kafka系列四、kafka架构原理、高可靠性存储分析及配置优化
一、概述
二、Kafka的使用场景
(1)日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如Hadoop、Hbase、Solr等;
三、Kafka基本架构
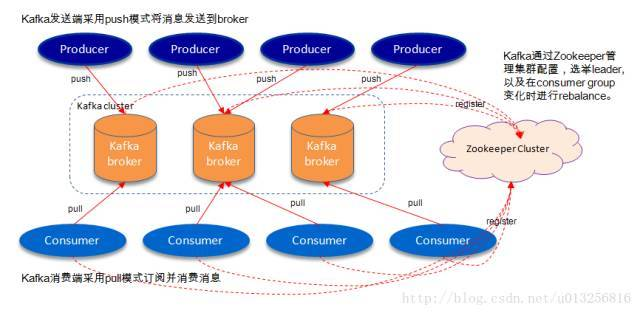
如上图所示,一个典型的Kafka体系架构包括:
- 若干Producer(可以是服务器日志,业务数据,页面前端产生的page view等等),
- 若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),
- 若干Consumer (Group),以及一个Zookeeper集群。
Kafka通过Zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。Producer使用push(推)模式将消息发布到broker,Consumer使用pull(拉)模式从broker订阅并消费消息。
1、Topic & Partition
一个topic可以认为一个一类消息,每个topic将被分成多个partition,每个partition在存储层面是append log文件。任何发布到此partition的消息都会被追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型的数字,它唯一标记一条消息。每条消息都被append到partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)。

每一条消息被发送到broker中,会根据partition规则选择被存储到哪一个partition。partition机制可以通过指定producer的partition.class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。如果partition规则设置的合理,所有消息可以均匀分布到不同的partition里,这样就实现了水平扩展。(如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而partition解决了这个问题)。在创建topic时可以在$KAFKA_HOME/config/server.properties中指定这个partition的数量(如下所示),当然可以在topic创建之后去修改partition的数量。
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
#默认partitions数量
num.partitions=1
四、高可靠性存储分析概述
五、Kafka文件存储机制
drwxr-xr-x root root Apr : topic_zzh_test-
drwxr-xr-x root root Apr : topic_zzh_test-
drwxr-xr-x root root Apr : topic_zzh_test-
drwxr-xr-x root root Apr : topic_zzh_test-
#在强制刷新数据到磁盘允许接收消息的数量
#log.flush.interval.messages= # 在强制刷新之前,消息可以在日志中停留的最长时间
