sqlalchemy-查询
User这个类创建的表 User1这个类创建的表
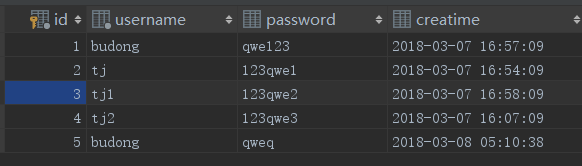

基本查询结果
# 1 查看sql原生语句
rs =session.query(User).filter(User.username=='budong')
print(rs)
# 2 query(module) .all()
rs =session.query(User).filter(User.username=='budong').all() # .all list
print(rs, type(rs[0])) # 索引取值 当query(module) 类型为User类的实例对象
print(rs[0].username,rs[0].id) # rs[0]这个实例对象通过.username,.id取得值
# 3 hasattr() getattr()
# 没有这条数据则会报错超出索引 先判断是否存在hasattr() ,再取值getattr()数据不存在报错
print(hasattr(rs[0], 'username')) # 判断是否有这个username属性 返回值True False
if hasattr(rs[0], 'username'):
print(getattr(rs[0],'username')) # 安全取值
print(rs[0].username) >>> True
>>> budong
>>> budong
# 4 .first() [0]
rs =session.query(User).filter(User.username=='budong').first() # 返回一条数据,无则返回none
rs1 =session.query(User).filter(User.username=='budong')[0] # 取第一条数据无则报错
print(rs, rs1,sep='\n')
print(rs.id, rs1.username) # 取出值
if rs != None:
print(rs)
>>> <User(id=1,username=budong,password=qwe123,createtime=2018-03-07 16:57:09)>
<User(id=1,username=budong,password=qwe123,createtime=2018-03-07 16:57:09)>
>>> 1 budong
>>> <User(id=1,username=budong,password=qwe123,createtime=2018-03-07 16:57:09)>
# 5 query(module的属性)
rs =session.query(User.id).filter(User.username=='tj').all() # all返回list
print(rs) # list
print(rs[0]) # 当query(module的属性) 返回结果为元祖
print(rs[0][0]) >>> [(2,)]
>>> (2,)
>>> 2
# 6 条件查询
# filter_by(直接跟module的属性,以字典形式传参) 并且只能判断 =
rs = session.query(User).filter_by(username='budong').all()
print(rs)
# filter(module.属性) 能判断 == != >= 常用
rs = session.query(User).filter(User.username=='budong').all()
print(rs) >>> [<User(id=1,username=budong,password=qwe123,createtime=2018-03-07 16:57:09)>, <User(id=5,username=budong,password=qweq,createtime=2018-03-08 05:10:38)>]
>>> [<User(id=1,username=budong,password=qwe123,createtime=2018-03-07 16:57:09)>, <User(id=5,username=budong,password=qweq,createtime=2018-03-08 05:10:38)>]
模糊查询
# 7 模糊查询
# like_ notlike
rs = session.query(User).filter(User.username.like('%don%')).all()
print(rs)
rs = session.query(User).filter(User.username.notlike('%don%')).all() # 相反
print(rs)
>>> [<User(id=1,username=budong,password=qwe123,createtime=2018-03-07 16:57:09)>, <User(id=5,username=budong,password=qweq,createtime=2018-03-08 05:10:38)>]
>>> [<User(id=2,username=tj,password=123qwe1,createtime=2018-03-07 16:54:09)>, <User(id=3,username=tj1,password=123qwe2,createtime=2018-03-07 16:58:09)>,
<User(id=4,username=tj2,password=123qwe3,createtime=2018-03-07 16:07:09)>]
# 8 in_ notin 满足一个条件即可
rs = session.query(User).filter(User.username.in_(['budong','tj'])).all()
print(rs)
rs = session.query(User).filter(User.username.notin_(['budong','tj'])).all() # 相反
print(rs) >>> [<User(id=1,username=budong,password=qwe123,createtime=2018-03-07 16:57:09)>, <User(id=2,username=tj,password=123qwe1,createtime=2018-03-07 16:54:09)>,
<User(id=5,username=budong,password=qweq,createtime=2018-03-08 05:10:38)>]
