[综]隐马尔可夫模型Hidden Markov Model (HMM)
http://www.zhihu.com/question/20962240
隐马尔可夫(HMM)好讲,简单易懂不好讲。我认为 @者也的回答没什么错误,不过我想说个更通俗易懂的例子。我希望我的读者不是专家,而是对这个问题感兴趣的入门者,所以我会多阐述数学思想,少写公式。霍金曾经说过,你多写一个公式,就会少一半的读者。所以时间简史这本关于物理的书和麦当娜关于性的书卖的一样好。我会效仿这一做法,写最通俗易懂的答案。
还是用最经典的例子,掷骰子。假设我手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
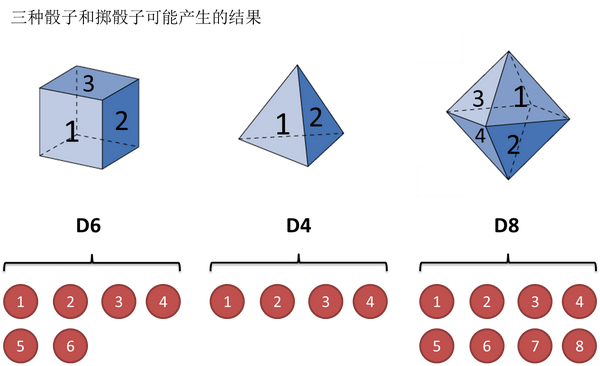
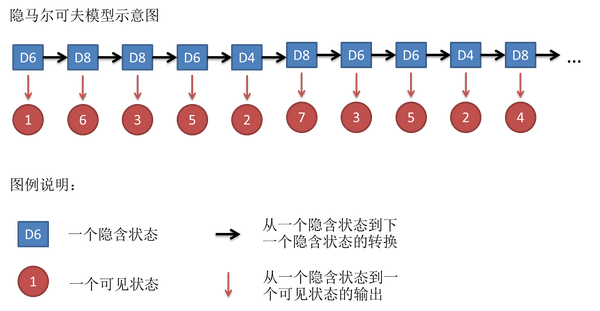
假设我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。例如我们可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4
这串数字叫做可见状态链。但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
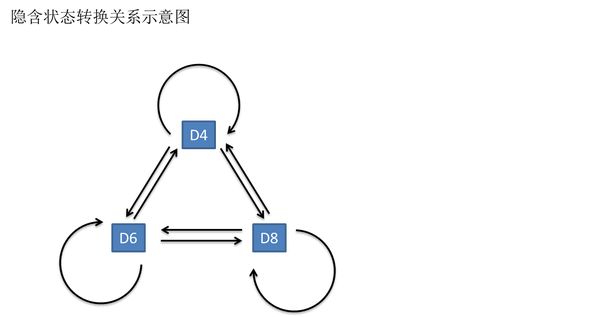
一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)。在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。
同样的,尽管可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如,我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。
其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但是应用HMM模型时候呢,往往是缺失了一部分信息的,有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。如果应用算法去估计这些缺失的信息,就成了一个很重要的问题。这些算法我会在下面详细讲。
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××
如果你只想看一个简单易懂的例子,就不需要往下看了。
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××
说两句废话,答主认为呢,要了解一个算法,要做到以下两点:会其意,知其形。答主回答的,其实主要是第一点。但是这一点呢,恰恰是最重要,而且很多书上不会讲的。正如你在追一个姑娘,姑娘对你说“你什么都没做错!”你要是只看姑娘的表达形式呢,认为自己什么都没做错,显然就理解错了。你要理会姑娘的意思,“你赶紧给我道歉!”这样当你看到对应的表达形式呢,赶紧认错,跪地求饶就对了。数学也是一样,你要是不理解意思,光看公式,往往一头雾水。不过呢,数学的表达顶多也就是晦涩了点,姑娘的表达呢,有的时候就完全和本意相反。所以答主一直认为理解姑娘比理解数学难多了。
回到正题,和HMM模型相关的算法主要分为三类,分别解决三种问题:
1)知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。
这个问题呢,在语音识别领域呢,叫做解码问题。这个问题其实有两种解法,会给出两个不同的答案。每个答案都对,只不过这些答案的意义不一样。第一种解法求最大似然状态路径,说通俗点呢,就是我求一串骰子序列,这串骰子序列产生观测结果的概率最大。第二种解法呢,就不是求一组骰子序列了,而是求每次掷出的骰子分别是某种骰子的概率。比如说我看到结果后,我可以求得第一次掷骰子是D4的概率是0.5,D6的概率是0.3,D8的概率是0.2.第一种解法我会在下面说到,但是第二种解法我就不写在这里了,如果大家有兴趣,我们另开一个问题继续写吧。
2)还是知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率。
看似这个问题意义不大,因为你掷出来的结果很多时候都对应了一个比较大的概率。问这个问题的目的呢,其实是检测观察到的结果和已知的模型是否吻合。如果很多次结果都对应了比较小的概率,那么就说明我们已知的模型很有可能是错的,有人偷偷把我们的骰子給换了。
3)知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)。
这个问题很重要,因为这是最常见的情况。很多时候我们只有可见结果,不知道HMM模型里的参数,我们需要从可见结果估计出这些参数,这是建模的一个必要步骤。
问题阐述完了,下面就开始说解法。(0号问题在上面没有提,只是作为解决上述问题的一个辅助)
0.一个简单问题
其实这个问题实用价值不高。由于对下面较难的问题有帮助,所以先在这里提一下。
知道骰子有几种,每种骰子是什么,每次掷的都是什么骰子,根据掷骰子掷出的结果,求产生这个结果的概率。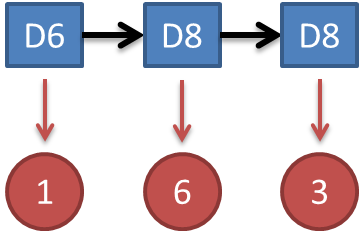 解法无非就是概率相乘:
解法无非就是概率相乘:
1.看见不可见的,破解骰子序列
这里我说的是第一种解法,解最大似然路径问题。
举例来说,我知道我有三个骰子,六面骰,四面骰,八面骰。我也知道我掷了十次的结果(1 6 3 5 2 7 3 5 2 4),我不知道每次用了那种骰子,我想知道最有可能的骰子序列。
其实最简单而暴力的方法就是穷举所有可能的骰子序列,然后依照第零个问题的解法把每个序列对应的概率算出来。然后我们从里面把对应最大概率的序列挑出来就行了。如果马尔可夫链不长,当然可行。如果长的话,穷举的数量太大,就很难完成了。
另外一种很有名的算法叫做Viterbi algorithm. 要理解这个算法,我们先看几个简单的列子。
首先,如果我们只掷一次骰子:
看到结果为1.对应的最大概率骰子序列就是D4,因为D4产生1的概率是1/4,高于1/6和1/8.
把这个情况拓展,我们掷两次骰子:
结果为1,6.这时问题变得复杂起来,我们要计算三个值,分别是第二个骰子是D6,D4,D8的最大概率。显然,要取到最大概率,第一个骰子必须为D4。这时,第二个骰子取到D6的最大概率是
同样的,我们可以计算第二个骰子是D4或D8时的最大概率。我们发现,第二个骰子取到D6的概率最大。而使这个概率最大时,第一个骰子为D4。所以最大概率骰子序列就是D4 D6。
继续拓展,我们掷三次骰子:
同样,我们计算第三个骰子分别是D6,D4,D8的最大概率。我们再次发现,要取到最大概率,第二个骰子必须为D6。这时,第三个骰子取到D4的最大概率是
同上,我们可以计算第三个骰子是D6或D8时的最大概率。我们发现,第三个骰子取到D4的概率最大。而使这个概率最大时,第二个骰子为D6,第一个骰子为D4。所以最大概率骰子序列就是D4 D6 D4。
写到这里,大家应该看出点规律了。既然掷骰子一二三次可以算,掷多少次都可以以此类推。我们发现,我们要求最大概率骰子序列时要做这么几件事情。首先,不管序列多长,要从序列长度为1算起,算序列长度为1时取到每个骰子的最大概率。然后,逐渐增加长度,每增加一次长度,重新算一遍在这个长度下最后一个位置取到每个骰子的最大概率。因为上一个长度下的取到每个骰子的最大概率都算过了,重新计算的话其实不难。当我们算到最后一位时,就知道最后一位是哪个骰子的概率最大了。然后,我们要把对应这个最大概率的序列从后往前推出来。
2.谁动了我的骰子?
比如说你怀疑自己的六面骰被赌场动过手脚了,有可能被换成另一种六面骰,这种六面骰掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。你怎么办么?答案很简单,算一算正常的三个骰子掷出一段序列的概率,再算一算不正常的六面骰和另外两个正常骰子掷出这段序列的概率。如果前者比后者小,你就要小心了。
比如说掷骰子的结果是:
要算用正常的三个骰子掷出这个结果的概率,其实就是将所有可能情况的概率进行加和计算。同样,简单而暴力的方法就是把穷举所有的骰子序列,还是计算每个骰子序列对应的概率,但是这回,我们不挑最大值了,而是把所有算出来的概率相加,得到的总概率就是我们要求的结果。这个方法依然不能应用于太长的骰子序列(马尔可夫链)。
我们会应用一个和前一个问题类似的解法,只不过前一个问题关心的是概率最大值,这个问题关心的是概率之和。解决这个问题的算法叫做前向算法(forward algorithm)。
首先,如果我们只掷一次骰子:
看到结果为1.产生这个结果的总概率可以按照如下计算,总概率为0.18:
把这个情况拓展,我们掷两次骰子:
看到结果为1,6.产生这个结果的总概率可以按照如下计算,总概率为0.05:
继续拓展,我们掷三次骰子:
看到结果为1,6,3.产生这个结果的总概率可以按照如下计算,总概率为0.03: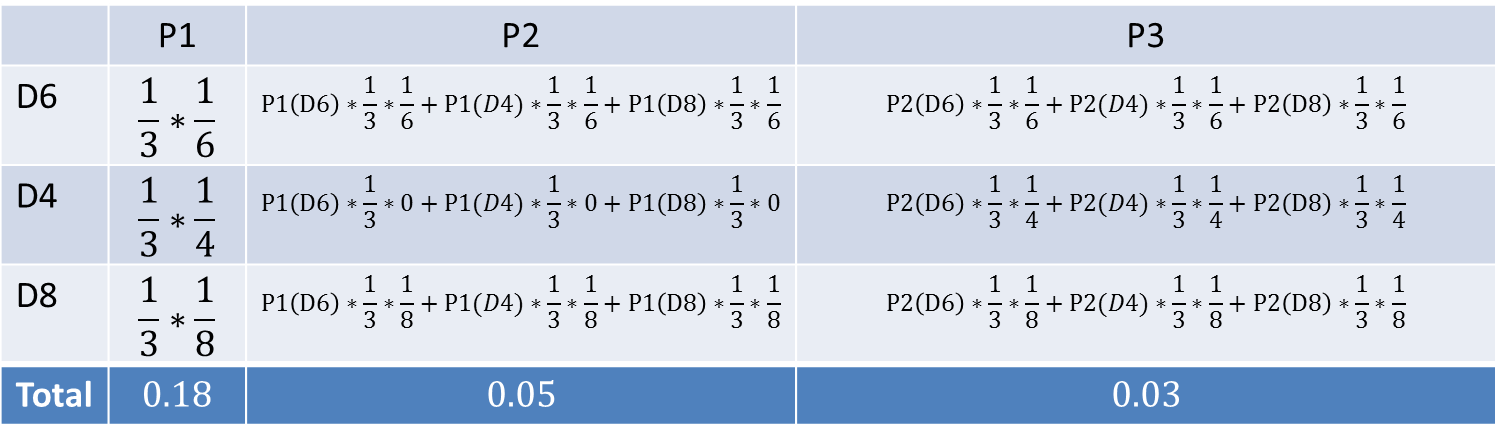
同样的,我们一步一步的算,有多长算多长,再长的马尔可夫链总能算出来的。用同样的方法,也可以算出不正常的六面骰和另外两个正常骰子掷出这段序列的概率,然后我们比较一下这两个概率大小,就能知道你的骰子是不是被人换了。
3.掷一串骰子出来,让我猜猜你是谁
(答主很懒,还没写,会写一下EM这个号称算法的方法)
上述算法呢,其实用到了递归,逆向推导,循环这些方法,我只不过用很直白的语言写出来了。如果你们去看专业书籍呢,会发现更加严谨和专业的描述。毕竟,我只做了会其意,要知其形,还是要看书的。
摘自我的博客http://blog.csdn.net/ppn029012
1. 赌场风云(背景介绍)

最近一个赌场的老板发现生意不畅,于是派出手下去赌场张望。经探子回报,有位大叔在赌场中总能赢到钱,玩得一手好骰子,几乎是战无不胜。而且每次玩骰子的时候周围都有几个保镖站在身边,让人不明就里,只能看到每次开局,骰子飞出,沉稳落地。老板根据多年的经验,推测这位不善之客使用的正是江湖失传多年的"偷换骰子大法”(编者注:偷换骰子大法,用兜里自带的骰子偷偷换掉均匀的骰子)。老板是个冷静的人,看这位大叔也不是善者,不想轻易得罪他,又不想让他坏了规矩。正愁上心头,这时候进来一位名叫HMM帅哥,告诉老板他有一个很好的解决方案。
不用近其身,只要在远处装个摄像头,把每局的骰子的点数都记录下来。
然后HMM帅哥将会运用其强大的数学内力,用这些数据推导出
1. 该大叔是不是在出千?
