Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
【注】
1、该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送--Spark入门实战系列》获取;
2、Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用一般使用64位操作系统,内容分为三部分:基础环境搭建、Hadoop编译安装和Spark编译安装,该环境作为后续实验基础;
3、文章演示了Hadoop、Spark的编译过程,同时附属资源提供了编译好的安装包,觉得编译费时间可以直接使用这些编译好的安装包进行部署。
1、运行环境说明
1.1 硬软件环境
线程,主频2.2G,10G内存
l 虚拟软件:VMware® Workstation 9.0.0 build-812388
l 虚拟机操作系统:CentOS6.5 64位,单核,1G内存
l 虚拟机运行环境:
Ø JDK:1.7.0_55 64位
位)
Ø Scala:2.10.4
Ø Spark:1.1.0(需要编译)
1.2 集群网络环境
集群包含三个节点,节点之间可以免密码SSH访问,节点IP地址和主机名分布如下:
|
序号 |
IP地址 |
机器名 |
类型 |
核数/内存 |
用户名 |
目录 |
|
192.168.0.61 |
hadoop1 |
NN/DN/RM Master/Worker |
核/3G |
hadoop |
/app 程序所在路径 /app/scala-... /app/hadoop /app/complied |
|
|
192.168.0.62 |
hadoop2 |
DN/NM/Worker |
核/2G |
hadoop |
||
|
192.168.0.63 |
hadoop3 |
DN/NM/Worker |
核/2G |
hadoop |
1.所有节点均是CentOS6.5 64bit系统,防火墙/SElinux均禁用,所有节点上均创建了一个hadoop用户,用户主目录是/home/hadoop,上传文件存放在/home/hadoop/upload文件夹中。
2.所有节点上均创建了一个目录/app用于存放安装程序,并且拥有者是hadoop用户,对其必须有rwx权限(一般做法是root用户在根目录下创建/app目录,并使用chown命令修改该目录拥有者为hadoop),否则hadoop用户使用SSH往其他机器分发文件会出现权限不足的提示
1.3 安装使用工具
1.3.1 Linux文件传输工具
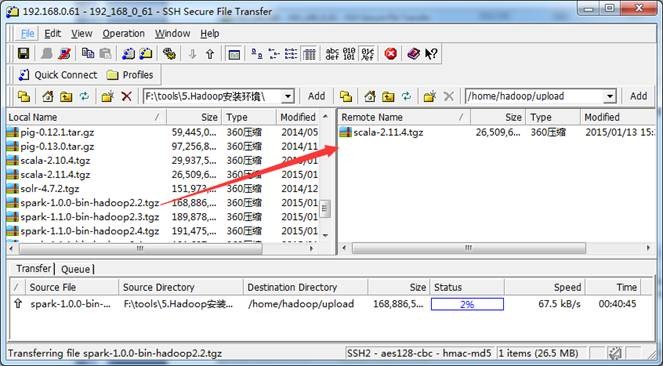
向Linux系统传输文件推荐使用SSH Secure File Transfer,该工具顶部为工具的菜单和快捷方式,中间部分左面为本地文件目录,右边为远程文件目录,可以通过拖拽等方式实现文件的下载与上传,底部为操作情况监控区,如下图所示:
1.3.2 Linux命令行执行工具
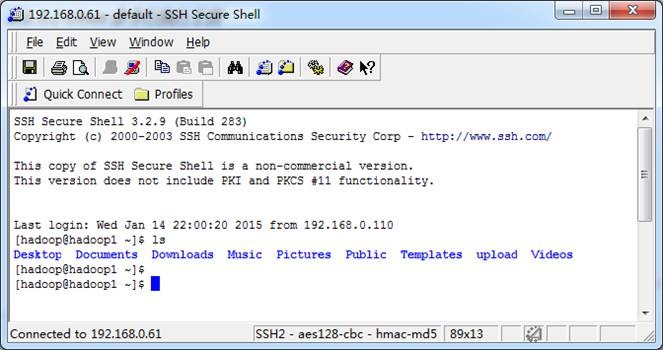
l SSH Secure Shell SSH Secure工具的SSH Secure Shell提供了远程命令执行,如下图所示:
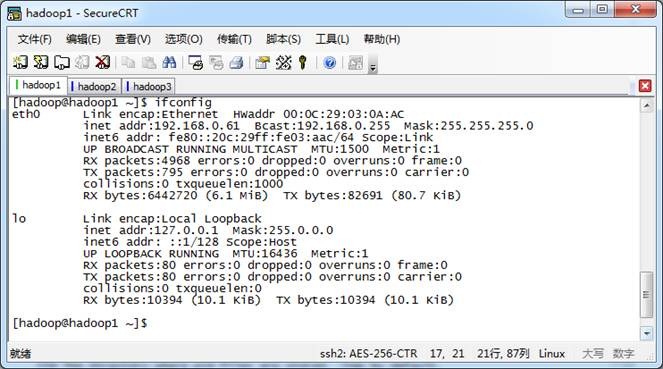
l SecureCRT SecureCRT是常用远程执行Linux命令行工具,如下图所示:
、搭建样板机环境
本次安装集群分为三个节点,本节搭建样板机环境搭建,搭建分为安装操作系统、设置系统环境和配置运行环境三个步骤。
2.1 安装操作系统
第一步 插入CentOS 6.5的安装介质,使用介质启动电脑出现如下界面
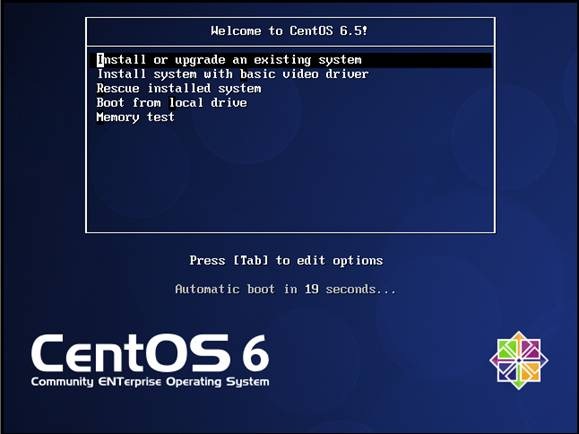
lInstall or upgrade an existing system 安装或升级现有的系统
linstall system with basic video driver 安装过程中采用基本的显卡驱动
lRescue installed system 进入系统修复模式
lBoot from local drive 退出安装从硬盘启动
lMemory test 内存检测
第二步 介质检测选择"Skip",直接跳过
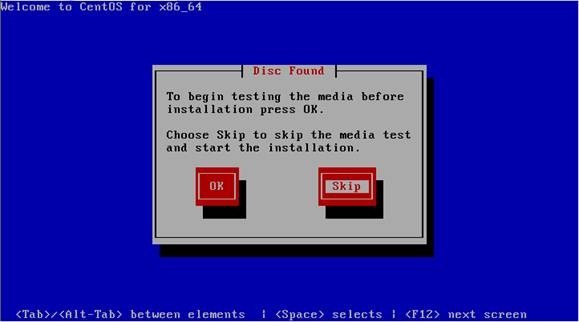
第三步 出现引导界面,点击“next”