#log.flush.interval.ms= #一个日志的最小存活时间,可以被删除
log.retention.hours= # 一个基于大小的日志保留策略。段将被从日志中删除只要剩下的部分段不低于log.retention.bytes。
#log.retention.bytes= # 每一个日志段大小的最大值。当到达这个大小时,会生成一个新的片段。
log.segment.bytes= # 检查日志段的时间间隔,看是否可以根据保留策略删除它们
log.retention.check.interval.ms=
segment文件由两部分组成,分别为“.index”文件和“.log”文件,分别表示为segment索引文件和数据文件。这两个文件的命令规则为:partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值,数值大小为64位,20位数字字符长度,没有数字用0填充,如下:
.index
.log
.index
.log
.index
.log
以上面的segment文件为例,展示出segment:00000000000000170410的“.index”文件和“.log”文件的对应的关系,如下图:
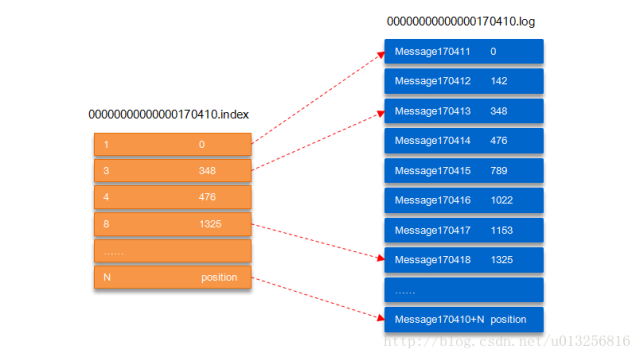
如上图,“.index”索引文件存储大量的元数据,“.log”数据文件存储大量的消息,索引文件中的元数据指向对应数据文件中message的物理偏移地址。其中以“.index”索引文件中的元数据[3, 348]为例,在“.log”数据文件表示第3个消息,即在全局partition中表示170410+3=170413个消息,该消息的物理偏移地址为348。
六、复制原理和同步方式
Kafka中topic的每个partition有一个预写式的日志文件,虽然partition可以继续细分为若干个segment文件,但是对于上层应用来说可以将partition看成最小的存储单元(一个有多个segment文件拼接的“巨型”文件),每个partition都由一些列有序的、不可变的消息组成,这些消息被连续的追加到partition中。


七、零拷贝
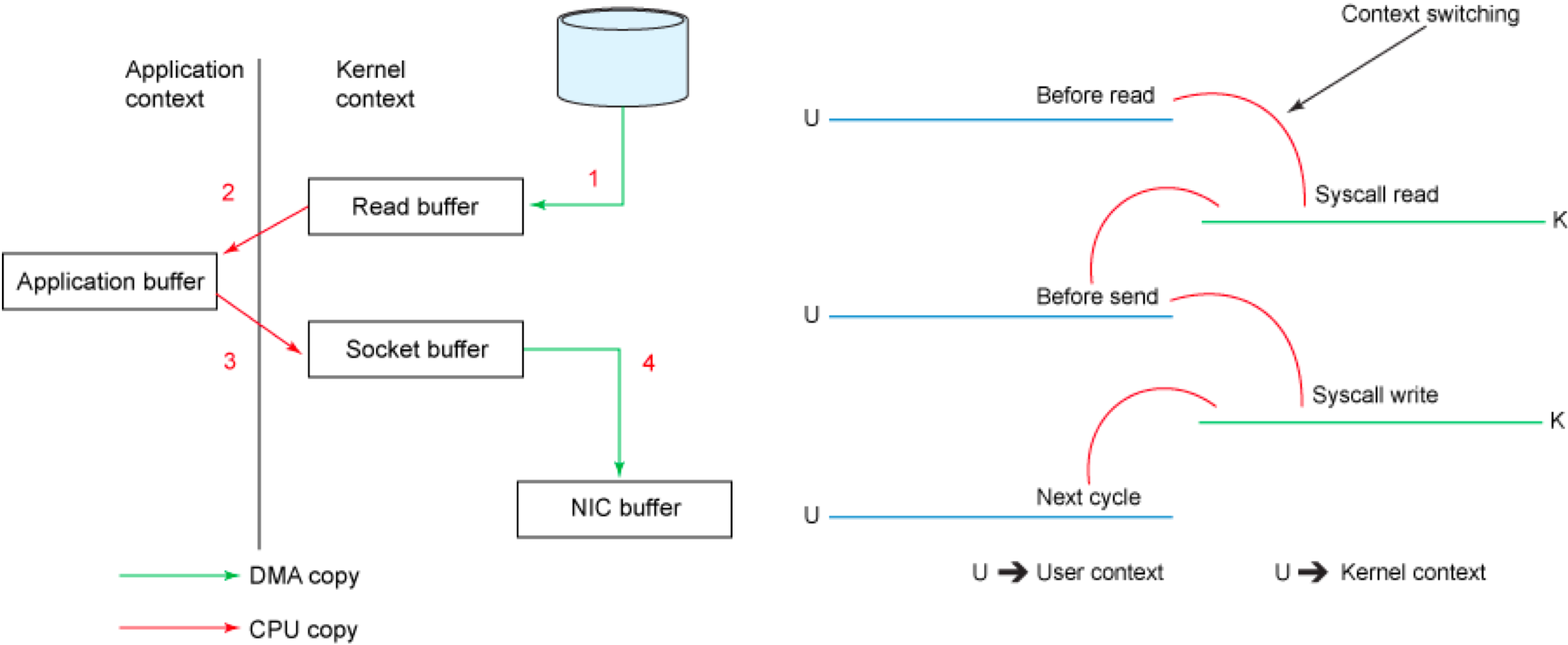
1、传统模式下的四次拷贝与四次上下文切换
以将磁盘文件通过网络发送为例。传统模式下,一般使用如下伪代码所示的方法先将文件数据读入内存,然后通过Socket将内存中的数据发送出去。
buffer = File.read
Socket.send(buffer)
这一过程实际上发生了四次数据拷贝。首先通过系统调用将文件数据读入到内核态Buffer(DMA拷贝),然后应用程序将内存态Buffer数据读入到用户态Buffer(CPU拷贝),接着用户程序通过Socket发送数据时将用户态Buffer数据拷贝到内核态Buffer(CPU拷贝),最后通过DMA拷贝将数据拷贝到NIC Buffer。同时,还伴随着四次上下文切换,如下图所示。
2、sendfile和transferTo实现零拷贝
Linux 2.4+内核通过sendfile系统调用,提供了零拷贝。数据通过DMA拷贝到内核态Buffer后,直接通过DMA拷贝到NIC Buffer,无需CPU拷贝。这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件-网络发送由一个sendfile调用完成,整个过程只有两次上下文切换,因此大大提高了性能。零拷贝过程如下图所示。

