061 hive中的三种join与数据倾斜
一:hive中的三种join
1.map join
应用场景:小表join大表
一:设置mapjoin的方式:
)如果有一张表是小表,小表将自动执行map join。
默认是true。
<property>
<name>hive.auto.convert.join</name>
<value>true</value>
</property>
)判断小表
<property>
<name>hive.mapjoin.smalltable.filesize</name>
<value>25000000</value>
</property>
二:隐式执行
/*+ MAPJOIN(tb_name) */
两种方式说明:

2.reduce join
应用场景:大表join大表
但是效率不高。
3.SMB join(sort merger bucket):hash取余
排序合并桶。
条件:A桶个数必须与B桶的个数相同,或者B桶的个数是A桶的个数的倍数
例如:
A:4
B:8
——》A的每一个桶joinB桶的两个小桶就可以了。
设置:
hive.auto.convert.sortmerge.join=true
二:数据倾斜
1.原因
指在mapreduce中某一个值数据量过多,导致reduce的负载不均衡
主要分为
join
group by
三:参考数据倾斜
1.链接
https://my.oschina.net/leejun2005/blog/178631
2.前言
在做Shuffle阶段的优化过程中,遇到了数据倾斜的问题,造成了对一些情况下优化效果不明显。
主要是因为在Job完成后的所得到的Counters是整个Job的总和,优化是基于这些Counters得出的平均值,而由于数据倾斜的原因造成map处理数据量的差异过大,
使得这些平均值能代表的价值降低。Hive的执行是分阶段的,map处理数据量的差异取决于上一个stage的reduce输出,所以如何将数据均匀的分配到各个reduce中,就是解决数据倾斜的根本所在。
3.操作
其实就两种,因为,count distinct的底层就是group by。
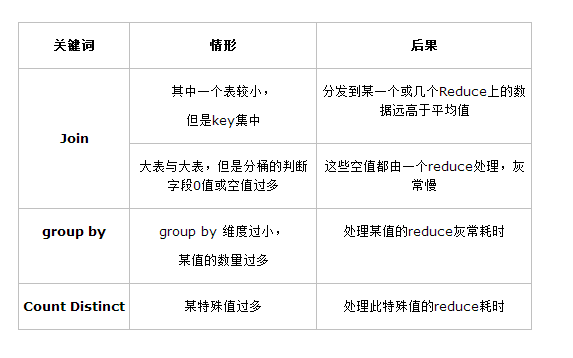
4.原因
1)、key分布不均匀
2)、业务数据本身的特性
3)、建表时考虑不周
4)、某些SQL语句本身就有数据倾斜
5.表现
任务进度长时间维持在99%,查看任务监控页面,发现只有少量的reduce子系统未完成。
单一的reduce的记录与平均记录差距过大,通常达到3倍甚至更多。
四:解决方案
1.主要针对的group by
map的combiner
hive.groupby.skewindata
替换值,将不要的值替换掉,然后过滤掉。
2.参数调节
)hive.map.aggr=true
map端的combiner,提前聚合一下。
)hive.groupby.skewindata=true
不按照key进行分区,map端的结果到了reduce后就进行一次聚合,达到reduce负载均衡。
这时,再进行一次mapreduce,group by key 分布到reduce,实现最终的聚合。
2.SQL调节
)如何Join:
关于驱动表的选取,选用join key分布最均匀的表作为驱动表
做好列裁剪和filter操作,以达到两表做join的时候,数据量相对变小的效果。
)大小表Join:
使用map join让小的维度表(1000条以下的记录条数) 先进内存。在map端完成reduce.
)大表Join大表:
把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
)count distinct大量相同特殊值
count distinct时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理,直接过滤,在最后结果中加1。
如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
)group by维度过小:
采用sum() group by的方式来替换count(distinct)完成计算。
五:业务场景(实际中会遇到的情况)
1.空值产生数据倾斜
)过滤
select * from log a
join users b
on a.user_id is not null
and a.user_id = b.user_id
union all select * from log a where a.user_id is null; )赋予新的值 select *
from log a
left outer join users b
on case when a.user_id is null then concat(‘hive’,rand() ) else a.user_id end = b.user_id;
)比较
方法2比方法1效率更好,不但io少了,而且作业数也少了。
解决方法1中 log读取两次,jobs是2。解决方法2 job数是1 。
2适合无效 id (比如 -99 , ’’, null 等) 产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上 ,解决数据倾斜问题。
2.不同的数据类型进行关联
)原因
用户表中user_id字段为int,log表中user_id字段既有string类型也有int类型。当按照user_id进行两个表的Join操作时,默认的Hash操作会按int型的id来进行分 配,这样会导致所有string类型id的记录都分配到一个Reducer中。
)把数字类型转换成字符串类型
select * from users a
left outer join logs b
on a.usr_id = cast(b.user_id as string)
3.表不大不小
)解决
select /*+mapjoin(x)*/* from log a
left outer join (
select /*+mapjoin(c)*/d.*
from ( select distinct user_id from log ) c
join users d
on c.user_id = d.user_id
) x
on a.user_id = b.user_id;
061 hive中的三种join与数据倾斜的更多相关文章
- Hive中的三种不同的数据导出方式介绍
问题导读:1.导出本地文件系统和hdfs文件系统区别是什么?2.带有local命令是指导出本地还是hdfs文件系统?3.hive中,使用的insert与传统数据库insert的区别是什么?4.导出数据 ...