第四步 选择安装过程语言,选中"English(English)"
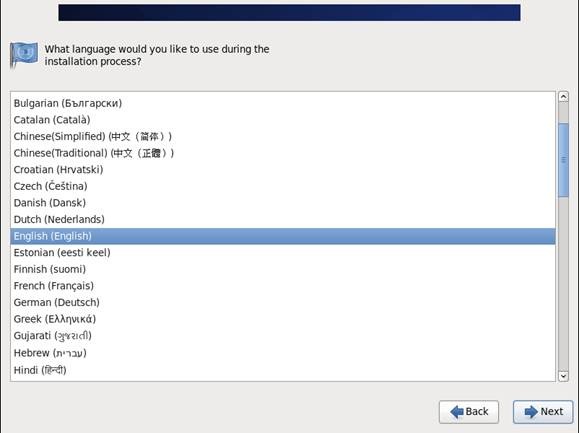
第五步 键盘布局选择“U.S.English”
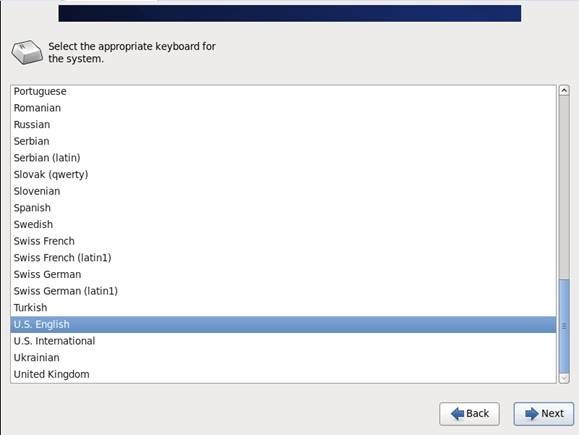
第六步 选择“Basic Storage Devies"点击"Next"
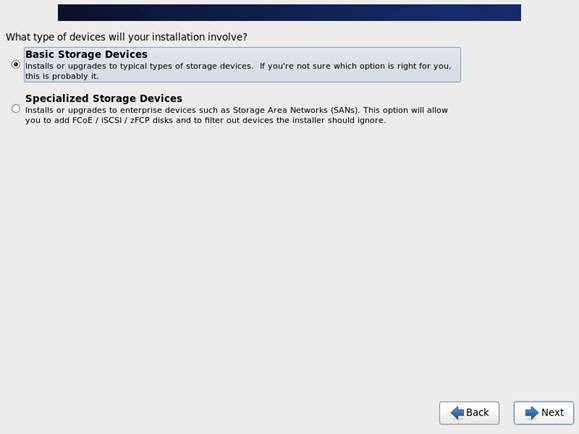
第七步 询问是否覆写所有数据,选择"Yes,discard any data"
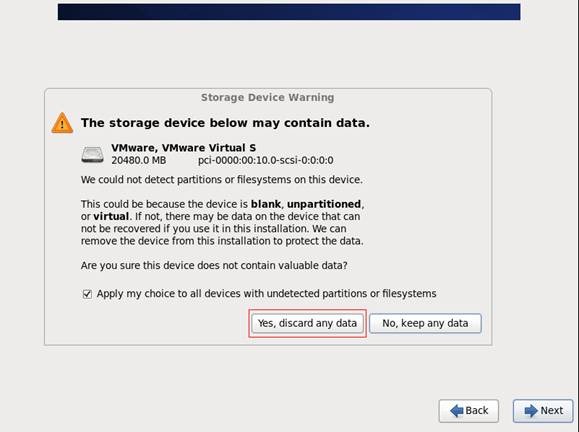
第八步 Hostname填写格式“英文名.姓”
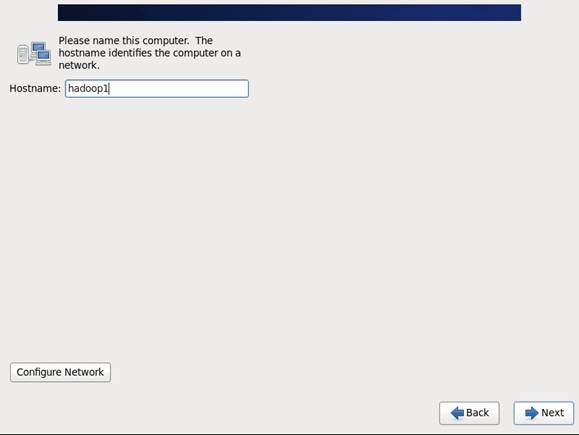
第九步 时区可以在地图上点击,选择“Shanghai”并取消System clock uses UTC选择
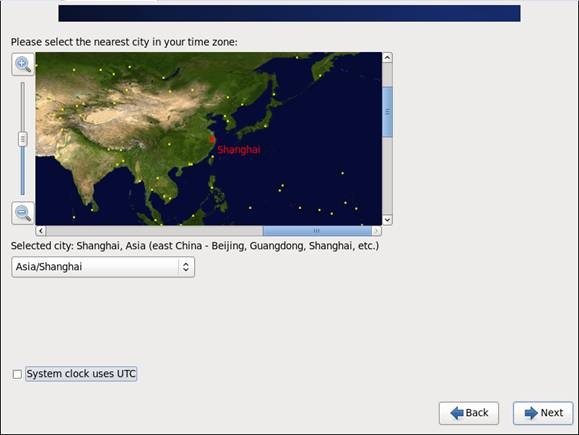
第十步 设置root的密码
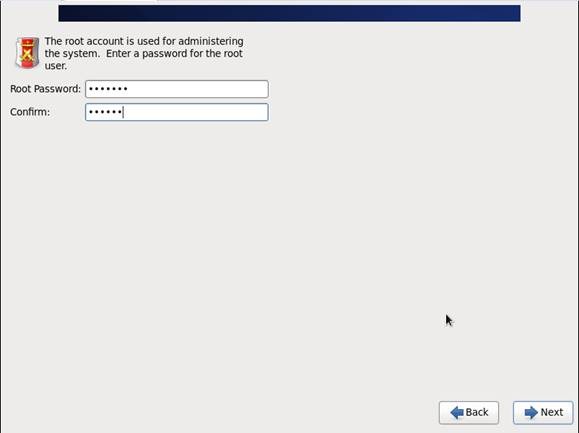
第十一步 硬盘分区,一定要按照图示点选
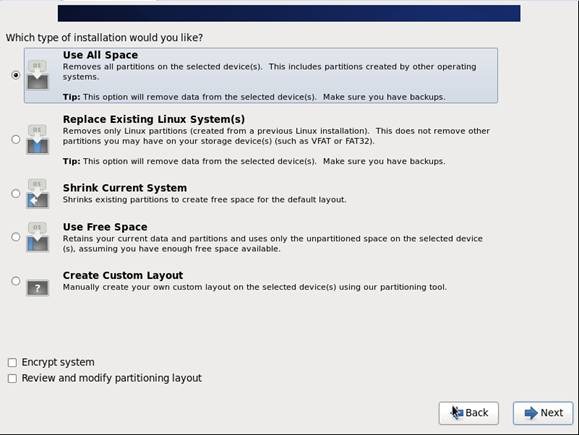
第十二步 询问是否改写入到硬盘,选择"Write changes to disk"
