Presto 架构和原理简介(转)
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 Hive 的 10 倍以上。Presto 可以查询包括 Hive、Cassandra 甚至是一些商业的数据存储产品,单个 Presto 查询可合并来自多个数据源的数据进行统一分析。Presto 的目标是在可期望的响应时间内返回查询结果,Facebook 在内部多个数据存储中使用 Presto 交互式查询,包括 300PB 的数据仓库,超过 1000 个 Facebook 员工每天在使用 Presto 运行超过 3 万个查询,每天扫描超过 1PB 的数据。
目录:
- presto架构
- presto低延迟原理
- presto存储插件
- presto执行过程
- presto引擎对比
Presto架构

- Presto查询引擎是一个Master-Slave的架构,由下面三部分组成:
- 一个Coordinator节点
- 一个Discovery Server节点
- 多个Worker节点
- Coordinator: 负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行
- Discovery Server: 通常内嵌于Coordinator节点中
- Worker节点: 负责实际执行查询任务,负责与HDFS交互读取数据
- Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息
- 更形象架构图如下:

Presto低延迟原理
- 完全基于内存的并行计算
- 流水线式计算作业
- 本地化计算
- 动态编译执行计划
- GC控制
Presto存储插件
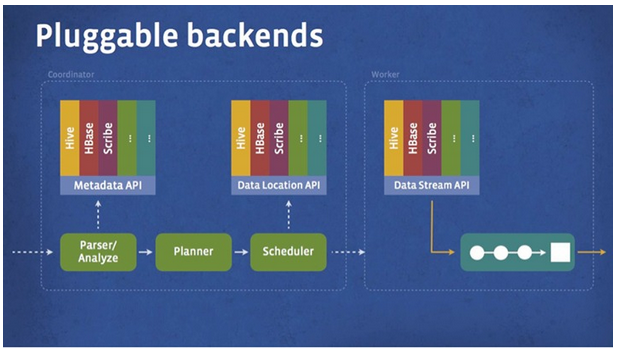
- Presto设计了一个简单的数据存储的抽象层, 来满足在不同数据存储系统之上都可以使用SQL进行查询。
- 存储插件(连接器,connector)只需要提供实现以下操作的接口, 包括对元数据(metadata)的提取,获得数据存储的位置,获取数据本身的操作等。
- 除了我们主要使用的Hive/HDFS后台系统之外, 我们也开发了一些连接其他系统的Presto 连接器,包括HBase,Scribe和定制开发的系统
- 插件结构图如下:
presto执行过程
- 执行过程示意图:
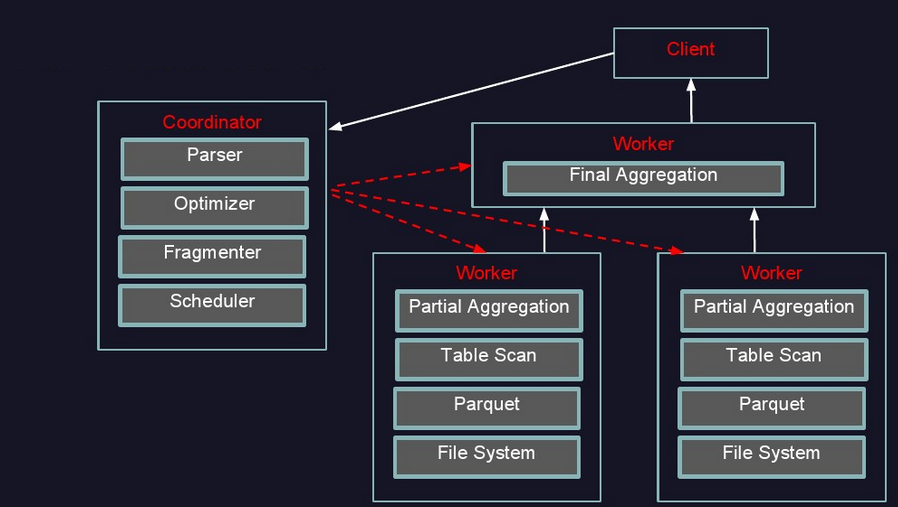
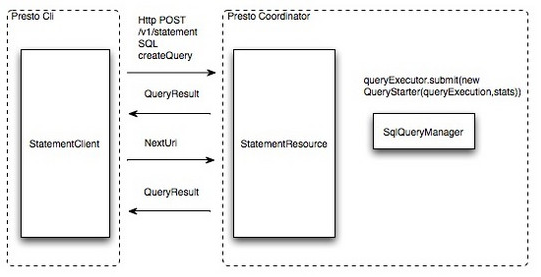
- 提交查询:用户使用Presto Cli提交一个查询语句后,Cli使用HTTP协议与Coordinator通信,Coordinator收到查询请求后调用SqlParser解析SQL语句得到Statement对象,并将Statement封装成一个QueryStarter对象放入线程池中等待执行,如下图:示例SQL如下
select c1.rank, count(*) from dim.city c1 join dim.city c2 on c1.id = c2.id where c1.id > 10 group by c1.rank limit 10;
