Spark学习之路 (十三)SparkCore的调优之资源调优JVM的基本架构
一、JVM的结构图
1.1 Java内存结构
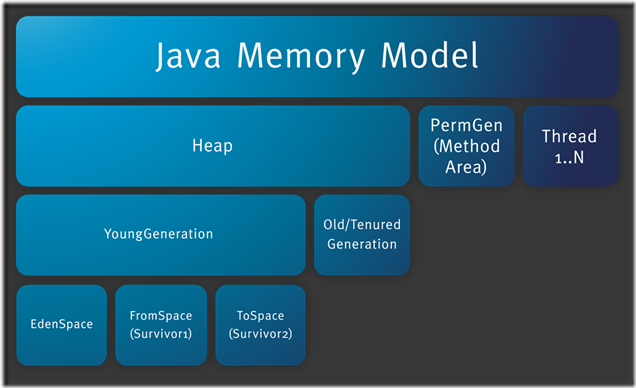
JVM内存结构主要有三大块:堆内存、方法区和栈。
堆内存是JVM中最大的一块由年轻代和老年代组成,而年轻代内存又被分成三部分,Eden空间、From Survivor空间、To Survivor空间,默认情况下年轻代按照8:1:1的比例来分配;
方法区存储类信息、常量、静态变量等数据,是线程共享的区域,为与Java堆区分,方法区还有一个别名Non-Heap(非堆);
栈又分为java虚拟机栈和本地方法栈主要用于方法的执行。
1.2 如何通过参数来控制各区域的内存大小
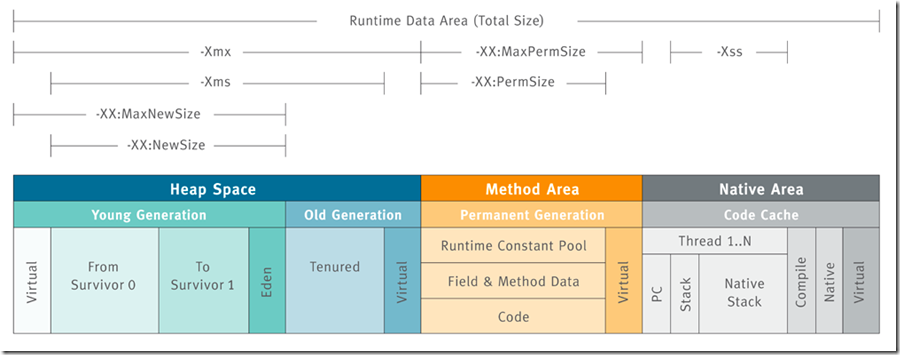
1.3 控制参数
-Xms设置堆的最小空间大小。
-Xmx设置堆的最大空间大小。
-XX:NewSize设置新生代最小空间大小。
-XX:MaxNewSize设置新生代最大空间大小。
-XX:PermSize设置永久代最小空间大小。
-XX:MaxPermSize设置永久代最大空间大小。
-Xss设置每个线程的堆栈大小。
没有直接设置老年代的参数,但是可以设置堆空间大小和新生代空间大小两个参数来间接控制。
老年代空间大小=堆空间大小-年轻代大空间大小
1.4 JVM和系统调用之间的关系
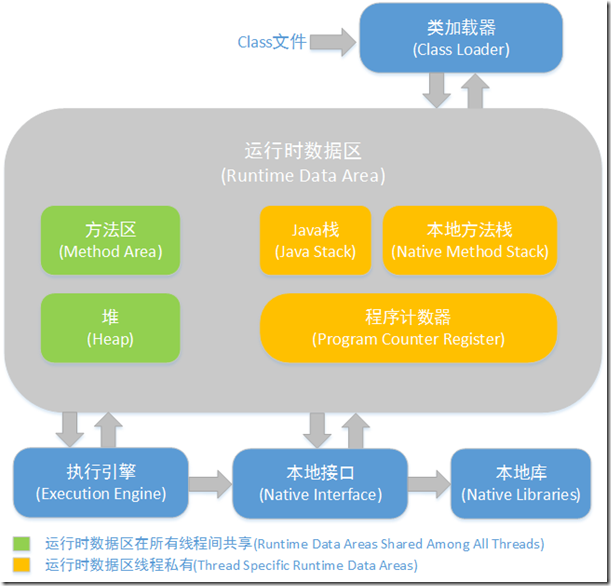
方法区和堆是所有线程共享的内存区域;而java栈、本地方法栈和程序员计数器是运行是线程私有的内存区域。
二、JVM各区域的作用
2.1 Java堆(Heap)
对于大多数应用来说,Java堆(Java Heap)是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
Java堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC堆”。如果从内存回收的角度看,由于现在收集器基本都是采用的分代收集算法,所以Java堆中还可以细分为:新生代和老年代;再细致一点的有Eden空间、From Survivor空间、To Survivor空间等。
根据Java虚拟机规范的规定,Java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们的磁盘空间一样。在实现时,既可以实现成固定大小的,也可以是可扩展的,不过当前主流的虚拟机都是按照可扩展来实现的(通过-Xmx和-Xms控制)。
如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常。
2.2 方法区(Method Area)
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
对于习惯在HotSpot虚拟机上开发和部署程序的开发者来说,很多人愿意把方法区称为“永久代”(Permanent Generation),本质上两者并不等价,仅仅是因为HotSpot虚拟机的设计团队选择把GC分代收集扩展至方法区,或者说使用永久代来实现方法区而已。
Java虚拟机规范对这个区域的限制非常宽松,除了和Java堆一样不需要连续的内存和可以选择固定大小或者可扩展外,还可以选择不实现垃圾收集。相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入了方法区就如永久代的名字一样“永久”存在了。这个区域的内存回收目标主要是针对常量池的回收和对类型的卸载,一般来说这个区域的回收“成绩”比较难以令人满意,尤其是类型的卸载,条件相当苛刻,但是这部分区域的回收确实是有必要的。
根据Java虚拟机规范的规定,当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。
2.3 程序计数器(Program Counter Register)
程序计数器(Program Counter Register)是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里(仅是概念模型,各种虚拟机可能会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
由于Java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
如果线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Natvie方法,这个计数器值则为空(Undefined)。
此内存区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域。
2.4 JVM栈(JVM Stacks)
与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stacks)也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它不等同于对象本身,根据不同的虚拟机实现,它可能是一个指向对象起始地址的引用指针,也可能指向一个代表对象的句柄或者其他与此对象相关的位置)和returnAddress类型(指向了一条字节码指令的地址)。
其中64位长度的long和double类型的数据会占用2个局部变量空间(Slot),其余的数据类型只占用1个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
在Java虚拟机规范中,对这个区域规定了两种异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;如果虚拟机栈可以动态扩展(当前大部分的Java虚拟机都可动态扩展,只不过Java虚拟机规范中也允许固定长度的虚拟机栈),当扩展时无法申请到足够的内存时会抛出OutOfMemoryError异常。
