什么是UTF-8
1)开篇啰嗦
感谢这篇博客,在网上转悠了好几天,觉得下面这篇博客我读起来最最容易理解
https://blog.csdn.net/guxiaonuan/article/details/78678043
2)起源
ASCII码大家都很熟悉了,事实证明,对可以用ASCII表示的字符使用UNICODE并不高效,因为Unicode比ASCII码占用大一倍的空间,对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符及,他们被称为通用转换格式,即UTF(Unicode Transformation Format)。常见的UTF格式有UTF-7, UTF-7.5, UTF-8,UTF-16, 以及 UTF-32。
字符集为每个字符分配了一个唯一的编号,通过这个编号就能找到对应的字符。在编程过程中我们经常会使用字符,而使用字符的前提就是把字符放入内存中,毫无疑问,放入内存中的仅仅是字符的编号,而不是真正的字符实体。
3)如何才能将字符编号放入内存中
对于 ASCII 字符集,这很容易。ASCII 总共包含 128 个字符,用 7 个比特位(Bit)恰好能够存储,不过考虑到计算机一般把字节(Byte)作为基本单元,为了操作方便,我们不妨用一个字节(也就是 8 个比特位)来存储 ASCII。这样虽然浪费了一个比特位,但是读写效率提高了。
但是对于 Unicode,问题就没有这么简单了。Unicode 目前已经包含了上百万的字符,位置靠前的字符用一个字节就能存储,位置靠后的字符用三个字节才能存储。我们可以为所有字符都分配三个字节的内存,也可以为编号小的字符分配一个字节或者两个字节的内存,而为编号大的字符分配三个字节的内存。
----字符集和字符编码不一样
字符集和字符编码不是一个概念,字符集定义了文字和二进制的对应关系,为字符分配了唯一的编号,而字符编码规定了如何将文字的编号存储到内存中。有的字符集在制定时就考虑到了编码的问题,是和编码结合在一起的;有的字符集只管制定字符的编号,至于怎么编码,是其他人的事情。
4)方案1:为每个字符分配固定长度的内存
目前的 Unicode 已经收录了上百万的字符,至少需要三个字节才能容纳下所有的字符编号。假设字符 'A3中¥' 的 Unicode 编码值(十六进制形式)分别是 2A、31、DA49、BB672C,那么它们在内存中的存储形式为:

在几乎所有的字符集中,常用字符的编号往往比较小,罕见字符的编号往往比较大,包括 Unicode 在内。
’A‘和‘3’ 是 ASCII 编码中的字符,Unicode 为了兼容 ASCII,在设计时刻意保留了原来 ASCII 中字符的编号,所以英文字母和阿拉伯数字在 Unicode 中的编号都非常小,用一个字节足以容纳。¥可以看做是一个极其少见,或者只有极少数地区才会使用到的字符,这样的字符编号往往比较大,有时候需要三个字节才能容纳。
¥是人民币符号,是汉字文化的一部分,它和其它汉字一样,实际上是用两个字节存储的,不过这里我们为了演示,故意犯错地说它需要三个字节。
上图中带灰色背景的字节是没有用到的字节,它们就是被浪费掉的一部分内存空间,这就是用固定长度的内存来存储字符编号的缺点:常用字符的编号都比较小,这种方案会浪费很多内存空间,对于以英文为主的国家,比如美国、加拿大、英国等,内存利用率甚至会低于 50%。
5)方案2:为每个字符分配尽量少的内存
既然上面的方案有缺点,那我们就来改进一下。改进的思路也很明确,就是把空闲的内存压缩掉,为每个字符分配尽量少的字节,例如, 'A' 和 '3' 分配一个字节足以, '中'分配两个字节足以
这样虽然没有了空闲字节,不浪费任何内存空间了,但是又出现新的问题了:如果我不说,怎么知道’2A‘表示一个字符,而不是'2A31' 或者’2A31DA‘才表示一个字符?后面的字符也有类似的问题。
对于第一种方案,每个字符占用的字节数是固定的,很容易区分各个字符;而这种方案,不同的字符占用的字节数不同,字符之间也没有特殊的标记,计算机是无法定位字符的。
这种方案还需要改进,必须让不同的字符编码有不同的特征,并且字符处理程序也需要调整,要根据这些特征去识别不同的字符。