从具体实现来看,Kafka的数据传输通过TransportLayer来完成,其子类PlaintextTransportLayer通过Java NIO的FileChannel的transferTo和transferFrom方法实现零拷贝,如下所示。
@Override
public long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
注: transferTo和transferFrom并不保证一定能使用零拷贝。实际上是否能使用零拷贝与操作系统相关,如果操作系统提供sendfile这样的零拷贝系统调用,则这两个方法会通过这样的系统调用充分利用零拷贝的优势,否则并不能通过这两个方法本身实现零拷贝。
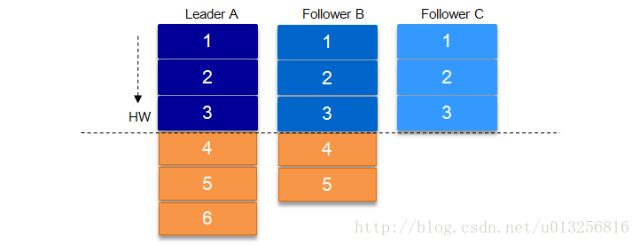
八、 ISR(副本同步队列)

九、数据可靠性和持久性保证
- 1(默认):这意味着producer在ISR中的leader已成功收到的数据并得到确认后发送下一条message。如果leader宕机了,则会丢失数据。
- 0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
- -1:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。但是这样也不能保证数据不丢失,比如当ISR中只有leader时(前面ISR那一节讲到,ISR中的成员由于某些情况会增加也会减少,最少就只剩一个leader),这样就变成了acks=1的情况。
如果要提高数据的可靠性,在设置request.required.acks=-1的同时,也要min.insync.replicas这个参数(可以在broker或者topic层面进行设置)的配合,这样才能发挥最大的功效。min.insync.replicas这个参数设定ISR中的最小副本数是多少,默认值为1,当且仅当request.required.acks参数设置为-1时,此参数才生效。如果ISR中的副本数少于min.insync.replicas配置的数量时,客户端会返回异常:org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required。
接下来对acks=1和-1的两种情况进行详细分析:
9.1、request.required.acks=1
producer发送数据到leader,leader写本地日志成功,返回客户端成功;此时ISR中的副本还没有来得及拉取该消息,leader就宕机了,那么此次发送的消息就会丢失。
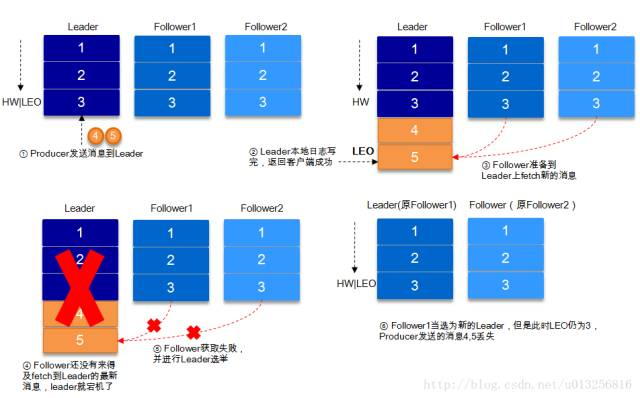
9.2、request.required.acks=-1
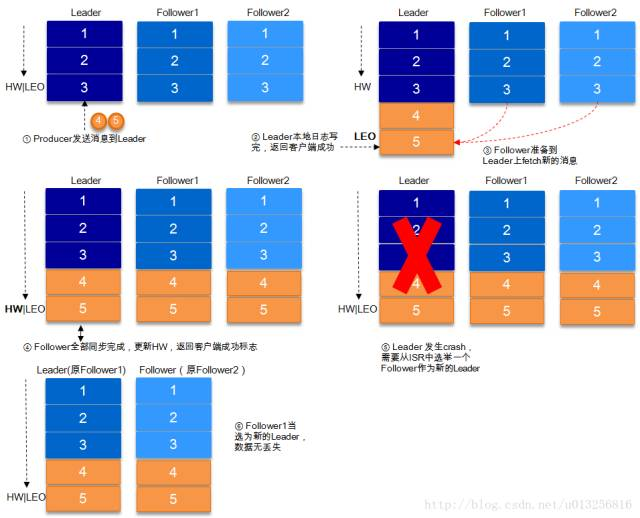
acks=-1的情况下,数据发送到leader后 ,部分ISR的副本同步,leader此时挂掉。比如follower1h和follower2都有可能变成新的leader, producer端会得到返回异常,producer端会重新发送数据,数据可能会重复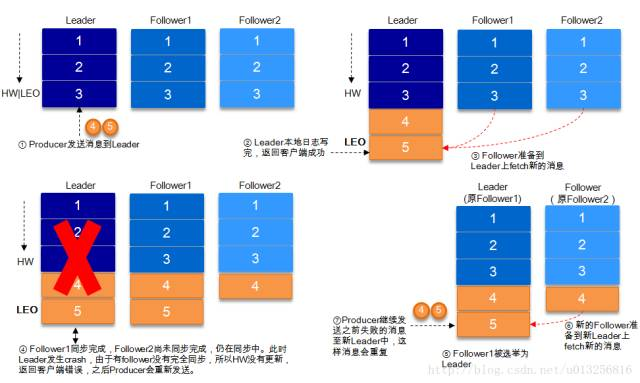
