数据表示Numpy
1 基本
1.1 基本介绍
掌握表示, 清洗, 统计和展示数据的能力
Numpy, Matplotlib, Pandas, Projects
摘要: 有损的提取数据特征的过程
可以将一组数据, 摘要出
1) 基本统计(排序)
2) 分布/累计统计
3) 数据特征 相关性, 周期性等
4) 数据挖掘(形成知识)
1.2 Anaconda
Anaconda是数据分析的基本工具
具体有
1) 开源免费
2) 支持800多个第三方库
3) 包含多个主流工具
4) 适合数据计算领域开发
5) 全平台支持
Anaconda是一个集成各类Python工具的集成平台
Anaconda本身不是一个开发工具, 而是一个平台
Anaconda是基于conda这个包管理和环境管理工具的
conda是一个工具, 用于包管理和环境管理, 与pip类似, 管理Python第三方库, 允许多用户使用不同版本Python, 并且能灵活切换
anaconda = conda + Python + 第三方库
1) conda
conda的命令行使用方式(conda推出的时候推荐使用方式):
检测conda版本
conda --version
更新conda
conda update conda
在Anaconda中的conda的图形化方式:
打开Anaconda, 可以找到Environments, 默认生成了一个叫做root的环境空间, 这就是conda的图形界面形式, 里面列好了安装和未安装的包
还可以通过新建一个环境空间, 配置新的环境
2) Spyder
这个Anaconda集成的一个编程工具
可以找home中找到spyder, 点击launch打开
默认打开方式界面有三个区域, 分别是坐车的编辑区, 右上的文件导航和帮组区, 右下是IPython区
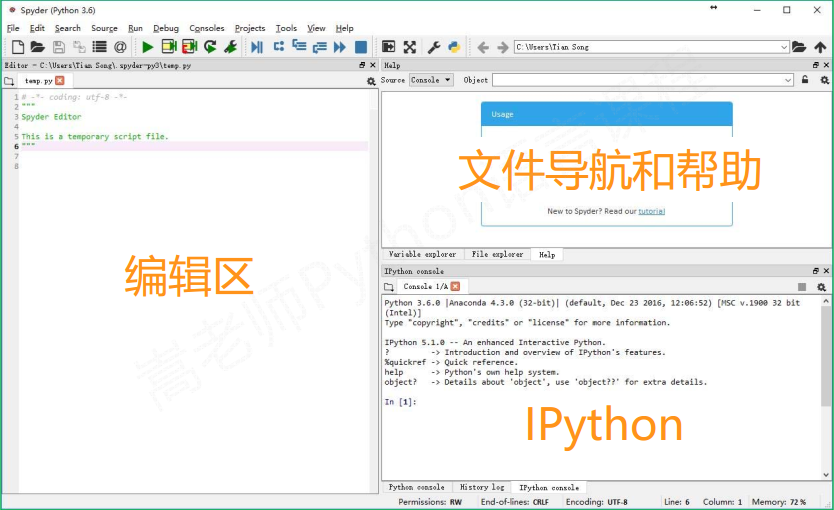
可以修改界面区域设置
也可以设置编辑区的主题
Tools -> preference -> Syntax coloring -> Scheme -> Monokai
IPython是一个功能强大的交互式shell
适合交互式数据可视化
适合GUI相关应用
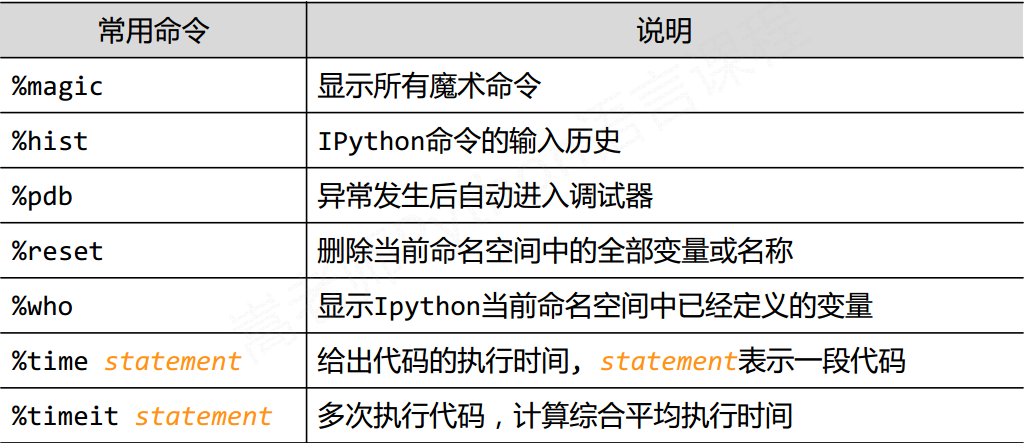
IPython的使用技巧
可以在变量后面加上? 来查看具体信息
IPython的输入提示前面有 In 表示提示输入, Out 表示输出, 后面中括号里面的是输入命令的序号
直接在命令行中执行py文件
%run py文件
%魔术命令
IPython事实上提供了交互接口, 具体执行还是Python内核
2 Numpy入门
2.1 数据的维度
维度: 一组数据的组织形式
一维数据: 沿着一个方向(X轴)展开
一维数据由对等的, 有序或者无序的 数据构成, 采用线性方式组织
可以列表, 数组, 集合等表示
列表与数组基本相似, 只有一点不同, 数组内的数据类型是一致的, 但是列表不要求数据类型一致
二维数据: 沿着两个方向(X轴, Y轴)展开(类似表格)
由多个一维数据构成, 是一维数据的组合形成
可用列表形式表示
多维数据
由一维或者二维数据在新维度上扩展形成
可用字典, 列表形式表示
2.2 ndarray
NumPy是一个开元的Python科学计算基础库, 内含:
1) N维数组对象 ndarray
2) 广播功能函数, 用于在数组之间进行计算
3) 整合c/c++/Fortran代码工具
4) 线性代数, 傅里叶变换, 随机数生成
NumPy是SciPy, Panda是等数据处理或者科学计算库的基础
引用NUmPy
import numpy as np
np是一个约定俗成的别名
ndarray
是NumPy中用作N维数组对象
与列表相比, 有更适合科学计算的特点
1) ndarray内的数据是同一类型, 因此可以整体对该类型进行操作, 更加贴近使用