2. 如果是在出千,那么他用了几个作弊的骰子? 还有当前是不是在用作弊的骰子。
3. 这几个作弊骰子出现各点的概率是多少?
天呐,老板一听,这位叫HMM的甚至都不用近身,就能算出是不是在作弊,甚至都能算出别人作弊的骰子是什么样的。那么,只要再当他作弊时,派人围捕他,当场验证骰子就能让他哑口无言。
2. HMM是何许人也?
在让HMM开展调查活动之前,该赌场老板也对HMM作了一番调查。
HMM(Hidden Markov Model), 也称隐性马尔可夫模型,是一个概率模型,用来描述一个系统隐性状态的转移和隐性状态的表现概率。
系统的隐性状态指的就是一些外界不便观察(或观察不到)的状态, 比如在当前的例子里面, 系统的状态指的是大叔使用骰子的状态,即
{正常骰子, 作弊骰子1, 作弊骰子2,...}
隐性状态的表现也就是, 可以观察到的,由隐性状态产生的外在表现特点。这里就是说, 骰子掷出的点数.
{1,2,3,4,5,6}
HMM模型将会描述,系统隐性状态的转移概率。也就是大叔切换骰子的概率,下图是一个例子,这时候大叔切换骰子的可能性被描述得淋漓尽致。
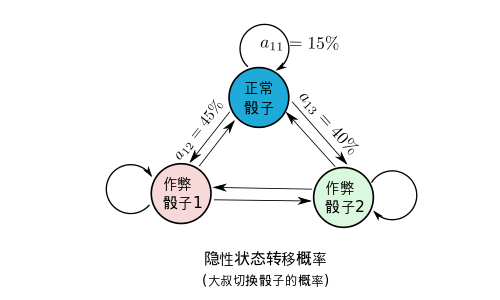
很幸运的,这么复杂的概率转移图,竟然能用简单的矩阵表达, 其中a_{ij}代表的是从i状态到j状态发生的概率

当然同时也会有,隐性状态表现转移概率。也就是骰子出现各点的概率分布, (e.g. 作弊骰子1能有90%的机会掷到六,作弊骰子2有85%的机会掷到'小’). 给个图如下,
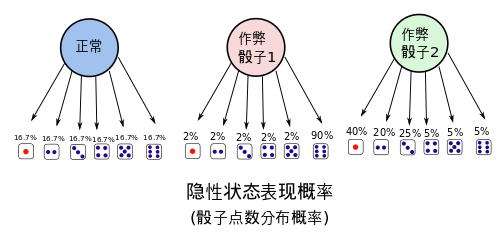
隐性状态的表现分布概率也可以用矩阵表示出来,

把这两个东西总结起来,就是整个HMM模型。
这个模型描述了隐性状态的转换的概率,同时也描述了每个状态外在表现的概率的分布。总之,HMM模型就能够描述扔骰子大叔作弊的频率(骰子更换的概率),和大叔用的骰子的概率分布。有了大叔的HMM模型,就能把大叔看透,让他完全在阳光下现形。
3. HMM能干什么!
总结起来HMM能处理三个问题,
3.1 解码(Decoding)
解码就是需要从一连串的骰子中,看出来哪一些骰子是用了作弊的骰子,哪些是用的正常的骰子。
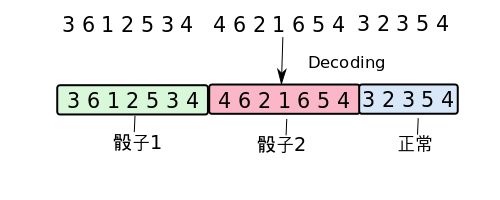
比如上图中,给出一串骰子序列(3,6,1,2..)和大叔的HMM模型, 我们想要计算哪一些骰子的结果(隐性状态表现)可能对是哪种骰子的结果(隐性状态).
3.2学习(Learning)
学习就是,从一连串的骰子中,学习到大叔切换骰子的概率,当然也有这些骰子的点数的分布概率。这是HMM最为恐怖也最为复杂的招数!!
3.3 估计(Evaluation)
估计说的是,在我们已经知道了该大叔的HMM模型的情况下,估测某串骰子出现的可能性概率。比如说,在我们已经知道大叔的HMM模型的情况下,我们就能直接估测到大叔扔到10个6或者8个1的概率。
4. HMM是怎么做到的?
4.1 估计
估计是最容易的一招,在完全知道了大叔的HMM模型的情况下,我们很容易就能对其做出估计。
现在我们有了大叔的状态转移概率矩阵A,B就能够进行估计。比如我们想知道这位大叔下一局连续掷出10个6的概率是多少? 如下
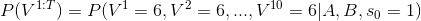
这表示的是,在一开始隐性状态(s0)为1,也就是一开始拿着的是正常的骰子的情况下,这位大叔连续掷出10个6的概率。
现在问题难就难在,我们虽然知道了HMM的转换概率,和观察到的状态V{1:T}, 但是我们却不知道实际的隐性的状态变化。
好吧,我们不知道隐性状态的变化,那好吧,我们就先假设一个隐性状态序列, 假设大叔前5个用的是正常骰子, 后5个用的是作弊骰子1.
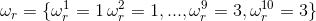
好了,那么我们可以计算,在这种隐性序列假设下掷出10个6的概率.
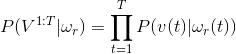
这个概率其实就是,隐性状态表现概率B的乘积.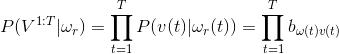
但是问题又出现了,刚才那个隐性状态序列是我假设的,而实际的序列我不知道,这该怎么办。好办,把所有可能出现的隐状态序列组合全都试一遍就可以了。于是,
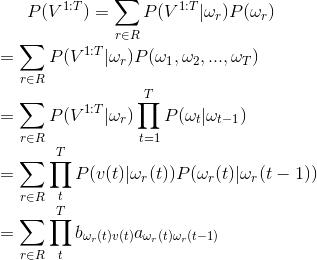
R就是所有可能的隐性状态序列的集合。的嗯,现在问题好像解决了,我们已经能够通过尝试所有组合来获得出现的概率值,并且可以通过A,B矩阵来计算出现的总概率。
但是问题又出现了,可能的集合太大了, 比如有三种骰子,有10次选择机会, 那么总共的组合会有3^10次...这个量级O(c^T)太大了,当问题再大一点时候,组合的数目就会大得超出了计算的可能。所以我们需要一种更有效的计算P(V(1:T)概率的方法。
比如说如下图的算法可以将计算P(V1:T)的计算复杂度降低至O(cT).
有了这个方程,我们就能从t=0的情况往前推导,一直推导出P(V1:T)的概率。下面让我们算一算,大叔掷出3,2,1这个骰子序列的可能性有多大(假设初始状态为1, 也就是大叔前一次拿着的是正常的骰子)?
4.2 解码(Decoding)
解码的过程就是在给出一串序列的情况下和已知HMM模型的情况下,找到最可能的隐性状态序列。
用数学公式表示就是, (V是Visible可见序列, w是隐性状态序列, A,B是HMM状态转移概率矩阵)
(公式太多,请具体看我博客中的推导机器学习 --- 4. 大内密探HMM(隐马尔可夫)围捕赌场老千)
然后又可以使用估计(4.1)中的前向推导法,计算出最大的P(w(1:T), V(1:T)).
在完成前向推导法之后,再使用后向追踪法(Back Tracking),对求解出能令这个P(w(1:T), V(1:T))最大的隐性序列.这个算法被称为维特比算法(Viterbi Algorithm).
4.3 学习(Learning)
学习是在给出HMM的结构的情况下(比如说假设已经知道该大叔有3只骰子,每只骰子有6面),计算出最有可能的模型参数.
(公式太多,请具体看我博客中的推导机器学习 --- 4. 大内密探HMM(隐马尔可夫)围捕赌场老千)
5. HMM 的应用
以上举的例子是用HMM对掷骰子进行建模与分析。当然还有很多HMM经典的应用,能根据不同的应用需求,对问题进行建模。
但是使用HMM进行建模的问题,必须满足以下条件,
1.隐性状态的转移必须满足马尔可夫性。(状态转移的马尔可夫性:一个状态只与前一个状态有关)
2. 隐性状态必须能够大概被估计。
在满足条件的情况下,确定问题中的隐性状态是什么,隐性状态的表现可能又有哪些.
HMM适用于的问题在于,真正的状态(隐态)难以被估计,而状态与状态之间又存在联系。
5.1 语音识别
语音识别问题就是将一段语音信号转换为文字序列的过程. 在个问题里面
隐性状态就是: 语音信号对应的文字序列
而显性的状态就是: 语音信号.
