gensim使用方法以及例子
gensim是一个Python的自然语言处理库,能够将文档根据TF-IDF,LDA,LSI等模型转换成向量模式,此外,gensim还实现了word2vec,能够将单词转换为词向量。
1. corpora和dictionary
1.1 基本概念和用法
corpora是gensim中的一个基本概念,是文档集的表现形式。corpora就是一个二维矩阵。举例:
hurry up
rise up
这两篇文档总共就3个词,hurry,rise,up。如果将这3个词映射到数字,比如说hurry, rise, up分别对应1,2,3,那么上述的文档集的一种表现形式可以是:
1,0,1
0,1,1
这种方法只考虑词频,不考虑词语间的位置关系。因为第一个文档中的两个词分别编号1,3且都只出现了一次,所以第1个和第3个为1,第2个为0。
在实际运行中,单词数量极多(上万甚至10万级别),而一篇文档的单词数是有限的,这时采用密集矩阵来表示的话,会造成极大的内存浪费,所以gensim内部是用稀疏矩阵的形式来表示。
如何将文档转化为上述形式?
这里就要提到词典的感念(dictionary)。词典是所有文档中所有单词的集合,而且记录了各词的出现次数等信息。
对于字符串形式的文档,首先要将字符串分割成词语列表。如:"hurry up"要分割成['hurry', 'up']。对于中文来讲,一般用jieba。
将文档分割成词语之后,使用dictionary = corpora.Dictionary(texts)生成词典,并可以使用save函数将词典持久化。
生成词典后corpus = [dictionary.doc2bow(text) for text in texts]转化为向量形式。
例1:
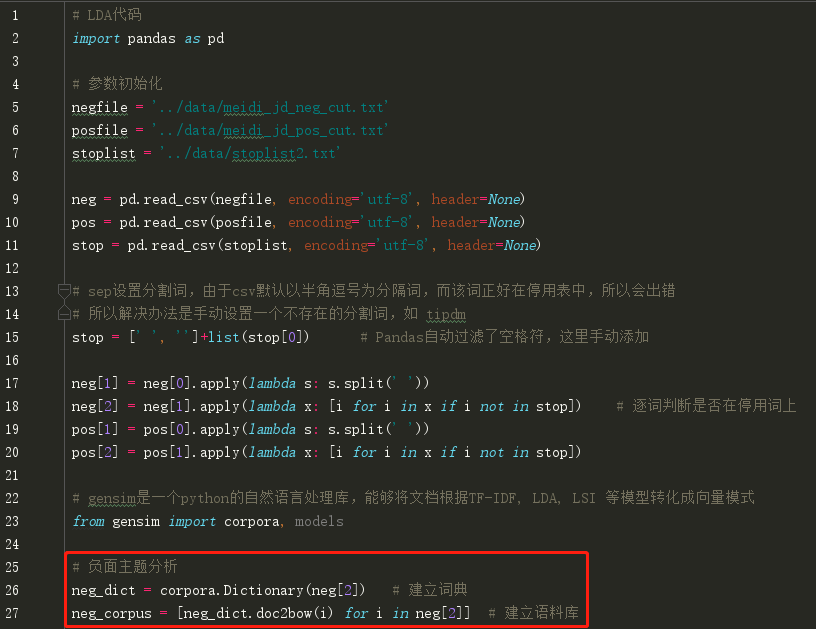
例2:
from gensim import corpora
from collections import defaultdict
documents = ["Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey"] # 去掉停用词
stoplist = set('for a of the and to in'.split())
texts = [[word for word in document.lower().split() if word not in stoplist]
for document in documents] # 去掉只出现一次的单词
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] += 1
texts = [[token for token in text if frequency[token] > 1]
for text in texts] dictionary = corpora.Dictionary(texts) # 生成词典 # 将文档存入字典,字典有很多功能,比如
# diction.token2id 存放的是单词-id key-value对
# diction.dfs 存放的是单词的出现频率
dictionary.save('/tmp/deerwester.dict') # store the dictionary, for future reference
corpus = [dictionary.doc2bow(text) for text in texts]
corpora.MmCorpus.serialize('/tmp/deerwester.mm', corpus) # store to disk, for later use
注意最后的corpora.MmCorpus.serialize将持久化到磁盘中。相反,可以用
corpus = corpora.MmCorpus('/tmp/deerwester.mm')
来从磁盘中读取corpus。
除了MmCorpus以外,还有其他格式,例如SvmLightCorpus, BleiCorpus, LowCorpus等,用法类似。
1.2 dictionary的其他一些用法
dictionary.filter_n_most_frequent(N)
过滤掉出现频率最高的N个单词
dictionary.filter_extremes(no_below=5, no_above=0.5, keep_n=100000)
