golang中的字符串
0.1、索引
https://waterflow.link/articles/1666449874974
1、字符串编码
在go中rune是一个unicode编码点。
我们都知道UTF-8将字符编码为1-4个字节,比如我们常用的汉字,UTF-8编码为3个字节。所以rune也是int32的别名。
type rune = int32
当我们打印一个英文字符hello的时候,我们可以得到s的长度为5,因为英文字母代表1个字节:
package main
import "fmt"
func main() {
s := "hello"
fmt.Println(len(s)) // 5
}
但是当我们打印嗨的时候,会打印3个字节。因为使用UTF-8,这个字符会被编码成3个字节:
package main
import "fmt"
func main() {
s := "嗨"
fmt.Println(len(s)) // 3
}
所以,我们使用len内置函数输出的并不是字符数,而是字节数。
下面看一个有趣的例子,我们都知道汉字符使用3个字节编码,分别是0xE5, 0x97, 0xA8。我们运行下面代码会得到汉字嗨:
package main
import "fmt"
func main() {
s := string([]byte{0xE5, 0x97, 0xA8})
fmt.Println(s) // 嗨
}
所以我们需要知道:
- 字符集是一组字符,而编码描述了如何将字符集转换为二进制
- 在 Go 中,字符串引用任意字节的不可变切片
- Go 源码使用 UTF-8 编码。 因此,所有字符串文字都是 UTF-8 字符串。 但是因为字符串可以包含任意字节,如果它是从其他地方(不是源码)获得的,则不能保证它是基于 UTF-8 编码的
- 使用 UTF-8,一个 Unicode 字符可以编码为 1 到 4 个字节
- 在 Go 中对字符串使用 len 返回字节数,而不是字符数
2、字符串遍历
我们在开发中经常会用到对字符串进行遍历的场景。 也许我们想对字符串中的每个 rune 执行一个操作,或者实现一个自定义函数来搜索特定的子字符串。 在这两种情况下,我们都必须遍历字符串的不同字符。 但往往会得到让我们意想不到的结果。
我们看下下面的例子,打印一个字符串中的不同字符和对应的位置:
package main
import "fmt"
func main() {
s := "h嗨llo"
for i := range s {
fmt.Printf("字符位置 %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
}
go run 7.go
字符位置 0: h
字符位置 1: å
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
我们想要的效果是通过遍历字符串,打印出每个字符的索引。但是我们却得到了一个特殊的字符å,其实我们想要的是嗨。
但是打印的字节数是符合我们的预期的,因为嗨是一个中文占用了3个字节,所以len返回的是7。
3、字符串中的字符数
如果我们想要正确的获取字符串的字符数,可以使用go中的utf8包:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
for i := range s {
fmt.Printf("字符位置 %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s)) // 获取字符数
}
go run 7.go
字符位置 0: h
字符位置 1: å
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
rune len=5
在这个例子中,可以看到,我们确实遍历了5次,也就是对应字符串的5个字符。但是我们获取到的索引其实是对应每个字符的起始位置。像下面这样

那我们如何打印出正确的结果呢?我们稍微修改下代码:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
for i, v := range s { // 此处改为获取v,可以获取到字符本身
fmt.Printf("字符位置 %d: %c\n", i, v)
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s))
}
go run 7.go
字符位置 0: h
字符位置 1: 嗨
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
rune len=5
另外一种方法就是把字符串转换成rune切片,这样也会正确打印结果:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
b := []rune(s)
for i := range b {
fmt.Printf("字符位置 %d: %c\n", i, b[i])
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s))
}
go run 7.go
字符位置 0: h
字符位置 1: 嗨
字符位置 2: l
字符位置 3: l
字符位置 4: o
len=7
rune len=5
下面是rune切片遍历的过程(中间省略了将字节转换为rune的过程,需要遍历字节,复杂度为O(n))
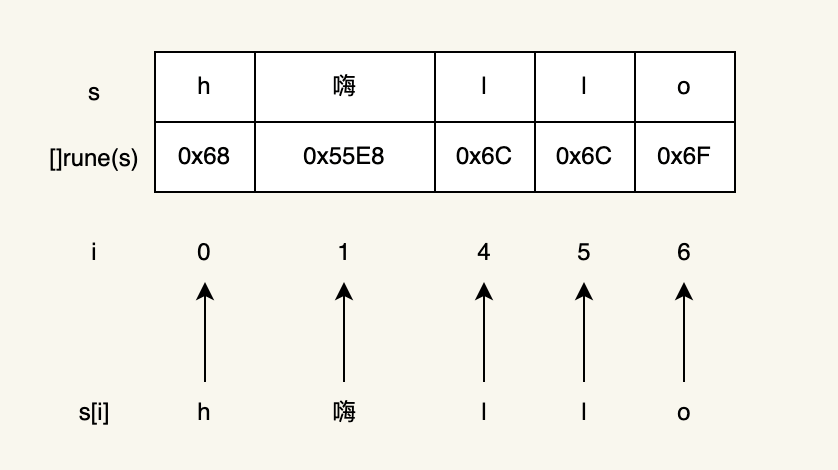
4、字符串trim
开发中我们经常会遇到去除字符串头部或者尾部字符的操作。比如我们现在有个字符串xohelloxo,现在我们想去除尾部的xo,可能我们会像下面这样写:
package main
import (
"fmt"
"strings"
)
func main() {
s := "xohelloxo"
s = strings.TrimRight(s, "xo")
fmt.Println(s)
}
go run 7.go
xohell
