主成分分析(PCA)与SVD奇异值分解
假设原始数据是10(行,样例数,y1-y10)*10(列,特征数x1-x10)的(10个样例,每样例对应10个特征)
(1)、分别求各特征(列)的均值并对应减去所求均值。

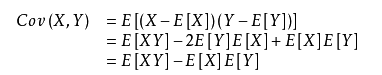
(3)、求协方差阵的特征值和特征向量。
(4)、将特征值按照从大到小排序,选择其中最大的k个。将其对应的k个特征向量分别作为列向量组成特征向量矩阵。
(5)、将样本点投影到选取的k个特征向量上。这里需要捋一捋,若原始数据中样例数为m,特征数为n,减去均值后的样本矩阵仍为MatrixDATA(m,n); 协方差矩阵是C(n,n);特征向量矩阵为EigenMatrix(n,k); 投影可得: FinalDATA(m,k)=MatrixDATA(m,n) * EigenMatrix(n,k) 。
这样,原始数据就由原来的n维特征变成了k维,而k维数据是原数据的线性组合。
链接:https://www.zhihu.com/question/38417101/answer/94338598
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1、为什么求特征协方差的特征向量就是最理想的k维向量?
2、投影的过程意义在于?
【对于第一点】 可以通过最大方差理论解释。处理信号时,信噪比定义为10倍lg信号与噪声功率之比,这个用非周期的数字信号平均功率来解释比较直观(模拟信号只要做积分即可),在观测时间序列有N个时间点,将每个时间点的幅值的平方作和,再将总和除以点数N,信噪比其实就是信号与噪声的方差比。而一般认为,信号具有较大的方差(包含信息),噪声具有较小的方差。所以我们认为的最好的k个特征应该尽可能的包含有用信号,亦即信号损失尽可能小。故在将n维特征转换为k维后,取的是前k个较大方差的特征方向。下面 我们来看一下投影的详细过程(图片引自JerryLead blog)
<img src="https://pic1.zhimg.com/2d91f456c0c6e6661979ceb684952f90_b.png" data-rawwidth="504" data-rawheight="352" class="origin_image zh-lightbox-thumb" width="504" data-original="https://pic1.zhimg.com/2d91f456c0c6e6661979ceb684952f90_r.png">u是直线的斜率也是直线的方向向量,而且是 u是直线的斜率也是直线的方向向量,而且是单位向量。样本点x在u上的投影点距离远点的距离是两向量内积,
u是直线的斜率也是直线的方向向量,而且是单位向量。样本点x在u上的投影点距离远点的距离是两向量内积,
这里u为单位向量,故内积即为投影的长度。
考虑m个样本点都做u上的投影,故样本在u上投影后的点的方差(只考虑u方向,参照原点)可以计算如下:
前面样本点经过预处理,每一维特征均值为0,故投影到u上的样本点(只有一个到原点的距离值)的均值仍然是0。方差计算如下
<img data-rawwidth="367" data-rawheight="134" src="https://pic4.zhimg.com/ba5b7495e4645991bcf24532d0f57757_b.png" class="content_image" width="367">
u为单位向量,中间部分
<img src="https://pic1.zhimg.com/1e1af9db7d50566fec4b550dc6e3984c_b.png" data-rawwidth="116" data-rawheight="54" class="content_image" width="116">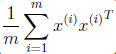 其实相当于样本的特征协方差矩阵,这里我要详细的解释一下为什么。
其实相当于样本的特征协方差矩阵,这里我要详细的解释一下为什么。
还记得样本的特征协方差矩阵吗?特征协方差矩阵中非对角线元素的求法为cov(x1,x2) = E{[(x1-E(x1)][x2-E(x2)]},也就是两个特征所对应的样本值序列分别减去各自均值后的乘积的均值(因为是无偏估计,这里计算均值是除以m-1而非m)。
理一理我们手头上的数据: m个样例; n个特征<img src="https://pic3.zhimg.com/df43c1f76c7e0cacc6c0394af8aad222_b.png" data-rawwidth="159" data-rawheight="27" class="content_image" width="159">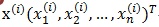
在求特征协方差矩阵时的x1,x2,....xn是对应的特征列。是Data中的列,这里不要和行
<img src="https://pic3.zhimg.com/df43c1f76c7e0cacc6c0394af8aad222_b.png" data-rawwidth="159" data-rawheight="27" class="content_image" width="159">搞混淆哦,如果我们要求特征x1的方差D(x1)=搞混淆哦,如果我们要求特征x1的方差D(x1)=; 特征x1,x2的协方差Cov(x1,x2)=
。其余以此类推。再看<img src="https://pic1.zhimg.com/1e1af9db7d50566fec4b550dc6e3984c_b.png" data-rawwidth="116" data-rawheight="54" class="content_image" width="116">注意这里最为重要,需要理解。 公式中是列向量与行向量的乘积(结果是一个矩阵),对m个矩阵做
注意这里最为重要,需要理解。 公式中是列向量与行向量的乘积(结果是一个矩阵),对m个矩阵做结果是一个矩阵。我们不妨试着将这个矩阵乘开看一看是什么鬼。