当然上图中如果在leader crash的时候,follower2还没有同步到任何数据,而且follower2被选举为新的leader的话,这样消息就不会重复。
注:Kafka只处理fail/recover问题,不处理Byzantine问题。
9.3、关于HW的进一步探讨
9.4、Leader选举
等待ISR中任意一个replica“活”过来,并且选它作为leader
选择第一个“活”过来的replica(并不一定是在ISR中)作为leader
这就需要在可用性和一致性当中作出一个简单的抉择。如果一定要等待ISR中的replica“活”过来,那不可用的时间就可能会相对较长。而且如果ISR中所有的replica都无法“活”过来了,或者数据丢失了,这个partition将永远不可用。选择第一个“活”过来的replica作为leader,而这个replica不是ISR中的replica,那即使它并不保障已经包含了所有已commit的消息,它也会成为leader而作为consumer的数据源。默认情况下,Kafka采用第二种策略,即
- unclean.leader.election.enable=true,也可以将此参数设置为false来启用第一种策略。
- unclean.leader.election.enable这个参数对于leader的选举、系统的可用性以及数据的可靠性都有至关重要的影响。
下面我们来分析下几种典型的场景。
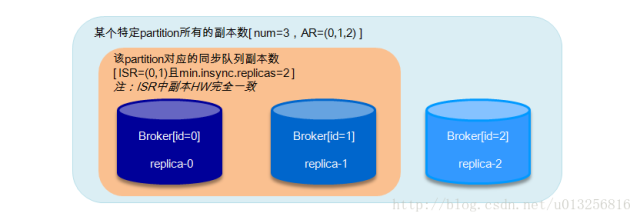
如果replica-0不能恢复,需要将min.insync.replicas设置为1,恢复write功能。
如果replica-0起来,而replica-1不能起来,这时候仍然不能选出leader,因为当设置unclean.leader.election.enable=false时,leader只能从ISR中选举,当ISR中所有副本都失效之后,需要ISR中最后失效的那个副本能恢复之后才能选举leader, 即replica-0先失效,replica-1后失效,需要replica-1恢复后才能选举leader。保守的方案建议把unclean.leader.election.enable设置为true,但是这样会有丢失数据的情况发生,这样可以恢复read服务。同样需要将min.insync.replicas设置为1,恢复write功能;replica-1恢复,replica-0不能恢复,这个情况上面遇到过,read服务可用,需要将min.insync.replicas设置为1,恢复write功能;
replica-0和replica-1都不能恢复,这种情况可以参考情形2.
9.5、Kafka的发送模式

以batch的方式推送数据可以极大的提高处理效率,kafka producer可以将消息在内存中累计到一定数量后作为一个batch发送请求。batch的数量大小可以通过producer的参数(batch.num.messages)控制。通过增加batch的大小,可以减少网络请求和磁盘IO的次数,当然具体参数设置需要在效率和时效性方面做一个权衡。在比较新的版本中还有batch.size这个参数。
十、高可靠性使用分析
10.1、消息传输保障
- At most once: 消息可能会丢,但绝不会重复传输
- At least once:消息绝不会丢,但可能会重复传输
- Exactly once:每条消息肯定会被传输一次且仅传输一次