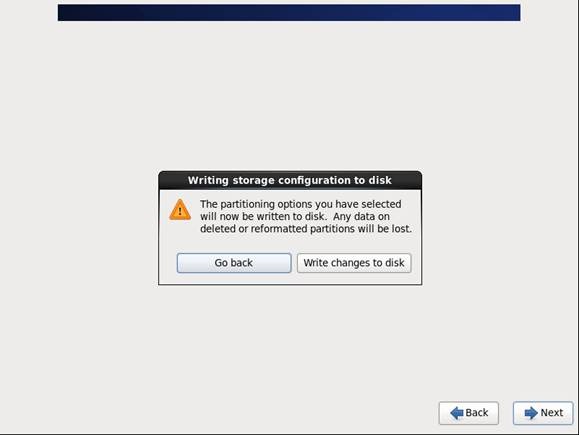
第十三步 选择系统安装模式为"Desktop"
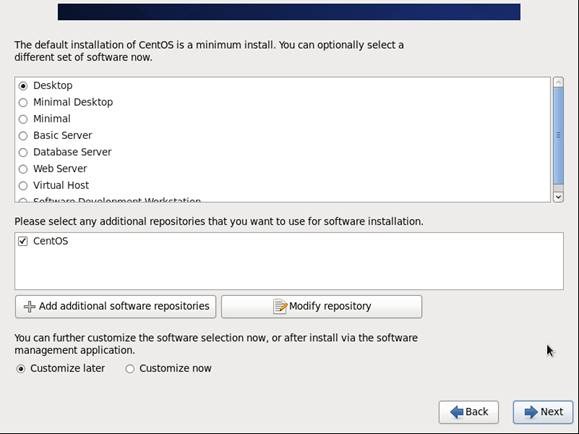
第十四步 桌面环境就设置完成了,点击安装
第十五步 安装完成,重启
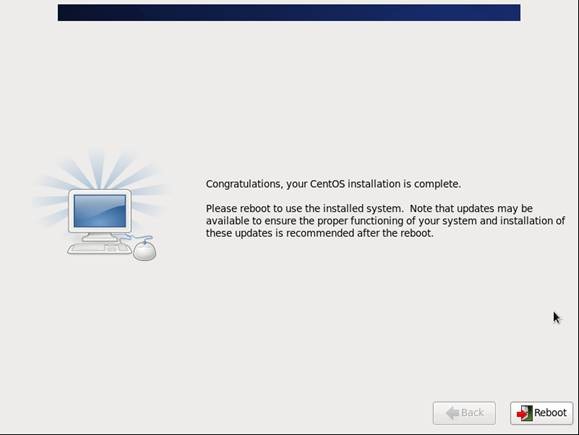
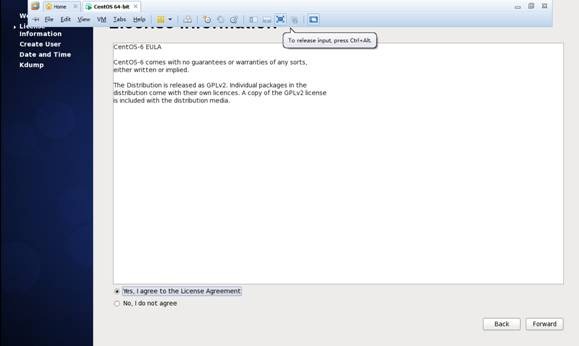
第十六步 重启之后,的License Information
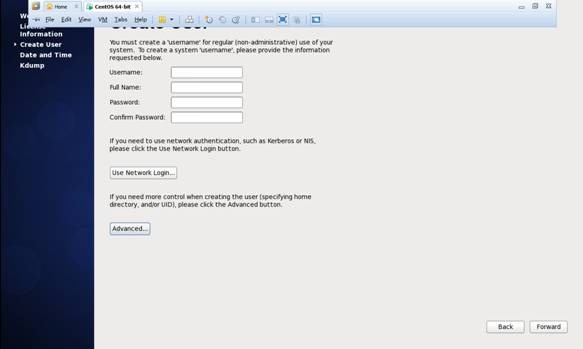
第十七步 创建用户和设置密码(这里不进行设置用户和密码)
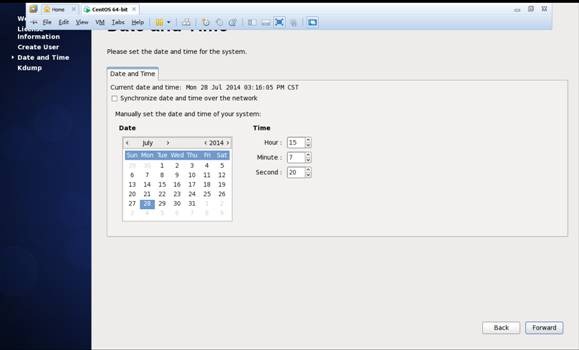
第十八步 "Date and Time" 选中 “Synchronize data and time over the network”
Finsh之后系统将重启
2.2 设置系统环境
该部分对服务器的配置需要在服务器本地进行配置,配置完毕后需要重启服务器确认配置是否生效,特别是远程访问服务器需要设置固定IP地址。
2.2.1 设置机器名
以root用户登录,使用#vi /etc/sysconfig/network 打开配置文件,根据实际情况设置该服务器的机器名,新机器名在重启后生效