- 逻辑执行过程示意图如下:
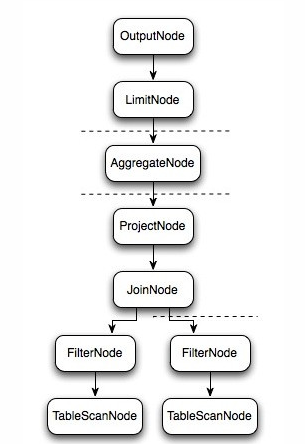
- 上图逻辑执行计划图中的虚线就是Presto对逻辑执行计划的切分点,逻辑计划Plan生成的SubPlan分为四个部分,每一个SubPlan都会提交到一个或者多个Worker节点上执行
- SubPlan有几个重要的属性planDistribution、outputPartitioning、partitionBy属性整个执行过程的流程图如下:
- PlanDistribution:表示一个查询阶段的分发方式,上图中的4个SubPlan共有3种不同的PlanDistribution方式
- Source:表示这个SubPlan是数据源,Source类型的任务会按照数据源大小确定分配多少个节点进行执行
- Fixed: 表示这个SubPlan会分配固定的节点数进行执行(Config配置中的query.initial-hash-partitions参数配置,默认是8)
- None: 表示这个SubPlan只分配到一个节点进行执行
- OutputPartitioning:表示这个SubPlan的输出是否按照partitionBy的key值对数据进行Shuffle(洗牌), 只有两个值HASH和NONE
- PlanDistribution:表示一个查询阶段的分发方式,上图中的4个SubPlan共有3种不同的PlanDistribution方式
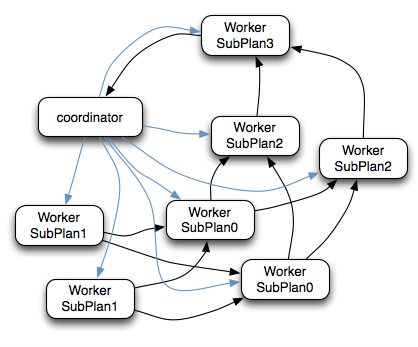
- 在上图的执行计划中,SubPlan1和SubPlan0 PlanDistribution=Source,这两个SubPlan都是提供数据源的节点,SubPlan1所有节点的读取数据都会发向SubPlan0的每一个节点;SubPlan2分配8个节点执行最终的聚合操作;SubPlan3只负责输出最后计算完成的数据,如下图:
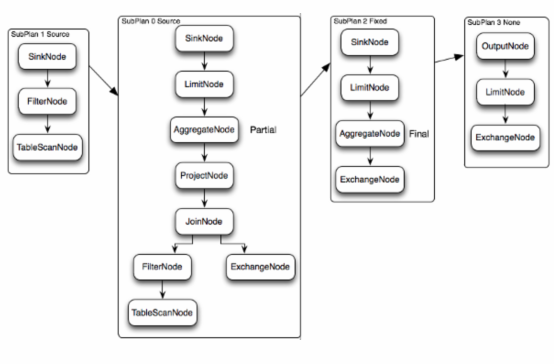
- SubPlan1和SubPlan0 作为Source节点,它们读取HDFS文件数据的方式就是调用的HDFS InputSplit API,然后每个InputSplit分配一个Worker节点去执行,每个Worker节点分配的InputSplit数目上限是参数可配置的,Config中的query.max-pending-splits-per-node参数配置,默认是100
- SubPlan1的每个节点读取一个Split的数据并过滤后将数据分发给每个SubPlan0节点进行Join操作和Partial Aggr操作
- SubPlan0的每个节点计算完成后按GroupBy Key的Hash值将数据分发到不同的SubPlan2节点
- 所有SubPlan2节点计算完成后将数据分发到SubPlan3节点
- SubPlan3节点计算完成后通知Coordinator结束查询,并将数据发送给Coordinator
presto引擎对比
- 与hive、SparkSQL对比结果图

Presto 架构和原理简介(转)的更多相关文章
- Presto架构及原理
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 ...