可以看到这不是我们期望的结果。我们可以看下TrimRight的工作原理:
- 从右侧取出第一个字符o,判断是否在xo中,在就移除
- 重复步骤1,知道不符合条件
所以就可以解释通了。当然和它相似的TrimLeft和Trim也是一样的原理。
如果我们只想删除最后xo可以使用TrimSuffix函数:
package main
import (
"fmt"
"strings"
)
func main() {
s := "xohelloxo"
s = strings.TrimSuffix(s, "xo")
fmt.Println(s)
}
go run 7.go
xohello
当然也有对应的从前面删除的函数TrimPrefix。
5、字符串连接
开发中我们经常会用到连接字符串的操作,在go中我们一般有2种方式。
我们先看下+号连接的方式:
package main
import (
"fmt"
"strings"
)
func implode(values []string, operate string) string {
s := ""
for _, value := range values {
s += operate
s += value
}
s = strings.TrimPrefix(s, operate)
return s
}
func main() {
a := []string{"hello", "world"}
s := implode(a, " ")
fmt.Println(s)
}
go run 7.go
hello world
这种方式的缺点就是,由于字符串的不变性,每次+号赋值的时候s不会被更新,而是重新分配内存,所以这种方式对性能有很大影响。
还有一种方式就是使用strings.Builder:
package main
import (
"fmt"
"strings"
)
func implode(values []string, operate string) string {
sb := strings.Builder{}
for _, value := range values {
_, _ = sb.WriteString(operate)
_, _ = sb.WriteString(value)
}
s := strings.TrimPrefix(sb.String(), operate)
return s
}
func main() {
a := []string{"hello", "world"}
s := implode(a, " ")
fmt.Println(s)
}
go run 7.go
hello world
首先,我们创建了一个 strings.Builder 结构。 在每次遍历中,我们通过调用 WriteString 方法构造结果字符串,该方法将 value 的内容附加到其内部缓冲区,从而最大限度地减少内存复制。
WriteString 的第二个参数返回的是error,但是error的值会一直为nil。 之所以有第二个error参数是因为我 strings.Builder 实现了 io.StringWriter 接口,它包含一个方法:WriteString(s string) (n int, err error)。
我们看下WriteString的内部是什么样的:
func (b *Builder) WriteString(s string) (int, error) {
b.copyCheck()
b.buf = append(b.buf, s...)
return len(s), nil
}
我们可以看到b.buf是一个字节切片,而里面的实现是使用了append方法。我们知道如果切片很大,使用append会让底层数组不断扩容,影响代码执行效率。
我们知道解决这个问题的方法是,如果事先知道切片的大小,我们可以在初始化的时候就分配好切片的容量。
所以上面的字符串连接还有一种优化方案:
package main
import (
"fmt"
"strings"
)
func implode(values []string, operate string) string {
total := 0
for i := 0; i < len(values); i++ {
total += len(values[i])
}
total += len(operate) * len(values)
sb := strings.Builder{}
sb.Grow(total) // 这里会重新分配b.buf的长度和容量
for _, value := range values {
_, _ = sb.WriteString(operate)
_, _ = sb.WriteString(value)
}
s := strings.TrimPrefix(sb.String(), operate)
return s
}
func main() {
a := []string{"hello", "world"}
s := implode(a, " ")
fmt.Println(s)
}
go run 7.go
hello world
6、字节切片转字符串
需要明确的是,字节切片转换成字符串,需要复制一份副本出来。可以通过下面的代码做验证:
b := []byte{'a', 'b', 'c'}
s := string(b)
b[1] = 'x'
fmt.Println(s)
事实上,上面将会输出abc而不是axc。所以字节切片到字符串的转换是有开销的。
但是我们开发中经常用到的包iio.Read之类的,入参或者返回经常是字节切片类型。而我们调用这些函数时经常是以字符串的形式,导致我们不得不做一些字节切片刀字符串的转换。
所以结论是,当我们需要使用字符串作为入参或者返回时,我们首先要考虑的是能用字节切片的就用字节切片。
golang中的字符串的更多相关文章
- golang中的字符串拼接
go语言中支持的字符串拼接的方法有很多种,这里就来罗列一下 常用的字符串拼接方法 1.最常用的方法肯定是 + 连接两个字符串.这与python类似,不过由于golang中的字符串是不可变的类型,因此用 ...
