Hadoop2.6.0的FileInputFormat的任务切分原理分析(即如何控制FileInputFormat的map任务数量)
前言
首先确保已经搭建好Hadoop集群环境,可以参考《Linux下Hadoop集群环境的搭建》一文的内容。我在测试mapreduce任务时,发现相比于使用Job.setNumReduceTasks(int)控制reduce任务数量而言,控制map任务数量一直是一个困扰我的问题。好在经过很多摸索与实验,终于梳理出来,希望对在工作中进行Hadoop进行性能调优的新人们有个借鉴。本文只针对FileInputFormat的任务划分进行分析,其它类型的InputFormat的划分方式又各有不同。虽然如此,都可以按照本文类似的方法进行分析和总结。
为了简便起见,本文以Hadoop2.6.0自带的word count例子为例,进行展开。
wordcount
我们首先准备好wordcount所需的数据,一共有两份文件,都位于hdfs的/wordcount/input目录下:
这两个文件的内容分别为:
On the top of the Crumpretty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
和
But his face you could not see,
On account of his Beaver Hat.
有关如何操作hdfs并准备好数据的细节,本文不作赘述。
现在我们不作任何性能优化(不增加任何配置参数),然后执行hadoop-mapreduce-examples子项目(有关此项目介绍,可以阅读《Hadoop2.6.0子项目hadoop-mapreduce-examples的简单介绍》一文)中自带的wordcount例子:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6..jar wordcount /wordcount/input /wordcount/output/result1
当然也可以使用朴素的方式运行wordcount例子:
hadoop org.apache.hadoop.examples.WordCount -D mapreduce.input.fileinputformat.split.maxsize= /wordcount/input /wordcount/output/result1
最后执行的结果在hdfs的/wordcount/output/result1目录下:
执行结果可以查看/wordcount/output/result1/part-r-00000的内容:
第一次优化
wordcount例子,查看运行结果不是本文的目的。在执行wordcount例子时,在任务运行信息中可以看到创建的map及reduce任务的数量: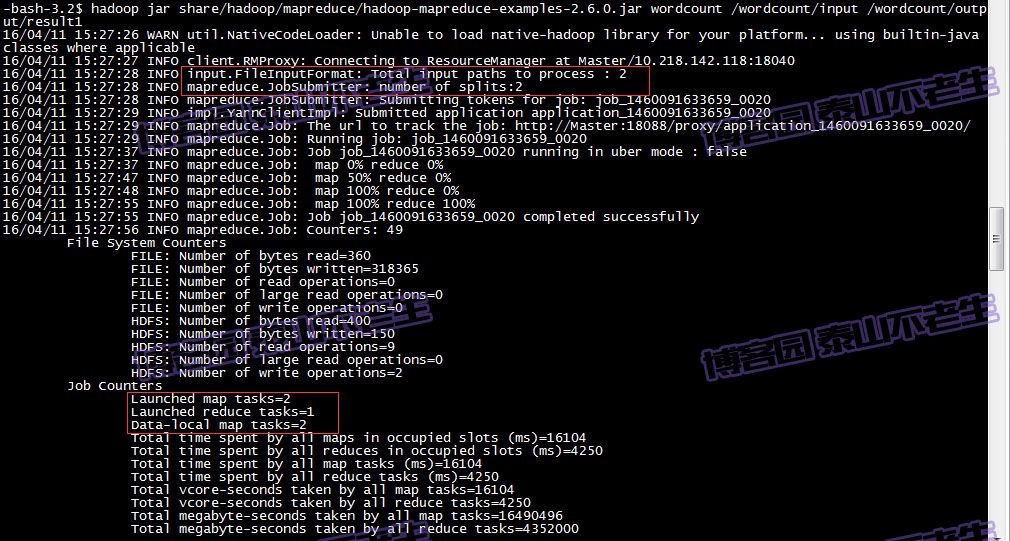
可以看到FileInputFormat的输入文件有2个,JobSubmitter任务划分的数量是2,最后产生的map任务数量也是2,看到这我们可以猜想由于我们提供了两个输入文件,所以会有2个map任务。我们此处姑且不论这种猜测正确与否,现在我们打算改变map任务的数量。通过查看文档,很多人知道使用mapreduce.job.maps参数可以快速修改map任务的数量,事实果真如此?让我们先来实验一番,输入以下命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6..jar wordcount -D mapreduce.job.maps= /wordcount/input /wordcount/output/result2
执行以上命令后,观察输出的信息,与之前未添加mapreduce.job.maps参数的输出信息几乎没有变化。难道Hadoop的实现人员开了一个玩笑,亦或者这是一个bug?我们先给这个问题在我们的大脑中设置一个检查点,最后再来看看究竟是怎么回事。
第二次优化
用mapreduce.job.maps调整map任务数量没有见效,我们翻翻文档,发现还有mapreduce.input.fileinputformat.split.minsize参数,它可以控制map任务输入划分的最小字节数。这个参数和mapreduce.input.fileinputformat.split.maxsize通常配合使用,后者控制map任务输入划分的最大字节数。我们目前只调整mapreduce.input.fileinputformat.split.minsize的大小,划分最小的尺寸变小是否预示着任务划分数量变多?来看看会发生什么?输入以下命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6..jar wordcount -D mapreduce.input.fileinputformat.split.minsize= /wordcount/input /wordcount/output/result3