我们再来看下面的推导:
用表示
,
表示
.那么式子
=
就可以写成:
u是单位向量,,对
式两边左乘u有,
也就是
;
是我们的特征协方差矩阵,故
也就是该矩阵的特征值u就是特征向量。故
=
的最大值就是
的最大值,也就是
的最大值。
PCA最终保留的前k个特征值就是对应的前k大的方差的特征方向。
【对于第二点】 可以看到投影过程为: FinalDATA(m,k)=MatrixDATA(m,n) * EigenMatrix(n,k)
试思考:1,矩阵右乘列向量-- 得到新的列向量为矩阵各列的线性组合
2,矩阵A右乘矩阵B(k列)-- 得到新的矩阵,该矩阵每一列均为A矩阵各列做k次不同的线性组合的结果。这也就是楼上说的新的特征(k列)是原特征(n列)线性组合的结果。如果非要看新的k维是原来的特征如何得到的,可以把特征协方差矩阵的特征向量求取出来,对应看出如何做的线性组合。
关于线性组合与投影:为什么投影可以用线性组合或者说是矩阵相乘来实现呢?
这里涉及坐标空间的变换,把数据从原空间投影到选择的k维特征空间中。这里解释起来比较多,姑且就理解为一种线性映射吧,有时间再来补充。实际上k<n故
把数据从原空间投影到选择的k维特征空间中会损失掉一部分的信息(后n-k个特征向量对应的信息),这也是主成分分析降维的结果。
奇异值与主成分分析(PCA):
主成分分析在上一节里面也讲了一些,这里主要谈谈如何用SVD去解PCA的问题。PCA的问题其实是一个基的变换,使得变换后的数据有着最大的方差。方差的大小描述的是一个变量的信息量,我们在讲一个东西的稳定性的时候,往往说要减小方差,如果一个模型的方差很大,那就说明模型不稳定了。但是对于我们用于机器学习的数据(主要是训练数据),方差大才有意义,不然输入的数据都是同一个点,那方差就为0了,这样输入的多个数据就等同于一个数据了。以下面这张图为例子:

这个假设是一个摄像机采集一个物体运动得到的图片,上面的点表示物体运动的位置,假如我们想要用一条直线去拟合这些点,那我们会选择什么方向的线呢?当然是图上标有signal的那条线。如果我们把这些点单纯的投影到x轴或者y轴上,最后在x轴与y轴上得到的方差是相似的(因为这些点的趋势是在45度左右的方向,所以投影到x轴或者y轴上都是类似的),如果我们使用原来的xy坐标系去看这些点,容易看不出来这些点真正的方向是什么。但是如果我们进行坐标系的变化,横轴变成了signal的方向,纵轴变成了noise的方向,则就很容易发现什么方向的方差大,什么方向的方差小了。
一般来说,方差大的方向是信号的方向,方差小的方向是噪声的方向,我们在数据挖掘中或者数字信号处理中,往往要提高信号与噪声的比例,也就是信噪比。对上图来说,如果我们只保留signal方向的数据,也可以对原数据进行不错的近似了。
PCA的全部工作简单点说,就是对原始的空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第1、2个轴正交的平面中方差最大的,这样假设在N维空间中,我们可以找到N个这样的坐标轴,我们取前r个去近似这个空间,这样就从一个N维的空间压缩到r维的空间了,但是我们选择的r个坐标轴能够使得空间的压缩使得数据的损失最小。
还是假设我们矩阵每一行表示一个样本,每一列表示一个feature,用矩阵的语言来表示,将一个m * n的矩阵A的进行坐标轴的变化,P就是一个变换的矩阵从一个N维的空间变换到另一个N维的空间,在空间中就会进行一些类似于旋转、拉伸的变化。

而将一个m * n的矩阵A变换成一个m * r的矩阵,这样就会使得本来有n个feature的,变成了有r个feature了(r < n),这r个其实就是对n个feature的一种提炼,我们就把这个称为feature的压缩。用数学语言表示就是:

但是这个怎么和SVD扯上关系呢?之前谈到,SVD得出的奇异向量也是从奇异值由大到小排列的,按PCA的观点来看,就是方差最大的坐标轴就是第一个奇异向量,方差次大的坐标轴就是第二个奇异向量…我们回忆一下之前得到的SVD式子:

在矩阵的两边同时乘上一个矩阵V,由于V是一个正交的矩阵,所以V转置乘以V得到单位阵I,所以可以化成后面的式子

将后面的式子与A * P那个m * n的矩阵变换为m * r的矩阵的式子对照看看,在这里,其实V就是P,也就是一个变化的向量。这里是将一个m * n 的矩阵压缩到一个m * r的矩阵,也就是对列进行压缩,如果我们想对行进行压缩(在PCA的观点下,对行进行压缩可以理解为,将一些相似的sample合并在一起,或者将一些没有太大价值的sample去掉)怎么办呢?同样我们写出一个通用的行压缩例子:

这样就从一个m行的矩阵压缩到一个r行的矩阵了,对SVD来说也是一样的,我们对SVD分解的式子两边乘以U的转置U’