2.2.2 设置IP地址
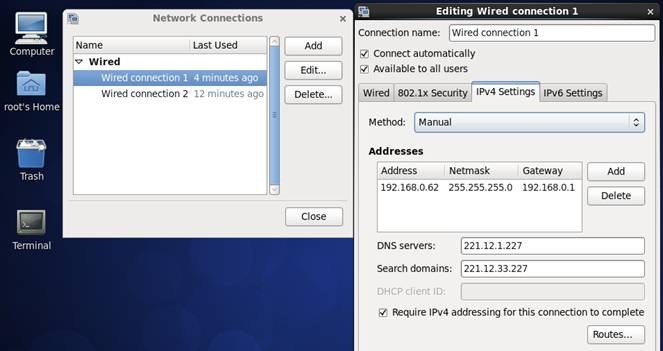
1. 点击System-->Preferences-->Network Connections,如下图所示:
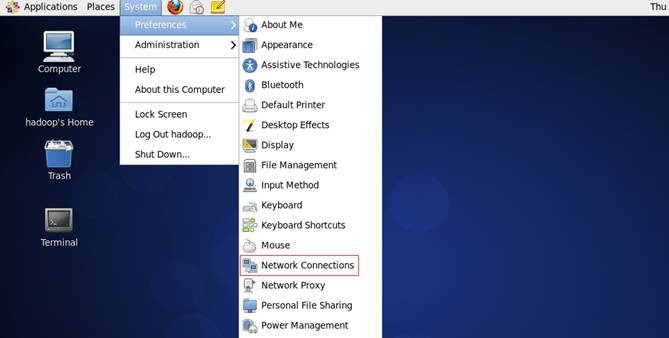
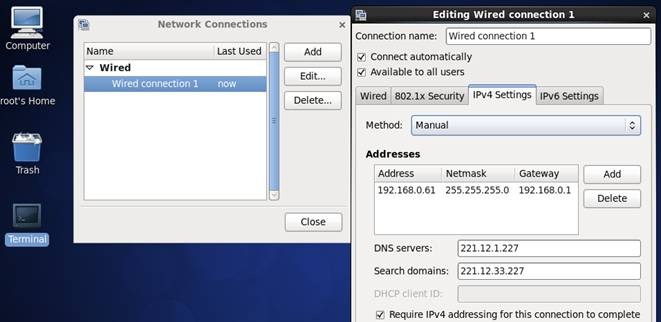
2. 修改或重建网络连接,设置该连接为手工方式,设置如下网络信息:
IP地址: 192.168.0.61
子网掩码: 255.255.255.0
网关: 192.168.0.1
DNS: 221.12.1.227 (需要根据所在地设置DNS服务器)
【注意】
、网关、DNS等根据所在网络实际情况进行设置,并设置连接方式为"Available to all users",否则通过远程连接时会在服务器重启后无法连接服务器;
、如果是运行在VM Ware虚拟机,网络使用桥接模式,设置能够连接到互联网中,以方便后面Hadoop和Spark编译等试验。
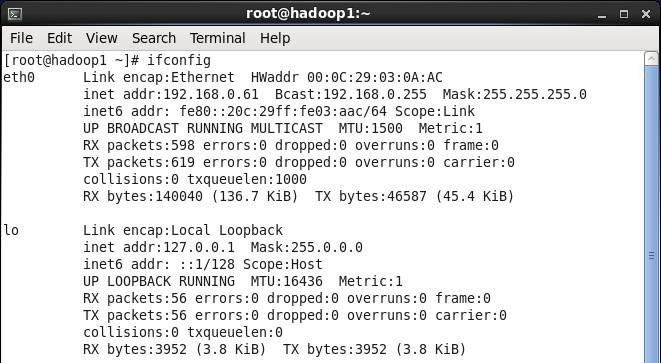
3. 在命令行中,使用ifconfig命令查看设置IP地址信息,如果修改IP不生效,需要重启机器再进行设置(如果该机器在设置后需要通过远程访问,建议重启机器,确认机器IP是否生效):
2.2.3设置Host映射文件
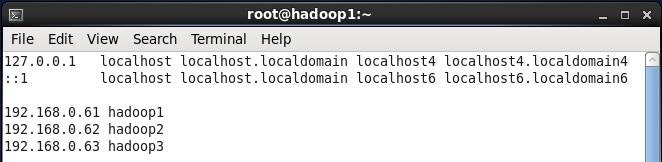
1. 使用root身份编辑/etc/hosts映射文件,设置IP地址与机器名的映射,设置信息如下:
#vi /etc/hosts
l 192.168.0.61 hadoop1
l 192.168.0.62 hadoop2
l 192.168.0.63 hadoop3
2. 使用如下命令对网络设置进行重启
#/etc/init.d/network restart
或者 #service network restart
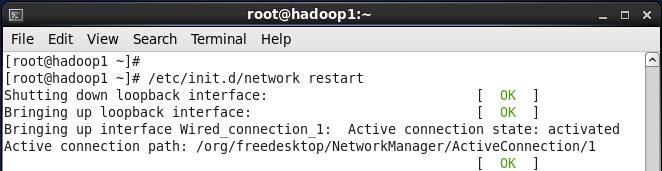
3. 验证设置是否成功
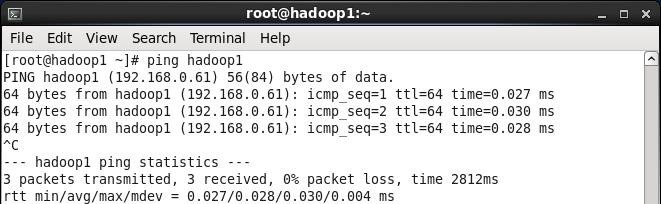
2.2.4关闭防火墙
在hadoop安装过程中需要关闭防火墙和SElinux,否则会出现异常
1. service iptables status 查看防火墙状态,如下所示表示iptables已经开启
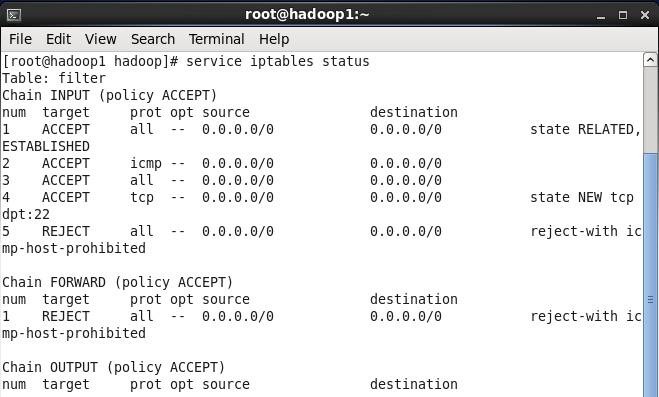
2. 以root用户使用如下命令关闭iptables
#chkconfig iptables off

