Kubernetes(k8s)底层网络原理刨析
1 典型的数据传输流程图
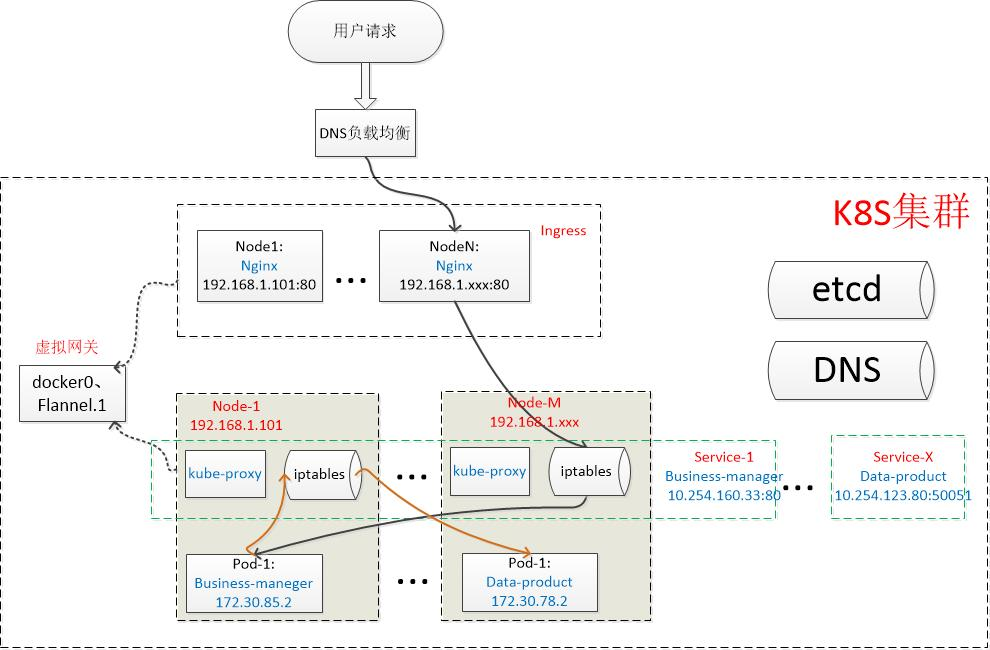
• 一个外部的business-manager请求,首先进入集群的入口(ingress),ingress反向代理后负载到business-manager的service。Service层再负载到某个node下的具体的business-manager pod
• Business-manager pod再将请求发往data-product的service,同理,service层继续随机选择一个data-product的Pod来接收请求
• 上面这个请求,涉及到容器的网络-docker0、跨主机通讯-flannel网络方案、ingress和service组件,以及DNS等,下面我会挨个介绍它们的基本原理。
2 3种ip说明
写这个文档的同时,我在虚拟机上搭建了一个K8S环境,集群内包含2台主机,ip分别为192.168.0.21和192.168.0.22,主要组件为ingress->nginx、service->kube-proxy、网络->flannel,我们以这个集群为例进行分析。
在深入之前,我们先科普一下K8S集群内常见IP的含义:
# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
business-manager-666f454f7f-bg2bt 1/1 Running 0 153m 172.30.76.4 192.168.0.21
business-manager-666f454f7f-kvn5z 1/1 Running 0 153m 172.30.76.5 192.168.0.21
business-manager-666f454f7f-ncjp7 1/1 Running 0 153m 172.30.9.4 192.168.0.22
data-product-6664c6dcb9-7sxnz 1/1 Running 0 160m 172.30.76.2 192.168.0.21
data-product-6664c6dcb9-j2f48 1/1 Running 0 160m 172.30.76.3 192.168.0.21
data-product-6664c6dcb9-p5xkw 1/1 Running 0 160m 172.30.9.3 192.168.0.22
Node ip:宿主机的ip,由路由器分配。上图最右边的NODE列代表的就是容器所在的宿主机的物理ip,可以看到现在集群内2台主机都有分配容器。
Pod ip:被docker0网桥隔离的pod子网的ip。K8s在每个Node里虚拟出的局域网。上图的IP列,就是每个pod ip,可以看到同一宿主机下Pod在同网段(后面我会介绍不同的node下的Pod,是如何借助flannel来实现跨主机通讯的)
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
business-manager ClusterIP 10.254.80.22 <none> 80/TCP 156m
data-product ClusterIP 10.254.116.224 <none> 50051/TCP 159m
kubernetes ClusterIP 10.254.0.1 <none> 443/TCP 5h8m
Cluster ip:k8s分配给每个service的全局唯一的虚拟ip,也可以叫VIP。VIP没有挂接到网络设备,不能直接访问。(后面会介绍这个ip的用处)
除了上面的3个主要ip,集群里还有其他的一些特定的ip和网段:
• DNS服务器:这里配置的是10.254.0.2:53
• 10.254.0.0/16网段,是可配置的当前集群的网段,DNS和service的虚拟Ip正是处在这个网段里。
3 Docker0网桥和flannel网络方案