2) 经过优化, 可以提升基于这个特点的运算速度
3) 基于这个特点, 可以节省运算和存储空间(因为类型相同)
由两部分构成
1) 实际的数据
2) 描述这些数据的元数据(数据维度, 数据类型等)
一般要求所有元素的类型是相同的
数组的下表是从0开始的
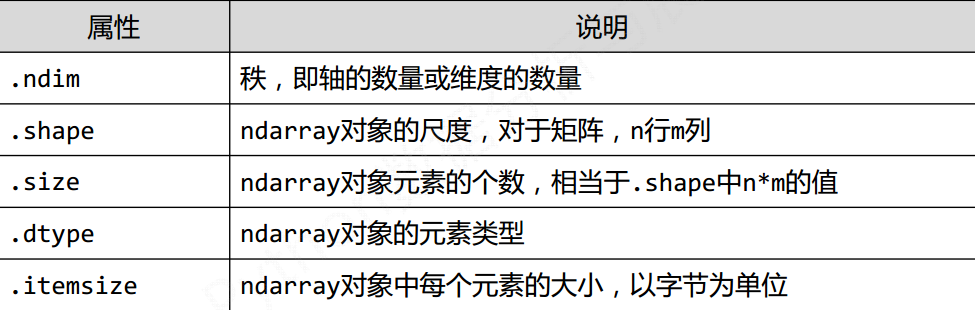
两个基本概念
1) 轴(axis) 保存数据的维度 在轴上, 每个数据存储在其中
2) 秩(rank) 轴的数量(数据类型有多少个维度)
对象的属性
ndarray支持的元素类型



这样的精确定义可以使得对存储空间有一个更好的优化, 也可以帮组估计程序的规模
另外, 尽量在定义ndarray的时候使用同质的对象, 也就是元素的个数相同
如果不同质, 那么ndarray会把整个元素当成一个对象
2.3 ndarray数组的创建
创建ndarray的四种方式
1) 使用列表, 元组
2) 使用NumPy穿件ndarray数组, 如arange, ones, zeros
3) 从字节流(raw bytes)中创建
4) 从文件中读取特定格式
1) 使用列表, 元组创建
变量名 = np.array(列表或者元组类型数据, dtype=np.类型)
其中可以不指定dtype, 这样NumPy会根据输入的内容来自动判断使用什么样的数据类型

