【Hadoop 分布式部署 十 一: NameNode HA 自动故障转移】
问题描述: 上一篇就是NameNode 的HA 部署完成,但是存在问题,问题是如果 主NameNode的节点宕机了,还是需要人工去使用命令来切换NameNode的Acitve 这样很不方便,所以
这篇学习笔记就是记录如何解决 故障转移的
启动以后每个都是Standby,选举一个为Active
监控 每个NameNode 都应该监控 (ZKFC Failover Controller 失败故障转移控制器)
开始进行配置
在hdfs-site.xml 文件中配置 :
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
在core-site.xml 文件中配置 :
<!--配置zookeeper 集群 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop-senior.zuoyan.com:2181,hadoop-senior02.zuoyan.com:2181,hadoop-senior03.zuoyan.com:2181</value>
</property>
启动:
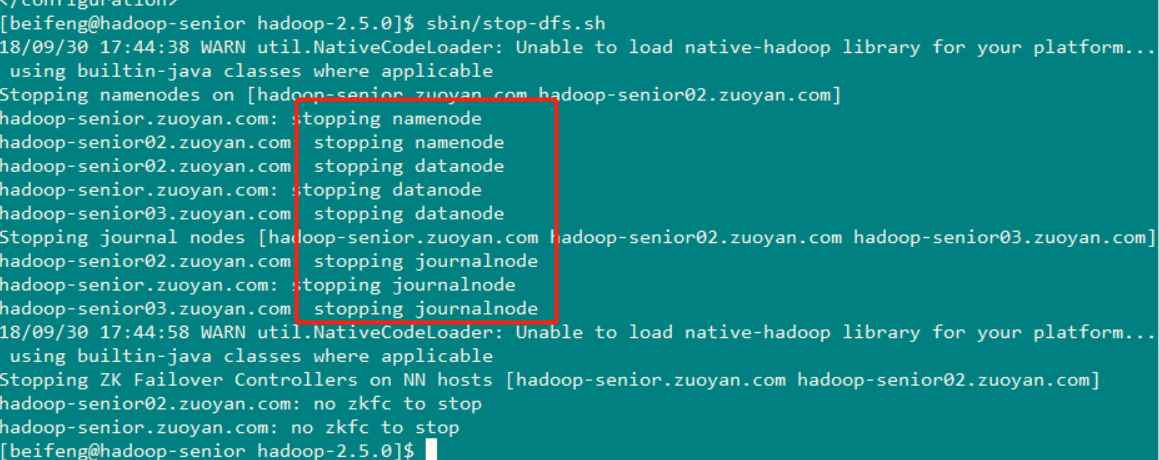