执行以上命令后,观察输出信息,依然未发生改变。好吧,弟弟不给力,我们用它的兄弟参数mapreduce.input.fileinputformat.split.maxsize来控制。如果我们将mapreduce.input.fileinputformat.split.maxsize改得很小,会怎么样?输入以下命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6..jar wordcount -D mapreduce.input.fileinputformat.split.maxsize= /wordcount/input /wordcount/output/result4
这是的信息有了改变,我们似乎取得了想要的结果:

呵呵,任务划分成了177个,想想也是,我们把最大的划分字节数仅仅设置为1字节。接着往下看确实执行了177个map任务: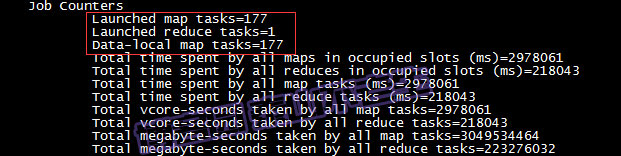
我们还可以通过Web UI观察map任务所分配的Container。首先查看Slave1节点上分配的Container情况: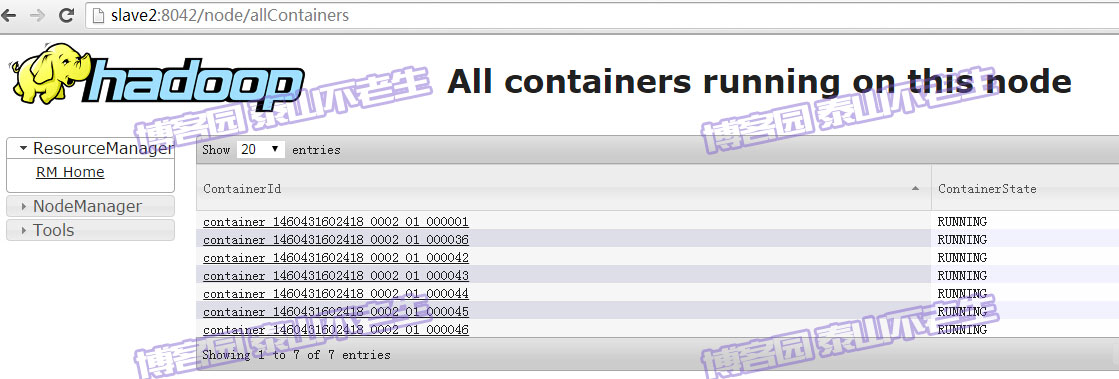
再来看看Slave2节点上分配的Container情况:
确实说明最多有15个Container分配给当前作业执行map任务。由于在YARN中yarn.nodemanager.resource.cpu-vcores参数的默认值是8,所以Slave1和Slave2两台机器上的虚拟cpu总数是16,由于ResourceManager会为mapreduce任务分配一个Container给ApplicationMaster(即MrAppMaster),所以整个集群只剩余了15个Container用于ApplicationMaster向NodeManager申请和运行map任务。
第三次优化
阅读文档我们知道dfs.blocksize可以控制块的大小,看看这个参数能否发挥作用。为便于测试,我们首先需要修改hdfs-site.xml中dfs.blocksize的大小为10m(最小就只能这么小,Hadoop限制了参数单位至少是10m)。
<property>
<name>dfs.blocksize</name>
<value>10m</value>
</property>
然后,将此配置复制到集群的所有NameNode和DataNode上。为了使此配置在不重启的情况下生效,在NameNode节点上执行以下命令:
hadoop dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
我们使用以下命令查看下系统内的文件所占用的blocksize大小:
hadoop dfs -stat "%b %n %o %r %y" /wordcount/input/quangle*
输出结果如下:
可以看到虽然quangle.txt和quangle2.txt的字节数分别是121字节和56字节,但是在hdfs中这两个文件的blockSize已经是10m了。现在我们试试以下命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6..jar wordcount /wordcount/input /wordcount/output/result5
观察输出信息,发现没有任何效果。
源码分析
经过以上3次不同实验,发现只有mapreduce.input.fileinputformat.split.maxsize参数确实影响了map任务的数量。现在我们通过源码分析,来一探究竟吧。
首先我们看看WordCount例子的源码,其中和任务划分有关的代码如下:
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
我们看到使用的InputFormat是FileOutputFormat,任务执行调用了Job的waitForCompletion方法。waitForCompletion方法中真正提交job的代码如下:
public boolean waitForCompletion(boolean verbose) throws IOException, InterruptedException, ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