Kafka的消息传输保障机制非常直观。当producer向broker发送消息时,一旦这条消息被commit,由于副本机制(replication)的存在,它就不会丢失。但是如果producer发送数据给broker后,遇到的网络问题而造成通信中断,那producer就无法判断该条消息是否已经提交(commit)。虽然Kafka无法确定网络故障期间发生了什么,但是producer可以retry多次,确保消息已经正确传输到broker中,所以目前Kafka实现的是at least once。
10.2、消息去重
10.3、高可靠性配置
- topic的配置:replication.factor>=3,即副本数至少是3个;2<=min.insync.replicas<=replication.factor
- broker的配置:leader的选举条件unclean.leader.election.enable=false
- producer的配置:request.required.acks=-1(all),producer.type=sync
十一、内部网络框架
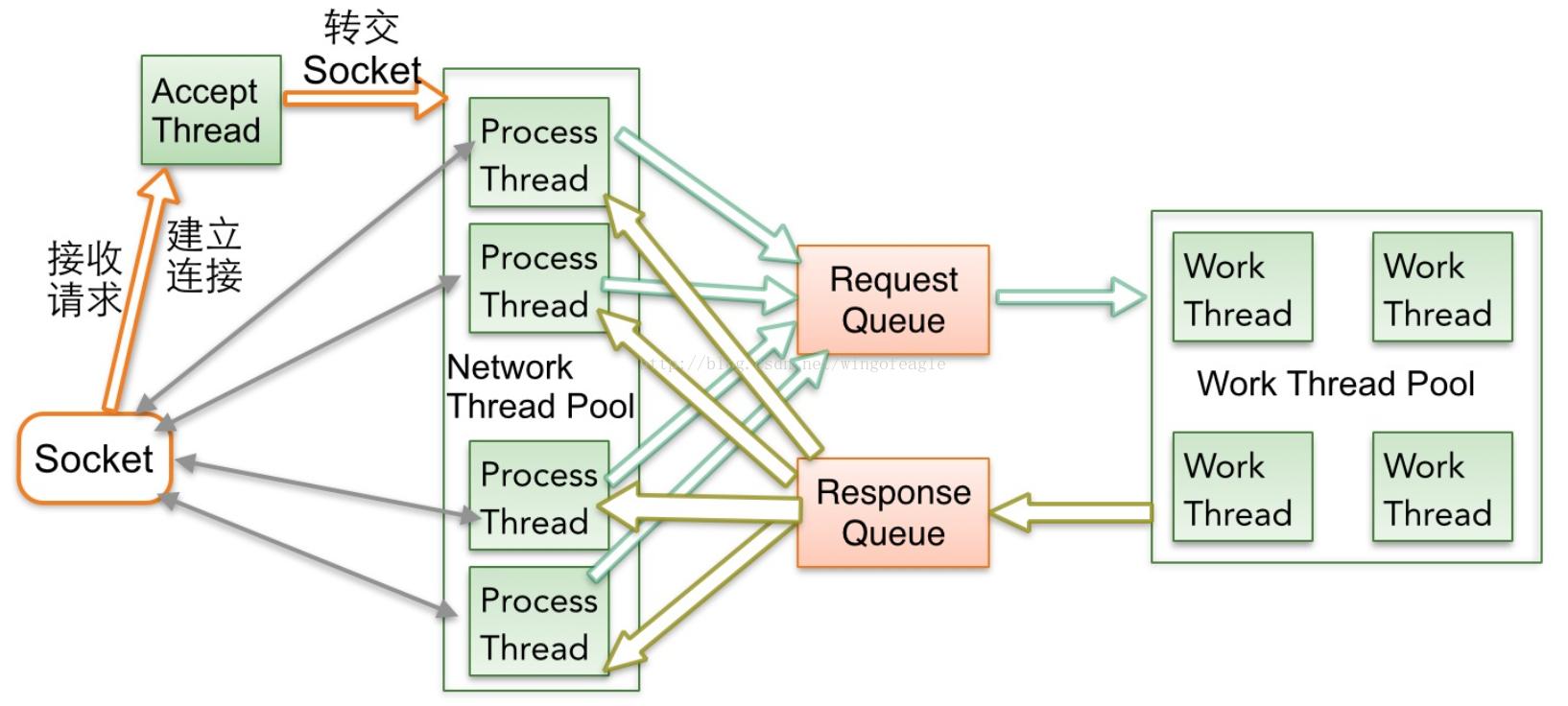
Broker的内部处理流水线化,分为多个阶段来进行(SEDA),以提高吞吐量和性能,尽量避免Thead盲等待,以下为过程说明。
- Accept Thread负责与客户端建立连接链路,然后把Socket轮转交给Process Thread
- Process Thread负责接收请求和响应数据,Process Thread每次基于Selector事件循环,首先从Response Queue读取响应数据,向客户端回复响应,然后接收到客户端请求后,读取数据放入Request Queue。
- Work Thread负责业务逻辑、IO磁盘处理等,负责从Request Queue读取请求,并把处理结果放入Response Queue中,待Process Thread发送出去。
十二、rebalance机制
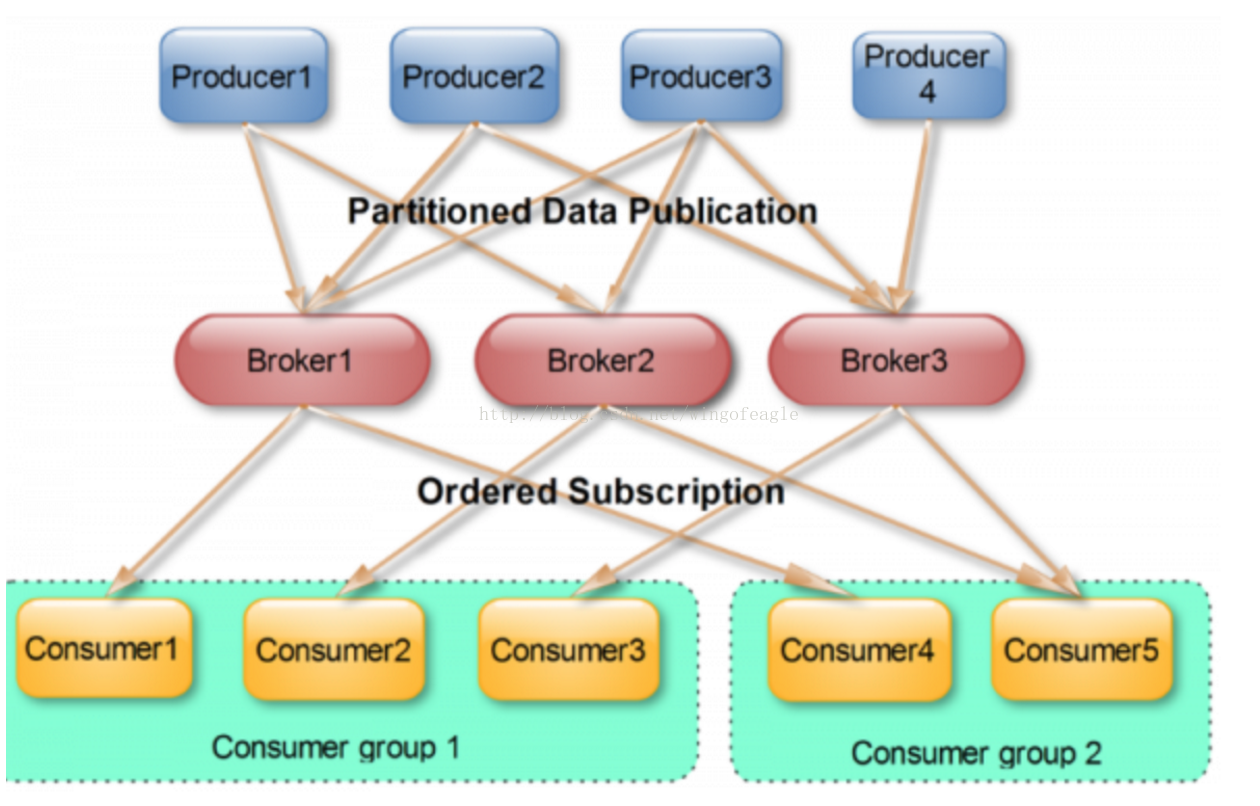
Kafka保证同一consumer group中只有一个consumer会消费某条消息,实际上,Kafka保证的是稳定状态下每一个consumer实例只会消费某一个或多个特定的数据,而某个partition的数据只会被某一个特定的consumer实例所消费。这样设计的劣势是无法让同一个consumer group里的consumer均匀消费数据,优势是每个consumer不用都跟大量的broker通信,减少通信开销,同时也降低了分配难度,实现也更简单。另外,因为同一个partition里的数据是有序的,这种设计可以保证每个partition里的数据也是有序被消费。
如果某consumer group中consumer数量少于partition数量,则至少有一个consumer会消费多个partition的数据,如果consumer的数量与partition数量相同,则正好一个consumer消费一个partition的数据,而如果consumer的数量多于partition的数量时,会有部分consumer无法消费该topic下任何一条消息。
Consumer Rebalance算法如下 :
. 将目标 topic 下的所有 partirtion 排序,存于PT