1.去掉出现次数低于no_below的
2.去掉出现次数高于no_above的。注意这个小数指的是百分数
3.在1和2的基础上,保留出现频率前keep_n的单词
dictionary.filter_tokens(bad_ids=None, good_ids=None)
有两种用法,一种是去掉bad_id对应的词,另一种是保留good_id对应的词而去掉其他词。注意这里bad_ids和good_ids都是列表形式
dictionary.compacity()
在执行完前面的过滤操作以后,可能会造成单词的序号之间有空隙,这时就可以使用该函数来对词典来进行重新排序,去掉这些空隙。
1.3 分批处理和分布式计算结果的汇总
文本的规模很大时,造成内存不足以容纳文本的情况,就需要将所有文本分批处理,最后再将各批次计算得到的结果进行汇总。分布式计算时也有类似的需求。
这里假设在两个批次中,分别生成了dict1,corpus1以及dict2,corpus2.
第一步,首先将两个词典合并。当然,如果是先统一生成词典再分批生成词向量的话,可以跳过这一步,因为词典是一样的。
dict2_to_dict1 = dict1.merge_with(dict2)
要注意的是,得到的dict2_to_dict1并不是生成后的词典,而是dict2中的单词序号到这些词在合并后词典新序号的映射表。而dict1本身成为合并后的新词典。
第二步,合并corpus。
如果之前跳过了第一步,即dict1就是dict2的话,可以直接进行合并。合并有两种方式,一种是
merged_corpus = [x for x in corpus1] + [x for x in corpus2]
另外一种,则需使用内置的itertools类
merged_corpus = itertools.chain(corpus1, corpus2)
merged_corpus = [x for x in merged_corpus]
如果之前的词典也是分批生成的话,则需要对corpus2进行一定的处理
new_corpus2 = dict2_to_dict1[corpus2]
merged_corpus = itertools.chain(corpus1, new_corpus2)
merged_corpus = [x for x in merged_corpus]
这样,就把分批处理得到的dict和corpus都合并起来了。
2. models
在models中,可以对corpus进行进一步处理,比如使用TF-IDF模型,LDA模型,LSI模型,非常强大。
在按照之前的方法生成了corpus和dictionary以后,就可以生成模型了。
tfidf_model = models.TfidfModel(corpus)
注意,目前只是生成了一个模型,但这是类似于生成器,并不是将对应的corpus转化后的结果。对tf-idf模型而言,里面存储有各个单词的词频,文频等信息。想要将文档转化成TF-IDF模式表示的向量,还要使用如下命令:
corpus_tfidf = tfidf_model[corpus]
对于LDA和LSI模型,用法有所不同 :
lsi_model = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=2)
corpus_lsi = lsi_model[corpus_tfidf]
可以看到,这里除了corpus以外,还多了num_topic的选项。这是指潜在主题(topic)的数目,也等于转成LSI模型以后每个文档对应的向量长度。转化以后的向量在各项的值,即为该文档在该潜在主题的权重 。因此LSI和LDA的结果可以看做该文档的文档向量,用于后续的分类,聚类等算法。值得注意的是,id2word是所有模型都有的选项,可以指定使用的词典。
由于这里num_topics=2,所以可以用作图的方式直观的显现出来。

可以很清楚的看到,9个文档可以看成两类,分别是前5行和后4行。
来自:https://blog.csdn.net/u014595019/article/details/52218249
gensim使用方法以及例子的更多相关文章
- C++ stringstream介绍,使用方法与例子
From: http://www.usidcbbs.com/read-htm-tid-1898.html C++引入了ostringstream.istringstream.stringstream这 ...