- golang 中获取字符串个数
golang 中获取字符串个数 在 golang 中不能直接用 len 函数来统计字符串长度,查看了下源码发现字符串是以 UTF-8 为格式存储的,说明 len 函数是取得包含 byte 的个数 // ...
- golang中获取字符串长度的几种方法
一.获取字符串长度的几种方法 - 使用 bytes.Count() 统计 - 使用 strings.Count() 统计 - 将字符串转换为 []rune 后调用 len 函数进行统计 ...
- golang中字符串的底层实现原理和常见功能
1. 字符串的底层实现原理 package main import ( "fmt" "strconv" "unicode/utf8" ) f ...
- 基础知识 - Golang 中的正则表达式
------------------------------------------------------------ Golang中的正则表达式 ------------------------- ...
- google的grpc在golang中的使用
GRPC是google开源的一个高性能.跨语言的RPC框架,基于HTTP2协议,基于protobuf 3.x,基于Netty 4.x. 前面写过一篇golang标准库的rpc包的用法,这篇文章接着讲一 ...
- Golang中Struct与DB中表字段通过反射自动映射 - sqlmapper
Golang中操作数据库已经有现成的库"database/sql"可以用,但是"database/sql"只提供了最基础的操作接口: 对数据库中一张表的增删改查 ...
- golang 中 string 转换 []byte 的一道笔试题
背景 去面试的时候遇到一道和 string 相关的题目,记录一下用到的知识点.题目如下: s:="123" ps:=&s b:=[]byte(s) pb:=&b s ...
- golang中Context的使用场景
golang中Context的使用场景 context在Go1.7之后就进入标准库中了.它主要的用处如果用一句话来说,是在于控制goroutine的生命周期.当一个计算任务被goroutine承接了之 ...
随机推荐
- linux常见命令(十二)
sed/egrep将order.txt文件按行号展示出来,并删除第2,4行nl order.txt |sed '2,4d'将order.txt文件按行号展示出来,并删除第3行nl order.txt ...
- Luogu1382 楼房 (线段树 扫描线)
各种低级错误.jpg,数组开大就过.jpg 线段树离散化扫描线 #include <iostream> #include <cstdio> #include <cstri ...
- java中为什么只存在值传递(以传入自定义引用类型为例)
java中只有值传递 为什么这么说?两个例子: public class Student { int sage = 20; String sname = "云胡不归"; publi ...
- Spring源码 10 IOC refresh方法5
本文章基于 Spring 5.3.15 Spring IOC 的核心是 AbstractApplicationContext 的 refresh 方法. 其中一共有 13 个主要方法,这里分析第 5 ...
- ArkUI 数据绑定、列表渲染、事件处理
前言 有过开发微信小程序经验的小伙伴学习鸿蒙应用开发非常容易过渡过来. HML(HarmonyOS Markup Language)是一套类HTML的标记语言,通过组件,事件构建出页面的内容.页面具备 ...
- 开发H5程序或者小程序的时候,后端Web API项目在IISExpress调试中使用IP地址,便于开发调试
在我们开发开发H5程序或者小程序的时候,有时候需要基于内置浏览器或者微信开发者工具进行测试,这个时候可以采用默认的localhost进行访问后端接口,一般来说没什么问题,如果我们需要通过USB基座方式 ...
- 【MySQL】从入门到精通6-MySQL数据类型与官方文档
上期:[MySQL]从入门到精通5-一对多-外键 这个是官方文档链接,是世界上最全面的MySQL教学了,所有问题都可以在这里找到解决方法. https://dev.mysql.com/doc/ htt ...
- OpenJudge 1.5.39 与7无关的数
39:与7无关的数 总时间限制: 1000ms 内存限制: 65536kB 描述 一个正整数,如果它能被7整除,或者它的十进制表示法中某一位上的数字为7,则称其为与7相关的数.现求所有小于等于n(n ...
- HPC+时代,携手亚马逊云科技,共赴数字化升级的星辰大海!
高性能计算(HPC)和云计算曾是两个"平行世界",各自演绎着精彩,却鲜有交集. 传统上,HPC主要应用于大规模计算,如天气预报.石油勘探.药物研发等.这些任务通常借助超级计算机或计 ...
- Java中的SPI原理浅谈
在面向对象的程序设计中,模块之间交互采用接口编程,通常情况下调用方不需要知道被调用方的内部实现细节,因为一旦涉及到了具体实现,如果需要换一种实现就需要修改代码,这违反了程序设计的"开闭原则& ...