要想让不同的字符编码有不同的特征,可以从两个方面下手:
1) 一是从字符集本身下手,在设计字符集时,刻意让不同的字符编号有不同的特征。
例如,对于编号较小的、用一个字节足以容纳的字符,我们就可以规定这个字符编号的最高位(Bit)必须是 0;对于编号较大的、要用两个字节存储的字符,我们就可以规定这个字符编号的高字节的最高位必须是 1,低字节的最高位必须是 0;对于编号更大的、需要三个字节存储的字符,我们就可以规定这个字符编号的所有字节的最高位都必须是 1。
程序在定位字符时,从前往后依次扫描,如果发现当前字节的最高位是 0,那么就把这一个字节作为一个字符编号。如果发现当前字节的最高位是 1,那么就继续往后扫描,如果后续字节的最高位是 0,那么就把这两个字节作为一个字符编号;如果后续字节的最高位是 1,那么就把挨着的三个字节作为一个字符编号。
这种方案的缺点很明显,它会导致字符集不连续,中间留出大量空白区域,这些空白区域不能定义任何字符。
2) 二是从字符编号下手,可以设计一种转换方案,字符编号在存储之前先转换为有特征的、容易定位的编号,读取时再按照相反的过程转换成字符本来的编号。
那么,转换后的编号要具备什么样的特征呢?其实也可以像上面一样,根据字节的最高位是 0 还是 1 来判断字符到底占用了几个字节。
相比第一种方案,这种方案有缺点也有优点:
- 缺点就是多了转换过程,字符在存储和读取时要经过转换,效率低;
- 优点就是在制定字符集时不用考虑存储的问题,可以任意排布字符。
6)Unicode 到底使用哪种编码方案
Unicode 是一个独立的字符集,它并不是和编码绑定的,你可以采用第一种方案,为每个字符分配固定长度的内存,也可以采用第二种方案,为每个字符分配尽量少的内存。
需要注意的是,Unicode 只是一个字符集,在制定的时候并没有考虑编码的问题,所以采用第二种方案时,就不能从字符集本身下手了,只能从字符编号下手,这样在存储和读取时都要进行适当的转换。
Unicode 可以使用的编码有三种,分别是:
- UFT-8:一种变长的编码方案,使用 1~6 个字节来存储;
- UFT-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
- UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
UTF 是 Unicode Transformation Format 的缩写,意思是“Unicode转换格式”,后面的数字表明至少使用多少个比特位(Bit)来存储字符。
6) UTF-8
UTF-8 的编码规则很简单:如果只有一个字节,那么最高的比特位为 0;如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
- 0xxxxxxx:单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的;
- 110xxxxx 10xxxxxx:双字节编码形式;
- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式;
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式。
xxx 就用来存储 Unicode 中的字符编号。
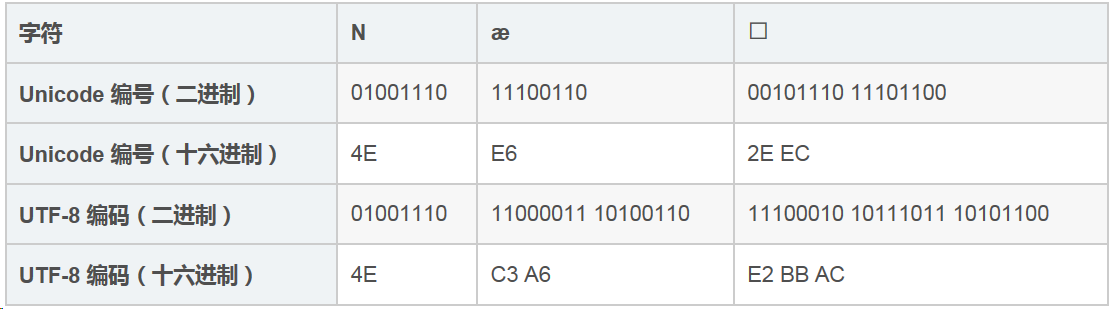
对于常用的字符,它的 Unicode 编号范围是 0 ~ FFFF,用 1~3 个字节足以存储,只有及其罕见,或者只有少数地区使用的字符才需要 4~6个字节存储。
只有 UTF-8 兼容 ASCII,UTF-32 和 UTF-16 都不兼容 ASCII,因为它们没有单字节编码。
什么是UTF-8的更多相关文章
- 从Java String实例来理解ANSI、Unicode、BMP、UTF等编码概念
转(http://www.codeceo.com/article/java-string-ansi-unicode-bmp-utf.html#0-tsina-1-10971-397232819ff9a ...