- 【转】C++ stringstream介绍,使用方法与例子
原文来自:http://www.cnblogs.com/lancidie/archive/2010/12/03/1895161.html C++引入了ostringstream.istringstre ...
- C#A类派生类强转基类IL居然还是可以调用派生类中方法的例子
大家都知道在C#中,如果B类继承自A类,如果一个对象是B类型的但是转换为A类型之后,这个对象是无法在调用属于B类型的方法的,如下例子: 基类A: public class A { } 派生类B: pu ...
- oracle调用java方法的例子(下面所有代码都是在sql/plus中写)
在Oracle中调用Java程序,注意:java方法必须是static类型的,如果想在JAVA中使用system.out/err输出log. 需要在oracle 中执行"call dbms_ ...
- JSP调用JAVA方法小例子
用JAVA编写的函数 package doc; //定义一个包 public class Dy { //定义一个类 public static int Sub(int x,int y){ //定义函数 ...
- JSTL.带标签体的标签,方法和例子
1. 实现 forEach 标签: 两个属性: items(集合类型, Collection), var(String 类型) doTag: 遍历 items 对应的集合 把正在遍历的对象放入到 pa ...
- 完整的RecylerView的使用方法和例子
一.RecylerView的特点 1. 不关心Item是否显示在正确的位置,通过设置不同LayoutManager 的实例让Item显示不同的风格. 2. 不关心 Item间如何分离.要定义It ...
- asp.net 抽象方法和虚方法的用法区别,用Global类重写Application_BeginRequest等方法为例子
不废话,直接贴代码 public abstract class LogNetGlobal : System.Web.HttpApplication { protected void Applicati ...
- cocos2d JS-(JavaScript) 动态生成方法的例子
function User(properties) { for (var i in properties) { (function (which) { var p = i; which["g ...
随机推荐
- The Little Prince-12/12
The Little Prince-12/12 双十二,大家有没有买买买呢?宝宝双十一之后就吃土了,到现在,叶子都长出来了!!! 当你真的喜欢一个人的时候 就会想很多 会很容易办蠢事 说傻话 小王子要 ...
- 离开(切换)当前页面时改变页面title
document.addEventListener('visibilitychange', function () { if (document.visibilityState == 'hidden' ...
- thinkphp 开启事物
$Member->startTrans();//启动事务 // 提交事务$ Member->commit(); // 事务回滚$Member ->rollback();
- selenium 模拟手机
import time from selenium import webdriver mobileEmulation = {'deviceName': 'Galaxy S5'} options = w ...
- oracle 12c AUTO_SAMPLE_SIZE动态采用工作机制
The ESTIMATE_PERCENT parameter in DBMS_STATS.GATHER_*_STATS procedures controls the percentage of ro ...
- suse日常操作(含suse/rhel内核与发行版对应关系)
最近有家客户要求只能使用suse系统,是suse 12 sp3的,而且版本都不同意换,一直以来,都是使用rhel的客户,还没遇到过suse的,可偏偏不巧,我们的系统和suse 12 sp3自带的gli ...
- android之发送Get或Post请求至服务器接口
import java.io.BufferedReader; import java.io.ByteArrayOutputStream; import java.io.IOException; imp ...
- ORA-16038 ORA-19809 ORA-00312
问题表现: 连接数据库启动报错,ORA-03113, 查看详细的alert日志发现更多报错,如下 ORA-19809: 超出了恢复文件数的限制ORA-19804: 无法回收 209715200 字节磁 ...
- 2018年湘潭大学程序设计竞赛G又见斐波那契
链接:https://www.nowcoder.com/acm/contest/105/G来源:牛客网 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 32768K,其他语言65536 ...
- CSS层叠样式表--找到标签
0 怎么学习CSS 1 CSS的四种引入方式 2 CSS的四种基本选择器 3 属性选择器 4 CSS伪类 5 CSS选择器优先级 6 CSS的继承性 怎么学习CSS 1.怎么找到标签(CSS选择器) ...