cs229_part3
接下来就是最最最重要的一个有监督学习算法了。
支持向量机
问题背景
样本集表示:
\[(x,y)\in D, x\in R^n, y\in \{-1,+1\}\]
回到之前的逻辑回归模型中:
逻辑回归中如果\(h ( x ) =g(\theta^Tx)\geq 0.5\)我们就认为是正例(y=1)。也就是\(\theta^Tx\geq 0\),且\(\theta^Tx\)趋向于无穷大的时候h(x)输出的概率也会越接近于1。所以说:
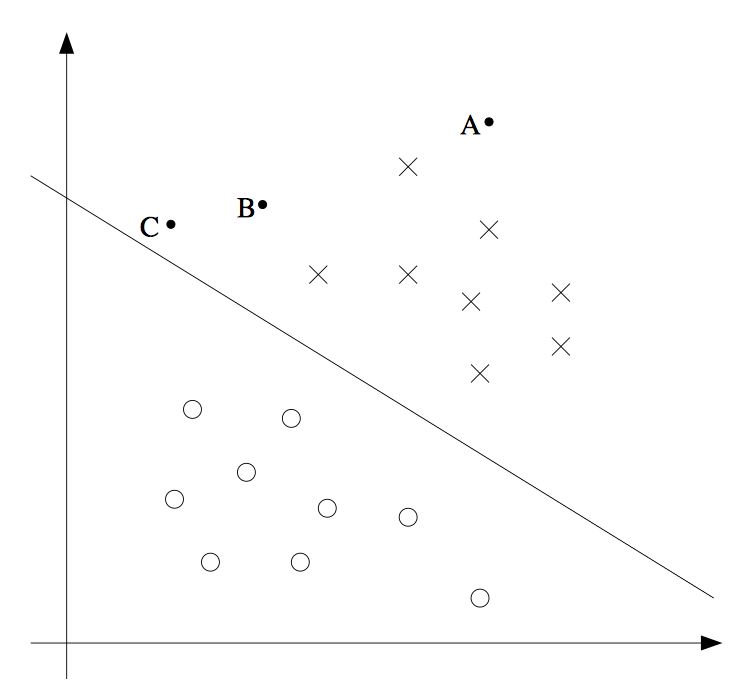
在图像上来理解的话,中间那条线是我们的决策边界。也就是说点离我们的决策边界越远我们越是确信这个点是属于一类。所以我们如何基于这样的间距想法来构造一个模型呢。或者说我们如何构造一个模型,找点一条线使得不同种类的点离这条线都足够远呢。
即SVM是一个最大间距分类器。
构造假设
这里我们要把之前用的符号换一下,把\(\theta^Tx\)表示成\(w^Tx+b\),实际上就是把偏置项给显示地拿了出来。还有一个要注意的是样本集中的分类标签改为了+1和-1而不是之前的0和1。
基于刚才问题背景中的想法,我们构造的假设函数就是:
\[
h(x) = \left\{ \begin{array} { c l } { +1,} & { w^Tx+b \geq 0} \\ { - 1,} & { w^Tx+b < 0} \end{array} \right.
\]
衡量误差
于是我们现在要的就是如何使得点离我们分类直线的距离足够大。
那么先定义点到直线的距离,即某点\(p\)到超平面\(w^Tx+b=0\)的距离为:
\[
\frac { 1} { \| w \| } | w ^ { T } p + b |
\]
其实这条公式我们初高中就学过,只不过是写成这样的:对于直线\(Ax+By+C=0\)点\(p=(x',y')\)到直线的距离为:
\[
\frac{|Ax'+By'+C|}{\sqrt {A^2+B^2}}
\]
那么我们定义间隔为:
\[
\gamma = 2\min _ { i } \frac { 1} { \| w \| } | w ^ { T } x _ { i } + b |
\]
那么最终的优化目标就是:
\[
\begin{array} { r l }
{\max _ { w ,b } \min _ { i }} & {\frac { 2} { \| w \| } | w ^ { T } x _ { i } + b |} \\
{\text{s.t.}} & {y _ { i } ( w ^ { T } x _ { i } + b ) > 0,\quad i = 1,2,\dots ,m}
\end{array}
\]
问题求解
在求解问题之前我们先做一个重要的假设:样本集线性可分。
为了化简问题我们可以对\((w,b)\)进行放缩,即令:
\[
\min _ { i } | w^Tx _ { i } + b | = 1
\]
那么求解优化问题可以化简成:
\[
\left.\begin{array} { l } { \min _ { w ,b } \frac { 1} { 2} w ^ { T } w } \\ { \text{ s.t } \quad y _ { i } \left( w ^ { T } x _ { i } + b \right) \geq 1,\quad i = 1,2,\dots ,m } \end{array} \right.