>>> [<User(id=3,username=tj1,password=123qwe2,createtime=2018-03-07 16:58:09)>, <User(id=4,username=tj2,password=123qwe3,createtime=2018-03-07 16:07:09)>]
# 9 is_ isnot is 用来判断是否为空 是空则取值
rs = session.query(User.username).filter(User.username.is_(None)).all()
print(rs)
rs = session.query(User.username).filter(User.username.isnot(None)).all() # 相反
print(rs) >>> []
>>> [('budong',), ('tj',), ('tj1',), ('tj2',), ('budong',)]
# 10 limit 限制数据条数
rs =session.query(User).filter(User.username=='budong').all()
print(rs)
rs =session.query(User).filter(User.username=='budong').limit(1).all()
print(rs) >>> [<User(id=1,username=budong,password=qwe123,createtime=2018-03-07 16:57:09)>, <User(id=5,username=budong,password=qweq,createtime=2018-03-08 05:10:38)>]
>>> [<User(id=1,username=budong,password=qwe123,createtime=2018-03-07 16:57:09)>]
# 11 offset(n) 不取前n条数据 称为 偏移量:偏移n条数据
rs = session.query(User).filter(User.username=='budong').offset(1).all()
print(rs) >>> [<User(id=5,username=budong,password=qweq,createtime=2018-03-08 05:10:38)>]
# 12 slice 切片 左闭右开
rs = session.query(User).filter(User.username=='budong').slice(0,1).all()
print(rs) >>> [<User(id=1,username=budong,password=qwe123,createtime=2018-03-07 16:57:09)>]
# 13 one 只有一条数据则取值 反之 报错
# rs = session.query(User).filter(User.username=='budong').one() # 满足条件的超过1条,报错
rs = session.query(User).filter(User.username=='tj').one()
print(rs)
>>> <User(id=2,username=tj,password=123qwe1,createtime=2018-03-07 16:54:09)>
# 14 order_by(*args) 排序(按asc)
# 升序
rs = session.query(User.id).filter(User.username=='budong').order_by(User.id).all()
print(rs)
# 降序 需导入降序desc
from sqlalchemy import desc
rs = session.query(User.id).filter(User.username=='budong').order_by(desc(User.id)).all()
print(rs) >>> [(1,), (5,)]
>>> [(5,), (1,)]
# 15 group_by
from sqlalchemy import func,extract
# 按query的属性 进行分组 再统计该属性的所有值出现的次数
rs = session.query(User.username,func.count(User.id)).group_by(desc(User.username)).all()
print(rs) >>> [('tj2', 1), ('tj1', 1), ('tj', 1), ('budong', 2)]
# 16 group_by + having(判断条件 常跟func的count sum avg 等使用) 先分组在执行having
rs = session.query(User.username,func.count(User.id)).group_by(desc(User.username)).\
having(func.count(User.id)>1).all()
print(rs)
rs = session.query(User.username,func.max(User.id)).group_by(User.username).all()
print(rs) # 通过username分组 多条数据的取id最大的那条
rs = session.query(User.username,func.min(User.id)).group_by(User.username).all()
print(rs) # 通过username分组 多条数据的取id最小的那条 >>> [('budong', 2)]
>>> [('budong', 5), ('tj', 2), ('tj1', 3), ('tj2', 4)]
>>> [('budong', 1), ('tj', 2), ('tj1', 3), ('tj2', 4)]
# 17 extract 能获取某部分时间(year,month,day,hour,minute,second) 进行分组及统计
rs = session.query(extract('minute',User.creatime).label('minute'),func.count('minute')).\
group_by('minute').all() # label 取别名
print(rs) >>> [(7, 1), (10, 1), (54, 1), (57, 1), (58, 1)]
# 18 or_ 或者 满足其中一个条件即可 类似in_ notin
rs = session.query(User.username).filter(or_(User.password=='qwe123',User.id>2)).all()