- SQL Server中的三种Join方式
1.测试数据准备 参考:Sql Server中的表访问方式Table Scan, Index Scan, Index Seek 这篇博客中的实验数据准备.这两篇博客使用了相同的实验数据. 2.SQ ...
- Oracle中的三种Join 方式
基本概念 Nested loop join: Outer table中的每一行与inner table中的相应记录join,类似一个嵌套的循环. Sort merge join: 将两个表排序,然后再 ...
- 014-HQL中级4-Hive中的三种不同的数据导出方式介绍
根据导出的地方不一样,将这些方式分为三种:(1).导出到本地文件系统:(2).导出到HDFS中:(3).导出到Hive的另一个表中.为了避免单纯的文字,我将一步一步地用命令进行说明. 一.导出到本地文 ...
- Hive中的4种Join方式
common join 普通join,性能较差,存在Shuffle map join 适用情况:大表join小表时,做不等值join 原理:将小表数据广播到各个节点,存储在内存中,在map阶段直接jo ...
- Hive的三种Join方式
Hive的三种Join方式 hive Hive中就是把Map,Reduce的Join拿过来,通过SQL来表示. 参考链接:https://cwiki.apache.org/confluence/dis ...
- Asp.Net中的三种分页方式
Asp.Net中的三种分页方式 通常分页有3种方法,分别是asp.net自带的数据显示空间如GridView等自带的分页,第三方分页控件如aspnetpager,存储过程分页等. 第一种:使用Grid ...
- MapReduce三种join实例分析
本文引自吴超博客 实现原理 1.在Reudce端进行连接. 在Reudce端进行连接是MapReduce框架进行表之间join操作最为常见的模式,其具体的实现原理如下: Map端的主要工作:为来自不同 ...
- Hive三种不同的数据导出的方式
转自:http://blog.chinaunix.net/uid-27177626-id-4653808.html Hive三种不同的数据导出的方式,根据导出的地方不一样,将这些方法分为三类:(1)导 ...
随机推荐
- luogu P2516 [HAOI2010]最长公共子序列
传送门 首先那个\(O(n^2)\)的dp都会吧,不会自己找博客或者问别人,或是去做模板题(误) 对以下内容不理解的,强势推荐flash的博客 我们除了原来记录最长上升子序列的\(f_{i,j}\), ...
- strstr函数字符串匹配问题
题目链接:http://acm.sdut.edu.cn/onlinejudge2/index.php/Home/Index/problemdetail/pid/2772.html AC代码: #inc ...
- winform程序生成条形码并且并且保存到本地文件中。
今天公司让做一个输入数字.字母生成条形码并且可以以图片格式保存到本地.当看到这个需求时候感觉很搞笑,明明可以用文本框搞定的东西非得做个程序.哎,寄人篱下,不多说了,这就是养兵千日用兵一时. 我在网上找 ...
- 【C++】面试题目:从尾到头打印链表
通过<剑指offer 名企面试官精讲典型编程题>看到一道讲解链表的题目. 题目:输入一个链表的头结点,从尾到头反过来打印出每个结点的值 链表定义如下: typedef struct _NO ...
- Epoll模型
Epoll模型 相比于select,epoll最大的好处在于它不会随着监听fd数目的增长而降低效率.因为在内核中的select实现中,它是采用轮询来处理的,轮询的fd数目越多,自然耗时越多.并且,在l ...
- springboot系列十一、redisTemplate和stringRedisTemplate对比、redisTemplate几种序列化方式比较
一.redisTemplate和stringRedisTemplate对比 RedisTemplate看这个类的名字后缀是Template,如果了解过Spring如何连接关系型数据库的,大概不会难猜出 ...
- jrockit静默安装笔记
操作系统安装版本:CentOS-6.4-i386-minimal JDK安装版本:jrockit-jdk1.6.0_20-R28.1.0-4.0.1-linux-ia32 1.通过SecureFX工具 ...
- ajax返回json对象的两种写法
1. 前言 dataType: 要求为String类型的参数,预期服务器返回的数据类型.如果不指定,JQuery将自动根据http包mime信息返回responseXML或responseText,并 ...
- OneNET麒麟座应用开发之八:采集大气压力等环境参数
采集大气压力和温度也是核算大气标准状况下的各种数据的必须参数,为此我们必须知道压力和温度才能计算标准状况下的各种参数,于此我们需要一个既能检测压力也能检测温度的元件. 1.硬件概述 MS5837压力传 ...
- python之抽象基类
抽象基类特点 1.不能够实例化 2.在这个基础的类中设定一些抽象的方法,所有继承这个抽象基类的类必须覆盖这个抽象基类里面的方法 思考 既然python中有鸭子类型,为什么还要使用抽象基类? 一是我们在 ...