Luncene学习二《搜索索引》
搜索索引的流程

第一步:创建一个Directory对象,也就是索引库存放的位置
第二步:创建一个IndexReader对象,需要指定Directory对象
第三步:创建一个indexsearcher对象,需要指定IndexReader对象
第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
第五步:执行查询.
第六步:返回查询结果。遍历查询结果并输出。
第七步:关闭IndexReader对象

// 搜索索引
@Test
public void testSearch() throws Exception {
// 第一步:创建一个Directory对象,也就是索引库存放的位置。
Directory directory = FSDirectory.open(new File("D:\\temp\\index"));// 磁盘
// 第二步:创建一个indexReader对象,需要指定Directory对象。
IndexReader indexReader = DirectoryReader.open(directory);
// 第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
Query query = new TermQuery(new Term("fileName", "lucene"));
// 第五步:执行查询。
TopDocs topDocs = indexSearcher.search(query, 10);
// 第六步:返回查询结果。遍历查询结果并输出。
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int doc = scoreDoc.doc;
Document document = indexSearcher.doc(doc);
// 文件名称
String fileName = document.get("fileName");
System.out.println(fileName);
// 文件内容
String fileContent = document.get("fileContent");
System.out.println(fileContent);
// 文件大小
String fileSize = document.get("fileSize");
System.out.println(fileSize);
// 文件路径
String filePath = document.get("filePath");
System.out.println(filePath);
System.out.println("------------");
}
// 第七步:关闭IndexReader对象
indexReader.close(); }
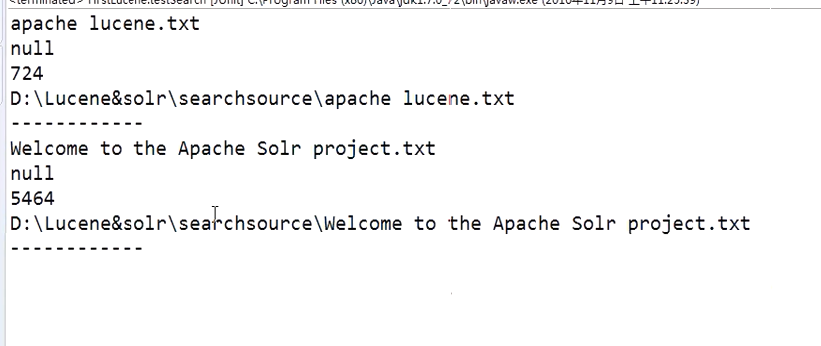
执行之后的效果
Luncene学习二《搜索索引》的更多相关文章
- MySQL学习(二)索引原理及其背后的数据结构
首先区分几个概念: 聚集索引 主索引和辅助索引(即二级索引) innodb中每个表都有一个聚簇索引(clustered index ),除此之外的表上的每个非聚簇索引都是二级索引,又叫辅助索引(sec ...
- ElasticSearch7.3学习(二十六)----搜索(Search)参数总结、结果跳跃(bouncing results)问题解析
1.preference 首先引入一个bouncing results问题,两个document排序,field值相同:不同的shard上,可能排序不同:每次请求轮询打到不同的replica shar ...
- Luncene 学习入门
Lucene是apache组织的一个用java实现全文搜索引擎的开源项目. 其功能非常的强大,api也很简单.总得来说用Lucene来进行建立 和搜索和操作数据库是差不多的(有点像),Document ...
- MySQL学习笔记(三)—索引
一.概述 1.基本概念 在大型数据库中,一张表中要容纳几万.几十万,甚至几百万的的数据,而当这些表与其他表连接后,所得到的新的数据数目更是要大大超出原来的表.当用户检索这么大量的数据时,经 ...
- Python学习二:词典基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7862377.html 邮箱:moyi@moyib ...
- MySQL实战45讲学习笔记:索引(第四讲)
一.索引模型 1.索引的作用: 索引的出现其实是为了提高数据查询的效率,就像书的目录一样 提高数据查询效率 2.索引模型的优缺点比较 二.InnoDB索引模型 1.二叉树是搜索效率最高的,但是实际上大 ...
- mysql学习笔记--数据库索引
一.索引的优点:查询速度快 二.索引的缺点: 1. 增.删.改(数据操作语句)效率低了 2. 索引占用空间 三.索引类型: 1. 普通索引 2. 唯一索引(唯一键) 3. 主键索引:只要主键就自动创建 ...
- pandas学习(创建多层索引、数据重塑与轴向旋转)
pandas学习(创建多层索引.数据重塑与轴向旋转) 目录 创建多层索引 数据重塑与轴向旋转 创建多层索引 隐式构造 Series 最常见的方法是给DataFrame构造函数的index参数传递两个或 ...
- 集成学习二: Boosting
目录 集成学习二: Boosting 引言 Adaboost Adaboost 算法 前向分步算法 前向分步算法 Boosting Tree 回归树 提升回归树 Gradient Boosting 参 ...
随机推荐
- numpy高级应用
reshape重塑数组 ravel 拉平数组 concatenate 最一般化的连接,沿一条轴连接一组数组 # print(np.concatenate([arr1,arr2],axis = 0)) ...
- 邮件服务器hMailServer管理工具hMailServer Administrator汉化(转)
//实现:邮件服务器hMailServer管理工具hMailServer Administrator的汉化 //环境: Windows Server 2008 R2 hMailServer Admin ...
- scrapy框架 + selenium 爬取豆瓣电影top250......
废话不说,直接上代码..... 目录结构 items.py import scrapy class DoubanCrawlerItem(scrapy.Item): # 电影名称 movieName = ...
- java was started but exit code =-805306369
打开STS 时报 java was started but exit code =-805306369这个错,一个页面. 原因我把STS里面的默认jdk换成了7.但是STS的ini文件里依赖的 ...
- Django后端项目----RESTful API
一. 什么是RESTful REST与技术无关,代表的是一种软件架构风格,REST是Representational State Transfer的简称,中文翻译为“表征状态转移” REST从资源的角 ...
- Inernet TLS协议注册表 开启
IE高级配置中,存在SSL支持协议,例如SSL TLS. 其在注册表的路径为:HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\I ...
- spring(读取外部数据库配置信息、基于注解管理bean、DI)
###解析外部配置文件在resources文件夹下,新建db.properties(和数据库连接相关的信息) driverClassName=com.mysql.jdbc.Driverurl=jdbc ...
- session(概念、session对象的获取、删除、验证)
# 1.session(会话)是什么? 服务器为了保存用户状态而创建的一个特殊的对象. 注: 当浏览器访问服务器时,服务器会创建一个session对象(该对象有一个唯一的id,一般称之为session ...
- mysql 汇总
子查询: select a.id,a.hotelname,max(b.day) as day,a.hotelrankid, c.hotelrank,min(b.basicprice) a ...
- 数据结构(C语言)—排序
数据结构(C语言)—排序 排序 排序是按关键字的非递增或递减顺序对一组记录中心进行排序的操作.(将一组杂乱无章的数据按一定规律顺次排列起来.) 未定列表与不稳定列表 假设 Ki = Kj ( 1 ≤ ...