\]
这是一个带约束的优化问题,之前梯度回归解决的是无约束的优化。所以简单理解的话我们可以使用二次规划对其进行求解,但是二次规划这里就先不讲了。有兴趣自行翻阅资料。
那么所谓SVM其实到这里就结束了。但是更重要的思想要体现在其对偶问题上。
对偶问题
虽然可以用二次规划求解这个问题。但是我们可以通过拉格朗日算子和对偶问题来对其进行再化简。
优化目标再定义
这里重新令\(θ=[w,b]^T\)
高等数学中我们学过用拉格朗日算子求条件极值。
对于有条件约束的优化问题:
\[
\left.\begin{array} { r l } { \min _ { \theta } } & { f ( \theta ) } \\ { \text{ s.t. } } & { g _ { i } ( \theta ) \leq 0,\quad i = 1,\dots ,k } \\ &{ h _ { i } ( \theta ) = 0,} \quad { i = 1,\dots ,l } \end{array} \right.
\]
定义其拉格朗日函数为:
\[
\mathcal { L } ( \theta ,\alpha ,\beta ) = f ( \theta ) + \sum _ { i = 1} ^ { k } \alpha _ { i } g _ { i } ( \theta ) + \sum _ { i = 1} ^ { l } \beta _ { i } h _ { i } ( \theta )
\]
带入拉格朗日算子得到:
\[
\min _ { \alpha } \max _ { \theta} \frac { 1} { 2} \theta ^ { T } \theta + \sum _ { i = 1} ^ { m } \alpha _ { i } \left( 1- y _ { i } \left( \theta ^ { T } x _ { i } + b \right) \right)
\]
\[
\text{ s.t. } \quad \alpha _ { i } \geq 0,\quad i = 1,2,\dots ,m
\]
对α的约束是拉格朗日函数提供,并不是我们问题本身的约束。这里突然多了个max操作是让g满足我们的条件约束。我们的约束是\(g(x)<0\)如果这个约束不满足,那么因为α和β的值是任意的,对g的max操作就会是正无穷。后面的min操作就没有意义了。
对于这样问题满足一定条件时,我们可以转换为其对偶问题,即min和max互换位置。这里省略了很多细节,请翻阅参考:
\[
\max _ { \alpha } \min _ { \theta } \quad \frac { 1} { 2} \theta ^ { T } \theta + \sum _ { i = 1} ^ { m } \alpha _ { i } \left( 1- y _ { i } \left( \theta ^ { T } x _ { i } + b \right) \right)
\]
\[
\text{ s.t. } \quad \alpha _ { i } \geq 0,\quad i = 1,2,\dots ,m
\]
因为内层的min没有约束,我们可以直接求导得到最小值。
\[
\frac { \partial \mathcal { L } } { \partial \theta } = \mathbf { 0} \Rightarrow w = \sum _ { i = 1} ^ { m } \alpha _ { i } y _ { i } x _ { i }
\]
\[
\frac { \partial \mathcal { L } } { \partial b } = 0\Rightarrow \sum _ { i = 1} ^ { m } \alpha _ { i } y _ { i } = 0
\]
化简为:
\[
\min _ { \alpha } \frac { 1} { 2} \sum _ { i = 1} ^ { m } \sum _ { j = 1} ^ { m } \alpha _ { i } \alpha _ { j } y _ { i } y _ { j } x _ { i } ^ { T } x _ { j } - \sum _ { i = 1} ^ { m } \alpha _ { i }
\]
\[