在介绍Ingress和service这两个组件之前,我们先简单了解一下k8s节点之间的底层网络原理及典型的flannel-VXLAN方案。后面的章节,默认在节点之间的传输,都会有docker0网桥和flannel插件的功劳。(有资料提到K8S采用cni0网桥替代了docker0网桥,两者的原理是一样的,我搭建的环境里只有docker0网桥,所以我们按docker0来分析)
# kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
business-manager-666f454f7f-7l86b 1/1 Running 1 11m 172.30.76.7 192.168.0.21
business-manager-666f454f7f-h5tvw 1/1 Running 1 11m 172.30.76.6 192.168.0.21
business-manager-666f454f7f-zxmsx 1/1 Running 0 8s 172.30.9.3 192.168.0.22
data-product-6664c6dcb9-4zk27 1/1 Running 1 11m 172.30.76.5 192.168.0.21
data-product-6664c6dcb9-7bn7p 1/1 Running 1 11m 172.30.76.3 192.168.0.21
data-product-6664c6dcb9-tkmms 1/1 Running 0 5m39s 172.30.9.2 192.168.0.22
大家注意到没有,每个pod具备不同的Ip(这里指k8s集群内可访问的虚拟ip),不同node下的pod甚至在不同的网段。那么问题来了,集群内不同IP、不同网段的节点是怎么实现通讯的呢?这样归功于docker0和flannel.1这两个虚拟网络设备,我们先ifconfig查看一下:
# ifconfig
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 172.30.76.1 netmask 255.255.255.0 broadcast 172.30.76.255
inet6 fe80::42:67ff:fe05:b530 prefixlen 64 scopeid 0x20<link>
ether 02:42:67:05:b5:30 txqueuelen 0 (Ethernet)
RX packets 31332 bytes 2136665 (2.0 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 21146 bytes 2125957 (2.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.21 netmask 255.255.255.0 broadcast 192.168.0.255
inet6 fe80::d34:64ee:27c8:3713 prefixlen 64 scopeid 0x20<link>
ether 00:15:5d:02:b2:00 txqueuelen 1000 (Ethernet)
RX packets 1588685 bytes 265883182 (253.5 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1604521 bytes 211279156 (201.4 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 172.30.21.0 netmask 255.255.255.255 broadcast 0.0.0.0
inet6 fe80::8822:81ff:fe5e:d8b7 prefixlen 64 scopeid 0x20<link>
ether 8a:22:81:5e:d8:b7 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 8 overruns 0 carrier 0 collisions 0
...