这样我们就得到了对行进行压缩的式子。可以看出,其实PCA几乎可以说是对SVD的一个包装,如果我们实现了SVD,那也就实现了PCA了,而且更好的地方是,有了SVD,我们就可以得到两个方向的PCA,如果我们对A’A进行特征值的分解,只能得到一个方向的PCA。
主成分分析(PCA)与SVD奇异值分解的更多相关文章
- 机器学习降维方法概括, LASSO参数缩减、主成分分析PCA、小波分析、线性判别LDA、拉普拉斯映射、深度学习SparseAutoEncoder、矩阵奇异值分解SVD、LLE局部线性嵌入、Isomap等距映射
机器学习降维方法概括 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u014772862/article/details/52335970 最近 ...
- 降维方法PCA与SVD的联系与区别
在遇到维度灾难的时候,作为数据处理者们最先想到的降维方法一定是SVD(奇异值分解)和PCA(主成分分析). 两者的原理在各种算法和机器学习的书籍中都有介绍,两者之间也有着某种千丝万缕的联系.本文在简单 ...
- 机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)
1. 动机一:数据压缩 第二种类型的 无监督学习问题,称为 降维.有几个不同的的原因使你可能想要做降维.一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快 ...
- 主成分分析(PCA)原理及推导
原文:http://blog.csdn.net/zhongkejingwang/article/details/42264479 什么是PCA? 在数据挖掘或者图像处理等领域经常会用到主成分分析,这样 ...
- 『科学计算_理论』SVD奇异值分解
转载请声明出处 SVD奇异值分解概述 SVD不仅是一个数学问题,在工程应用中的很多地方都有它的身影,比如前面讲的PCA,掌握了SVD原理后再去看PCA那是相当简单的,在推荐系统方面,SVD更是名声大噪 ...
- 数据预处理:PCA,SVD,whitening,normalization
数据预处理是为了让算法有更好的表现,whitening.PCA.SVD都是预处理的方式: whitening的目标是让特征向量中的特征之间不相关,PCA的目标是降低特征向量的维度,SVD的目标是提高稀 ...
- 机器学习之主成分分析PCA原理笔记
1. 相关背景 在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律.多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的 ...
- 浅谈 PCA与SVD
前言 在用数据对模型进行训练时,通常会遇到维度过高,也就是数据的特征太多的问题,有时特征之间还存在一定的相关性,这时如果还使用原数据训练模型,模型的精度会大大下降,因此要降低数据的维度,同时新数据的特 ...
- 机器学习实战基础(二十三):sklearn中的降维算法PCA和SVD(四) PCA与SVD 之 PCA中的SVD
PCA中的SVD 1 PCA中的SVD哪里来? 细心的小伙伴可能注意到了,svd_solver是奇异值分解器的意思,为什么PCA算法下面会有有关奇异值分解的参数?不是两种算法么?我们之前曾经提到过,P ...
- 深度学习入门教程UFLDL学习实验笔记三:主成分分析PCA与白化whitening
主成分分析与白化是在做深度学习训练时最常见的两种预处理的方法,主成分分析是一种我们用的很多的降维的一种手段,通过PCA降维,我们能够有效的降低数据的维度,加快运算速度.而白化就是为了使得每个特征能有同 ...
随机推荐
- JAVA Eclipse开发Android程序如何自定义图标
直接用做好的png图片替换res的所有分辨率的lc_launcher.png图片 注意到不同文件夹有不同的分辨率,直接把png图片做成最大的替换掉即可,不管小的. drawable-xxhdpi ...
- 对国外某hotel的内网域简单渗透
Penetration Testing不单单是一个博客,更热衷于技术分享的平台. 本文将讲述对国外某一hotel的渗透测试,让更多的人安全意识得到提高,有攻才有防,防得在好,也有疏忽的地方,这就是为啥 ...
- hdu1394 Minimum Inversion Number(最小逆序数)
Minimum Inversion Number Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/32768K (Java/O ...
- struts2获取文件真实路径
CreateTime--2017年8月25日15:59:33 Author:Marydon struts2获取文件真实路径 需要导入: import java.io.FileNotFoundExc ...
- ViewPager+Fragment 滑动菜单效果 实现步骤
1.xml中引用ViewPager <android.support.v4.view.ViewPager android:id="@+id/viewPa ...
- \\s+ split替换
出自: http://www.tuicool.com/articles/vy2ymm 详解 "\\s+" 正则表达式中\s匹配任何空白字符,包括空格.制表符.换页符等等, 等价于[ ...
- 自己定义ViewGroup控件(二)----->流式布局进阶(二)
main.xml <?xml version="1.0" encoding="utf-8"? > <com.example.SimpleLay ...
- Appium python Uiautomator2 多进程问题
appium更新uiautomator后可以获取tost了,大家都尝试,课程中也讲解了,但是这些跑的时候都在单机上,当我们多机并发的时候会出现一个端口问题,因为我们appium最后会调用uiautom ...
- git 工具 - 子模块(submodule)
From: https://git-scm.com/book/zh/v2/Git-%E5%B7%A5%E5%85%B7-%E5%AD%90%E6%A8%A1%E5%9D%97 子模块 有种情况我们经常 ...
- JS实现图片无缝滚动特效;附addEventListener()方法、offsetLeft和offsetWidth属性。
一:html部分 <body> <input id="btn1" type="button" value="向左"> ...