\text{ s.t. } \sum _ { i = 1} ^ { m } \alpha _ { i } y _ { i } = 0
\]
\[
\alpha _ { i } \geq 0,\quad i = 1,2,\dots ,m
\]
注意这里是min不是max是因为取了负号。那么最终的优化问题只与这个α有关。
我们回顾一下整个的流程:
首先回顾一下,最初带入拉格朗日算子得到的是,关于θ和α的双变量的单极值带双约束的问题,我们把约束条件放进转化为另一个极值。这样变成一个关于θ和α的双变量双极值单约束问题。再利用对偶问题,交换极值位置,使得内层的极值问题是无约束的,对其求解,用α消去了θ变成了关于α的单变量的单极值双约束问题,最后这个问题就可以用普通的二次规划进行求解了。
这里并不想太过于纠结数学上细节。但是把整个转化的过程理清楚即可。
KKT条件
因为这是一个有条件的优化问题,极值处需要满足:
- 主问题可行:\[g _ { i } ( w ) \leq 0,h _ { i } ( w) = 0\]
- 对偶问题可行:\[\alpha_i\geq0\]
- 互补松弛:\[\alpha _ { i } g _ { i } ( w ) = 0\]
这三个要满足的条件就是KKT条件。
支持向量
一般来说条件约束的函数极值一般会在约束处取到极值。所以说如下图所示:

我们取到约束的地方就是那两条虚线的地方。在虚线上的点就叫做支持向量,这也是支持向量机名称的由来。也就是说因为我们衡量误差的方式,最后求解的问题只会和这个支持向量相关,即我们直线只由支持向量决定。
于是假设函数最终表示成:
\[
h ( x ) = \operatorname{sign} \left( \sum _ { i \in S V } \alpha _ { i } y _ { i } \left\langle x _ { i } , x \right\rangle + b \right)
\]
SV表示支持向量,<>表示内积操作。
核函数
问题背景
回忆一下我们在求解问题中提到的基本假设就是,样本集线性可分,但是对于线性不可分的情况怎么办呢。
我们可以把样本集映射到更高维度空间上使得其线性可分。比如上面那张图,是二维平面上面样本集,如果我们把这些点投影到一维空间上面,比如说x轴。点就会变密。如果投影到零维空间上,那么所有点都变成了一个点。基于这样的直觉,我们可以认为样本集在越高维度空间上是越稀疏的。所以核函数的作用就是把样本集投影到更高维度空间上使其稀疏变得线性可分。
构造假设
在拉格朗日乘子法中我们求解得到了α并用α替代了w得到了新的假设函数:
\[
h(x)= \sum _ { i = 1} ^ { n } \alpha _ { i } y ^ { ( i ) } \left\langle x ^ { ( i ) } ,x \right\rangle + b
\]
也就是说如果新来了一个样本,我们要判断类别的话,只要和原来样本集中的点做内积计算即可。
回到刚才的问题上来,我们想把样本集映射到更高维度的空间上。假设函数中的我们做了内积运算\(\langle x ^ { ( i ) } ,x\rangle\)得到了一个值。所以要做的就是把x映射到更高维的空间再做内积运算即可。
如果\(\phi ( x )\)表示的是对向量x的一个映射,那么定义核函数k就是:
\[
K ( x ,z ) = \phi ( x ) ^ { T } \phi ( z )
\]
比如我们一个核函数为:
\[
K ( x ,z ) = \left( x ^ { T } z \right) ^ { 2}
\]
即:
\[
\left.\begin{aligned} K ( x ,z ) & = \left( \sum _ { i = 1} ^ { n } x _ { i } z _ { i } \right) \left( \sum _ { j = 1} ^ { n } x _ { j } z _ { j } \right) \\ & = \sum _ { i = 1} ^ { n } \sum _ { j = 1} ^ { n } x _ { i } x _ { j } z _ { i } z _ { j } \\ & = \sum _ { i ,j = 1} ^ { n } \left( x _ { i } x _ { j } \right) \left( z _ { i } z _ { j } \right) \end{aligned} \right.