部署flannel和docker后,会在宿主机上创建上述两个网络设备。接下来我们通过一个示意图来了解这两个设备的工作:
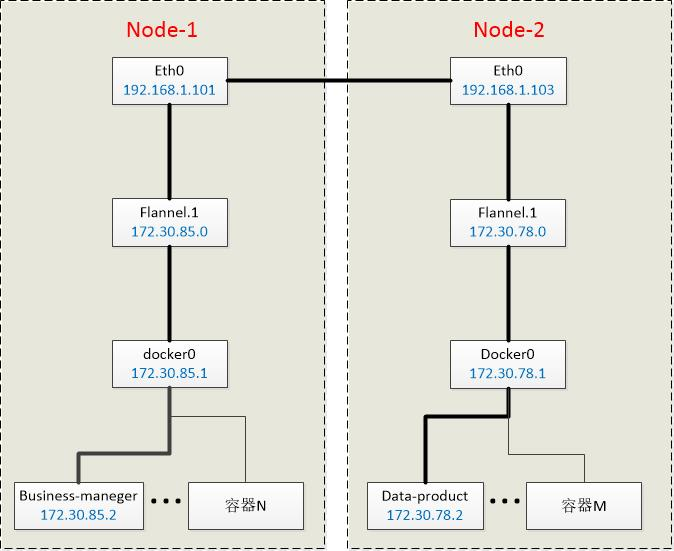
• K8s在每个宿主机(node)上创建了cni0网桥(这篇文档对应的集群环境采用的是docker0网桥,原理一样):容器的网关,实际指向的是这个网桥。
• Flannel则在每个宿主机上创建了一个VTEP(虚拟隧道端点)设备flannel.1。
现在我们来分析下docker0和flannel.1是怎么实现跨主机通讯的(由node1的business-manager:172.30.76.7发往node2的data-product:172.30.9.2):
# route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
default gateway 0.0.0.0 UG 100 0 0 eth0
172.30.0.0 0.0.0.0 255.255.0.0 U 0 0 0 flannel.1
172.30.76.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
192.168.0.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
- 上图是node1的路由表:第2行表示凡是发往172.30.0.0/16网段的包均交给node1-flannel.1设备处理;第3行表示凡是发往172.30.76.0/8网段的包均交给node1-docker0网桥处理。
- 于是business- manager的请求,首先到达node1-docker0网桥,目的地址是172.30.9.2,只能匹配第2条规则,请求被交给node1-flannel.1设备。
- node1-flannel.1又如何处理呢?请看下图,展示的是flannel.1的ARP表:
# ip neigh show dev flannel.1
172.30.9.2 lladdr 96:8f:2d:49:c5:31 REACHABLE
172.30.9.1 lladdr 96:8f:2d:49:c5:31 REACHABLE
172.30.9.0 lladdr 96:8f:2d:49:c5:31 STALE
- node1-flannel.1的ARP表记录的是ip和对应节点上的flannel.1设备mac的映射。于是发往172.30.9.2匹配到了上述第1条规则,需要发往mac地址为96:8f:2d:49:c5:31的设备。
# bridge fdb show flannel.1 |grep 96:8f:2d:49:c5:31
96:8f:2d:49:c5:31 dev flannel.1 dst 192.168.0.22 self permanent
- 这时候node1-flannel.1设备又扮演一个网桥的角色,上图为node1上查询出的桥接规则,96:8f:2d:49:c5:31的目的ip对应于192.168.0.22,这正是我们这个例子里node2的宿主机Ip。于是这个请求被转发给了node2。
- 不难理解,node2也有一个像第1步那样的路由表,于是来自node1-business-manager:172.30.76.7的请求最终经node2-docker0送达node2-data-product:172.30.9.2。
• 随着node和pod加入和退出集群,flannel进程会从ETCD感知相应的变化,并及时更新上面的规则。
• 现在我们已实现通过ip访问pod,但pod的ip随着k8s调度会变化,不可能隔三差五的去人工更新每个ip配置吧,这就需要service这个组件了,请看下一章。
4 Service和DNS
4.1 service
pod的ip不是固定的,而且同一服务的多个pod需要有负载均衡,这正是创建service的目的。
Service是由kube-proxy组件和iptables来共同实现的。
分析service原理前,大家可以先带上这个问题:service的ip为什么ping不通?