// 省略本文不关心的代码
return isSuccessful();
}
这里的submit方法的实现如下:
public void submit() throws IOException, InterruptedException, ClassNotFoundException {
// 省略本文不关心的代码</span>
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
submit方法首先创建了JobSubmitter实例,然后异步调用了JobSubmitter的submitJobInternal方法。JobSubmitter的submitJobInternal方法有关划分任务的代码如下:
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
writeSplits方法的实现如下:
private int writeSplits(org.apache.hadoop.mapreduce.JobContext job,
Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
if (jConf.getUseNewMapper()) {
maps = writeNewSplits(job, jobSubmitDir);
} else {
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}
由于WordCount使用的是新的mapreduce API,所以最终会调用writeNewSplits方法。writeNewSplits的实现如下:
private <T extends InputSplit>
int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
Configuration conf = job.getConfiguration();
InputFormat<?, ?> input =
ReflectionUtils.newInstance(job.getInputFormatClass(), conf); List<InputSplit> splits = input.getSplits(job);
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]); // sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
return array.length;
}
writeNewSplits方法中,划分任务数量最关键的代码即为InputFormat的getSplits方法(提示:大家可以直接通过此处的调用,查看不同InputFormat的划分任务实现)。根据前面的分析我们知道此时的InputFormat即为FileOutputFormat,其getSplits方法的实现如下:
public List<InputSplit> getSplits(JobContext job) throws IOException {
Stopwatch sw = new Stopwatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.elapsedMillis());
}
return splits;
}
getFormatMinSplitSize方法固定返回1,getMinSplitSize方法实际就是mapreduce.input.fileinputformat.split.minsize参数的值(默认为1),那么变量minSize的大小为mapreduce.input.fileinputformat.split.minsize与1之间的最大值。
getMaxSplitSize方法实际是mapreduce.input.fileinputformat.split.maxsize参数的值,那么maxSize即为mapreduce.input.fileinputformat.split.maxsize参数的值。
由于我的试验中有两个输入源文件,所以List<FileStatus> files = listStatus(job);方法返回的files列表的大小为2。
在遍历files列表的过程中,会获取每个文件的blockSize,最终调用computeSplitSize方法计算每个输入文件应当划分的任务数。computeSplitSize方法的实现如下:
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
因此我们知道每个输入文件被划分的公式如下:
map任务要划分的大小(splitSize )=(maxSize与blockSize之间的最小值)与minSize之间的最大值
bytesRemaining 是单个输入源文件未划分的字节数
根据getSplits方法,我们知道map任务划分的数量=输入源文件数目 * (bytesRemaining / splitSize个划分任务+bytesRemaining不能被splitSize 整除的剩余大小单独划分一个任务 )
总结
根据源码分析得到的计算方法和之前的优化结果,我们最后总结一下:
对于第一次优化,由于FileOutputFormat压根没有采用mapreduce.job.maps参数指定的值,所以它当然不会有任何作用。
对于第二次优化,minSize几乎由mapreduce.input.fileinputformat.split.minsize控制;mapreduce.input.fileinputformat.split.maxsize默认的大小是Long.MAX_VALUE,所以blockSize即为maxSize与blockSize之间的最小值;blockSize的默认大小是128m,所以blockSize与值为1的mapreduce.input.fileinputformat.split.minsize之间的最大值为blockSize,即map任务要划分的大小的大小与blockSize相同。
对于第三次优化,虽然我们将blockSize设置为10m(最小也只能这么小了,hdfs对于block大小的最低限制),根据以上公式maxSize与blockSize之间的最小值必然是blockSize,而blockSize与minSize之间的最大值也必然是blockSize。说明blockSize实际上已经发挥了作用,它决定了splitSize的大小就是blockSize。由于blockSize大于bytesRemaining,所以并没有对map任务数量产生影响。
针对以上分析,我们用更加容易理解的方式列出这些配置参数的关系:
当mapreduce.input.fileinputformat.split.maxsize > mapreduce.input.fileinputformat.split.minsize > dfs.blockSize的情况下,此时的splitSize 将由mapreduce.input.fileinputformat.split.minsize参数决定。
当mapreduce.input.fileinputformat.split.maxsize > dfs.blockSize > mapreduce.input.fileinputformat.split.minsize的情况下,此时的splitSize 将由dfs.blockSize配置决定。(第二次优化符合此种情况)
当dfs.blockSize > mapreduce.input.fileinputformat.split.maxsize > mapreduce.input.fileinputformat.split.minsize的情况下,此时的splitSize 将由mapreduce.input.fileinputformat.split.maxsize参数决定。
鸣谢
我在试验的过程中,遇到很多问题。但是很多问题在网络上都能找到,特此感谢在互联网上分享经验的同仁们。
后记:个人总结整理的《深入理解Spark:核心思想与源码分析》一书现在已经正式出版上市,目前京东、当当、天猫等网站均有销售,欢迎感兴趣的同学购买。
京东(现有满150减50活动)):http://item.jd.com/11846120.html
当当:http://product.dangdang.com/23838168.html
Hadoop2.6.0的FileInputFormat的任务切分原理分析(即如何控制FileInputFormat的map任务数量)的更多相关文章
- MapReduce的map个数调节 与 Hadoop的FileInputFormat的任务切分原理
在对日志等大表数据进行处理的时候需要人为地设置任务的map数,防止因map数过小导致集群资源被耗光.可根据大表的数据量大小设置每个split的大小. 例如设置每个split为500M: set map ...
- [置顶] Hadoop2.2.0中HDFS的高可用性实现原理
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障 ...
- hadoop之 Hadoop2.2.0中HDFS的高可用性实现原理
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障 ...