2) 最常用的方法, 使用NumPy穿件ndarray数组






可以看到, linspace()中的endpoint设为False时, 计算的规则并没有改变, 只是最后一个边界值不显示了
也就是说, 设置为False的时候, 相当于计算的时候第三个参数+1, 然后最后一个值不要
所以linspace(1, 10, 4) 基本等效于 linspace(1, 10, 3, endpoint=False), 只是最后一个值没有了
由于浮点数在科学计算中的普遍性, 除了arange函数之外, 基本上创建出的都默认使用浮点数作为类型
2.4 对ndarray的变换
ndarray的变换包括维度的变换和元素类型的变换
主要方法有





np.int没有这个类型, 代表的是一类数据类型
astype()方法一定会创建新的数组(原始数据的一个拷贝), 即使两个类型一致

2.5 ndarray的操作
基本才做是 索引 和 切片
索引: 获取数组中特定位置元素的过程
切片: 获得数组的元素子集的过程
一维数组的操作, 与列表类似

多维素组的操作


2.6 ndarray的运算
1) 数组与标量之间的运算
数组中的数据都与这个标量进行运算

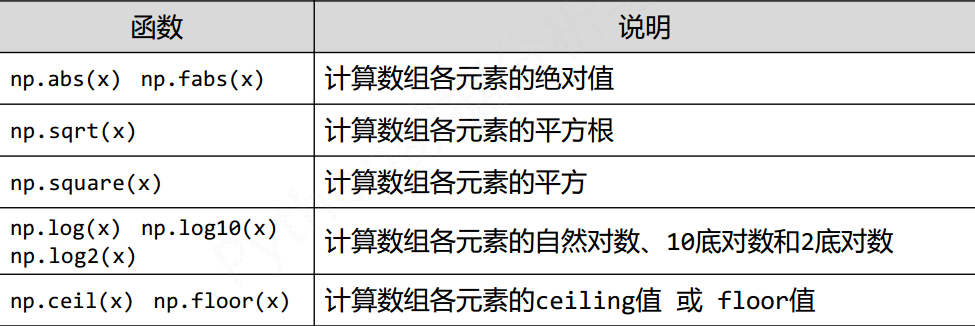
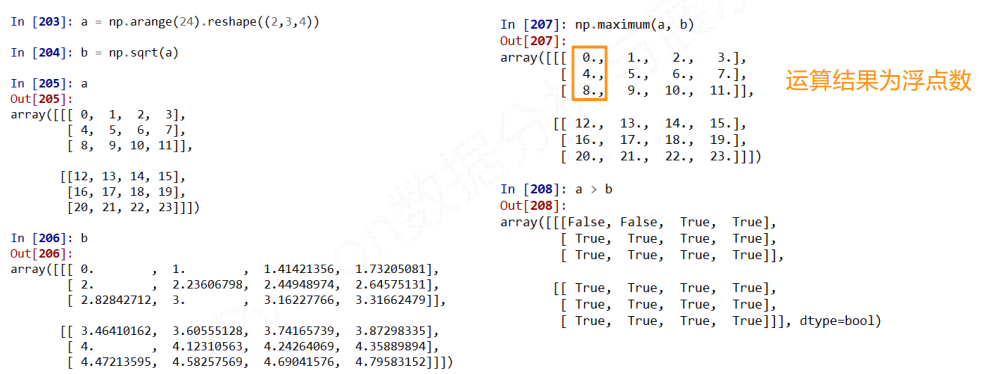
2) NumPy一元函数
对ndarray中的数据执行元素级运算的函数