- ascii、unicode、utf、gb等编码详解
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物.他们看到8个开关状态是好的,于是他们把这称为"字节".再后来,他们又做了一些可以处理这 ...
- 转载:谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词
转载: 谈谈Unicode编码,简要解释UCS.UTF.BMP.BOM等名词 这是一篇程序员写给程序员的趣味读物.所谓趣味是指可以比较轻松地了解一些原来不清楚的概念,增进知识,类似于打RPG游戏的升级 ...
- Unicode 与 UTF 字符标准
Unicode 国际字符标准(UCS)是一个字符编码系统,它被设计用来支持世界各国不同语言书面文体之间的数据交换.处理以及显示. Unicode用两个字节表示一个字符.前127个字符与A ...
- 利用zxing制作彩色,高容错,支持中文等UTF编码的QR二维码图片
利用zxing制作彩色,高容错,支持中文等UTF编码的QR二维码图片.代码如下 import java.awt.Color;import java.io.File;import java.util.H ...
- UTF编码问题小结
在编程当中经常出现乱码的问题,而由此一般会引发很多惨剧,如读文件不成功.用户名显示乱码等,所以端午节抽了一小点时间好好看了一下编码问题,以备遗忘. 首先是中文编码,除了台湾和香港常用的BIG5,国内大 ...
- 请问什么是UTF字符串?
utf是编码方式,一般而言是国际性质的编码格式,有utf-8,utf-9,utf-16等多种形式,是最高级别的编码方式,也就是说如果你要读取的数据流设置成utf编码的话就要用到相应的编码方式来读取了, ...
- jsp中pageEncoding、charset=UTF -8
jsp中pageEncoding.charset=UTF -8" 在JSP/Servlet 中主要有以下几个地方可以设置编码,pageEncoding="UTF-8". ...
- java 乱码详解_jsp中pageEncoding、charset=UTF -8"、request.setCharacterEncoding("UTF-8")
http://blog.csdn.net/qinysong/article/details/1179480 java 乱码详解__jsp中pageEncoding.charset=UTF -8&quo ...
- Unicode(UTF&UCS)深度历险
Unicode(UTF&UCS)深度历险 计算机网络诞生后,大家慢慢地发现一个问题:一个字节放不下一个字符了!因为需要交流,本地化的文字需要能够被支持. 最初的字符集使用7bit来存储字符,因 ...
随机推荐
- spring mvc 资源映射配置
在springmvc配置文件中添加 <mvc:resources location="/css/" mapping="/css/**"/> < ...
- spring学习(02)之配置文件没有提示问题
配置文件没有提示问题 1 spring引入schema约束,把约束文件引入到eclipse中 (1)复制约束路径 http://www.springframework.org/schema/beans ...
- 【Selenium】selenium中隐藏元素如何定位?
前言 面试题:selenium 中隐藏元素如何定位?这个是很多面试官喜欢问的一个题,如果单纯的定位的话,隐藏元素和普通不隐藏元素定位没啥区别,用正常定位方法就行了 但是吧~~~很多面试官自己都搞不清楚 ...
- SSH高级服务
SSH端口转发 SSH 会自动加密和解密所有 SSH 客户端与服务端之间的网络数据.但是,SSH 还能够将其他 TCP 端口的网络数据通过 SSH 链接来转发,并且自动提供了相应的 加密及解密服务.这 ...
- 001-分布式理论-CAP定理
一.概述 CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性). Availability(可用性).Partition tolerance(分区容错性)这三个基本需求 ...
- ES6的export与Nodejs的module.exports
原文:https://www.cnblogs.com/lxg0/p/7774094.html module.exports与exports,export与export default之间的关系和区别 ...
- spring boot 使用视图modelandview
1:springboot使用视图解析器,添加依赖 <!-- freemarker模板引擎视图 --> <dependency> <groupId>org.sprin ...
- js中实现IE的打印预览
HTML中添加:<object id="WebBrowser" classid=CLSID:8856F961-340A-11D0-A96B-00C04FD705A2 widt ...
- itemscope itemtype="http://schema.org/AggregateRating"
Review Canonical URL: http://schema.org/Review Thing > CreativeWork > Review A review of an it ...
- calibur处理ROSETTA输出的多个结构文件,clustering
下载网址:https://sourceforge.net/projects/calibur/ 安装: $ tar zxvf calibur.tar.gz $ cd calibur $ make 安装完 ...