首先关闭所有HDFS服务: sbin/stop-dfs.sh (可以看到服务关闭的顺序 )
然后将节点一(hadoop-senior.zuoyan.com )上 刚配置好的两个配置文件(core-site.xml 和 hdfs-site.xm ) 同步到其余两台机器上去
使用命令:scp -r etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml hadoop-senior02.zuoyan.com:/opt/app/hadoop-2.5.0/etc/hadoop/
使用命令:scp -r etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml hadoop-senior03.zuoyan.com:/opt/app/hadoop-2.5.0/etc/hadoop/

接下来就是启动zookeeper ,进入到zookeeper的安装目录中,执行命令 bin/zkServer.sh start

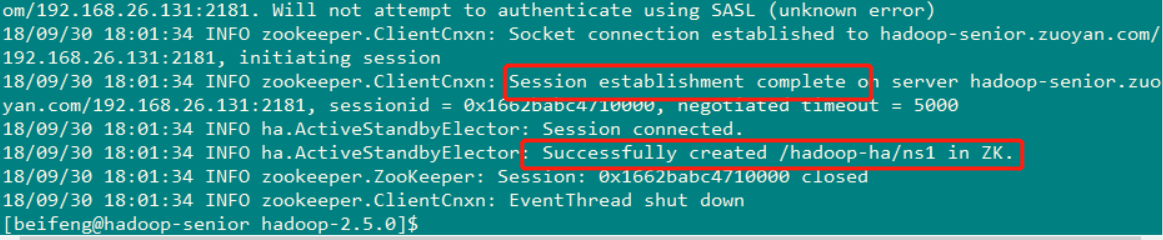
启动完成后要进行的操作:初始化HA在zookeeper 中 ( 第一个节点 ) 状态 bin/hdfs zkfc -formatZk