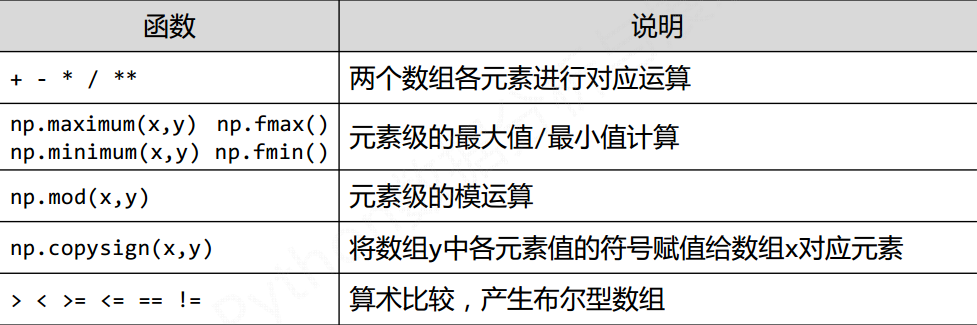
3) NumPy二元函数
基本理念是将数组当做一个元素进行处理表示, 不具体理会具体实现
可以使用常用的表示符来表示
3 NumPy的数据存取与函数
3.1 CSV文件存取
CSV(Comma-Separated Value, 逗号分割值)
CSV是一种常见的文件格式, 用来存储批量数据
主要是用于存储一维或者二维数据
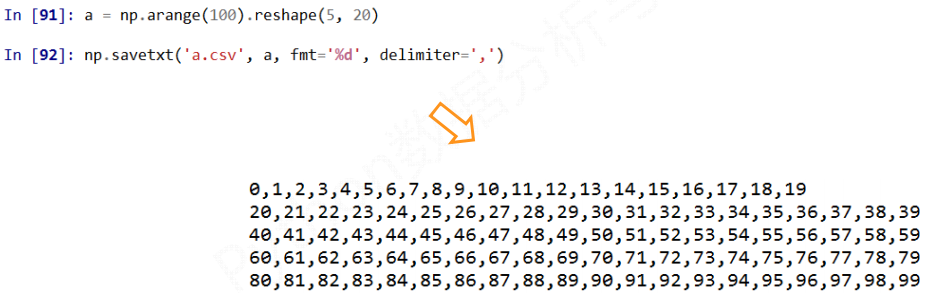
1) 写入CSV文件
np.savetxt(frame, array, fmt="%.18e", delimiter=None)
frame: 文件, 字符串或产生器, 也可以是.gz或.bz2的压缩文件
array: 存入文件的数组
fmt: 写入文件的格式, 默认是%.18e也就是保留小数点后18位的科学计数法, 如%d %.2f %.18e
delimiter: 分割字符串, 默认是任何空格

2) 读入CSV文件
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
frame: 文件, 字符串或产生器, 也可以是.gz或.bz2的压缩文件
dtype: 数据类型, 可选
delimiter: 分割字符串, 默认是任何空格
unpack: 如何True, 读入属性将分别写入不同变量

CSV文件的局限性
CSV只能有效存储一维和二维数组
3.2 多维数据的存取
多维数据的存储用tofile
1) 多维数据的存储
a.tofile(frame, sep='', format='%s')
frame: 文件, 字符串
sep: 数据分割字符串,如果是空串,写入文件为二进制
format: 写入数据的格式
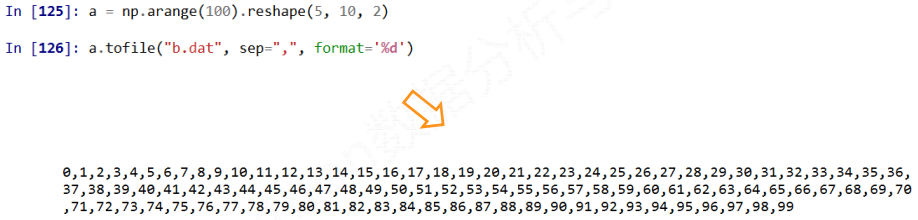
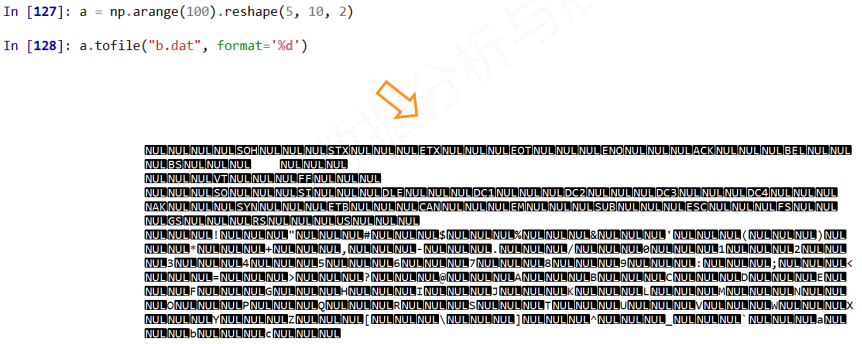
指定分割符的时候, 打开保存的文件是能够阅读的
如果不指定分隔符, 则保存的是二进制数据, 保存二进制的时候更加的省存储空间
一般来说, 保存的文件用.dat格式, 也就是文件格式
2) 多维数据的读取
np.fromfile(frame, dtype=float, count=‐, sep='')
frame: 文件, 字符串
dtype: 读取的数据类型, 默认是所有数据类型
count: 读入元素个数, -1表示读入整个文件, 需要部分的话就需要写读入的数量
sep: 数据分割字符串, 如果是空串, 读入文件为二进制