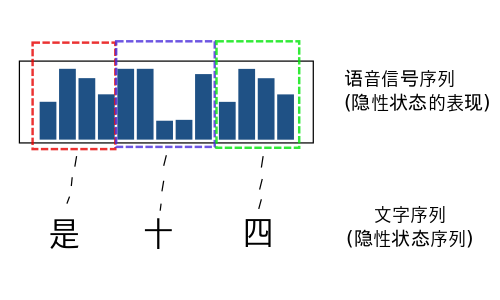
HMM模型的学习(Learning): 语音识别的模型学习和上文中通过观察骰子序列建立起一个最有可能的模型不同. 语音识别的HMM模型学习有两个步骤:
1. 统计文字的发音概率,建立隐性表现概率矩阵B
2. 统计字词之间的转换概率(这个步骤并不需要考虑到语音,可以直接统计字词之间的转移概率即可)
语音模型的估计(Evaluation): 计算"是十四”,"四十四"等等的概率,比较得出最有可能出现的文字序列.
5.2 手写识别
这是一个和语音差不多,只不过手写识别的过程是将字的图像当成了显性序列.
5.3 中文分词
“总所周知,在汉语中,词与词之间不存在分隔符(英文中,词与词之间用空格分隔,这是天然的分词标记),词本身也缺乏明显的形态标记,因此,中文信息处理的特有问题就是如何将汉语的字串分割为合理的词语序。例如,英文句子:you should go to kindergarten now 天然的空格已然将词分好,只需要去除其中的介词“to”即可;而“你现在应该去幼儿园了”这句表达同样意思的话没有明显的分隔符,中文分词的目的是,得到“你/现在/应该/去/幼儿园/了”。那么如何进行分词呢?主流的方法有三种:第1类是基于语言学知识的规则方法,如:各种形态的最大匹配、最少切分方法;第2类是基于大规模语料库的机器学习方法,这是目前应用比较广泛、效果较好的解决方案.用到的统计模型有N元语言模型、信道—噪声模型、最大期望、HMM等。第3类也是实际的分词系统中用到的,即规则与统计等多类方法的综合。”[1]使用HMM进行中文分词.
5.4 HMM实现拼音输入法
拼音输入法,是一个估测拼音字母对应想要输入的文字(隐性状态)的过程(比如, ‘pingyin’ -> 拼音)
WARNING:这篇文章是给零基础人士看的。目标是让普通初中生以及只有初中基础人士无障碍理解HMM框架。追求数学严谨性人士、追求用简洁符号表达模型的同学以及数理基础良好的大神请自行移步参阅文献。
讲这种东西就得先搞清HMM到底干了什么,初学者很容易对“模型在干嘛”这个问题上犯晕。我个人特别讨厌跟初学者上来就讲state space/transition matrix/emission probability云云的讲法(注:比如《统计学习方法》李航博士那种讲法。虽然用来准备面试很方便,但初学者肯定会被符号和几个概念绕晕了;另外,私以为他换掉符号和前人文献不保持一致的做法又会让初学者又多了一道坎去翻。总之,不太厚道)。因为初学时,对大多非理科出身的人而言,用抽象的名词与符号描述的“语言系统”还没固化在脑袋里。用抽象符号在那儿讲就好比“一群人还没学会走,就逼着他们快点跑”。这是不太现实的。
综上,用复杂抽象的语言描述不合适的,这个学习曲线过于陡峭,别人需要时间消化。基于此原因,我发现,对零基础小伙伴们用游戏的例子去类比地解释往往比较容易降低学习难度,比如这样讲:
我是一战士,修炼出了三种战斗形态,分别为暴怒态,正常状态和防御态。同时我也会三个被动技能,分别是普通平A,爆击(攻击伤害翻倍),吸血(生命汲取)。
我在暴怒状态下打出暴击的概率是80%,打出吸血概率为5%;
在平衡形态下,打出暴击的比率为30%,打出吸血的概率是20%;
在防御形态下,暴击成功概率为5%,吸血概率为60%。
总结一下,战士在不同状态下能打出技能的概率不一样。
本来,战士这个职业在暴怒态时,身边会有一圈红光环;防御态时,会有一圈蓝光环。但是,现在我正在玩游戏,游戏突然出了个bug:有个傻x程序员改了游戏的代码,他给写崩了,从此战士身边光环都看不见了。那我没法通过看脚下的光环知道战士在爆什么状态了。
话说,现在问题来了:由于看不到脚下光环,我只能估计“战士”在爆什么状态;但我现在打一boss,砍10次,发现8次都是暴击,血哗哗地翻倍在掉,你觉得我这战士最可能是爆了什么状态?
(每次用这个不规范的例子和新手讲,他们立刻就懂了;而且他们接下来还会问:"’暴怒状态’不能总持续吧?这不科学,应该限定个一段时间后,暴怒状态消失的概率为50%...."你瞧瞧连状态转换的transition prob自己都能假设出来了,都会抢答了都lol...“HMM的在干什么”的问题很容易地让他们就理解了)
综上,一个战士的状态会不断随时间变化;然后他的被动技能发动概率会因为所处不同状态而不同。这就是HMM想表达的东西。并且我们还可以通过它回答一些有趣的问题:通过战士发动的技能来推测战士所出的状态。
这个例子只是个感性认识,它其实只是告诉了我们hmm比较“像什么东西”。显然,我们还需要更规范更严谨地去介绍什么是HMM,去规范化这个模型。这个例子里的“战士”可以换成其它答案里的天气,换成硬币等等。但无论用什么说法,我们已经能通过这个例子抓住核心问题了:HMM模型就是这样一个系统——它有一个能不断改变的隐藏的状态(在这个例子里就是战士爆的状态。它会变,而且由于一个码农的缘故,状态变得不可见)在持续地影响它的外在表现(在这个例子里就是战士打出的技能是暴击、平a、还是吸血的概率)。再重复一遍:HMM模型就是这样一个系统——它有一个会随时间改变的隐藏的状态,在持续地影响它的外在表现。
现在我们再继续规范一下这个例子,让它更贴近那种严谨描述。
因为我们知道战士打人总爆击,角色特别bug,这没法玩啊。所以我们要限制一下战士爆状态。
我们在游戏里做了个限制:
我们设定,战士一开始进入游戏世界时是正常状态的。而且,每过一段时间(比如1分钟),战士就会自动爆一次状态。最后,每一次爆发还和上一次状态爆的状态是什么有关:
1.上一次如果是正常状态,那下次变为暴怒的概率比较大。下次转换成暴怒状态,平衡状态或防御状态的概率我们假设分别为60%,30%,10%。这保证了战士职业下次能有较大的概率能打出暴击!
2.同理,若当我们上次在暴怒态时,下次继续保持暴怒态的概率就得限制一下。下次继续保持暴怒的概率就设为10%,而转换成正常状态的概率是60%,转换成防御态的概率是30%;
3.如果上次是防御态,那么我们也让它下次也尽量变正常。(不然总吸血啊)那他下次转成其它三态的概率(三态和以上对应书写顺序一致)分别为为10%,60,30%。
这样服务器就能限制战士的爆暴怒态的次数,让它不那么imba。
顺便提一下,其实以上的这种限定——让战士下一次爆不同状态的概率只和上次处在什么状态有关系——叫马尔可夫性质(markov property)。
经过这样的设定后,不仅仅战士这个职业不会那么imba,而且,我们可以靠以上这些数字来计算之前只能感性理解的问题了。比如:我这个战士在第一分钟的时候是正常状态,那么我第二分钟赶去死亡谷打一个boss能暴击的概率是多少?(这个当作思考题,提示:想想两个问题,上一状态和下一状态间转换的概率是多少?不同状态下发不同技能的概率是多少?)
最后总结一下。以上例子中讲明了HMM的五样“要素”:
1.状态和状态间转换的概率
2.不同状态下,有着不同的外在表现的概率。
3.最开始设置的初始状态
4.能转换的所有状态的集合
5.能观察到外在表现的结合
Hidden 说明的是状态的不可见性;Markov说明的是状态和状态间是markov chain。这就是为什么叫Hidden Markov Model。
我相信你们再去看其它答案里写的就明白多了。
ps:懂了是什么之后再去看paper就好多了。没记错的话去,看《A tutorial on Hidden Markov Models and selected applications in Speech recognition》。另外,HMM除了上文提到的“五要素”,还有“三个基本问题”。这文章将hmm的三个基本问题讲得很清楚。
其它扯淡回答:
如何通俗易懂地介绍Gaussian Process? - 知乎用户的回答
什么是狄利克雷分布?狄利克雷过程又是什么? - 知乎用户的回答
链接:http://www.zhihu.com/question/20962240/answer/64187492
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
隐形马尔可夫模型,英文是 Hidden Markov Models,所以以下就简称 HMM。
既是马尔可夫模型,就一定存在马尔可夫链,该马尔可夫链服从马尔可夫性质:即无记忆性。也就是说,这一时刻的状态,受且只受前一时刻的影响,而不受更往前时刻的状态的影响。
在这里我们仍然使用非常简单的天气模型来做说明。
<img src="https://pic4.zhimg.com/648a55725e67d718d97d6a475891d70b_b.png" data-rawwidth="600" data-rawheight="566" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/648a55725e67d718d97d6a475891d70b_r.png">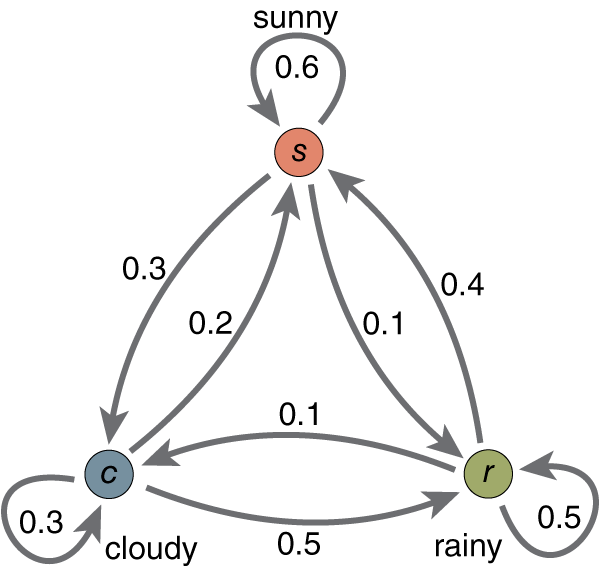
在这个马尔可夫模型中,存在三个状态,Sunny, Rainy, Cloudy,同时图片上标的是各个状态间的转移概率(如果不明白什么是转移概率,那建议先去学习什么是马尔可夫再来看HMM)。
现在我们要说明什么是 HMM。既是隐形,说明这些状态是观测不到的,相应的,我们可以通过其他方式来『猜测』或是『推断』这些状态,这也是 HMM 需要解决的问题之一。
举个例子,我女朋友现在在北京工作,而我还在法国读书。每天下班之后,她会根据天气情况有相应的活动:或是去商场购物,或是去公园散步,或是回家收拾房间。我们有时候会通电话,她会告诉我她这几天做了什么,而闲着没事的我呢,则要通过她的行为猜测这几天对应的天气最有可能是什么样子的。
以上就是一个简单的 HMM,天气状况属于状态序列,而她的行为则属于观测序列。天气状况的转换是一个马尔可夫序列。而根据天气的不同,有相对应的概率产生不同的行为。在这里,为了简化,把天气情况简单归结为晴天和雨天两种情况。雨天,她选择去散步,购物,收拾的概率分别是0.1,0.4,0.5, 而如果是晴天,她选择去散步,购物,收拾的概率分别是0.6,0.3,0.1。而天气的转换情况如下:这一天下雨,则下一天依然下雨的概率是0.7,而转换成晴天的概率是0.3;这一天是晴天,则下一天依然是晴天的概率是0.6,而转换成雨天的概率是0.4. 同时还存在一个初始概率,也就是第一天下雨的概率是0.6, 晴天的概率是0.4.