. 对某 consumer group 下所有 consumer 排序,存于 CG,第 i 个consumer 记为 Ci
. N=size(PT)/size(CG),向上取整
. 解除 Ci 对原来分配的 partition 的消费权(i从0开始)
. 将第i*N到(i+)*N-1个 partition 分配给 Ci
目前consumer rebalance的控制策略是由每一个consumer通过Zookeeper完成的。具体的控制方式如下:
在/consumers/[consumer-group]/下注册id
设置对/consumers/[consumer-group] 的watcher
设置对/brokers/ids的watcher
zk下设置watcher的路径节点更改,触发consumer rebalance
在这种策略下,每一个consumer或者broker的增加或者减少都会触发consumer rebalance。因为每个consumer只负责调整自己所消费的partition,为了保证整个consumer group的一致性,所以当一个consumer触发了rebalance时,该consumer group内的其它所有consumer也应该同时触发rebalance。
- Herd effect
任何broker或者consumer的增减都会触发所有的consumer的rebalance
- Split Brain
每个consumer分别单独通过Zookeeper判断哪些partition down了,那么不同consumer从Zookeeper“看”到的view就可能不一样,这就会造成错误的reblance尝试。而且有可能所有的consumer都认为rebalance已经完成了,但实际上可能并非如此。
十三、BenchMark
13.1、测试环境
Memory: 62G
Network: 4000Mb
OS/kernel: CentOs release 6.6 (Final)
Disk: 1089G
Kafka版本:0.10.1.0
broker端JVM参数设置:
-Xmx8G -Xms8G -server -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRemark -XX:+DisableExplicitGC -Djava.awt.headless=true -Xloggc:/apps/service/kafka/bin/../logs/kafkaServer-gc.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.port=
客户端机器配置:
- CPU: 24core/2.6GHZ
- Memory: 3G
- Network: 1000Mb
- OS/kernel: CentOs release 6.3 (Final)
- Disk: 240G
13.2、不同场景测试
场景1:
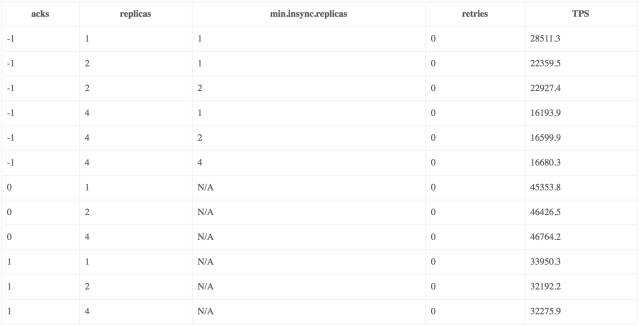
- 客户端的acks策略对发送的TPS有较大的影响,TPS:acks_0 > acks_1 > ack_-1;
- 副本数越高,TPS越低;副本数一致时,min.insync.replicas不影响TPS;
- acks=0/1时,TPS与min.insync.replicas参数以及副本数无关,仅受acks策略的影响。