首先在第二个节点的终端下链接上zookeeper的客户端

然后在第一个节点上进行初始化

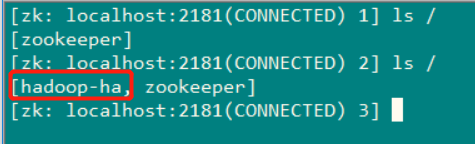
然后在hadoop-senior02.zuoyan.com 主机上的zookeeper 的客户端进行查看 ls /
( 就会发现多了一个节点 )
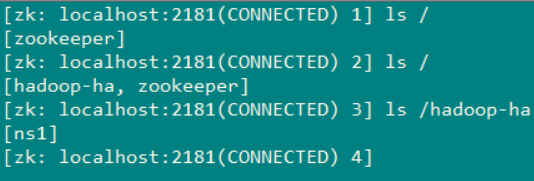
在查看hadoop-ha 这个就是 初始化时创建的那个文件目录
启动HDFS :
命令:sbin/start-dfs.sh
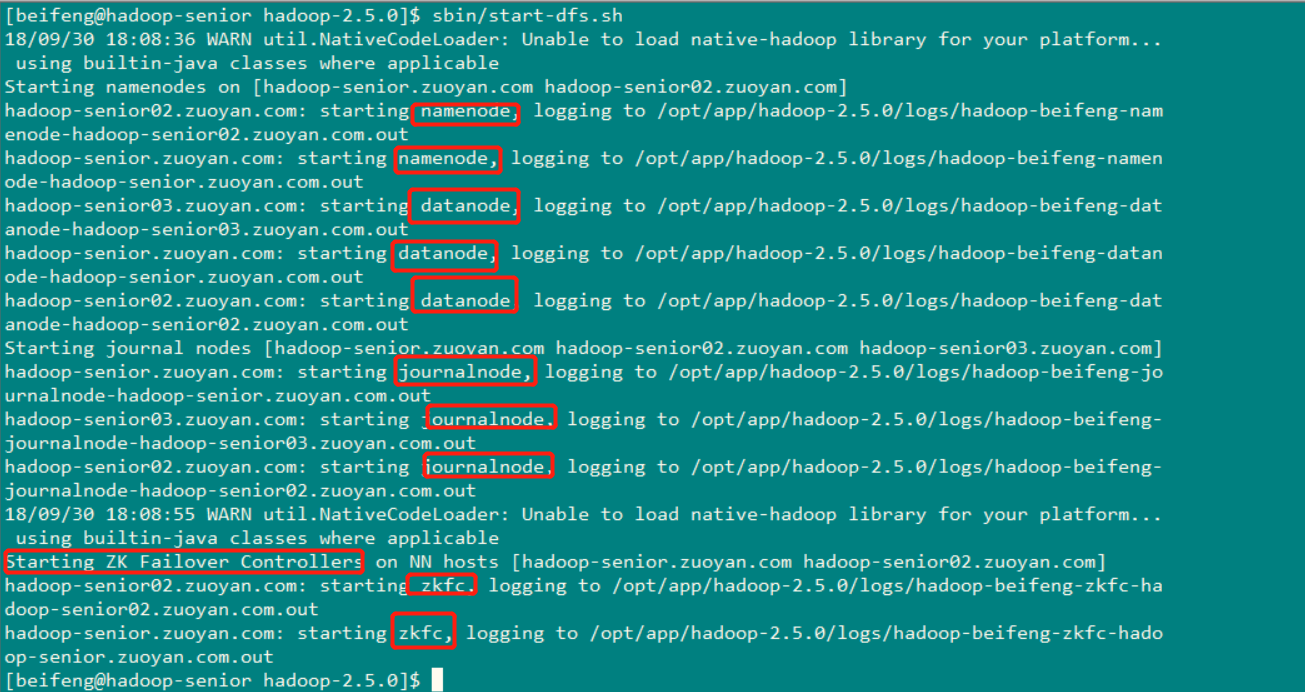
查看启动的服务
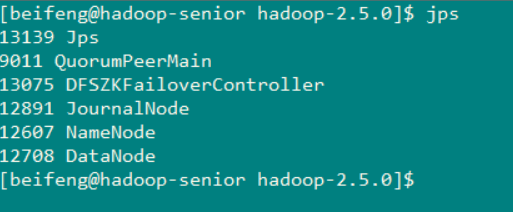
现在主节点 NameNode 和 Standby 的分布情况
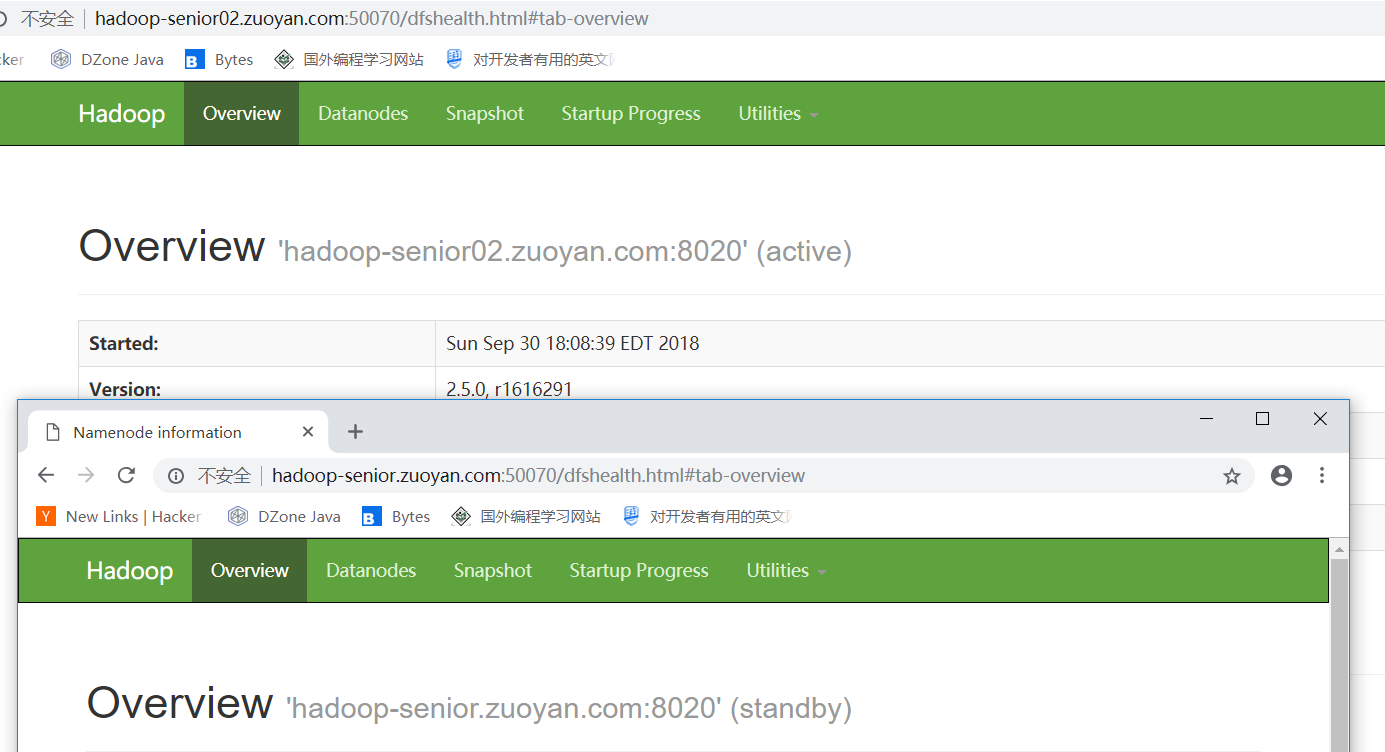
现在要结束掉Active的节点,检查他是否会自己进行故障转移
jps 查看一下任务运行的 id号 然后使用命令 kill -9 9991

然后去查看Hadoop-senior.zuoyan.com 是否成为了Active
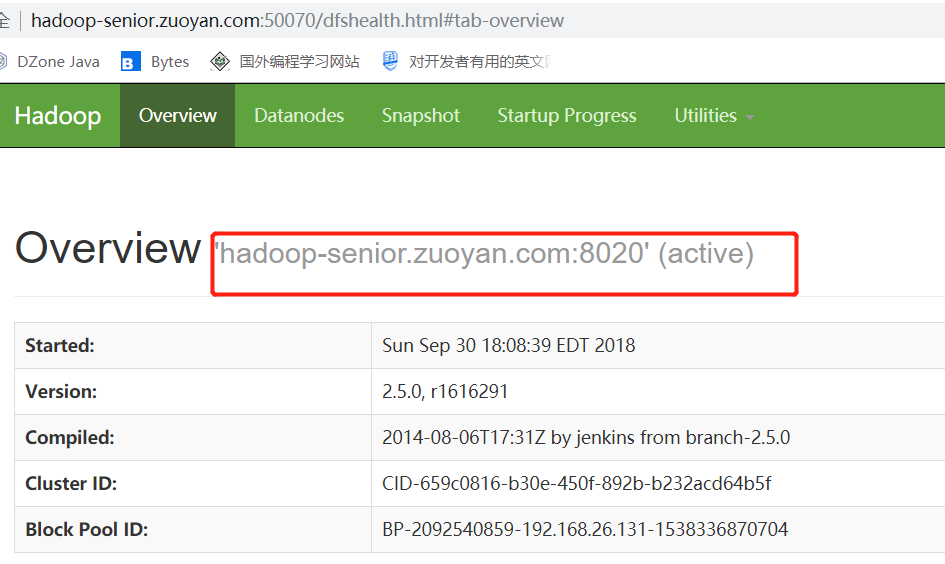
注意:zookeeper 挂了 不会对集群造成影响,就是不能进行故障自动转移,
还有就是zookeeper 需要服务器的时间同步
这种HA的结构 是QJM
【Hadoop 分布式部署 十 一: NameNode HA 自动故障转移】的更多相关文章
- 【Hadoop 分布式部署 十:配置HDFS 的HA、启动HA中的各个守护进程】
官方参考 配置 地址 :http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabili ...
- 安装部署Apache Hadoop (完全分布式模式并且实现NameNode HA和ResourceManager HA)
本节内容: 环境规划 配置集群各节点hosts文件 安装JDK1.7 安装依赖包ssh和rsync 各节点时间同步 安装Zookeeper集群 添加Hadoop运行用户 配置主节点登录自己和其他节点不 ...
- 3.16 使用Zookeeper对HDFS HA配置自动故障转移及测试
一.说明 从上一节可看出,虽然搭建好了HA架构,但是只能手动进行active与standby的切换: 接下来看一下用zookeeper进行自动故障转移: # 在启动HA之后,两个NameNode都是s ...