OK,我们现在直接上图,随便一个node的iptables(内容比较丰富,我随便截了几段,下文会挑几个重要的规则展开分析):
# iptables-save
...
-A KUBE-FIREWALL -m comment --comment "kubernetes firewall for dropping marked packets" -m mark --mark 0x8000/0x8000 -j DROP
-A KUBE-FORWARD -m comment --comment "kubernetes forwarding rules" -m mark --mark 0x4000/0x4000 -j ACCEPT
-A KUBE-FORWARD -s 10.254.0.0/16 -m comment --comment "kubernetes forwarding conntrack pod source rule" -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A KUBE-FORWARD -d 10.254.0.0/16 -m comment --comment "kubernetes forwarding conntrack pod destination rule" -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A KUBE-SERVICES -d 10.254.0.2/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp has no endpoints" -m tcp --dport 53 -j REJECT --reject-with icmp-port-unreachable
-A KUBE-SERVICES -d 10.254.0.2/32 -p udp -m comment --comment "kube-system/kube-dns:dns has no endpoints" -m udp --dport 53 -j REJECT --reject-with icmp-port-unreachable
...
-A KUBE-MARK-DROP -j MARK --set-xmark 0x8000/0x8000
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
-A KUBE-SEP-CNIAJ35IU3EJ7UR6 -s 172.30.9.3/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-CNIAJ35IU3EJ7UR6 -p tcp -m tcp -j DNAT --to-destination 172.30.9.3:8080
-A KUBE-SEP-DGXT5Z3WOYVLBGRM -s 172.30.76.3/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-DGXT5Z3WOYVLBGRM -p tcp -m tcp -j DNAT --to-destination 172.30.76.3:50051
...
-A KUBE-SERVICES -d 10.254.80.22/32 -p tcp -m comment --comment "default/business-manager:business-manager cluster IP" -m tcp --dport 80 -j KUBE-SVC-FZ5DC5B5DCQ4E7RC
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-SVC-45TXGSBX3LGQQRTB -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-DGXT5Z3WOYVLBGRM
-A KUBE-SVC-45TXGSBX3LGQQRTB -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-P6GCAAVN4MLBXK7I
-A KUBE-SVC-45TXGSBX3LGQQRTB -j KUBE-SEP-QFJ7ESRM37V67WJQ
...
现在可以回答service ip ping不通的问题了,因为service不是真实存在的(没有挂接具体的网络设备),而是由上图这些iptables规则组成的一个虚拟的服务。
• Iptables是linux内核提供给用户的可配置的网络层防火墙规则,内核在解析网络层ip数据包时,会加入相应的检查点,匹配iptables定义的规则。
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
business-manager ClusterIP 10.254.80.22 <none> 80/TCP 3h28m
data-product ClusterIP 10.254.116.224 <none> 50051/TCP 3h32m
kubernetes ClusterIP 10.254.0.1 <none> 443/TCP 6h
• 我们还是看第3章的例子,business-manager要访问data-product,于是往service-data-product的ip和port(10.254.116.224:50051)发送请求。每个service对象被创建时,k8s均会分配一个集群内唯一的ip给它,并且该ip伴随service的生命周期不会变化,这就解决了本节开篇的Pod ip不固定的问题。