<img src="https://pic4.zhimg.com/792e033ff9b0418b3b6c9bbaef30fd83_b.png" data-rawwidth="623" data-rawheight="477" class="origin_image zh-lightbox-thumb" width="623" data-original="https://pic4.zhimg.com/792e033ff9b0418b3b6c9bbaef30fd83_r.png">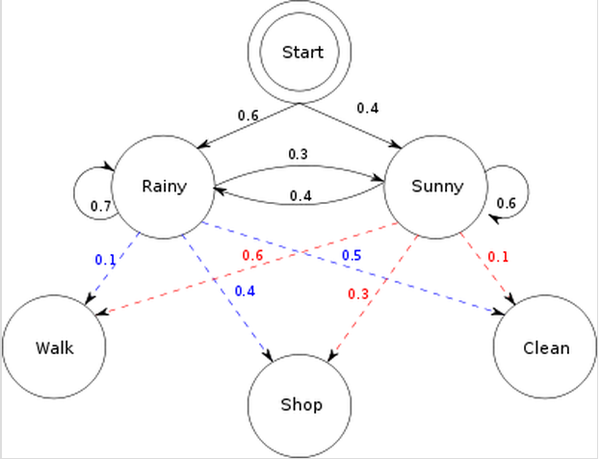
根据以上的信息,我们得到了 HMM的一些基本要素:初始概率分布 π,状态转移矩阵 A,观测量的概率分布 B,同时有两个状态,三种可能的观测值。
现在,重点是要了解并解决HMM 的三个问题。
问题1,已知整个模型,我女朋友告诉我,连续三天,她下班后做的事情分别是:散步,购物,收拾。那么,根据模型,计算产生这些行为的概率是多少。
问题2,同样知晓这个模型,同样是这三件事,我女朋友要我猜,这三天她下班后北京的天气是怎么样的。这三天怎么样的天气才最有可能让她做这样的事情。
问题3,最复杂的,我女朋友只告诉我这三天她分别做了这三件事,而其他什么信息我都没有。她要我建立一个模型,晴雨转换概率,第一天天气情况的概率分布,根据天气情况她选择做某事的概率分布。(惨绝人寰)
而要解决这些问题,伟大的大师们分别找出了对应的算法。问题一,Forward Algorithm,向前算法,或者 Backward Algo,向后算法。 问题二,Viterbi Algo,维特比算法。问题三,Baum-Welch Algo,鲍姆-韦尔奇算法(中文好绕口)。
尽管例子有些荒谬(天气情况要复杂的多,而且不太可能满足马尔可夫性质;同时,女朋友要做什么往往由心情决定而不由天气决定。而从问题一来看,一定是天数越多,这个概率就会越低;从问题三来看,观察到的行为越多,模型才能更准确一些),但是应该已经简单却又详尽地解释了什么是 HMM。如果只是想了解个大概,到此为止。
===========================我是分割线====================================
分割线以下的,就是具体如何解决这三大问题。需要数学基础,概率基础。
问题1的解决1:遍历算法。
要计算产生这一系列行为的概率,那我们把每一种天气情况下产生这些行为都罗列出来,那每种情况的和就是这个概率。有三天,每天有两种可能的天气情况,则总共有种情况.
举例其中一种情况 : P(下雨,下雨,下雨,散步,购物,收拾)=P(第一天下雨)P(第一天下雨去散步)P(第二天接着下雨)P(下雨去购物)P(第三天还下雨)P(下雨回家收拾)=0.6X0.1X0.7X0.4X0.7X0.5=0.00588
当然,这里面的 P(第二天接着下雨)当然是已知第一天下雨的情况下,第二天下雨的概率,为0.7.
将八种情况相加可得,三天的行为为{散步,购物,收拾}的可能性为0.033612. 看似简单易计算,但是一旦观察序列变长,计算量就会非常庞大(的复杂度,T 为观测序列的长度)。
问题1 的解决2:向前算法。
先计算 t=1时刻,发生『散步』一行为的概率,如果下雨,则为 P(散步,下雨)=P(第一天下雨)X P(散步 | 下雨)=0.6X0.1=0.06;晴天,P(散步,晴天)=0.4X0.6=0.24
t=2 时刻,发生『购物』的概率,当然,这个概率可以从 t=1 时刻计算而来。
如果t=2下雨,则 P(第一天散步,第二天购物, 第二天下雨)= 【P(第一天散步,第一天下雨)X P(第二天下雨 | 第一天下雨)+P(第一天散步,第一天晴天)X P(第二天下雨 | 第一天晴天)】X P(第二天购物 | 第二天下雨)=【0.06X0.7+0.24X0.3】X0.4=0.0552
如果 t=2晴天,则 P(第一天散步,第二天购物,第二天晴天)=0.0486 (同理可得,请自行推理)
如果 t=3,下雨,则 P(第一天散步,第二天购物,第三天收拾,第三天下雨)=【P(第一天散步,第二天购物,第二天下雨)X P(第三天下雨 | 第二天下雨)+ P(第一天散步,第二天购物,第二天天晴)X P(第三天下雨 | 第二天天晴)】X P(第三天收拾 | 第三天下雨)=【0.0552X0.7+0.0486X0.4】X0.5= 0.02904
如果t=3,晴天,则 P(第一天散步,第二天购物,第三天收拾,第三天晴天)= 0.004572
那么 P(第一天散步,第二天购物,第三天收拾),这一概率则是第三天,下雨和晴天两种情况的概率和。0.02904+0.004572=0.033612.
以上例子可以看出,向前算法计算了每个时间点时,每个状态的发生观测序列的概率,看似繁杂,但在 T 变大时,复杂度会大大降低。
<img src="https://pic4.zhimg.com/489523ae4ffe659de5f7c73c074cef6f_b.png" data-rawwidth="340" data-rawheight="269" class="content_image" width="340">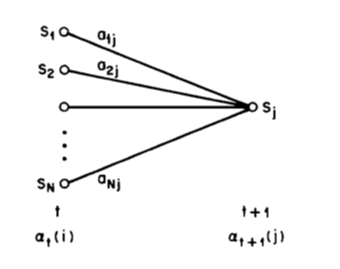
问题1的解决3:向后算法
顾名思义,向前算法是在时间 t=1的时候,一步一步往前计算。而相反的,向后算法则是倒退着,从最后一个状态开始,慢慢往后推。
初始化: (第一次使用知乎的公式编辑,还蛮靠谱的嘛)
递推:
=0,.7x0.5x1+0.3x0.1x1=0.38
其中第一项则是转移概率,第二天下雨转到第三天下雨的概率为0.7;第二项则是观测概率,第三天下雨的状况下,在家收拾的概率为0.5;第三项就是我们定义的向后变量(backward variable)。
同理推得
结束:P(散步,购物,收拾) ==0.6×0.1×0.1298+0.4×0.6×0.1076
=0.033612
<img src="https://pic3.zhimg.com/1a89bf925b4c1af2cc17416764d1d60e_b.png" data-rawwidth="340" data-rawheight="295" class="content_image" width="340">
三种算法的答案是一致的。
问题2的解决:维特比算法
维特比算法致力于寻找一条最佳路径,以便能最好地解释观测到的序列。
初始化:
初始路径:
递推,当然是要找出概率比较大的那条路径。
那么,到达第二天下雨这一状态的最佳路径,应该是:
也就是说,第一天是晴天的可能性更大。
同样地,可以推得,
结束:比较 的大小,发现前者较大,则最后一天的状态最有可能是 下雨天。
回推:根据 可知,到达第三天下雨这一状态,最有可能是第二天也下雨,再根据
可知,到达第二天下雨这一状态,最有可能是第一天是晴天。
由此,我们得到了最佳路径,即,晴天,雨天,雨天。
问题3的解决:Baum-Welch 算法。
此问题的复杂度要远远高于前两种算法,不是简单解释就能说的清楚的了。若有兴趣,可以私信我。
我非常赞同霍金老头的『多一个公式,少十个读者』的说法,但是自己写起来,却发现用英文的这些公式好像比中文更简洁易懂,中文好像更罗里吧嗦一些。
依然怀着非常感恩的心,再次感谢这个问题以及回答问题的这些热心的人们给我带来的帮助。
链接:http://www.zhihu.com/question/20962240/answer/48444087
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
这个HMM的应用是来自于東京大学(東大真是所神奇的学校)的一个研究组在IJCAI 2007年的一篇文章,日文版的标题是《隠れマルコフモデルに基づくピアノ運指の自動決定》,英文版的标题是《Automatic Determination of Piano Fingering based on Hidden Markov Model》,论文的网页在这里:Sagayama & Ono Lab。从网页可以知道,这篇文中的工作其实至少从2005年就开始了。
愚以为在我目前能做到的范围内最好的学习一篇论文并让其对自己有用的方法就是重现之,所以此答案也按照现在回看当时重现过程的过程的顺序写。对于这个问题,我觉得比较重要的一点是“如何将HMM模型套用到这个问题上”,什么是HMM中的“因”,什么是HMM中的“果”,这个HMM在解决与琴键指法有关的问题是如何对应到HMM的三大任务=Scoring, Matching, Training的。然后你就很容易知道问题的输入是什么、输出是什么,然后将其转化为一个用程序员思维能解决的问题。
所以就开始俺们的钢琴运指自动决定之旅吧:
为了先有一个印象并明确问题的背景和定义,先看开门见山的介绍图:
<img data-rawheight="338" data-rawwidth="450" src="https://pic1.zhimg.com/7499958e318dbb13f88a64fb74678794_b.jpg" class="origin_image zh-lightbox-thumb" width="450" data-original="https://pic1.zhimg.com/7499958e318dbb13f88a64fb74678794_r.jpg">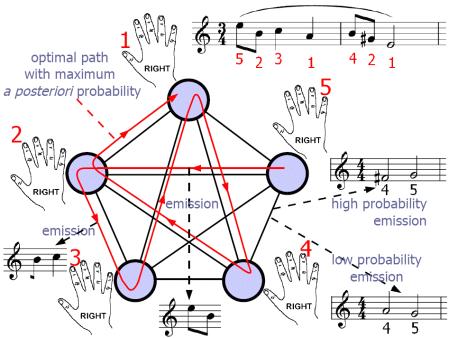
这个图的意思是说,“你有一个HMM模型,往里面丢入琴谱,它就能给你输出指法。”
这图,首先大致说明了这个HMM里面有哪些变量:
・HMM中的“Hidden State(隐藏状态)”的是右手的五个手指编号(1=大拇指,2=食指,3=中指,4=无名指,5=小指)。
・HMM的“Emission(可见输出状态链)”是“所弹奏出来的音符”。