2.2.5关闭SElinux
1. 使用getenforce命令查看是否关闭


2. 修改/etc/selinux/config 文件
将SELINUX=enforcing改为SELINUX=disabled,执行该命令后重启机器生效
#vi /etc/selinux/config
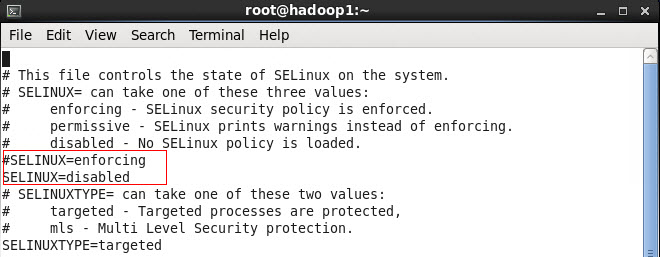
2.3 配置运行环境
2.3.1 更新OpenSSL
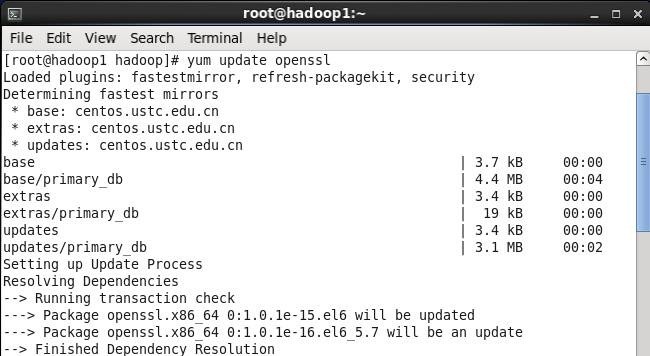
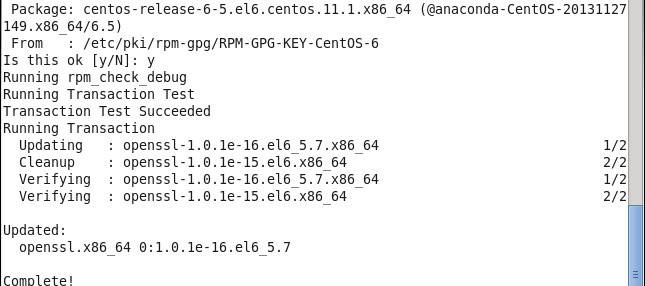
CentOS系统自带的OpenSSL存在bug,如果不更新OpenSSL在Ambari部署过程会出现无法通过SSH连接节点,使用如下命令进行更新:
#yum update openssl
2.3.2 修改SSH配置文件
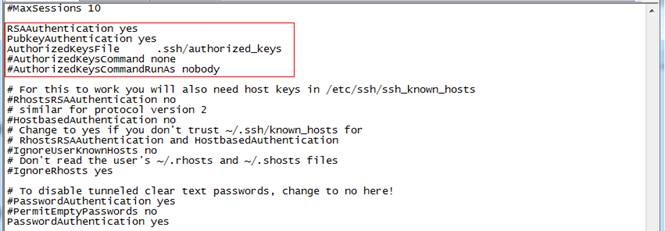
1. 以root用户使用如下命令打开sshd_config配置文件
#vi /etc/ssh/sshd_config
开放三个配置,如下图所示:
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
2. 配置后重启服务
#service sshd restart