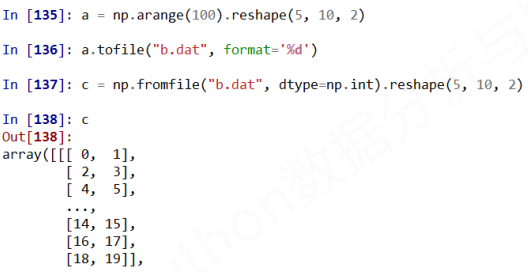
注意事项
由于读入之后维度信息丢失, 读完之后就是一个纯一维数组
因此, 该方法需要读取时知道存入文件时数组的维度和元素类型
解决办法是再写一个元数据文件存储丢失的维度信息和元素类型, 这在存储大量的数据的时候还是很有效的
因此, 一般来说tofile()和fromfile()需要配合使用
3) NumPy提供的便捷文件存取
np.save(fname, array)
np.savez(fname, array)
fname: 文件名,以.npy为扩展名,压缩扩展名为.npz
array: 数组变量
np.load(fname)
fname: 文件名,以.npy为扩展名,压缩扩展名为.npz
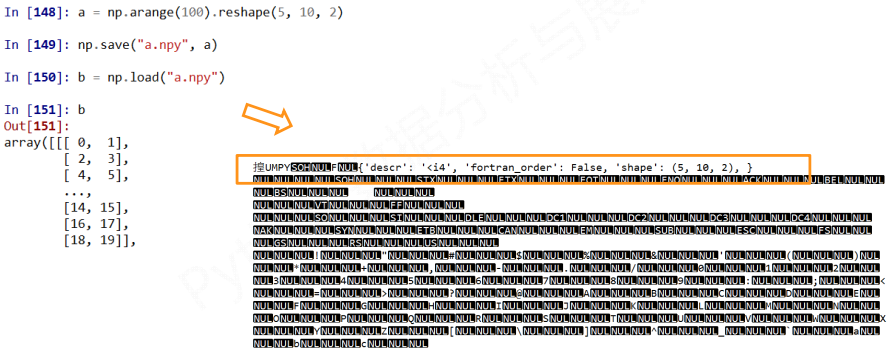
注意, 使用NumPy提供的便捷方法确实很够很快的存取而且, 保留了维度信息和数据类型信息, 能够很好的还原
保留的原因是因为在数据的首行保留了这些信息
但是这只能在NumPy中使用
要想在各个环境中交互, 还需要使用之前的tofile()和fromfile()
3.3 NumPy的随机数函数
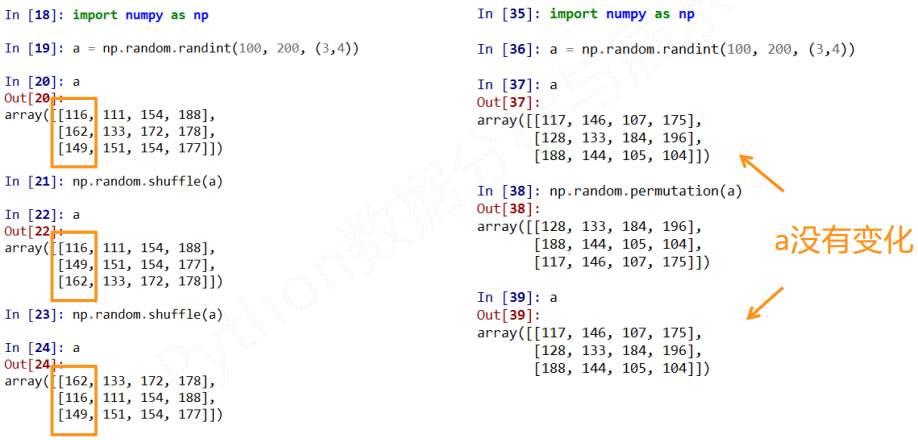
NumPy中的 np.random.* 可以为数组提供相应的随机数的功能
常见的随机数函数有:
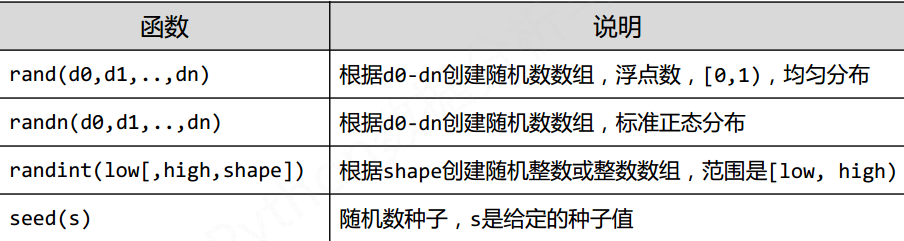