在这篇论文的问题描述中,“弹奏的音符”是知道的,“所用的指法”是不知道的。因为不知道,所以就需要用算法去算出来。所以这里和事实上的过程其实是反过来的:在此论文中,“指法”是原因,“音符”是结果,“事情发生”就是“指法导致了弹奏出这些音符”;这个过程在英文版论文中称为“fingering-to-performance conversion”,与事情看起来发生的顺序是相反的(一个人是先看到琴谱,然后才有指法的,这种现实中的发生顺序来说的过程在英文版论文中称为“score-to-fingering conversion”)。此论文中的概率用贝叶斯术语的名字来说就是:
・P(指法)是先验概率(Prior Probability/事前確率=じぜんかくりつ)、
・P(音符|指法)是似然度(Likelihood/尤度関数=ゆうどかんすう)、
・P(音符,指法)是联合概率(Joint Probability/結合確率=けつごうかくりつ)、
・P(音符)是边缘概率(Marginal Probability/周辺確率=しゅうへんかくりつ)、
・P(指法|音符)是后验概率(Posterior Probability/事後確率=じごかくりつ)。【通过改变指法来最大化这个概率的过程,就是MAP,即Maximum A-Posteriori过程,即是Viterbi Search法做的事情。】
然后,它说明了这个HMM的性质:
・这个HMM是一个“Mealy Machine”,因为它是在转换的过程中输出的,而不是当处于某个状态时输出的(在某个状态输出,就应是Moore Machine)。“Mealy Machine”的输出概率函数是关于边的起始结点和终止结点的函数。所以,图右方的“High probability emission”意思是,“当我先用右手无名指弹奏了#F之后,再用右手小指弹奏#F右边的G的概率比较高”;图右下角的“Low probability emission”的意思是,“当我先用右手的无名指弹奏了G之后,再用右手小指弹奏G左边的#F的概率比较低”。
・也就是说,输出某个音符的概率可以写成,用语言解释就是“在我现在用第f_{i-1}个手指弹奏y_{i-1}这个音时,我接下来要用第f_i个手指奏y_i这个音的概率”。[1]
・至于状态转换概率则是不分Moore Machine和Mealy Machine的,都是,也就是当前用了某个手指之后,会转而使用下一个手指的概率。这个概率表可以用来对某些现象进行建模,譬如说:“中指和无名指连续交替按键很不灵活”,就可以通过使得赋给
与
更低的值来达成。
有了这些定义,我们就能知道如何完成HMM中的三个任务:
・Scoring:给定一个指法,通过打分看它好弹还是不好弹。输入是指法,输出是分数。
・Matching:给定一个琴谱,给出最好的指法。输入是琴谱,输出是指法。
・Training:给定琴谱和指法组成的测试用例,通过改变HMM中的参数,来使得这个HMM能“学习”到测试用例中潜藏的规则。
首先是Scoring,就是这个HMM是如何计算某个指法安排出现的概率的,以上面的图为例:
・图中的红箭头经过的结点表示状态转换,也就是“5、2、3、1、4、2、1”。在处于某个状态时,所进行的状态转换只依赖于当前的状态是什么。
・红箭头经过的边表示所输出的可见状态,也就是右上角的音符:E5, B4, C5, A4, B4, #G4, E。
・除了第一个音符以外,其它的音符都是按照上面的输出概率公式计算的。比如说用此指法弹奏第二个B4的条件概率就是。
这就是“给定一个指法和所弹奏的音符,计算出它被弹奏出来的概率是多少”的过程。如果只给定音符,再罗列出所有可能的指法,就能从中计算出概率最大的指法。但是直接罗列速度会慢,所以可以用Viterbi Search来更快地计算出来。
那么就来到了第二点,Matching,就是给定一个谱子后,如何知道在当前的HMM中,最好的指法是什么?这是计算最大后验概率 P(指法|音符) 的问题。如前所述这其实是一个通过动态规划来达到比枚举高效很多的编程问题,其基本的样子是从给定的谱子的第一个音符开始,一直往后走,在每一步都保存“弹到当前的音符时最好的指法是什么”的信息供下一步使用,省掉计算时间的。此算法称为Viterbi Search(Viterbi algorithm),它所搜索的空间可称为Trellis Graph (Trellis (graph))。因为维基百科上的Viterbi算法的Python代码是可以直接拷贝下来运行的,为了有所不同,以下就以图中的片段来举个例子,运行一遍论文中所述的演算法(这里强制第一个音符必须用5指,所以开始概率是设成了{0.01, 0.01, 0.01, 0.01, 1.00}):
图中t表示输出状态链的“时间”,也就是音符的下标,从0开始。
当t=0的时候弹奏的概率就是开始概率。t>0时弹奏的概率就涉及输出概率与转换概率。
以下和论文中一样,只考虑只用右手、只有单音(没有和弦)的情况。
<img data-rawheight="392" data-rawwidth="658" src="https://pic3.zhimg.com/a694b1d7f89b5b7e45c77e582552b4be_b.jpg" class="origin_image zh-lightbox-thumb" width="658" data-original="https://pic3.zhimg.com/a694b1d7f89b5b7e45c77e582552b4be_r.jpg">t=[0, 1]时的概率,就表示弹奏前两个音符所用的各种指法的概率。图中的网状图就是一个Trellis graph,每条边对应一次HMM状态转换同时也对应着(在t>0时的)弹出一个音符的动作;每个结点对应着一个手指,也就是能够用以弹奏某个音的某个手指。每条有颜色的路径就表示某个片段中的指法安排。Viterbi算法是一种动态规划,所以它在每一步时都需要把“对于每个手指,从开始到这一步时,这一步必用这个手指的最高的概率和对应的指法”存在动态规划表里,以供下一步的计算使用。 t=[0, 1]时的概率,就表示弹奏前两个音符所用的各种指法的概率。图中的网状图就是一个Trellis graph,每条边对应一次HMM状态转换同时也对应着(在t>0时的)弹出一个音符的动作;每个结点对应着一个手指,也就是能够用以弹奏某个音的某个手指。每条有颜色的路径就表示某个片段中的指法安排。Viterbi算法是一种动态规划,所以它在每一步时都需要把“对于每个手指,从开始到这一步时,这一步必用这个手指的最高的概率和对应的指法”存在动态规划表里,以供下一步的计算使用。
t=[0, 1]时的概率,就表示弹奏前两个音符所用的各种指法的概率。图中的网状图就是一个Trellis graph,每条边对应一次HMM状态转换同时也对应着(在t>0时的)弹出一个音符的动作;每个结点对应着一个手指,也就是能够用以弹奏某个音的某个手指。每条有颜色的路径就表示某个片段中的指法安排。Viterbi算法是一种动态规划,所以它在每一步时都需要把“对于每个手指,从开始到这一步时,这一步必用这个手指的最高的概率和对应的指法”存在动态规划表里,以供下一步的计算使用。
从这个图所反映的动态规划表中可以看出,用右手小拇指弹第一个音E5,然后再用右手食指弹第二个音B4的概率是所有25种可能中概率最高的,其概率高达10^(-2.31009)。这个概率并没有什么实际意义,只在对所有指法间进行比较有意义。相比起来,用右手大拇指弹奏第一个音E5再用右手小拇指弹奏第二个音B4的概率就低多了,只有10^(-13.0603),这是个穿指的动作,而穿指从大拇指穿到小拇指也比从食指、中指和无名指穿到小指要简单,所以指向t=1时的5的箭头是从1指向5的。这是Viterbi算法在构建动态规划表中的规则。
这个表的内容会用到t=[0,1,2]的情况,如下:
<img data-rawheight="285" data-rawwidth="499" src="https://pic1.zhimg.com/a114926515f1fd8ca6cb448faf904938_b.jpg" class="origin_image zh-lightbox-thumb" width="499" data-original="https://pic1.zhimg.com/a114926515f1fd8ca6cb448faf904938_r.jpg">指的就是此图在t=[0,1]中的箭头都是在上一张中出现过的箭头的意思。 指的就是此图在t=[0,1]中的箭头都是在上一张中出现过的箭头的意思。
指的就是此图在t=[0,1]中的箭头都是在上一张中出现过的箭头的意思。
再继续一步:
<img data-rawheight="285" data-rawwidth="502" src="https://pic2.zhimg.com/c6c00a9d5d305db03fa00eedc0ab6c95_b.jpg" class="origin_image zh-lightbox-thumb" width="502" data-original="https://pic2.zhimg.com/c6c00a9d5d305db03fa00eedc0ab6c95_r.jpg">
将这个过程重复到最后,就得到了这一段谱子的指法:
<img data-rawheight="283" data-rawwidth="803" src="https://pic2.zhimg.com/4f3f7f542c3b209ab07d193103048319_b.jpg" class="origin_image zh-lightbox-thumb" width="803" data-original="https://pic2.zhimg.com/4f3f7f542c3b209ab07d193103048319_r.jpg">在这张动态规划表中,概率最大的是[5231421]这个指法,也就是图中所示的。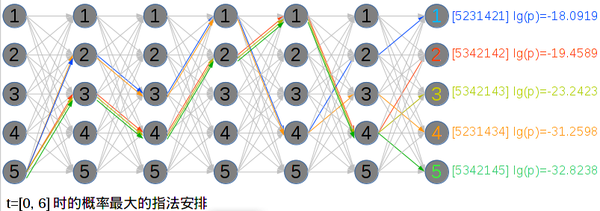 在这张动态规划表中,概率最大的是[5231421]这个指法,也就是图中所示的。
在这张动态规划表中,概率最大的是[5231421]这个指法,也就是图中所示的。
以上就是这篇论文中所描述的“用HMM来计算给定的一段乐谱的最佳指法”的方法。
最后,就是Training阶段——如何通过训练HMM参数的方法来“学到”测试用例呢?