2.3.3增加hadoop组和用户
使用如下命令增加hadoop 组和hadoop 用户(密码),创建hadoop组件存放目录
#groupadd -g 1000 hadoop
#useradd -u 2000 -g hadoop hadoop
#mkdir -p /app/hadoop
#chown -R hadoop:hadoop /app/hadoop
#passwd hadoop

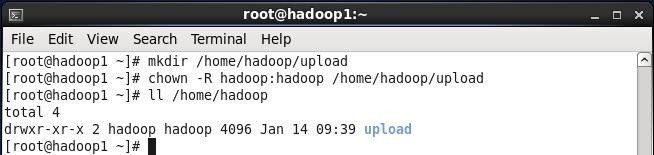
创建hadoop用户上传文件目录,设置该目录组和文件夹为hadoop
#mkdir /home/hadoop/upload
#chown -R hadoop:hadoop /home/hadoop/upload
2.3.4JDK安装及配置
1. 下载JDK1.7 64bit安装包
打开JDK1.7 64bit安装包下载链接为:
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
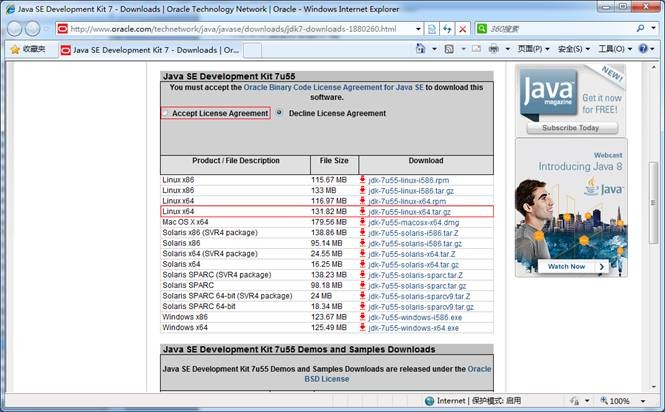
打开界面之后,先选中 Accept License Agreement ,然后下载 jdk-7u55-linux-x64.tar.gz,如下图所示:
2. 赋予hadoop用户/usr/lib/java目录可读写权限,使用命令如下:
$sudo chmod -R 777 /usr/lib/java

该步骤有可能遇到问题2.2,可参考解决办法处理
3. 把下载的安装包,使用1.1.3.1介绍的ssh工具上传到/usr/lib/java 目录下,使用如下命令进行解压
$tar -zxvf jdk-7u55-linux-x64.tar.gz

解压后目录如下图所示:

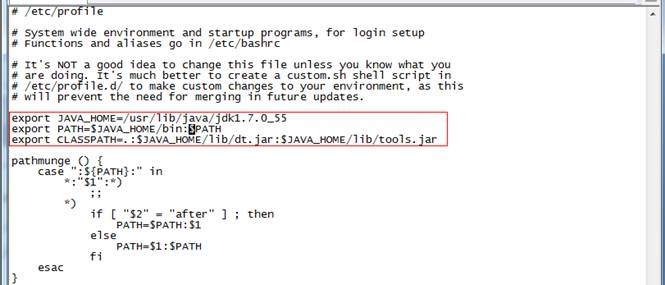
4. 使用root用户配置/etc/profile文件,并生效该配置
export JAVA_HOME=/usr/lib/java/jdk1.7.0_55
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
5. 重新登录并验证
$logout
$java -version

2.3.5 Scala安装及配置
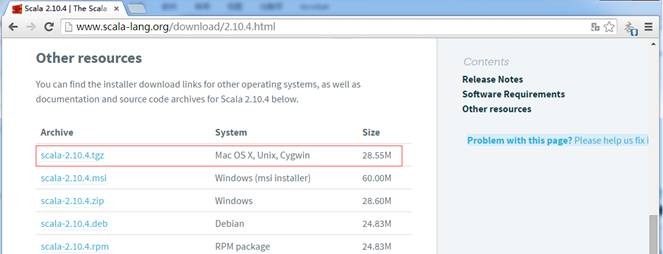
1. 下载Scala安装包
Scala2.10.4安装包下载链接为:http://www.scala-lang.org/download/2.10.4.html,因为在Scala2.11.4下IDEA有些异常,故在这里建议安装Scala2.10.4版本
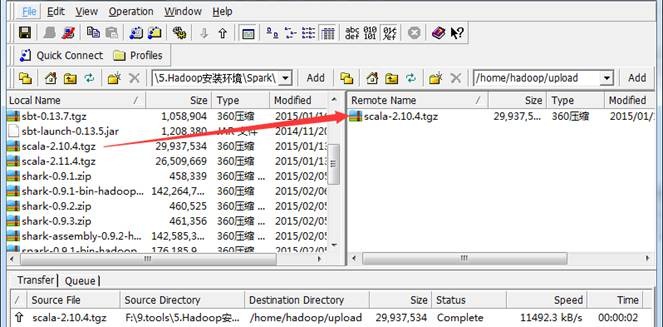
2. 上传Scala安装文件
把下载的scala安装包使用SSH Secure File Transfer工具(如1.3.1介绍)上传到/home/hadoop/upload目录下,如下图所示:
3. 解压缩
到上传目录下,用如下命令解压缩:
$cd /home/hadoop/upload
$tar -zxf scala-2.10.4.tgz

迁移到/app目录下:
$sudo mv scala-2.10.4 /app/
4. 使用root用户配置/etc/profile文件,并生效该配置
export SCALA_HOME=/app/scala-2.10.4
export PATH=$PATH:${SCALA_HOME}/bin