- Hadoop2.7.1配置NameNode+ResourceManager高可用原理分析
关于NameNode高可靠需要配置的文件有core-site.xml和hdfs-site.xml 关于ResourceManager高可靠需要配置的文件有yarn-site.xml 逻辑结构: Nam ...
- hadoop2.2.0伪分布式搭建3--安装Hadoop
3.1上传hadoop安装包 3.2解压hadoop安装包 mkdir /cloud #解压到/cloud/目录下 tar -zxvf hadoop-2.2.0.tar.gz -C /cloud/ 3 ...
- hadoop2.2.0伪分布式搭建
1.准备Linux环境 1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ...
- Hadoop2.2.0安装过程记录
1 安装环境1.1 客户端1.2 服务端1.3 安装准备 2 操作系统安装2.1.1 BIOS打开虚拟化支持2.1.2 关闭防火墙2.1.3 安装 ...
- Windows 8.0上Eclipse 4.4.0 配置CentOS 6.5 上的Hadoop2.2.0开发环境
原文地址:http://www.linuxidc.com/Linux/2014-11/109200.htm 图文详解Windows 8.0上Eclipse 4.4.0 配置CentOS 6.5 上的H ...
- Eclipse中部署hadoop2.3.0
1 eclipse中hadoop环境部署概览 eclipse 中部署hadoop包括两大部分:hdfs环境部署和mapreduce任务执行环境部署.一般hdfs环境部署比较简单,部署后就 可以在ecl ...
随机推荐
- Java基础常见英语词汇
Java基础常见英语词汇(共70个) ['ɔbdʒekt] ['ɔ:rientid]导向的 ['prəʊɡræmɪŋ]编程 OO: object ...
- 数组中第K小的数字(Google面试题)
http://ac.jobdu.com/problem.php?pid=1534 题目1534:数组中第K小的数字 时间限制:2 秒 内存限制:128 兆 特殊判题:否 提交:1120 解决:208 ...
- MyEclipse 8.5汉化教程
汉化包下载:http://yunpan.cn/QIUaVS2CU5wCd 1.解压MyEclipse中的language文件夹 以我的安装目录为例,我的MyEclipse8.5的安装在D:盘下.将解压 ...
- document.createElement()方法
document.createElement()是在对象中创建一个对象,主要和appendChild() 方法或者insertBefore() 方法联合使用. appendChild() 方法在节点的 ...
- iOS开发XCODE5 SVN配置 使用办法 (转) 收藏一下
标签: xcode5svn xcodesvn使用 xcode自带的svn xcodesvn版本操作 xcode自带svn版本 这两天响应老板要求,把所有代码放到公司的SVN服务器上,按照我的想法肯 ...
- MVC 基础和增删改、登录
一.什么是MVC?1.了解MVC 是一种使用 MVC(Model View Controller 模型-视图-控制器)设计创建 Web 应用程序的模式: Model(模型)表示应用程序核心 ...
- 循序渐进Python3(八) -- 0 -- 初识socket
socket通常也称作"套接字",用于描述IP地址和端口,是一个通信链的句柄,应用程序通常通过"套接字"向网络发出请求或者应答网络请求. socket起源于Un ...
- CSS3 background-size 属性
http://www.w3school.com.cn/cssref/pr_background-size.asp
- WPF简单导航框架(Window与Page互相调用)
相当多的WPF程序都有着丰富的页面和功能,如何使程序在不同页面间转换并降低资源占用,选择适合自己的导航框架就很重要了.最近花了一点时间做了一个简单的导航框架,并在这个过程中对Window.Page.U ...
- Linux进程间通信之消息队列
本文依据以下思路展开,首先从宏观上阐述消息队列的机制,然后以具体代码为例进一步阐述该机制,最后试着畅想一下该通信机制潜在的应用. 消息队列是在两个不相关进程间传递数据的一种简单.高效方式,她独立于发送 ...