在实现此论文的过程中我对于具体计算输出概率的方法是用了一些猜测的,所以与原文可能有所不符,所以将论文中所出现的7个乐谱片段输入后,有3、4个音符的指法与文中提及的结果不同。所以我想通过调整参数的方法让我的HMM的输出结果能与论文中相符。
说是Bonus阶段是,因为论文中没有明示这一阶段是如何做的,但是有提及根据常理是可以把这个训练过程做成的。
这回用于训练用的是随机梯度下降法(Stochastic gradient descent),这种方法可以用于参数都是连续变量、目标函数也是连续变量的模型。其最基本的更新规则是 ,其中w是参数,alpha是学习速率,p是Viterbi算法算出的最佳指法与训练用例指法的分数之差,当梯度下降完成时,训练用例中的指法就会变成所有指法中最优的并被Viterbi找到,也就是p会等于0 。
训练过程中给HMM模型不停地出示正确的指法就像是不停背诵英语单词强化记忆一样。以下示出用论文中出现的7个片段用作训练的样子。训练中能修正的HMM参数有以下这些:
・转换概率(25个)
・五个手指与黑/白键的接触点的Y轴坐标(10个)
一共是35个可以调整的参数。
在训练前,我们猜测出来的参数做成的HMM输出的指法能够符合这7个训练用例中的5个(以下为论文中的谱子的截图,黑色的圈是在论文中用作指法合理性的讨论的,和此回需要进行的重现算法的任务没有关系):
<img data-rawheight="574" data-rawwidth="429" src="https://pic1.zhimg.com/31a8e86dfb2286ac9f726370a1a93624_b.jpg" class="origin_image zh-lightbox-thumb" width="429" data-original="https://pic1.zhimg.com/31a8e86dfb2286ac9f726370a1a93624_r.jpg">
可以看到图中有两处红字是我们当前的HMM输出的指法与训练用例的指法不同之处。现在将这七个片段放入Stochastic Descent过程中,随着其进行,可以将参数的变化和目标函数的变化画在下图中:
<img data-rawheight="964" data-rawwidth="748" src="https://pic2.zhimg.com/6247ceec36a100c1c42519cc72615a01_b.jpg" class="origin_image zh-lightbox-thumb" width="748" data-original="https://pic2.zhimg.com/6247ceec36a100c1c42519cc72615a01_r.jpg">三栏中,最上栏是分数之差,也就是对每个训练用例,给定的训练指法与当前最好的指法的分数之差,为0表示给定的训练指法就是最佳指法。中间栏是转换概率。最下栏是10个接触点的Y轴坐标。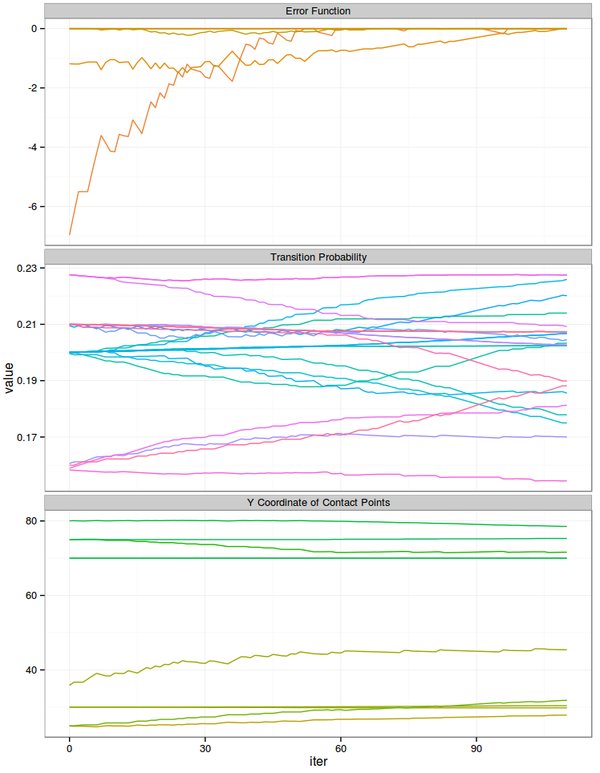 三栏中,最上栏是分数之差,也就是对每个训练用例,给定的训练指法与当前最好的指法的分数之差,为0表示给定的训练指法就是最佳指法。中间栏是转换概率。最下栏是10个接触点的Y轴坐标。
三栏中,最上栏是分数之差,也就是对每个训练用例,给定的训练指法与当前最好的指法的分数之差,为0表示给定的训练指法就是最佳指法。中间栏是转换概率。最下栏是10个接触点的Y轴坐标。
可以看到分数之差随着训练的进行总体上的趋势是在接近0。当训练完成后,这个HMM就能复制出图中所示的7个片段中的指法啦! \^O^/
如果再展开还有许多问题:对于Stochastic Descent还可以通过自动调整学习速率的方法来加快计算;训练过程不一定是Consistent的,意即总会到某个时候不可能完全复制出训练用例中的指法;和弦和双手两个声部的处理,但是这些就是不同于此问题的另一问题了,而且我也不是非常理解,所以就不在这里写啦。
[1]:在重现这篇论文的结果时我们认为尽管原论文并没有说,但是y_{i-1}还是有必要出现在竖线的右边的。按我们的理解,原文并非是完全没有说,而是隐含地用了y_{i-1}来得到计算输出概率时高斯分布的中心点的位置。
链接:http://www.zhihu.com/question/20962240/answer/24641399
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
它有三个要素,
1. 可见随机变量:用来描述你所感兴趣的物理量,随时间变化
2. 隐含的状态变量:一个假设的存在,每个时间点的物理量背后都对应一个状态量
3. 变量间的关系:用概率的方法(通常是概率密度函数)描述以下三个关系或变量:初始状态量,当前的隐含状态量与下一个隐含状态量间关系(此处还用到马尔科夫假设:当前隐含状态只取决于前一个隐含状态),当前的隐含状态量与可见随机量间关系
举例说,我用HMM去描述一组不同类型的手部动作,每个动作有一种特定的模式,例如用手打拍子,2/4拍(上下上),3/4拍(上下右上),4/4拍(上下左右上),现实中,即使重复同样的拍子,手所划过的轨迹还是会有差别,但不同的拍子,其模式完全不同,用HMM去描述一种动作,所对应的可见随机变量就是手的位置,隐含状态变量就是上下左右四个大致位置,变量间关系用你假设的的概率密度函数描述。至于参数估计,推断等技术问题,有成熟高效的算法可以处理,这也是HMM受欢迎的原因。详细内容参考Rabiner的经典论文:An introduction to hidden Markov models。
补充:
1. 隐含状态变量是假设的存在,并不一定有对应的物理解释,此例状态值取上下左右四个值是为了好理解,实现模型时可以取任意数量的状态值,是一个可调参数。
2. 隐含状态变量通常是离散的,可见状态变量可离散可连续。
链接:http://www.zhihu.com/question/20962240/answer/61025758
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
之前上汉语语音课准备语音识别部分时一位朋友发给我的,作为理工科白痴我也看懂了。找不到原链,侵立删
1.题目背景:
从前有个村儿,村里的人的身体情况只有两种可能:健康或者发烧。
假设这个村儿的人没有体温计或者百度这种神奇东西,他唯一判断他身体情况的途径就是到村头我的偶像金正月的小诊所询问。
月儿通过询问村民的感觉,判断她的病情,再假设村民只会回答正常、头晕或冷。
有一天村里奥巴驴就去月儿那去询问了。
第一天她告诉月儿她感觉正常。
第二天她告诉月儿感觉有点冷。
第三天她告诉月儿感觉有点头晕。
那么问题来了,月儿如何根据阿驴的描述的情况,推断出这三天中阿驴的一个身体状态呢?
为此月儿上百度搜 google ,一番狂搜,发现维特比算法正好能解决这个问题。月儿乐了。
2.已知情况:
隐含的身体状态 = { 健康 , 发烧 }
可观察的感觉状态 = { 正常 , 冷 , 头晕 }
月儿预判的阿驴身体状态的概率分布 = { 健康:0.6 , 发烧: 0.4 }
月儿认为的阿驴身体健康状态的转换概率分布 = {
健康->健康: 0.7 ,
健康->发烧: 0.3 ,
发烧->健康:0.4 ,
发烧->发烧: 0.6
}月儿认为的在相应健康状况条件下,阿驴的感觉的概率分布 = {
健康,正常:0.5 ,冷 :0.4 ,头晕: 0.1 ;
发烧,正常:0.1 ,冷 :0.3 ,头晕: 0.6
}
阿驴连续三天的身体感觉依次是: 正常、冷、头晕 。
3.题目:
已知如上,求:阿驴这三天的身体健康状态变化的过程是怎么样的?
4.过程:
根据 Viterbi 理论,后一天的状态会依赖前一天的状态和当前的可观察的状态。那么只要根据第一天的正常状态依次推算找出到达第三天头晕状态的最大的概率,就可以知道这三天的身体变化情况。
传不了图片,悲剧了。。。
1.初始情况:
- P(健康) = 0.6,P(发烧)=0.4。
2.求第一天的身体情况:
计算在阿驴感觉正常的情况下最可能的身体状态。
- P(今天健康) = P(健康|正常)*P(健康|初始情况) = 0.5 * 0.6 = 0.3
- P(今天发烧) = P(发烧|正常)*P(发烧|初始情况) = 0.1 * 0.4 = 0.04
那么就可以认为第一天最可能的身体状态是:健康。
3.求第二天的身体状况:
计算在阿驴感觉冷的情况下最可能的身体状态。
那么第二天有四种情况,由于第一天的发烧或者健康转换到第二天的发烧或者健康。
- P(前一天发烧,今天发烧) = P(发烧|前一天)*P(发烧->发烧)*P(冷|发烧) = 0.04 * 0.6 * 0.3 = 0.0072
- P(前一天发烧,今天健康) = P(健康|前一天)*P(发烧->健康)*P(冷|健康) = 0.04 * 0.4 * 0.4 = 0.0064
- P(前一天健康,今天健康) = P(发烧|前一天)*P(健康->健康)*P(冷|健康) = 0.3 * 0.7 * 0.4 = 0.084
- P(前一天健康,今天发烧) = P(健康|前一天)*P(健康->发烧)*P(冷|发烧) = 0.3 * 0.3 *.03 = 0.027
那么可以认为,第二天最可能的状态是:健康。
4.求第三天的身体状态:
计算在阿驴感觉头晕的情况下最可能的身体状态。
- P(前一天发烧,今天发烧) = P(发烧|前一天)*P(发烧->发烧)*P(头晕|发烧) = 0.027 * 0.6 * 0.6 = 0.00972
- P(前一天发烧,今天健康) = P(健康|前一天)*P(发烧->健康)*P(头晕|健康) = 0.027 * 0.4 * 0.1 = 0.00108
- P(前一天健康,今天健康) = P(发烧|前一天)*P(健康->健康)*P(头晕|健康) = 0.084 * 0.7 * 0.1 = 0.00588
- P(前一天健康,今天发烧) = P(健康|前一天)*P(健康->发烧)*P(头晕|发烧) = 0.084 * 0.3 *0.6 = 0.01512
那么可以认为:第三天最可能的状态是发烧。
5.结论
链接:http://www.zhihu.com/question/20962240/answer/34079435
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
你知道的是:
HMM 研究的问题有,比如说,我们连续观察妹子的表现(),我们来猜她最可能的心情(
)是什么。
举个例子。如果我们知道妹子的表现()依次为
"不理你 -> 不理你 -> 不理你 -> 戳了你一下"
那么,我们求出最有可能的心情()序列是
"生气 -> 生气 -> 在考虑要不要原谅你 -> 决定原谅你" (*)
其实到这里就可以了,下面我试着直观地解释下我们是如何求出来这个最可能的心情序列的。
妹子的表现是已知的。我们求最可能的心情序列时,需要试着同时最大化两个量:
- 这个心情序列本身的可能性。如果你告诉我最大可能的心情序列是
"生气 -> 开心 -> 生气 -> 开心"
……这个序列的可能性本身就太小了吧。 - 在这个心情序列下观察到表现的可能性。如果你告诉我最大可能的心情序列是
"开心 -> 开心 -> 开心 -> 开心 "
这个序列的可能性倒是不小,妹子一直很开心倒是很常见的。可是 心情是开心 表现为不理我 的概率也太小了吧……
所以说,上面(*)不单是个可能的序列,而且符合我们观察到的表现。
链接:http://www.zhihu.com/question/20962240/answer/34202445
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
---------------以下正题----------------
首先说马尔科夫,这是基础,没有这个一切都是胡闹,之前很多答案并没有过多的顾及马尔科夫模型的问题,答案只能说是个隐概率模型。马尔科夫模型描述的是当前状态只和前一状态相关的情况。
【先打比方】打麻将坐庄,比如现在是东风庄,那么(理想情况下)下把有75%的概率是北风(被胡牌),25%还是东风(自己胡牌),而跟上一把是不是东风庄没有任何关系。这就是一个标准的马尔科夫过程,(考虑心里因素时也可能不是,这里不谈)
【再说不恰当的案例】而最多举得天气的例子,就不是很合适,第一,明天下雨的概率现实中绝对不仅依赖于今天是不是晴天,这在建模时需要首先考虑模型的精度,注意,概率模型是以[你所认知的]世界为基础的,在某个问题下,你可以认为全人类得癌症的概率是多少多少,在其他问题下,你可能认为男性女性得癌症的概率分别是多少,这取决于模型的精度和你掌握的信息来定。绝大部分问题不是天生就是马尔科夫的,首先,夏天冬天不一样,梅雨季节更不一样,用术语说,这是时变的,当然你可以在你的模型中忽略这些,”假装”他是马尔科夫的。
【再说具体点】作为马尔科夫的过程,就和HMM应用会扯上关系的问题来说,要注意,任何时候,当系统出于某一状态时(也可以是以某一概率处于某些状态),下周期处于状态的概率要是确定的(比如刚说的75%,和25%,数值可以不知道,但一定是不会变的某个值),而不依赖于之前的状态(前天)或系统的其他状态(冬季)。
【如果数学一些】由于任何状态迁移到其他状态的概率是确定的,所以我们如果知道本周期的概率分布,就可以求出下周期的分布,方法用中学时代的描述就是分类讨论,而本科阶段开始就用矩阵乘简单处理,这个就不多说了。要注意,能够写成矩阵(也就说概率是确定的)很重要。如果不是,那么就是其他问题了,比如半隐马尔科夫,如果有时间我下面会说,没有的话先坑着。
----------------开始HMM,之后讨论有什么用,因为你看完这段肯定不知道怎么用-----------------------
HMM针对的问题,必须是一个上面规范定义的过程,为什么?因为数学的求解能力是非常有限的,或许看似简单的变化,导致的可能是不可接受的计算量,
【先说定义】所谓的隐,就是看不见的意思。借用一句有切身感觉的话说”当看到方便面中油包变成固体的时候,宅男知道,冬天来了“。这里的季节(冬天)就是隐藏起来的变量,宅男(观察者)不出屋,所以看不到天气,他只可以看到方便面调料(这叫观测)。所谓的HMM,用来描述一个我们看不到系统状态,只能看到观测(但观测和状态之间有确定性的概率关系)的状态。
【需要强调的】第一就是刚刚的最后一句,观测和系统的状态之间必须有确定的概率关系,这个关系和系统的运行时间,之前的观测,之前的状态等等都不能有任何关系。也就是任何时候我看到固体的调料包,就代表(90%冬天,10%刚刚春天)。第二就是刚说到的,HMM是用来描述这样一个系统使用的工具,就好像我们可以用矩阵代表一个线性方程组一样。我们可以用HMM模型来表示一个这样的系统,定义它的量包括:(1)每个观测下,系统处于某状态的概率,共计观测类型*系统状态类型 个,(由于概率总和为1,有效的量少观测类型个)。(2)本周期系统处于某状态时,下周期各状态的概率分布(就是刚刚马尔科夫中的那个矩阵),数量为 状态类型 * 状态类型 个(同上,有效的略少)。(3)系统的初始状态分布,就是第一周期时候系统是什么样子,这样我们就可以计算出每周期的概率了。这个值一共有 状态类型个(有效的少一个)
----------------------------下面是怎么用HMM-----------------------------
刚刚已经说过什么是HMM了,就和高斯分布一样,HMM是描述系统分布的一种手段,那我们怎么用呢?(这里我们只谈用法思路,计算办法网上很多,思路和模型本身关系不是那么密切,就是算了)
【最常见的使用方法】我们说使用HMM时,一般时在解决这样的一个问题:当我有一个观测序列(样本)时,它和我所有已经知道的HMM模型哪个最匹配。我们通常会为每个我们预计要检测的东西训练一个HMM(用该类的大量样本)。
【沿用刚刚的例子】刚在举例子的时候没想太周全,这里就将就看吧。如果说我们可以用一个HMM描述宅男看方便面的问题的话,那么我们最可能干的事情就是,通过观察方便面油包状态,估计宅男所处的城市。是不是有点意外?居然不是看季节?其实HMM使用时最容易犯的错误就是弄混隐变量和我们的分类结果的关系了,关系就是没有关系!我们首先选取了世界各地宅男看到的油包状态,比如北京的1万个宅男,深圳的1万个,北冰洋的1万个宅男各3年的观察,作为样本,这时,我们系统一共涉及到了这样几个信息:(1)我们预计有3个HMM模型,分别是北京,深圳,北冰洋(2)我们只有2个观测结果,即油包是固态还是液态(3)我们的隐变量通常并不明确,但本例中我们估计系统状态可能是4季,所以我们设定4个隐变量,注意:这4个就代表四季在实际应用中完全就是猜的,而且不见得训练的结果就是四季!
【解决例子中的问题】为了完成这个工作,我们要干以下几步:(1)分别利用每个地区的1万个样本,各自训练一个HMM,方法可参考网上各种文章。(2)在实际判断一个宅男的地理位置时,拿到一个观察序列,然后分别计算北京、深圳、北冰洋的HMM能够得到这个观测序列的概率。概率最大的,就是该宅男的所在提。
--------------------------------------最后多说几句------------------------------------
HMM的求解是一个非常麻烦的事情,可以看成是一个EM迭代的过程,而且求解的变量非常多,这就直接导致了一些约束:(1)观测的种类不能很多,尤其不能是连续过程(2)系统隐状态也不宜太多(3)要检测的目标,也就是HMM的数量,倒不是大问题,因为这是线性增长的,多一倍求解时间只多一倍,一般都能接受
小妖怪随意碰到一个坛子,从里面拿出一个小球出来,把小球从窗子递出来,外面能看到小球的颜色。之后把小球放回去,再重复这个过程,就能得到一个序列。
在这个过程中存在两个随机过程,选择坛子和从坛子里选择小球,而中间的状态转移过程是被隐藏的。
其中重要的参数包含:一组状态的集合(不同坛子);输出符号的集合(不同颜色的小球);状态转移矩阵(从某个坛子跑到下一个坛子的概率);输出符号的概率分布(某个坛子抓出某种颜色小球的概率);初始状态概率分布(随机选择第一个坛子的概率)。
在课上听老师这么讲的……
链接:http://www.zhihu.com/question/20962240/answer/73054935
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
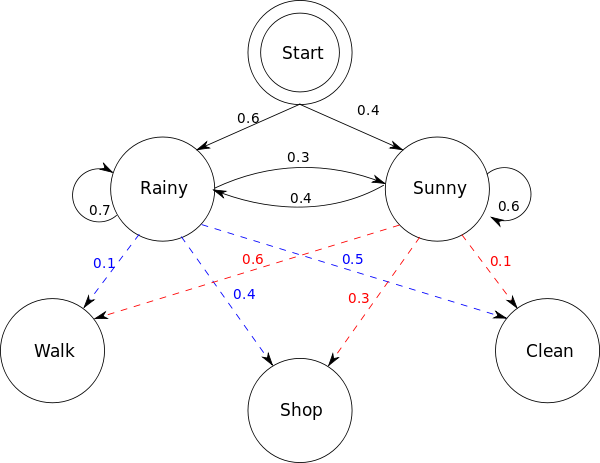
假设你有一个住得很远的朋友,他每天跟你打电话告诉你他那天做了什么.你的朋友仅仅对三种活动感兴趣:公园散步,购物以及清理房间.他选择做什么事情只凭天气.你对于他所住的地方的天气情况并不了解,但是你知道总的趋势.在他告诉你每天所做的事情基础上,你想要猜测他所在地的天气情况.你认为天气的运行就像一个马尔可夫链.其有两个状态 "雨"和"晴",但是你无法直接观察它们,也就是说,它们对于你是隐藏的.每天,你的朋友有一定的概率进行下列活动:"散步", "购物", 或 "清理". 因为你朋友告诉你他的活动,所以这些活动就是你的观察数据.这整个系统就是一个隐马尔可夫模型HMM.
你知道这个地区的总的天气趋势,并且平时知道你朋友会做的事情.也就是说这个隐马尔可夫模型的参数是已知的.你可以用程序语言(Python)写下来:
states = ('Rainy', 'Sunny')
observations = ('walk', 'shop', 'clean')
start_probability = {'Rainy': 0.6, 'Sunny': 0.4}
transition_probability = {
'Rainy' : {'Rainy': 0.7, 'Sunny': 0.3},
'Sunny' : {'Rainy': 0.4, 'Sunny': 0.6},
}
emission_probability = {
'Rainy' : {'walk': 0.1, 'shop': 0.4, 'clean': 0.5},
'Sunny' : {'walk': 0.6, 'shop': 0.3, 'clean': 0.1},
}
在这些代码中,start_probability代表了你对于你朋友第一次给你打电话时的天气情况的不确定性(你知道的只是那个地方平均起来下雨多些).在这里,这个特定的概率分布并非平衡的,平衡概率应该接近(在给定变迁概率的情况下){'Rainy': 0.571, 'Sunny': 0.429}< transition_probability 表示基于马尔可夫链模型的天气变迁,在这个例子中,如果今天下雨,那么明天天晴的概率只有30%.代码emission_probability 表示了你朋友每天做某件事的概率.如果下雨,有 50% 的概率他在清理房间;如果天晴,则有60%的概率他在外头散步.