print(rs) >>> [('budong',), ('tj1',), ('tj2',), ('budong',)]
User这个类创建的表 User1这个类创建的表
# 19 多表查询
# mysql中的 内链接cross join 内链接inner join 两者没区别, 内链接的结果会产生笛卡儿积 table1(的每条数据) X table2(的所有数据)
rs = session.query(User.username,User1.name).filter(User.id==User1.id).all() # 通过,直接query两张表= select * from table1,table2 属于内链接cross join
print(rs)
rs = session.query(User.username,User1.name).join(User1,User.id==User1.id).all() # join =内链接inner join
print(rs)
# mysql中的 外链接left join 和 外链接left outer join也没区别
# 外链接outerjoin = left outer join -- sqlalchemy 没有right outer join
rs = session.query(User.username,User1.name).outerjoin(User1,User.id==User1.id).all()
print(rs)we
# 已左表为准 两个表的数据并排显示,左表有多少条数据则显示多少,右边有多余的数据则不取,少于的数据则显示为None数据链接到左表
rs = session.query(User1.name,User.username).outerjoin(User,User.id==User1.id).all() #与上面相比交换表的位置
print(rs) >>> [('budong', 'D'), ('tj', 'A'), ('tj1', 'B'), ('tj2', 'C')]
>>> [('budong', 'D'), ('tj', 'A'), ('tj1', 'B'), ('tj2', 'C')]
>>> [('budong', 'D'), ('tj', 'A'), ('tj1', 'B'), ('tj2', 'C'), ('budong', None)]
>>> [('D', 'budong'), ('A', 'tj'), ('B', 'tj1'), ('C', 'tj2')]
# 20 联合查询 两个表并排显示
rs1 = session.query(User1.name)
rs2 = session.query(User.username)
print(rs1.union(rs2).all()) # union 去重
print(rs1.union_all(rs2).all()) # 显示所有包括重复的数据 'budong'为重复的数据 >>> [('D',), ('A',), ('B',), ('C',), ('budong',), ('tj',), ('tj1',), ('tj2',)]
>>> [('D',), ('A',), ('B',), ('C',), ('budong',), ('tj',), ('tj1',), ('tj2',), ('budong',)]
# 21 子表查询 cross join 产生笛卡儿积
# 原生sql是 select * from table1,table2; table2是这儿的子表
# 声明子表subquery() 子表可以是多个表取出的数据 所以比直接使用 cross join or inner join 能查更多表的相关数据
sql = session.query(User1.name).subquery()
# 父表的每一条数据都匹配子表的所有数据
print(session.query(User.username,sql.c.name).all()) # 固定写法 申明子表的sql.c.属性 >>> [('budong', 'D'), ('tj', 'D'), ('tj1', 'D'), ('tj2', 'D'), ('budong', 'D'), ('budong', 'A'), ('tj', 'A'), ('tj1', 'A'), ('tj2', 'A'), ('budong', 'A'),
('budong', 'B'), ('tj', 'B'), ('tj1', 'B'), ('tj2', 'B'), ('budong', 'B'), ('budong', 'C'), ('tj', 'C'), ('tj1', 'C'), ('tj2', 'C'), ('budong', 'C')]
原生sql语句查询
# 原生SQL查询
sql_1='select username from `user`'
row = session.execute(sql_1) # row =5条数据 row是一个对象 可以 for in 取值 dir(对象)
print(row.fetchone()) # 取出第一条数据 row -1 =4
print(row.fetchmany(2)) # 去出两条数据 row -2 =2
print(row.fetchall()) # 取出所有的数据 row =0 >>> ('budong',)
>>> [('tj',), ('tj1',)]
>>> [('tj2',), ('budong',)]
sql是字符串 可以用到字符串拼接
sql = '''
select * from user where id<%s;
''' %(3)
row = session.execute(sql)
for i in row:
print(i) # 元祖 >>> (1, 'budong', 'qwe123', datetime.datetime(2018, 3, 7, 16, 57, 9))
>>> (2, 'tj', '123qwe1', datetime.datetime(2018, 3, 7, 16, 54, 9))
sqlalchemy-查询的更多相关文章
- tornado 07 数据库—ORM—SQLAlchemy—查询
tornado 07 数据库—ORM—SQLAlchemy—查询 引言 #上节课使用query从数据库查询到了结果,但是query返回的对象是直接可用的吗 #在query.py内输入一下内容 from ...
- sqlalchemy 查询姿势总结
sqlalchemy查询使用 1.带条件查询 查询是最常用的,对于各种查询我们必须要十分清楚,首先是带条件的查询 #带条件查询 rows = session.query(User).filter_by ...