-A KUBE-SERVICES -d 10.254.116.224/32 -p tcp -m comment --comment "default/data-product:data-product cluster IP" -m tcp --dport 50051 -j KUBE-SVC-45TXGSBX3LGQQRTB
• KUBE-SERVICES:Iptables表里存在上面这条规则,表示发往10.254.116.224:50051的数据包,跳转到KUBE-SVC-45TXGSBX3LGQQRTB规则。
-A KUBE-SVC-45TXGSBX3LGQQRTB -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-DGXT5Z3WOYVLBGRM
-A KUBE-SVC-45TXGSBX3LGQQRTB -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-P6GCAAVN4MLBXK7I
-A KUBE-SVC-45TXGSBX3LGQQRTB -j KUBE-SEP-QFJ7ESRM37V67WJQ
• KUBE-SVC-xxx:这条规则,实际上是一条规则链,data-product我建了3个pod,所以这条规则链对应的正是这3个pod。这里是service负载均衡的关键实现,第1条规则表示采用随机模式,有1/3(33%)的概率跳转到KUBE-SEP-DGXT5Z3WOYVLBGRM;第2条规则的概率是1/2(50%);第3条则直接跳转。这里有个需要注意的地方,iptables是顺序往下匹配的,所以多节点随机算法,概率是递增的,以data-product为例,我配置了3个Pod,就有3条规则,第1条被选中的概率为1/3,第2条则为1/2,最后1条没得挑了,概率配置为1或直接跳转。
-A KUBE-SEP-P6GCAAVN4MLBXK7I -s 172.30.76.5/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-P6GCAAVN4MLBXK7I -p tcp -m tcp -j DNAT --to-destination 172.30.76.5:50051
• KUBE-SEP-xxx:假设随机到第2条KUBE-SEP-P6GCAAVN4MLBXK7I,这里又是两条规则。第1条是给转发的数据包加标签Mark,目的是在集群多入口的场景下,保证数据包从哪进来的就从哪个node返回给客户端,详细原理就不展开说了。同时这里还涉及到一个技术点,经过service转发的数据包,pod只能追查到转发的service所在的Node,如果有场景需要Pod明确知道外部client的源Ip,可以借用service的spec.externalTrafficPolicy=local字段实现。
• KUBE-SEP-xxx:第2条规则就很简单了,数据包转发给172.30.76.5:50051,这里已经拿到pod的ip和port,可以通过第3章的docker0和flannel.1网络进行通信了。
上面是基于iptables的service方案,存在一个风险,当pod数量很大,几百、几千时,遍历iptables将会是性能瓶颈。IPVS虚拟网卡技术在大量级的pod场景下表现比iptables优秀(运维的同事反馈11版本的k8s,官方已默认采用IPVS)。这不属于本文档的目的,不展开说。
本节开头我们提到service是由kube-proxy和iptables共同实现的,所以Kube-proxy所扮演的角色就不难想象了,kube-proxy负责感知集群的变化,及时更新service的规则。
最后,我们还面临着一个小问题,上面的过程是基于服务的VIP的访问服务的,通过服务名的方式访问又是怎么实现的呢,请看下一节:DNS
4.2 DNS
本来写这个文档没想到要有DNS这一章节的,但集群搭建好之后发现通过服务名无法访问服务,通过VIP却可以,才想起来集群还需要额外搭个DNS组件。
# kubectl get po -n kube-system
NAME READY STATUS RESTARTS AGE
kube-dns-7cd94476cd-kr76t 4/4 Running 0 25s
DNS组件是跑在kube-system命名空间下的一个pod,监听着集群ip:10.254.0.2:53。通过这个Ip:port(创建kubelet时指定DNS的ip)即可获取到集群内部的DNS解析服务。
现在我们随便进入一个pod里,可以看到dns的信息已被k8s写入。同时我们ping一个service:
# cat /etc/resolv.conf
nameserver 10.254.0.2
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
# ping data-product.default.svc.cluster.local
PING data-product.default.svc.cluster.local (10.254.116.224) 56(84) bytes of data.
^C
--- data-product.default.svc.cluster.local ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 1999ms
当然是ping不通的,但vip已经被解析出来了。
Kubenetes可以为pod提供稳定的DNS名字,且这个名字可通过pod名和service名拼接出来,以上面的data-product为例,该服务的完整域名是[服务名].[命名空间].svc.[集群名称]。相应的,每个pod也有类似规则的域名。
5 外部访问集群
5.1 外部访问service
Service代理的是集群内部的ip和端口,出了集群这个ip:port就没什么意义了。所以如何在集群外部访问到service呢?