2.5 本地方法栈(Native Method Stacks)
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native方法服务。虚拟机规范中对本地方法栈中的方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。甚至有的虚拟机(譬如Sun HotSpot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。
Spark学习之路 (十三)SparkCore的调优之资源调优JVM的基本架构的更多相关文章
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
- Spark学习之路 (八)SparkCore的调优之开发调优[转]
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark(六)Spark之开发调优以及资源调优
Spark调优主要分为开发调优.资源调优.数据倾斜调优.shuffle调优几个部分.开发调优和资源调优是所有Spark作业都需要注意和遵循的一些基本原则,是高性能Spark作业的基础:数据倾斜调优,主 ...
- Spark学习之路 (十一)SparkCore的调优之Spark内存模型
摘抄自:https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-apache-spark-memory-management/ind ...
- Spark学习之路 (十一)SparkCore的调优之Spark内存模型[转]
概述 Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优.本文旨在 ...
- Spark性能优化--开发调优与资源调优
参考: https://tech.meituan.com/spark-tuning-basic.html https://zhuanlan.zhihu.com/p/22024169 一.开发调优 1. ...
- Spark学习之路 (十二)SparkCore的调优之资源调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 一.概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都 ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优
摘抄自https://tech.meituan.com/spark-tuning-pro.html 一.概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘I ...
随机推荐
- JQuery is()与hasClass()方法的对比
is()和hasClass()方法都可以用以检查匹配的所有元素里是否含有指定类名,虽说hasClass(className)函数等价于is(“.className”) 但is()方法比hasClass ...
- BZOJ4391 High Card Low Card [Usaco2015 dec](贪心+线段树/set库
正解:贪心+线段树/set库 解题报告: 算辣直接甩链接qwq 恩这题就贪心?从前往后从后往前各推一次然后找一遍哪个地方最大就欧克了,正确性很容易证明 (这里有个,很妙的想法,就是,从后往前推从前往后 ...
- STLの应用
QAQ因为绝望地发现好像这些应用都没有题目...所以就专门开了个随笔存题面qwq 谁的孙子最多 给定一棵树,其中1号节点是根节点,问哪一个节点的孙子节点最多,有多少个.(孙子节点,就是儿子节点的儿子节 ...
- bzoj3733 [Pa2013]Iloczyn 搜索
正解:搜索 解题报告: 先放下传送门QwQ umm其实并不难,,,最近在复建基础姿势点所以都写的是些小水题QAQ 首先考虑如果能构造出来一定是因数凑起来鸭,所以先把因数都拆出来,然后就爆搜 几个常见的 ...
- Dubbo服务化框架使用整理
一.垂直应用架构拆分 在应用架构的演进过程中,垂直应用架构因为开发便捷,学习成本低,对于实现业务功能的增删改查提供了高效的开发支持,有利于前期业务高速发展的的快速实现.但是随着系统业务功能的不断扩展和 ...
- kvc原理
KVC底层实现原理 第一步:寻找该属性有没有setsetter方法?有,就直接赋值 第二步:寻找有没有该属性带下划线的成员属性?有,就直接赋值 第三步:寻找有没有该属性的成员属性?有,就直接赋值 1. ...
- InnoDB log file 设置多大合适?
简介: 数据库的东西,往往一个参数就牵涉N多知识点.所以简单的说一下.大家都知道innodb是支持事务的存储引擎.事务的四个特性ACID即原子性(atomicity),一致性(consistency) ...
- MySQL 创建用户并分配用户权限
mysql在最新的版本中会生成随机密码,存储在/etc/my.conf的文件中,但是大多数使用者不会在意这个,因为随机的密码识别性太差,所以我们可以自己配置数据库用户以及设置密码. 设置跳过密码登陆r ...
- Python3学习之路~6.6 类的继承
Inheritance 继承 面向对象编程 (OOP) 语言的一个主要功能就是“继承”.继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展.通过继承创 ...
- vue-3.0创建项目
.npm install --global @vue/cli .npm install -g @vue/cli-init .vue init webpack my-project