- SQLAlchemy查询
SQLAlchemy查询 结果查询: from databases.wechat import User from config import session def search(): result ...
- SQLAlchemy04 /SQLAlchemy查询高级
SQLAlchemy04 /SQLAlchemy查询高级 目录 SQLAlchemy04 /SQLAlchemy查询高级 1.排序 2.limit.offset和切片操作 3.懒加载 4.group_ ...
- SQLAlchemy(四):SQLAlchemy查询高级
目录 SQLAlchemy04 /SQLAlchemy查询高级 1.排序 2.limit.offset和切片操作 3.懒加载 4.group_by 5.having 6.join 7.subquery ...
- 把SQLAlchemy查询对象转换成字典
1-假设查出来的为单个对象 1-1 在model.py中为模型对象添加字典转换函数: from exts import db class User(db.Model): __tablename__ = ...
- sqlalchemy查询结果类型简析
Sqlalchemy的查询方式有很多种,例如可以查询全部,可以查询符合条件的,可以查询指定字段的.那么这么多种查询,返回的结果是不是一样的呢?作本文记录分析结果. Sql_forengin.py #c ...
- 把SQLAlchemy查询对象转换成字典/json使用(分开)
注:针对的是查询出来的是单条对象 多个对象的话可以使用for循环遍历查询出来的对象列表,也可以使用下面的方法 1.config.py文件 #!/usr/bin/env python #-*- codi ...
- 几种常见sqlalchemy查询:
#简单查询 print(session.query(User).all()) print(session.query(User.name, User.fullname).all ...
- 利用sqlalchemy 查询视图
这个问题 google 百度 中英文搜了一上午.最新的回答还是 7年前.最后自己靠着官方文档的自己改出来一个比较方便的方法 使用环境 python == 3.7.0 SQLAlchemy === 1. ...
随机推荐
- 17mysql2█▓
一.数据库的查询用法 1. 数据表记录的查询: 运算符.虑重.列运算.别名.排序.聚合函数.分组 1.1数据准备 create table exam( id int primary key aut ...
- 自学Linux Shell11.2-echo命令
点击返回 自学Linux命令行与Shell脚本之路 11.2-echo命令 echo命令的功能是在显示器上显示一段文字,一般起到一个提示的作用. 语 法:echo [-n][字符串]或 echo [- ...
- 自学Python1.4-Centos内vim中文乱码问题
自学Python之路 自学Python1.4-Centos内vim中文乱码问题 1. 登陆的系统---区域语言设置 1.1查看安装中文包: 查看系统是否安装中文语言包 (列出所有可用的公共语言环境的名 ...
- oracle导出导入数据库
一.给空表分配空间: 这一步一定要做,否则空表不能导出. 首先连接你要导出的库,在该库上执行以下sql: select 'alter table '||table_name||' allocate e ...
- 【BZOJ4813】[CQOI2017]小Q的棋盘(贪心)
[BZOJ4813][CQOI2017]小Q的棋盘(贪心) 题面 BZOJ 洛谷 题解 果然是老年选手了,这种题都不会做了.... 先想想一个点如果被访问过只有两种情况,第一种是进入了这个点所在的子树 ...
- [CF791D]Bear and Tree Jumps
题目描述 A tree is an undirected connected graph without cycles. The distance between two vertices is th ...
- 结构体练习(C)
结构体存储学生学号.姓名.总分,动态内存分配增加信息,然后排序 # include <stdio.h> # include <malloc.h> //# include < ...
- tf 常用函数 28原则
一个tensorflow图由以下几部分组成: 占位符变量(Placeholder)用来改变图的输入. 模型变量(Model)将会被优化,使得模型表现得更好. 模型本质上就是一些数学函数,它根据Plac ...
- 全面深入介绍C++字符串:string类
http://blog.csdn.net/liuliming3000/article/details/1809385 1 从C到C++ string类 2 string类的构造函数 3 string类 ...
- 使用“DiskGenius”精确隐藏硬盘坏道
现在大家手中可能都有些有坏道的硬盘,也可能现在机器上的硬盘也出问题了.硬盘有坏道,肯定不会全部都是坏道,不能使用了.但我们因此而不能使用了,那么就太可惜了.所以,只要把有坏道的区域隐藏起来,就如同使用 ...