种子函数就是设定一个种子值, 下次使用的随机函数就是按照这个值来生成的, 相同的种子值随机出来的值是相同的

shuffle改变原来的数组
permutation不改变原来的数组
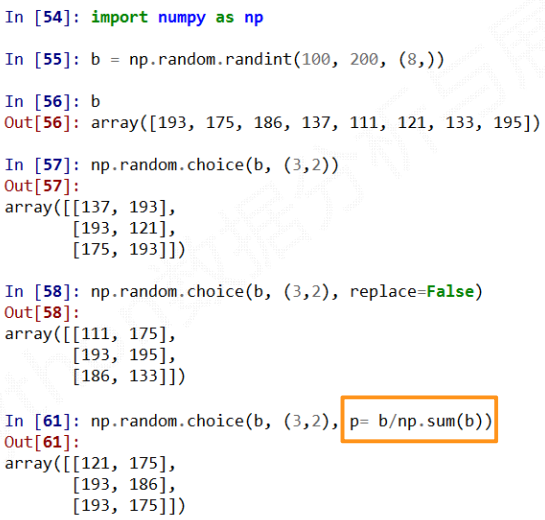
choice中replace默认为True, 也就是抽到的元素可以重复抽取. 设为False是, 则不可以重复抽取


3.4 NumPy的统计函数
NumPy直接提供统计类函数
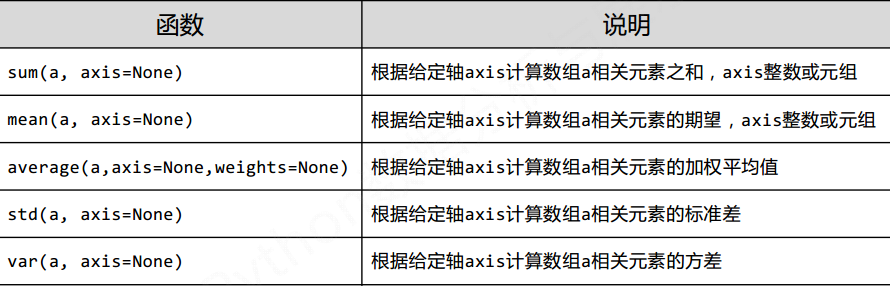
其中axis表示轴, 可以指定编号, 来指定计算第几维的数据进行计算
如shape为(3, 5)的数组, anis=0时, 是将每个数组对应的元素处理, anis=1就是处理里面的给个数组, anis=3超出边界


argmin()和argmax()获得的是, 将原数组处理成一维数组之后得到的index
可以使用unravel_index()传入shape来获得真是的index

3.5 NumPy的梯度函数
NumPy中有个著名的梯度函数
np.gradient(f)
计算数组f中元素的梯度, 当f为多维时, 返回每个维度梯度
梯度: 连续值之间的变化率, 即斜率
XY坐标轴连续三个X坐标对象的Y轴值: a, b, c, 其中, b的梯度是(c-a)/2
当在最末尾或者最开始时, 即a, b, ...的情况, a的梯度是(b-a); 当为..., a, b的时候, b的梯度为(b-a)
始终是都一个减去前一个