\]
那么\(\phi ( x )\)的映射就是:
\[
\phi ( x ) = \left[ \begin{array} { c } { x _ { 1} x _ { 1} } \\ { x _ { 1} x _ { 2} } \\ { x _ { 1} x _ { 3} } \\ { x _ { 2} x _ { 1} } \\ { x _ { 2} x _ { 1} } \\ { x _ { 2} x _ { 1} } \\ { x _ { 2} x _ { 2} } \\ { x _ { 3} x _ { 2} } \\ { x _ { 3} x _ { 3} } \end{array} \right]
\]
那么是不是任意的映射都可以作为核函数呢,当然并不是。详细请翻一下参考。
软间距
问题背景
仍然是回到之前那个线性可分的假设中,首先我们假设样本集线性可分,如果线性不可分就映射到高维使得其线性可分。但是如果映射到高纬度还是线性不可分呢。或者这样的一种情况:

本来我们的决策边界是左边这样的,但是如果出现了一个新的样本o我们的决策边界可能会变成右边这样。然而我们仔细思考一下对于右边这个样本集是不是虚线那条决策边界会更好一下。因为很有可能新的那个样本是一个被采样错误的样本。
于是因为存在线性不可分和采样错误的样本的存在。我们需要在衡量误差的时候对被假设函数分类错误的样本有一定的容忍度。
衡量误差
我们引入一个\(\xi\)值(也叫做松弛变量)表示我们对分类错误的容忍度。
\[
\left.\begin{array} { c l } \min _ {w ,b }& \frac { 1} { 2} | | w | | ^ { 2} + C \sum _ { i = 1} ^ { m } \xi _ { i }\\{ \text{ s.t. } } & { y ^ { ( i ) } \left( w ^ { T } x ^ { ( i ) } + b \right) \geq 1- \xi _ { i } ,\quad i = 1,\ldots ,m } \\ & { \xi _ { i } \geq 0,} \quad { i = 1,\ldots ,m } \end{array} \right.
\]
写在约束条件中的\(1-\xi\)其实就是允许支持向量向着决策边界方向移动了,这样间距就会变小,所以叫软间距,这给予了我们容忍分类错误的能力。
而写在优化条件里面中的\(\xi\)是使得分类错误不能太多,所以常数C就是我们对于错误的容忍度。
于是我们可以调节C改变优化的条件来使得这个分类器对于错误容忍度不同来构造更健壮的分类器。
小结
首先我们由最大间距的直觉来构造了一个新的分类器,也就是我们的支持向量机原始问题。我们再对其对偶问题求解得到对偶形式。再对线性不可分的情况下利用核函数映射到高纬。并引入软间距允许误差的存在也有利于线性不可分的情况。
参考
cs229_part3的更多相关文章
- cs229课程索引
重要说明 这个系列是以cs229为参考,梳理下来的有关机器学习传统算法的一些东西.所以说cs229的有些内容我会暂时先去掉放在别的部分里面,也会加上很多重要的,但是cs229没有讲到的东西.而且本系列 ...
随机推荐
- POJ-3275:Ranking the Cows(Floyd、bitset)
Ranking the Cows Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 3301 Accepted: 1511 ...
- JavaScript特点、优缺点及常用框架
参考来源: http://www.cnblogs.com/SanMaoSpace/archive/2013/06/14/3136774.html
- jQuery scrollLeft()与scrollTop() 源码解读
这里的实现也很容易懂,通过jQuery的静态方法each给jQuery的原型添加scrollLeft和scrollTop方法. 这里在取值时它把window和普通的element做了区分 如果是win ...
- Mvc 多级控制器 路由重写 及 多级Views目录 的寻找视图的规则
1.那么我们再来看我们需要的访问方式,如下图 如果我们要访问Admin下的TestController里面的Index页面,那么我们输入Test/Index,这个肯定不行的.因为TestControl ...
- 对javascript变量提升跟函数提升的理解
在写javascript代码的时候,经常会碰到一些奇怪的问题,例如: console.log(typeof hello); var hello = 123;//变量 function hello(){ ...
- zuul filter
前言 过滤器是Zuul的核心组件,这篇文章我们来详细讨论Zuul的过滤器.下面话不多说,来看看详细的介绍吧. 过滤器类型与请求生命周期 Zuul大部分功能都是通过过滤器来实现的.Zuul中定义了四种标 ...
- Oracle查询排序asc/desc 多列 order by
查询结果的排序 显示EMP表中不同的部门编号. 如果要在查询的同时排序显示结果,可以使用如下的语句: SELECT 字段列表 FROM 表名 WHERE 条件 ORDER BY 字段名1 [ASC|D ...
- 4、重建二叉树------------>剑指offer系列
题目1-二叉树重建 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树.假设输入的前序遍历和中序遍历的结果中都不含重复的数字. 例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序 ...
- be seen doing和be seen to do的区别
1. be seen doing和be seen to do的区别 be seen doing表被看到正在做某事:be seen to do 表被看到做某事(不表进行) He was seen to ...
- Android笔记--Bitmap(三) 针对不用Android版本的位图管理
Bitmap(三) | Android不同版本的相应操作 在不同的Android版本中.位图的存储方式是不同的. 1.小于等于 Android 2.2 (API level 8) 垃圾收集器回收内存时 ...