- presto架构和原理
Presto 是 Facebook 推出的一个基于Java开发的大数据分布式 SQL 查询引擎,可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别,据称该引擎的性能是 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- kafka原理简介并且与RabbitMQ的选择
kafka原理简介并且与RabbitMQ的选择 kafka原理简介,rabbitMQ介绍,大致说一下区别 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和 ...
- Oracle Golden Gate原理简介
Oracle Golden Gate原理简介 http://www.askoracle.org/oracle/HighAvailability/20140109953.html#6545406-tsi ...
- storm架构及原理
storm 架构与原理 1 storm简介 1.1 storm是什么 如果只用一句话来描述 storm 是什么的话:分布式 && 实时 计算系统.按照作者 Nathan Marz 的说 ...
- Hbase架构与原理(转)
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”.就像Bigtable利 ...
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- storm 原理简介及单机版安装指南——详细版【转】
storm 原理简介及单机版安装指南 本文翻译自: https://github.com/nathanmarz/storm/wiki/Tutorial 原文链接自:http://www.open-op ...
随机推荐
- Scrapy项目结构分析和工作流程
新建的空Scrapy项目: spiders目录: 负责存放继承自scrapy的爬虫类.里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或 ...
- 如何查看Unity的版本
打开Unity,Help->About Unity
- iOS企业版应用发布(部分低版本系统)无法安装到最新版app的问题-缓存导致
通过自己网站发布企业版app时,经过测试发现在部分已安装过旧版app的低版本ios手机存在这样的问题 :扫码覆盖安装新版app,安装到的仍然是就版本的app.这样就导致部分用户一直无法更新到最新版本. ...
- 零拷贝-zero copy
Efficient data transfer through zero copy Zero Copy I: User-Mode Perspective 0. 前言 在阅读RocketMQ的官方文档时 ...
- sql注入总结(一)--2018自我整理
SQL注入总结 前言: 本文和之后的总结都是进行总结,详细实现过程细节可能不会写出来~ 所有sql语句均是mysql数据库的,其他数据库可能有些函数不同,但是方法大致相同 0x00 SQL注入原理: ...
- Codeforces.542E.Playing on Graph(二分图)
题目链接 \(Description\) 给出一个n个点m条边的无向图. 你每次需要选择两个没有边相连的点,将它们合并为一个新点,直到这张图变成了一条链. 最大化这条链的长度,或输出无解. n< ...
- Python3练习题系列(07)——列表操作原理
目标: 理解列表方法的真实含义. 操作: list_1.append(element) ==> append(list_1, element) mystuff.append('hello') 这 ...
- jsp下载word
<%@ page language="java" contentType="application/msword;charset=utf-8"%> ...
- Python:内置函数
Python所有的内置函数 Built-in Functions abs() divmod() input() open() staticmethod() all() enumerat ...
- FMDB使用简介
转:http://my.oschina.net/youzaiyouzaie/blog/92325 源码地址:https://github.com/ccgus/fmdb 这次要分享的是在iOS中使用SQ ...