5. 重新登录并验证
$exit
$scala -version

、配置集群环境
复制样板机生成其他两个节点,按照规划设置及其命名和IP地址,最后设置SSH无密码登录。
3.1 复制样板机
复制样板机两份,分别为hadoop2和hadoop3节点

3.2 设置机器名和IP地址
以root用户登录,使用vi /etc/sysconfig/network 打开配置文件,根据1.2规划修改机器名,修改机器名后需要重新启动机器,新机器名在重启后生效

按照2.2.2配置方法修改机器IP地址
3.3 配置SSH无密码登录
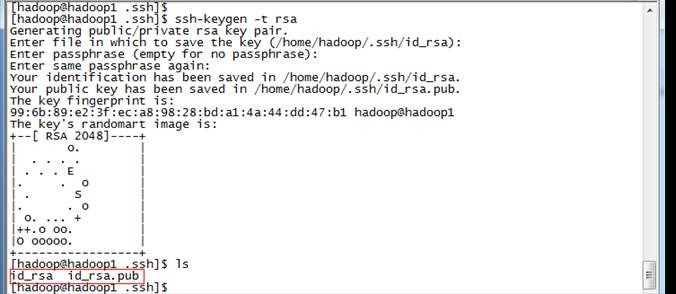
1. 使用hadoop用户登录在三个节点中使用如下命令生成私钥和公钥;
$ssh-keygen -t rsa
2. 进入/home/hadoop/.ssh目录在三个节点中分别把公钥命名为authorized_keys_hadoop1、authorized_keys_hadoop2和authorized_keys_hadoop3,使用命令如下:
$cd /home/hadoop/.ssh
$cp id_rsa.pub authorized_keys_hadoop1

3. 把两个从节点(hadoop2、hadoop3)的公钥使用scp命令传送到hadoop1节点的/home/hadoop/.ssh文件夹中;
$scp authorized_keys_hadoop2 hadoop@hadoop1:/home/hadoop/.ssh
$scp authorized_keys_hadoop3 hadoop@hadoop1:/home/hadoop/.ssh


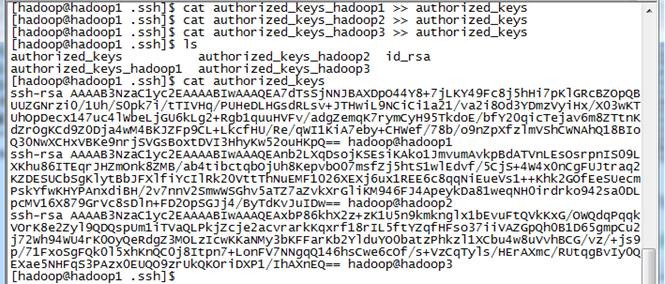
4. 把三个节点的公钥信息保存到authorized_key文件中
使用$cat authorized_keys_hadoop1 >> authorized_keys 命令
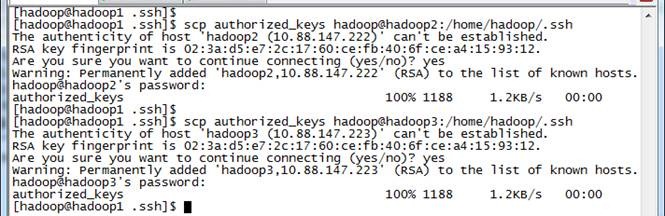
5. 把该文件分发到其他两个从节点上
使用$scp authorized_keys hadoop@hadoop2:/home/hadoop/.ssh把密码文件分发出去