方式一:配置service的type=NodePort,此方式下k8s会给service做端口映射。这种方式是最常用的,我们DEV环境下很多service做了端口映射,可以通过宿主机Ip加映射出去的端口号直接访问服务。这种方式的原理简单,kube-proxy只需要在iptables里增加一条规则,将外部端口的包导向第4章的service规则去处理即可。(下一节要讲的ingress,正是这种方式的一种更细致的实现)
方式二:type=LoadBalancer,适用于公有云提供的K8s环境,此时K8s使用一个叫作CloudProvider的转接层与公有云的API交互,并由公有云API来实现负载均衡。
方式三:type=ExternalName,这个方式的用法我还没搞清楚。
按前面章节的套路,这里我们依然会面临一个小问题,把外部需要访问的服务大量的通过端口映射方式暴露出去,势必给端口的管理带来麻烦。所以,接下来我们看看ingress是怎么作为集群的入口,帮我们管理后端服务的。
5.2 ingress
4.2章节,在集群内部我们实现了通过域名(服务名)获取具体的服务vip,从而免去了管理Vip烦恼。那么从外部访问集群的服务,又如何实现通过域名的方式呢?后端的服务有很多,我们也需要一个全局的负载均衡器来管理后面服务。这就是ingress。
# kubectl get po -n ingress-nginx
NAME READY STATUS RESTARTS AGE
nginx-ingress-controller-546bfbff9-hpwsz 1/1 Running 0 84s
• 使用ingress,我们除了要创建ingress对象以外,还需要安装一个ingress-controller,这里我们选择最常用的nginx-ingress-controller。如上所示,安装之后,会增加一个ingress-nginx命名空间,运行着nginx-ingress-controller容器。
# kubectl exec -ti nginx-ingress-controller-546bfbff9-hpwsz sh -n ingress-nginx
$ more /etc/nginx/nginx.conf
...
## start server data-product
server {
server_name data-product ;
listen 80;
set $proxy_upstream_name "-";
location / {
set $namespace "default";
set $ingress_name "data-product";
set $service_name "data-product";
set $service_port "50051";
set $location_path "/";
...
• 当Ingress对象被创建时,nginx-ingress-controller会在这个nginx容器内部生成一个配置文件/etc/nginx/nginx.conf(内容比较丰富,上图我截了一小段,可以看到data-product.default的主要配置),并用这个文件启动nginx服务。当ingress对象被更新时,nginx-ingress-controller会实现nginx服务的动态更新。
# cat ing.yaml
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: business-user
namespace: ns-jo
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: business-user.ns-jo
http:
paths:
- path: /
backend:
serviceName: business-user
servicePort: 80
• Nginx服务的功能:随便找一个ingress文件查看,rules字段包含一组域名、路径、后端服务名、服务端口的映射,这就是个反向代理的配置文件。当前我们用nginx做反向代理,以及将请求负载给后端的service。加上证书,nginx还可以解析https,给后端依然是http明文通信
现在又面临一个小问题了,这个nginx服务居然运行在容器里,参考5.1章节,这个服务外部还是访问不了啊?所以安装nginx-ingress-controller时还需要创建一个服务,将这个pod里的nginx服务监听的80和443端口暴露出去。
# kubectl describe svc ingress-nginx -n ingress-nginx
Name: ingress-nginx
Namespace: ingress-nginx
Labels: app.kubernetes.io/name=ingress-nginx
app.kubernetes.io/part-of=ingress-nginx
Annotations: <none>
Selector: app.kubernetes.io/name=ingress-nginx,app.kubernetes.io/part-of=ingress-nginx
Type: NodePort
IP: 10.254.189.164