使用范围, 在处理图像, 声音的时候, 可以发现图像或者声音的边缘
4 图像的手绘效果
4.1 图像的数组表示
图像一般采用RGB色彩模式
RGB表示像素点的颜色有红(R)绿(G)蓝(B), 取值范围都是0~255
RGB形成的颜色包括了人类视力所能感知的所有颜色
处理图像是使用PIL处理
安装PIL是 pip install pillow
可以 from PIL import Image来导入图像类
一张图就可以用一个Image对象来表示
图像的数组表示
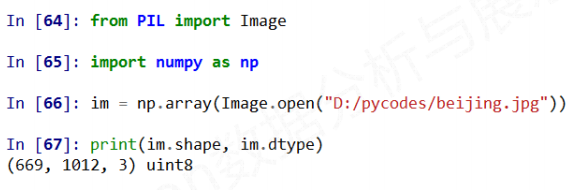
图像是一个三维数组, 维度分别是高度, 宽度, 像素RGB值
4.2 图像的变换
图像变换的流程
1) 读入图像
2) 处理得到的像素RGB数组
3) 保存为新文件
基本代码
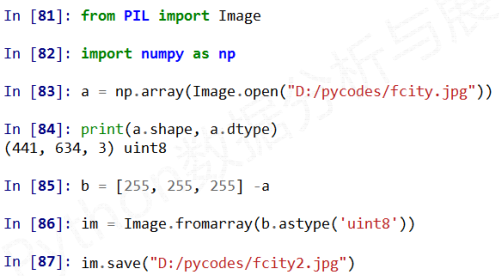
变换1

