据库始终保持一致性,同时可以通过事务的机制恢复到某个时间点,保证了提交到数据库的修改不会因为系统崩溃而丢失: 事务只是一个 ...
- 如何通过 Java 代码隐藏 Word 文档中的指定段落
在编辑Word文档时,我们有时需要将一些重要信息保密. 因此,可以隐藏它们以确保机密性. 在本文中,将向您介绍如何通过 Java 程序中的代码隐藏 Word 文档中的特定段落.下面是我整理的具体步骤, ...
- 绝杀processOn,这款UML画图神器,阿里字节都用疯了,你还不知道?
大家好,我是陶朱公Boy,又和大家见面了. 前言 在文章开始前,想先问大家一个问题,大家平时在项目需求评审完后,是直接开始编码了呢?还是会先写详细设计文档,后再开始进行编码开发? ☆现实 这个时候可能 ...
- 9.channels layers
settings.py配置 # 存储在内存里 CHANNEL_LAYERS = { "default": { "BACKEND": "channels ...
- 基于docker和cri-dockerd部署kubernetes v1.25.3
基于docker和cri-dockerd部署kubernetes v1.25.3 1.环境准备 1-1.主机清单 主机名 IP地址 系统版本 k8s-master01 k8s-master01.wan ...
- Codeforces Round #805 (Div. 3)G2. Passable Paths
题目大意: 给出一个无向无环连通图(树),n个点n-1条边,m次查询,每次询问给出一个集合,问集合里的树是否都在同一条链上(即能否不重复的走一条边而遍历整个点集) 思路:通过求lca,若有三个点x,y ...
- NC-日志配置及代码详解
目录 一.日志文件输出说明 二.日志配置说明 2.1 配置文件路径 2.2 配置格式 2.2.1 参数说明 三.代码说明 四.自定义日志实例 实例1-新建日志类 实例2-直接在代码中使用日志输出 五. ...
- TensorFlow深度学习!构建神经网络预测股票价格!⛵
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 TensorFlow 实战系列:https://www.showmeai ...