- MongoDB 主从复制及 自动故障转移
1.MongoDB 主从复制 MongoDB复制是将数据同步在多个服务器的过程. 复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性. 复制还允许您从 ...
- (2)MongoDB副本集自动故障转移原理
前文我们搭建MongoDB三成员副本集,了解集群基本特性,今天我们围绕下图聊一聊背后的细节. 默认搭建的replica set均在主节点读写,辅助节点冗余部署,形成高可用和备份, 具备自动故障转移的能 ...
- (2)MongoDB副本集自动故障转移全流程原理
前文我们搭建MongoDB三成员副本集,了解集群基本特性,今天我们围绕下图聊一聊背后的细节. 默认搭建的replica set均在主节点读写,辅助节点冗余部署,形成高可用和备份, 具备自动故障转移的能 ...
- 非域环境下搭建自动故障转移镜像无法将 ALTER DATABASE 命令发送到远程服务器实例的解决办法
非域环境下搭建自动故障转移镜像无法将 ALTER DATABASE 命令发送到远程服务器实例的解决办法 环境:非域环境 因为是自动故障转移,需要加入见证,事务安全模式是,强安全FULL模式 做到最后一 ...
- keepalive配置mysql自动故障转移
keepalive配置mysql自动故障转移 原创 2016年02月29日 02:16:52 2640 本文先配置了一个双master环境,互为主从,然后通过Keepalive配置了一个虚拟IP,客户 ...
- Redis集群以及自动故障转移测试
在Redis中,与Sentinel(哨兵)实现的高可用相比,集群(cluster)更多的是强调数据的分片或者是节点的伸缩性,如果在集群的主节点上加入对应的从节点,集群还可以自动故障转移,因此相比Sen ...
随机推荐
- Unicode字符需要几个字节来存储?
0)学习笔记: 我们常说的这句话“Unicode字符是2个字节”这句话有毛病 Unicode目前规划的总空间有17个平面, 0x0000---0x10FFFF,每个平面有 65536 个码点. Uni ...
- Redis入门——Java接口
1. maven配置 <dependency> <groupId>redis.clients</groupId> <artifactId>jedis&l ...
- 模拟windows全盘搜索
循环遍历pc上的文件夹,保存到mysql数据库中,搜索时,从数据库取数据.import osimport datetimeimport pymysqlimport threading def link ...
- EasyUI添加进度条
EasyUI添加进度条 添加进度条重点只有一个,如何合理安排进度刷新与异步调用逻辑,假如我们在javascript代码中通过ajax或者第三方框架dwr等对远程服务进行异步调用,实现进度条就需要做到以 ...
- vue之vue-cookies安装和使用说明
vue之vue-cookies安装和使用说明npm官方链接:https://www.npmjs.com/package/vue-cookies 安装,在对应项目根目录下执行:npm install v ...
- 读QT5.7源码(三)Q_OBJECT 和QMetaObject
Qt meta-object系统基于三个方面: 1.QObject提供一个基类,方便派生类使用meta-object系统的功能: 2.Q_OBJECT宏,在类的声明体内激活meta-object功 ...
- webVR框架A-frame
A-frame:https://blog.csdn.net/sun124608666/article/details/77869570 three.js学习文档:http://www.hewebgl. ...
- PKUWC2018 5/6
总结: D1T1T2的思路较为好想,D1T3考试时估计是战略放弃的对象,D2T1思路容易卡在优化状态上(虽然明显3n的状态中有很多无用状态,从而想到子集最优,选择子集最优容易发现反例,从而考虑连带周边 ...
- selenium 模拟手机
import time from selenium import webdriver mobileEmulation = {'deviceName': 'Galaxy S5'} options = w ...
- Prometheus监控学习笔记之在 HTTP API 中使用 PromQL
0x00 概述 Prometheus 当前稳定的 HTTP API 可以通过 /api/v1 访问. 0x01 API 响应格式 Prometheus API 使用了 JSON 格式的响应内容. 当 ...