4.3:flume+Kafka日志采集实验
〇、目标
使用kafka和flume组合进行日志采集
拓扑结构

一、重启SSH和zk服务
打开终端,首先输入:sudo service ssh restart

重启ssh服务。之后输入下述命令开启zookeeper服务:
zkServer.sh start

二、启动flume
输入cd /home/user/bigdata/apache-flume-1.9.0-bin
进入flume目录后输入
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties --name agent1
启动flume
三、启动kafka
打开一个终端,先配置hosts再进入到kafka目录,输入:
echo "127.0.0.1 "$HOSTNAME | sudo tee -a /etc/hosts
进入kafka目录,输入
cd /home/user/bigdata/kafka_2.11-1.0.0
nohup bin/kafka-server-start.sh config/server.properties >~/bigdata/kafka_2.11-1.0.0/logs/server.log 2>&1 &
后台启动kafka。输入jps查看进程:jps
输入:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic1
创建topic

输入bin/kafka-topics.sh --list --zookeeper localhost:2181
查看已经创建好的topic

输入bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic1
打开kafka的comsumer消费发来的信息。

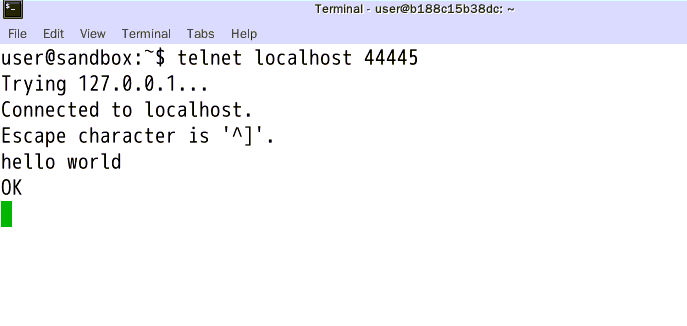
再打开第三个终端,输入:telnet localhost 44445
之后进行任意输入,会发现kafka的终端中出现了你输入的话。

4.3:flume+Kafka日志采集实验的更多相关文章
- Flume - Kafka日志平台整合
1. Flume介绍 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供 ...
- kafka+flume+HDFS日志采集项目框架
1,项目图如下: 2, 实现过程 启动HDFS: sbin/start-dfs.sh 启动zookeeper(三台): bin/zkServer.sh start 启动kafka(三台): root@ ...
- 大数据软件安装之Flume(日志采集)
一.安装地址 1) Flume官网地址 http://flume.apache.org/ 2)文档查看地址 http://flume.apache.org/FlumeUserGuide.html 3) ...
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
- 一次flume exec source采集日志到kafka因为单条日志数据非常大同步失败的踩坑带来的思考
本次遇到的问题描述,日志采集同步时,当单条日志(日志文件中一行日志)超过2M大小,数据无法采集同步到kafka,分析后,共踩到如下几个坑.1.flume采集时,通过shell+EXEC(tail -F ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- 日志采集框架Flume
前言 在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集.结果数据导出.任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中 ...
- 日志采集框架 Flume
日志采集框架 Flume 1 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到H ...
- 基于Flume+Kafka+ Elasticsearch+Storm的海量日志实时分析平台(转)
0背景介绍 随着机器个数的增加.各种服务.各种组件的扩容.开发人员的递增,日志的运维问题是日渐尖锐.通常,日志都是存储在服务运行的本地机器上,使用脚本来管理,一般非压缩日志保留最近三天,压缩保留最近1 ...
- Flume日志采集框架的使用
文章作者:foochane 原文链接:https://foochane.cn/article/2019062701.html Flume日志采集框架 安装和部署 Flume运行机制 采集静态文件到h ...
随机推荐
- Django django-admin.py 命令详解
一.Django 基本命令 下载 Django pip3 install django # 默认下载最新版 pip3 install django==4.1 # 手动选择版本 创建Djang ...
- Redis可视化工具(支持ssh链接)
1.Redis Desktop Manager RedisDesktopManager,简称RDM,这是一款很出名的Redis可视化管理工具,支持Windows,Mac,Ipad,LInux 开源地址 ...
- Elasticsearch基础但非常有用的功能之二:模板
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484584&idx=1&sn=accfb65 ...
- Jetbrains家的软件都可用的激活码-pycharm
网址:http://vrg123.com/ 步骤: 1,关注下方的公众号 2,点击菜单中的"激活密钥" 3,点击进入,获得网站密钥 4,在网站上输入网站密钥,点击获取,即可获取激活 ...
- Windows上Navicat工具远程连接PostgreSQL数据库
首先,在pgdata(也就是在安装pg时指定的存放数据的文件见中)文件夹中,找到pg_hba.conf文件,在文件最后写入下面的内容: host all all 0.0.0.0/0 trust 接着, ...
- 打印 Logger 日志时,需不需要再封装一下工具类?
在开发过程中,打印日志是必不可少的,因为日志关乎于应用的问题排查.应用监控等.现在打印日志一般都是使用 slf4j,因为使用日志门面,有助于打印方式统一,即使后面更换日志框架,也非常方便.在 < ...
- 我的Vue之旅、05 导航栏、登录、注册 (Mobile)
第一期 · 使用 Vue 3.1 + TypeScript + Router + Tailwind.css 构建手机底部导航栏.仿B站的登录.注册页面. 代码仓库 alicepolice/Vue-05 ...
- python-数据描述与分析2(利用Pandas处理数据 缺失值的处理 数据库的使用)
2.利用Pandas处理数据2.1 汇总计算当我们知道如何加载数据后,接下来就是如何处理数据,虽然之前的赋值计算也是一种计算,但是如果Pandas的作用就停留在此,那我们也许只是看到了它的冰山一角,它 ...
- 驱动开发:内核枚举IoTimer定时器
今天继续分享内核枚举系列知识,这次我们来学习如何通过代码的方式枚举内核IoTimer定时器,内核定时器其实就是在内核中实现的时钟,该定时器的枚举非常简单,因为在IoInitializeTimer初始化 ...
- aws上传文件、删除文件、图像识别
目录 aws的上传.删除s3文件以及图像识别文字功能 准备工作 安装aws cli 初始化配置AWS CLI s3存储桶开通 图像识别文字功能开通 aws的sdk 上传文件 方法一 方法二 删除文件 ...