下面将partition的个数设置为1,来进一步确认下不同的acks策略、不同的min.insync.replicas策略以及不同的副本数对于发送速度的影响,详细请看情景2和情景3。
场景2:

测试结果分析:
副本数越高,TPS越低(这点与场景1的测试结论吻合),但是当partition数为1时差距甚微。min.insync.replicas不影响TPS。
场景3:
在partition个数固定为1,测试不同的acks策略和副本数对发送速度的影响。
具体配置:一个producer;发送方式为sync;消息体大小为1kB;min.insync.replicas=1。topic副本数为:1/2/4;acks: 0/1/-1。
测试结果如下:
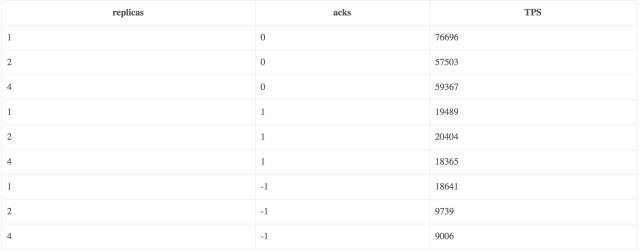
测试结果分析(与情景1一致):
- 副本数越多,TPS越低;
- 客户端的acks策略对发送的TPS有较大的影响,TPS:acks_0 > acks_1 > ack_-1。
场景4:
测试不同partition数对发送速率的影响
具体配置:一个producer;消息体大小为1KB;发送方式为sync;topic副本数为2;min.insync.replicas=2;acks=-1。partition数量设置为1/2/4/8/12。
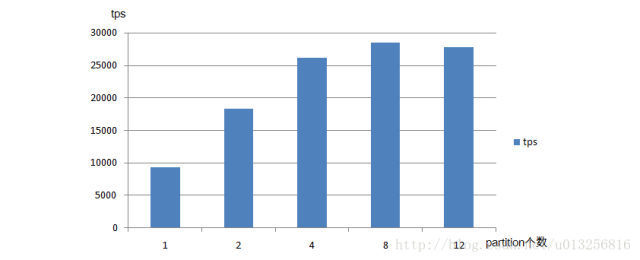
场景5:

- kill两台broker后,客户端可以继续发送。broker减少后,partition的leader分布在剩余的两台broker上,造成了TPS的减小;
- kill三台broker后,客户端无法继续发送。Kafka的自动重试功能开始起作用,当大于等于min.insync.replicas数量的broker恢复后,可以继续发送;
- 当retries不为0时,消息有重复落盘;客户端成功返回的消息都成功落盘,异常时部分消息可以落盘。
场景6:
测试单个producer的发送延迟,以及端到端的延迟。
具体配置:一个producer;消息体大小1KB;发送方式为sync;topic副本数为4;min.insync.replicas设置为2;acks=-1;partition数为12。
测试数据及结果(单位为ms):

- 当acks=-1时,Kafka发送端的TPS受限于topic的副本数量(ISR中),副本越多TPS越低;
- acks=0时,TPS最高,其次为1,最差为-1,即TPS:acks_0 > acks_1 > ack_-1
- min.insync.replicas参数不影响TPS;
- partition的不同会影响TPS,随着partition的个数的增长TPS会有所增长,但并不是一直成正比关系,到达一定临界值时,partition数量的增加反而会使TPS略微降低;
- Kafka在acks=-1,min.insync.replicas>=1时,具有高可靠性,所有成功返回的消息都可以落盘。
kafka系列四、kafka架构原理、高可靠性存储分析及配置优化的更多相关文章
- java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现
java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析 ...