6. 在三台机器中使用如下设置authorized_keys读写权限
$chmod 400 authorized_keys

7. 测试ssh免密码登录是否生效
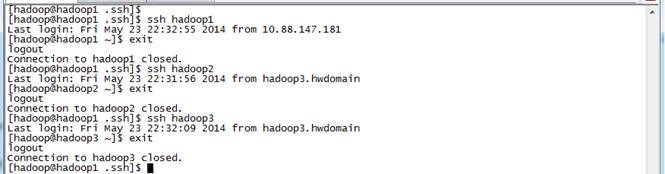
3.4 设置机器启动模式(可选)
设置好集群环境后,可以让集群运行在命令行模式下,减少集群所耗费的资源。以root用户使用#vi /etc/inittab,将 id:5:initdefault: 改为 id:3:initdefault:
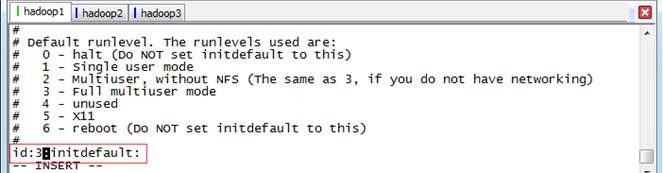
Linux 系统任何时候都运行在一个指定的运行级上,并且不同的运行级的程序和服务都不同,所要完成的工作和所要达到的目的都不同。CentOS设置了如下表所示的运行级,并且系统可以在这些运行级别之间进行切换,以完成不同的工作。运行级说明
l 0 所有进程将被终止,机器将有序的停止,关机时系统处于这个运行级别
l 1 单用户模式。用于系统维护,只有少数进程运行,同时所有服务也不启动
多用户模式。和运行级别3一样,只是网络文件系统(NFS)服务没被启动
多用户模式。允许多用户登录系统,是系统默认的启动级别
留给用户自定义的运行级别
多用户模式,并且在系统启动后运行X-Window,给出一个图形化的登录窗口
所有进程被终止,系统重新启动
、问题解决
4.1 安装CentOS64位虚拟机 This host supports Intel VT-x, but Intel VT-x is disabled
位虚拟机,安装过程中出现下图错误:
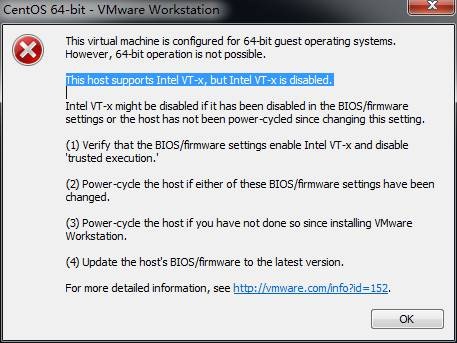
按F1 键进入BIOS 设置实用程序 使用箭头键security面板下找virtualization按Enter 键 进去Intel VirtualizationTechnology改成Enabled按F10 键保存并退出 选择Yes按Enter 键 完全关机(关闭电源)等待几秒钟重新启动计算机此Intel虚拟化技术开启成功
4.2 *** is not in the sudoers file解决方法
当使用hadoop用户需要对文件夹进行赋权,使用chmod命令出现“hadoop is not in the sudoers file. This incident will be reported”错误,如下所示:
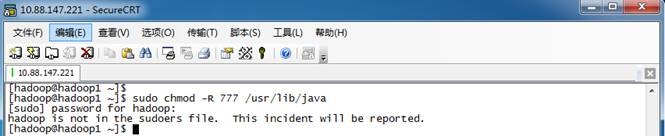
1. 使用su命令进入root用户
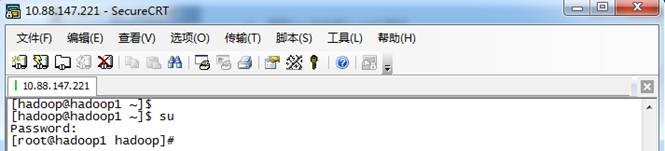
2. 添加文件的写权限,操作命令为:chmod u+w /etc/sudoers
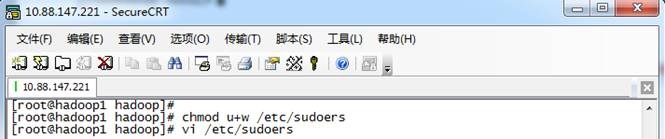
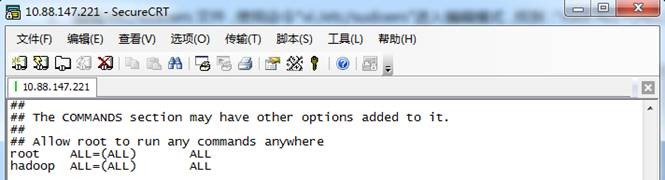
3. 编辑/etc/sudoers文件,使用命令"vi /etc/sudoers"进入编辑模式,找到:"root ALL=(ALL) ALL"在起下面添加"hadoop ALL=(ALL) ALL",然后保存退出。
Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建的更多相关文章
- Spark入门实战系列--2.Spark编译与部署(中)--Hadoop编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Hadooop 1.1 搭建环境 1.1.1 安装并设置maven 1. 下载mave ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 . 安装IntelliJ IDEA IDEA 全称 IntelliJ IDEA,是java语 ...
- Spark入门实战系列--9.Spark图计算GraphX介绍及实例
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .GraphX介绍 1.1 GraphX应用背景 Spark GraphX是一个分布式图处理 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark入门实战系列--7.Spark Streaming(下)--实时流计算Spark Streaming实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .实例演示 1.1 流数据模拟器 1.1.1 流数据说明 在实例演示中模拟实际情况,需要源源 ...
随机推荐
- Cannot refer to an instance field pageTitle while explicitly invoking a cons
当下面这样时在第7行会提示:Cannot refer to an instance field pageTitle while explicitly invoking a cons public cl ...
- Yii2 使用Composer
composer 是 PHP 用来管理依赖(dependency)关系的工具.你可以在自己的项目中声明所依赖的外部工具库(libraries),Composer 会帮你安装这些依赖的库文件 compo ...
- TypeScript之接口类型
Interfaces 作为TypeScript中的核心特色之一,能够让类型检查帮助我们知道一个对象应该有什么,相比我们在编写JavaScript的时候经常遇到函数需要传递参数,可能在编写的时候知道这个 ...
- 控件UI性能调优 -- SizeChanged不是万能的
简介 我们在之前的“UWP控件开发——用NuGet包装自己的控件“一文中曾提到XAML的布局系统 和平时使用上的一些问题(重写Measure/Arrange还是使用SizeChanged?),这篇博文 ...
- 必须知道的SQL编写技巧,多条件查询不拼字符串的写法
在做项目中,我们经常遇到复杂的查询方法,要根据用户的输入,判断某个参数是否合法,合法的话才能当作过滤条件,我们通常的做法是把查询SQL赋值给一个字符串变量,然后根据判断条件动态的拼接where条件进行 ...
- Senparc.Weixin.MP SDK 微信公众平台开发教程(三):微信公众平台开发验证
要对接微信公众平台的"开发模式",即对接到自己的网站程序,必须在注册成功之后(见Senparc.Weixin.MP SDK 微信公众平台开发教程(一):微信公众平台注册),等待官方 ...
- Git学习笔记(5)——分支管理
本文主要记录了分支的原理.分支的创建,删除,合并.以及分支的使用策略. 分支在实际中的作用 假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码,如果立刻提交,由于代码还没写完,不 ...
- Android Activity的生命周期简单总结
Android Activity的生命周期简单总结 这里的内容参考官方的文档,这篇文章的目的不是去总结Activity是如何启动,如何创造,以及暂停和销毁的,而是从实际开发中分析在Activity各个 ...
- telnet小结
几百年前就开始听说telnet了,却直到最近才真正完全搞懂!... http://www.cnblogs.com/wusthjp/archive/2012/01/05/2312975.html 可能要 ...
- CSS水平垂直居中的几种方法2
直接进入主题! 一.脱离文档流元素的居中 方法一:margin:auto法 CSS代码: div{ width: 400px; height: 400px; position: relative; b ...