其中convert('L')可以将图片转为灰度图片, 此时生成的就是一个二维数组了
变换2
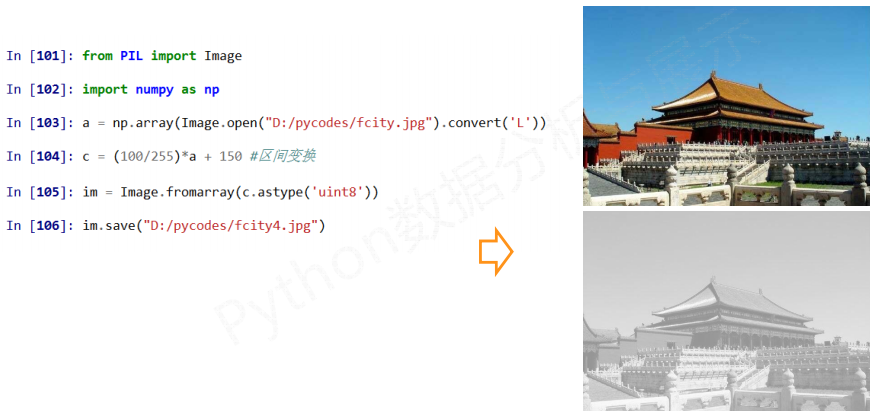
变换3
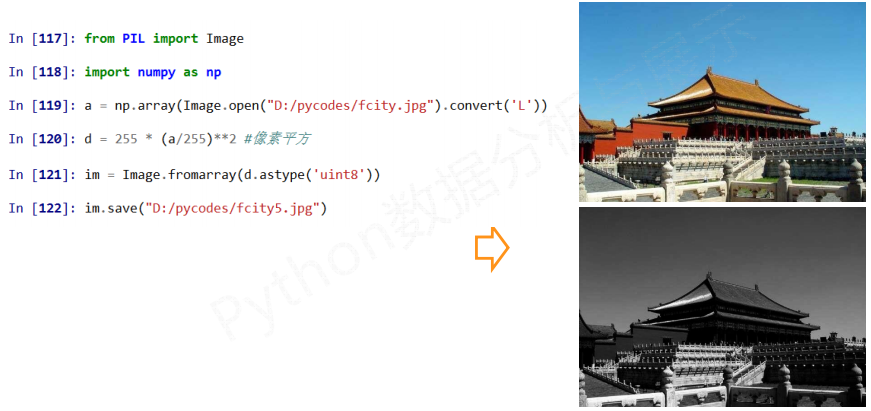
4.3 手绘效果
手绘的几个特征
1) 黑白灰
2) 边界线条较重
3) 相同或相近色彩趋于白色
4) 略有光源效果
数据表示Numpy的更多相关文章
- 数据分析与展示——NumPy库入门
这是我学习北京理工大学嵩天老师的<Python数据分析与展示>课程的笔记.嵩老师的课程重点突出.层次分明,在这里特别感谢嵩老师的精彩讲解. NumPy库入门 数据的维度 维度是一组数据的组 ...
- 数据分析——numpy
DIKW DATA-->INFOMATION-->KNOWLEDGE-->WISDOM 数据-->信息-->知识-->智慧 爬虫-->数据库-->数据分 ...
- 第一周——数据分析之表示 —— Numpy入门
数据的维度 从一个数据到一组数据 一个数据:表达一个含义 一组数据:表达一个或者多个含义 维度:一组数据的组织形式 一维数据 由对等关系的有序或者无序数据构成,采用线性方式组织,对应列表.数组和集合等 ...
- 数据分析之Numpy库入门
1.列表与数组 在python的基础语言部分,我们并没有介绍数组类型,但是像C.Java等语言都是有数组类型的,那python中的列表和数组有何区别呢? 一维数据:都表示一组数据的有序结构 区别: 列 ...
- Python数据分析与展示(1)-数据分析之表示(1)-NumPy库入门
Numpy库入门 从一个数据到一组数据 维度:一组数据的组织形式 一维数据:由对等关系的有序或无序数据构成,采用线性方式组织. 可用类型:对应列表.数组和集合 不同点: 列表:数据类型可以不同 数组: ...
- 《机器学习实战》---NumPy
NumPy库函数基础: 机器学习算法涉及很多线性代数知识. NumPy库中有很多线性代数计算. 之所以用到线性代数只是为了简化不同的数据点上执行的相同数学运算.将数据表示为矩阵形式, 只需要执行简单的 ...
- Python开发:NumPy学习(一)ndarray数组
一.数据维度 一个数据表达一个含义,一组数据表达一个或多个含义. 数据维度概念:一组数据的组织形式,其中有一维数据.二维数据.多维数据.高维数据. 1. 一维数据 一维数据由对等关系的有序或无序数据 ...
- Numpy的介绍与基本使用方法
1.什么是Numpy numpy官方文档:https://docs.scipy.org/doc/numpy/reference/?v=20190307135750 NumPy是一个功能强大的Pytho ...
- NumPy之:标量scalars
目录 简介 scalar类型的层次结构 内置Scalar类型 boolean Integers Unsigned integers Floating-point numbers Complex flo ...
随机推荐
- 【原创】关于jquery实现格式化时间
//js格式化时间,参数jsonDate可以是后台数据 function jsonDateFormat(jsonDate) { try { var date = new Date(parseInt(j ...
- 在C++ 程序中调用被C 编译器编译后的函数,为什么要加extern “C”
首先,作为extern是C/C++语言中表明函数和全局变量作用范围(可见性)的关键字,该关键字告诉编译器,其声明的函数和变量可以在本模块或其它模块中使用. 通常,在模块的头文件中对本模块提供给其它模块 ...
- 第九讲_图像生成 Image Captioning
第九讲_图像生成 Image Captioning 生成式对抗网络 Generative Adversarial network 学习数据分布:概率密度函数估计+数据样本生成 生成式模型是共生关系,判 ...
- 启动eclipse时出现“Failed to load the JNI shared library jvm.dll”错误及解决-及eclipse版本查看
启动eclipse时出现“Failed to load the JNI shared library jvm.dll”错误及解决-及eclipse版本查看 学习了:https://www.cnblog ...
- Data Binding Guide——google官方文档翻译(上)
android引入MVVM框架时间还不长,眼下还非常少有应用到app中的.但它是比較新的技术,使用它来搭建项目能省非常多代码,并且能使用代码架构比較清晰.本篇文章是我在学习MVVM时翻译的.篇幅比較长 ...
- 【java读书笔记】——Collection集合之六大接口(Collection、Set、List、Map、Iterator和Comparable)
两个月之前准备软考时,简单的从理论上总结了最经常使用的数据结构和算法,比方:线性表,链表,图.在进行java开发时,jdk为我们提供了一系列对应的类来实现主要的数据结构.jdk所提供的容器API位于j ...
- Android的logger机制分析
分析安卓的Logger机制 一.概述 Logger机制是在Android系统中提供的一个轻量级的日志系统,这个日志系统是以驱动程序的形式在内核空间实现的,在用户空间分别提供了Java接口和C/C++接 ...
- VueJS数据绑定文本显示:{{message}}
HTML <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <titl ...
- 三行代码实现.NET MVC统计显示页面的执行时间 超简单的实现方法 分析页面执行效率
三行代码实现.NET MVC统计显示页面的执行时间 超简单的实现方法 分析页面执行效率 博客页脚处添加了页面执行时间统计显示,如下图所示,也可以直接查看网页页脚处. 实现方法非常简单,只需三行代 ...
- 2014年8月25日,收藏家和杀手——面向对象的C++和C(一)
近期事情特别多,睡眠也都非常晚,有点精神和身体混乱的感觉,所以想写写技术分析文章.让两者的我都调整一下.这篇技术分析文章是一直想写的,当前仅仅是开篇,有感觉的时候就写写,属于拼凑而成,兴许的篇章没有时 ...