- Kafka系列一之架构介绍和安装
Kafka架构介绍和安装 写在前面 还是那句话,当你学习一个新的东西之前,你总得知道这个东西是什么?这个东西可以用来做什么?然后你才会去学习它,使用它.简单来说,kafka既是一个消息队列,如今,它也 ...
- Kafka系列之-Kafka Protocol实例分析
本文基于A Guide To The Kafka Protocol文档,以及Spark Streaming中实现的org.apache.spark.streaming.kafka.KafkaClust ...
- Kafka系列之-Kafka入门
接下来的这些博客,主要内容来自<Learning Apache Kafka Second Edition>这本书,书不厚,200多页.接下来摘录出本书中的重要知识点,偶尔参考一些网络资料, ...
- Kafka系列之-Kafka监控工具KafkaOffsetMonitor配置及使用
KafkaOffsetMonitor是一个可以用于监控Kafka的Topic及Consumer消费状况的工具,其配置和使用特别的方便.源项目Github地址为:https://github.com/q ...
- Kafka系列二 kafka相关问题理解
1.kafka是什么 类JMS消息队列,结合JMS中的两种模式,可以有多个消费者主动拉取数据,在JMS中只有点对点模式才有消费者主动拉取数据. kafka是一个生产-消费模型. producer:生产 ...
- Kafka系列四 flume-kafka-storm整合
flume-kafka-storm flume读取日志数据,然后发送至kafka. 1.flume配置文件 agent.sources = kafkaSource agent.channels = k ...
- Apache Kafka系列(四) 多线程Consumer方案
Apache Kafka系列(一) 起步 Apache Kafka系列(二) 命令行工具(CLI) Apache Kafka系列(三) Java API使用 Apache Kafka系列(四) 多线程 ...
- Apache Kafka系列(七)Kafka Repartition操作
Kafka提供了重新分区的命令,但是只能增加,不能减少 我的kafka安装在/usr/local/kafka_2.12-1.0.2目录下面, [root@i-zk1 kafka_2.-]# bin/k ...
随机推荐
- 【转】C语言字符串与数字相互转换
在C/C++语言中没有专门的字符串变量,通常用字符数组来存放字符串.字符串是以“\0”作为结束符.C/C++提供了丰富的字符串处理函数,下面列出了几个最常用的函数. ● 字符串输出函数puts. ● ...
- 利用Springboot-mail发送邮件
相信使用过Spring的众多开发者都知道Spring提供了非常好用的JavaMailSender接口实现邮件发送.在Spring Boot的Starter模块中也为此提供了自动化配置.下面通过实例看看 ...
- 使用selenium模拟登陆oschina
Selenium把元素定位接口封装得更简单易用了,支持Xpath.CSS选择器.以及标签名.标签属性和标签文本查找. from selenium.webdriver import PhantomJS ...
- CF 1023
昨天晚上打的一场CF,口胡一下前4题吧. A要注意细节,先找*,如果没有就判两者相等. 然后注意长度n - 1 <= m,然后前后比较,最后判断中间是不是字母. B先判断有没有解,然后求出 k ...
- A1022. Digital Library
A Digital Library contains millions of books, stored according to their titles, authors, key words o ...
- A1095. Cars on Campus
Zhejiang University has 6 campuses and a lot of gates. From each gate we can collect the in/out time ...
- pow log 与 (int)
1.不能用%d输出double类型的数 double a1=5.3; double a2=1234.1234; double a3=3412341.12341234; double b1=1.5; d ...
- NO.10: 在operator=中处理 "自我赋值"
1.确保当对象自我赋值时operator=有良好的行为,其中的技术包括 "来源对象" 和 "目标对象" 的地址,精心周到的语句顺序,以及“ copy and s ...
- Log4j 2X 日志文件路径问题
关于路径问题网上说啥的都有,但是也不能说人家错,只能说不适合你这个. 一开始,我用的 ${webapp.root} <RollingFile name="rollingFileSy ...
- java.sql.SQLSyntaxErrorException: ORA-00911: 无效字符
java.sql.SQLSyntaxErrorException: ORA-: 无效字符 at oracle.jdbc.driver.T4CTTIoer.processError(T4CTTIoer. ...