Port: http 80/TCP
TargetPort: 80/TCP
NodePort: http 30799/TCP
Endpoints: 172.30.76.2:80
Port: https 443/TCP
TargetPort: 443/TCP
NodePort: https 31522/TCP
Endpoints: 172.30.76.2:443
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
上面这个服务,正是ingress-nginx的SVC,它向外暴露的端口(NodePort)是30799和31522,对应的endpoints正是nginx容器里的nginx服务监听的两个端口80和433。这个ingress-service加上ingress-nginx容器,共同组成了ingress。所以广义上,ingress提供的是集群入口服务,是一个虚拟的概念。不考虑具体的功能的话,business层以NodePort方式运作时,就可以看作business层就是data层的ingress。
现在我们可以用business-manager.default:30799/api/v1/product/list来发起请求。
附 扩展实战
原理分析的再多再深入,最终还是希望能够为我们的工作提供一些帮助。所以下面的篇幅我记录了在分析过程中看到或是想到的可能有助于我们实际工作的思路,限于精力有限,这些思路我暂时还没有完整验证过,同学们有兴趣的话可以参与进来。
附A 用service实现DB的管理
当前DB的ip和端口是配置在每个应用的configmap里的,如果出现DB切换、迁移等因素导致IP或端口变更,我们需要挨个去修改每个应用的config。
K8s支持指定service的endpoints为一个特定的点,比如可以指定为DB的IP和端口。这样我们可以创建两个service:service-DB-read,和service-DB-write。由service来管理DB的IP和PORT,变更只需要修改这两个service的config即可。由4.1章节的分析我们知道,应用访问上述两个service,数据包会被转发给endpoints也就是真正的db。
请见下图,Endpoints指向集群外部数据库的service-mysql:
# kubectl describe svc mysql
Name: mysql
Namespace: default
Labels: <none>
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP: 10.254.84.209
Port: <unset> 3306/TCP
TargetPort: 3306/TCP
Endpoints: 192.168.0.103:3306
Session Affinity: None
Events: <none>
应用层通过访问service-mysql,流量最终会到达endpoints也就是集群外部的真实数据库的ip:port。细心的同学应该能想到,这玩意可以用于简单的数据库负载均衡,比如有多个读库的情况下,我们只需要让service-mysql的endpoints指向这几个读库,流量即能被负载均衡到各个库。
附B 用NetworkPolicy实现访问权限隔离
以DB为例,当前集群的DB对所有pod开放,那有没有办法限制访问权限呢,比如只允许data层访问。回想第4.1章节service的本质是iptables规则,那么就有可能通过iptables实现更细致的规则,比如DB的访问权限管理。这就是k8s的NetworkPolicy,支持以pod的标签的形式制定相应的iptables规则。目前flannel网络插件不支持NetworkPolicy,flannel + Calico插件可以实现。
附C 用secret对象管理账户密码
Kubernetes(k8s)底层网络原理刨析的更多相关文章
- 单例模式-DCL双重锁检查实现及原理刨析
以我的经验为例(如有不对欢迎指正),在生产过程中,经常会遇到下面两种情况: 1.封装的某个类不包含具有具体业务含义的类成员变量,是对业务动作的封装,如MVC中的各层(HTTPRequest对象以Thr ...
- Kubernetes学习之路(二十)之K8S组件运行原理详解总结
目录 一.看图说K8S 二.K8S的概念和术语 三.K8S集群组件 1.Master组件 2.Node组件 3.核心附件 四.K8S的网络模型 五.Kubernetes的核心对象详解 1.Pod资源对 ...
- Kubernetes(k8s)集群部署(k8s企业级Docker容器集群管理)系列之flanneld网络介绍及部署(三)
0.前言 整体架构目录:ASP.NET Core分布式项目实战-目录 k8s架构目录:Kubernetes(k8s)集群部署(k8s企业级Docker容器集群管理)系列目录 一.flanneld介绍 ...
- kubernetes pod infra container网络原理
刚开始接触kubernetes时,对kubelet的--pod-infra-container-image参数非常不能理解,不理解为什么我的业务应用需要依赖一个第三方的容器: 上文入门级kuberne ...