全部来自维基百科。解释的非常清楚。
Alice 和 Bob 是异地
Bob 那边的天气包括晴天和雨天,但是每天的天气与之前一天的天气相关
Bob 每天可能做三种事情,出游,购物和扫地
但是 Bob 某天具体做什么的概率与当天天气相关
Alice 每天问 Bob, 你今天做什么
Alice 并不清楚 Bob 那边的天气,Bob 不用告诉她,她也不用看天气预报
但是她可以根据 Bob 每天做的事情,天气的先验概率,和天气的转化规律等因素估计 Bob 那边这几天的天气规律。
作者:小小的寂寞
链接:http://www.zhihu.com/question/20962240/answer/100355680
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
链接:http://www.zhihu.com/question/20962240/answer/110582360
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
比如声音识别,我说"你好吗",计算机接受的声学信号波段是123,计算机要根据隐性马尔可夫模型逆推回"你好吗",已知123,以及已知在数据库里你是1的概率是0.5,已知好是2的概率是0.6,吗是3的概率是0.7,我们知道语音识别是和上下文相关的,所以2好跟在1你后面的概率是0.8,3吗跟在2好的概率是0.9,这样利用123推测是你好吗的概率是0.5*0.6*0.7*0.8*0.9,这个值作为一个训练结果的参数。但是计算机在求出最优解前还要尝试别的可能。利用隐性马尔可夫模型训练时,每次都产生一个这样的参数,比如也可能是"您好妈",或者"泥郝嘛",因为上下文的关系前者的概率值肯定比后者大,后者就被淘汰,然后再对比,再淘汰,这样一次次训练算出概率最大的值就是"你好吗"。当然解码时一条条算太慢,配合用维特比算法根据上下文的关系来提高效率会快一点,但那就和HMM模型无关了。
为什么叫"隐性"马尔可夫模型:
因为123是未知的波形图,不能根据数据库里没有的声波段内容来推测和数据的配对,也就是说无法做到推测1是你的概率。但是我们数据库里有汉字,所以可以根据汉字的声波数据来推测和未知声波的重合程度,也就是你是1的概率。也就是先知道你,才能推测出你是1的概率。因为不知道1,所以无法推测出1是你的概率。这样一来,马尔可夫链就变成隐性的了。
欢迎批评指正!
英文网址:Hidden Markov model
中文网址:隐马尔可夫模型
&lt;img src="https://pic4.zhimg.com/18e6b6f6bb68bfbda079e555722dc75b_b.jpg" data-rawwidth="600" data-rawheight="463" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/18e6b6f6bb68bfbda079e555722dc75b_r.jpg"&gt;
其实 Hagnesta 已在题目的评论里提到了。
作者:song wang
链接:http://www.zhihu.com/question/20962240/answer/33547346
来源:知乎
著作权归作者所有,转载请联系作者获得授权。
hmmgenerate 从一个马尔可夫模型产生一个状态序列和输出序列;
hmmestimate 计算转移和输出的极大似然估计;
hmmtrain 从一个输出序列计算转移和输出概率的极大似然估计;
hmmviterbi 计算一个隐马尔可夫模型最可能的状态变化过程;
hmmdecode 计算一个给定输出序列的后验状态概率。
下面部分介绍如何使用这些函数来分析隐马尔可夫模型。
1. 产生一个测试序列
下面代码产生上面简介中模型的转移和输出矩阵:
TRANS = [.9 .1; .05 .95;];
EMIS = [1/6, 1/6, 1/6, 1/6, 1/6, 1/6;...
7/12, 1/12, 1/12, 1/12, 1/12, 1/12];
要从模型产生一个随机的状态序列和输出序列,使用hmmgenerate:
[seq,states] = hmmgenerate(1000,TRANS,EMIS);
输出中,seq是输出序列,states是状态序列。hmmgenerate在第0步从状态1开始,在第一步转移到状态i1
,并返回i1作为状态的第一个入口。
2. 估计状态序列
给定了转移和输出矩阵TRANS和EMIS,函数hmmviterbi使用Viterbi算法计算模型给定输出序列seq最有可能
通过的状态序列:
likelystates = hmmviterbi(seq, TRANS, EMIS);
likelystates是和seq一样长的序列。计算hmmvertibi的精度如下:
sum(states == likelystates) / length(states)
ans =
0.8680
3. 估计转移和输出矩阵
函数hmmestimate和hmmtrain用于估计给定输出序列seq的转移和输出矩阵TRANS和EMIS。
使用hmmestimate
[TRANS_EST, EMIS_EST] = hmmestimate(seq, states)
TRANS_EST =
0.9065 0.0935
0.0406 0.9594
EMIS_EST =
0.1452 0.1516 0.1581 0.1968 0.1581 0.1903
0.5841 0.0754 0.0986 0.0812 0.0841 0.0768
由上面使用方式可知,hmmestimate函数需要事先知道了得到输出序列seq,以及得到此结果的状态变化序
列。
使用hmmtrain
如果不知道状态序列,但是知道TRANS和EMIS的初始猜测,那就可以使用hmmtrain来估计TRANS和EMIS。
假设已知如下初始猜测:
TRANS_GUESS = [.85 .15; .1 .9];
EMIS_GUESS = [.17 .16 .17 .16 .17 .17;.6 .08 .08 .08 .08 08];
TRANS和EMIS的估计如下:
[TRANS_EST2, EMIS_EST2] = hmmtrain(seq, TRANS_GUESS, EMIS_GUESS)
TRANS_EST2 =
0.9207 0.0793
0.0370 0.9630
EMIS_EST2 =
0.1792 0.1437 0.1436 0.1855 0.1509 0.1971
0.5774 0.0775 0.1042 0.0840 0.0859 0.0710
hmmtrain使用迭代算法来不断修改TRANS_GUESS和EMIS_GUESS,使得每一步修改得到的矩阵都更加可能产生观测序列seq。当前后两个两次迭代矩阵的变化在一个小的容错范围内时,迭代停止。如果算法无法达到容错的范围,则迭代到达一定次数时就会停止,并返回一个警告提示。默认的最大迭代次数为100。
如果算法达不到目标误差范围,则可以通过增加迭代次数和/或加大容错误差值来使其获得较合适结果:
改变迭代次数maxiter:hmmtrain(seq,TRANS_GUESS,EMIS_GUESS,'maxiterations',maxiter)
改变容错误差tol:hmmtrain(seq, TRANS_GUESS, EMIS_GUESS, 'tolerance', tol)
影响hmmtrain输出的矩阵可靠性的两点因素:
(1)算法收敛于局部极值,这点可以使用不同的初始猜测矩阵来尝试解决;
(2)序列seq太短而无法很好的训练矩阵,可以尝试使用较长的序列。
4. 估计后验状态概率(不太理解)
一个输出序列seq的后验状态概率是在特定状态下的模型产生在seq中一个输出的条件概率。假定seq已经给出,你可以使用hmmdecode得到后验状态概率。
PSTATES = hmmdecode(seq,TRANS,EMIS)
输出为一个M * N的矩阵。M是状态的个数,L是seq的长度。PSTATES(i, j)是模型在状态i时,产生seq第j个输出的条件概率。
楼上这个是matlab自带的统计工具箱里的吧? 可是这个只能用于离散HMM。
和楼主一样的问题,我下了Kevin Murphy 的Hidden Markov Model (HMM) Toolbox for Matlab,可是他给的介绍有点太少了,也不怎么看得懂。 有没有高手做过这方面研究呢?
[综]隐马尔可夫模型Hidden Markov Model (HMM)的更多相关文章
- 隐马尔科夫模型(hidden Markov model, HMM)
- 隐马尔可夫模型(Hidden Markov Model)
隐马尔可夫模型(Hidden Markov Model) 隐马尔可夫模型(Hidden Markov Model, HMM)是一个重要的机器学习模型.直观地说,它可以解决一类这样的问题:有某样事物存在 ...
- 隐马尔科夫模型(hidden Markov Model)
万事开头难啊,刚开头确实不知道该怎么写才能比较有水平,这篇博客可能会比较长,隐马尔科夫模型将会从以下几个方面进行叙述:1 隐马尔科夫模型的概率计算法 2 隐马尔科夫模型的学习算法 3 隐马尔科夫模型 ...
- 从马尔可夫模型(Markov Model)到隐马尔可夫模型(Hidden Markov Model)
1.参考资料: 博客园 - 刘建平随笔:https://www.cnblogs.com/pinard/p/6945257.html 哔站up主 - 白手起家的百万富翁:https://www.bili ...
- 隐马尔科夫模型(Hidden Markov Models)
链接汇总 http://www.csie.ntnu.edu.tw/~u91029/HiddenMarkovModel.html 演算法笔记 http://read.pudn.com/downloads ...
- 隐马尔科夫模型(Hidden Markov Models) 系列之五
转自:http://blog.csdn.net/eaglex/article/details/6458541 维特比算法(Viterbi Algorithm) 找到可能性最大的隐藏序列 通常我们都有一 ...
- 隐马尔科夫模型(Hidden Markov Models) 系列之三
转自:http://blog.csdn.net/eaglex/article/details/6418219 隐马尔科夫模型(Hidden Markov Models) 定义 隐马尔科夫模型可以用一个 ...
- 隐马尔科夫模型(Hidden Markov Models) 系列之二
转自:http://blog.csdn.net/eaglex/article/details/6385204 隐含模式(Hidden Patterns) 当马尔科夫过程不够强大的时候,我们又该怎么办呢 ...
- 隐马尔科夫模型(Hidden Markov Models) 系列之一
转自:http://blog.csdn.net/eaglex/article/details/6376826 介绍(introduction) 通常我们总是对寻找某一段时间上的模式感兴趣,这些模式可能 ...
随机推荐
- 克隆虚拟机重启服务时 Error:No suitable device found: no device found for connection "System eth0"
故障说明: 在克隆几台虚拟机,发现启动后不能配置IP地址等信息,使用linux命令: “ifup eth0”也不能激活网卡, 而在使用"service network restart&quo ...
- C++ Daily 《5》----虚函数表的共享问题
问题: 包含一个以上虚函数的 class B, 它所定义的 对象是否共用一个虚函数表? 分析: 由于含有虚函数,因此对象内存包含了一个指向虚函数表的指针,但是这个指针指向的是同一个虚函数表吗? 实验如 ...
- <转>Win7系统下利用U盘安装Ubuntu_12.04实现双系统教程
目前网上流传的关于Linux 系统的安装教程可是说是五彩缤纷,之前想采用硬盘安装方式,由于配置问题未能正确安装,现研究了下U盘安装,根据互联网上的一些资料及自己的总结,在Windows7 系统下采用U ...
- iOS Orientation bug
Every September means pain for iOS developers- you need to make sure your old apps/code run on the n ...
- 使用 OAuth2-Server-php 在 Yii 框架上搭建 OAuth2 Server
原文转自 http://www.cnblogs.com/ldms/p/4565547.html Yii 有很多 extension 可以使用,在查看了 Yii 官网上提供的与 OAuth 相关的扩展后 ...
- ionic中的service简单写法
在service中写服务 服务名叫feedService .service('feedService',function($ionicLoading,$q,$http){ return{ //获取反馈 ...
- CCI4.4/LintCode Balanced Binary Tree, Binary Tree, Binary Search Tree
Binary Tree: 0到2个子节点; Binary Search Tree: 所有左边的子节点 < node自身 < 所有右边的子节点: 1. Full类型: 除最下面一层外, 每一 ...
- ActiveMQ的初夜
Producer Flow Control mq自己实现了Flow Control(流量控制,默认开启),在mq的版本中,4.x和5.x流量控制实现原理并不相同,前者通过 TCP Flow Contr ...
- Surprise团队第四周项目总结
Surprise团队第四周项目总结 项目进展 这周我们小组的项目在上周的基础上进行了补充,主要注重在注册登录界面的改进优化与美观,以及关于人计算法的学习与初步实现. 我们小组针对上次APP中界面出现的 ...
- VMware卸载出现“the msi failed”解决办法
最近被VMware卸载搞烦死掉,最后通过这个帖子解决. http://www.cnblogs.com/noble/p/4144267.html 总结:有啥软件使用问题最好找官方的FAQ找答案,不然百度 ...