- kubernetes网络原理
1.1. 基础原则 每个Pod都拥有一个独立的IP地址,而且假定所有Pod都在一个可以直接连通的.扁平的网络空间中,不管是否运行在同一Node上都可以通过Pod的IP来访问. k8s中Pod的IP是最 ...
- K8S从入门到放弃系列-(11)kubernetes集群网络Calico部署
摘要: 前面几个篇幅,已经介绍master与node节点集群组件部署,由于K8S本身不支持网络,当 node 全部启动后,由于网络组件(CNI)未安装会显示为 NotReady 状态,需要借助第三方网 ...
- kubernetes/k8s CNI分析-容器网络接口分析
关联博客:kubernetes/k8s CSI分析-容器存储接口分析 kubernetes/k8s CRI分析-容器运行时接口分析 概述 kubernetes的设计初衷是支持可插拔架构,从而利于扩展k ...
- ThreadLocal原理简单刨析
ThreadLocal原理简单刨析 ThreadLocal实现了各个线程的数据隔离,要知道数据是如何隔离的,就要从源代码分析. ThreadLocal原理 需要提前说明的是:ThreadLocal只是 ...
- <TCP/IP原理> (三) 底层网络技术
传输介质 局域网(LAN) 交换(Switching) 广域网(WAN) 连接设备 第三章 底层网络技术 引言 1)Interne不是一种新的网络 建立在底层网络上的网际网 底层网络——“物理网”,网 ...
随机推荐
- Python 踩坑之旅进程篇其四一次性踩透 uid euid suid gid egid sgid的坑坑洼洼
目录 1.1 踩坑案例 1.2 填坑解法 1.3 坑位分析 1.4 技术关键字 1.5 坑后思考 下期坑位预告 代码示例支持 平台: Centos 6.3 Python: 2.7.14 代码示例: 菜 ...
- 【部分补充】【翻译转载】【官方教程】Asp.Net MVC4入门指南(4):添加一个模型
4. 添加一个模型 · 原文地址:http://www.asp.net/mvc/tutorials/mvc-4/getting-started-with-aspnet-mvc4/adding-a-mo ...
- OPEN SQL
OPEN SQL 1.SELECT .INSERT.UPDATE.DELETE.MODIFYSELECT 命令包含如下从句:SELECT: 需要查询资料库指定表的那些列,是一行还是多行INTO: 查询 ...
- 常用的图片相关方法,读取,保存,压缩,缩放,旋转,drawable转化
import android.content.Context; import android.content.res.AssetManager; import android.content.res. ...
- Java中方法的继承以及父类未被子类覆盖的方法调用的问题
在看java继承这一块的时候发现了一个问题,即父类未被子类覆盖的方法是如何调用的? 是子类拥有了父类的该方法只是没有显示表示,还是子类调用了父类的该方法. 为此做了一下验证 代码如下: public ...
- asterisk-java ami2 事件监听
asteriskServer文章1提到啦怎么获取,就不解释 asteriskServer.addChainListener(new AsteriskeventListenerInit());//整个服 ...
- OSSIM安装与使用感受
下载地址 http://www.alienvault.com OSSIM通过将开源产品进行集成,从而提供一种能够实现安全监控功能的基础平台.它的目标是提供一种集中式.有组织的,能够更好地进行监测和显示 ...
- centos上手动安装最新版本ELK
软件包下载地址:https://www.elastic.co/downloads/elasticsearch 1,安装es #tar zxvf elasticsearch-2.3.4.tar.gz # ...
- ACM的数学基础
懒得整理了,请勿往下看. (一)欧拉函数 设n为正整数,以φ(n)表示不超过n且与n互素的正整数的个数,称为n的欧拉函数值,这里函数φ:N→N,n→φ(n)称为欧拉函数.有如下一些性质: (1)欧拉 ...
- Berkeley DB (VC6.0 编译环境配置)
操作系统:winxp VC环境:VC6.0 必需文件:Berkeley DB安装文件(db-.msi) 下载地址:http://www.oracle.com/technology/software/p ...