【原】关于AdaBoost的一些再思考
一、Decision Stumps:
Decision Stumps称为单层分类器,主要用作Ensemble Method的组件(弱分类器)。一般只进行一次判定,可以包含两个或者多个叶结点。对于离散数据,可以选取该属性的任意一个数据作为判定的分割点;对于连续数据,可以选择属性的一个阈值做为分割点进行判定(大于该阈值分配到一类,小于该阈值分配到另一类;当然也可以选取多个阈值并由此得到多个叶结点)。
二、AdaBoost的理解:
1、基本流程
简单的说,AdaBoost框架就是根据指定的参数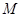 ,进行
,进行 轮训练得到
轮训练得到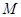 个弱分类器
个弱分类器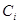 及每个弱分类器对应的权重
及每个弱分类器对应的权重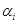 ,最后将这些弱分类器的结果进行线性组合得到最终的结果。
,最后将这些弱分类器的结果进行线性组合得到最终的结果。
关于多属性数据集的处理:
在每一轮训练过程中,在每个属性上根据分割的阈值不同得到多个单层分类器。在这些从所有属性上得到的分类器中选取一个带权误差率最小的单层分类器作为该轮训练的弱分类器。
2、带权分类误差
在进行训练之前,为训练集中的每个样本分配一个权重,使用向量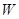 表示。在第
表示。在第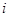 轮训练结束后,根据得到的弱分类器
轮训练结束后,根据得到的弱分类器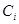 的性能计算该分类器
的性能计算该分类器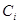 对应的权值
对应的权值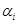 ,并由
,并由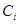 的在训练集上的分类结果对权重向量
的在训练集上的分类结果对权重向量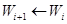 进行更新。
进行更新。
分类器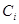 的性能度量和该分类器在训练集上的结果,都是通过计算该分类器在训练集上的带权分类误差获取。所谓带权分类误差,是指将待分类的样本包含的权重(此处的权重就是之前为该样本分配的权重),结合在该数据集上的分类误差得到分类器在该数据集上的一个考虑样本权重的分类误差,其定义如下:
的性能度量和该分类器在训练集上的结果,都是通过计算该分类器在训练集上的带权分类误差获取。所谓带权分类误差,是指将待分类的样本包含的权重(此处的权重就是之前为该样本分配的权重),结合在该数据集上的分类误差得到分类器在该数据集上的一个考虑样本权重的分类误差,其定义如下:
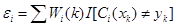 (1.1)
(1.1)
其中,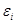 表示第
表示第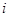 个弱分类器的带权分类误差值,
个弱分类器的带权分类误差值,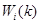 表示第
表示第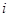 次更新后样本
次更新后样本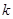 的权重,
的权重,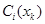 表示使用第
表示使用第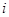 个弱分类器对样本
个弱分类器对样本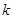 的分类结果,
的分类结果,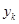 表示样本
表示样本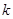 的真实标签,
的真实标签,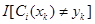 是一个指示函数,其值如下:
是一个指示函数,其值如下:
 (1.2)
(1.2)
通过公式(1.1)和(1.2)可以看出带权分类误差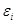 与两方面的因素相关:
与两方面的因素相关:
1) 分类器在样本上的误差值;
2) 样本集中每个样本的权重;
注意:AdaBoost就是通过该值与弱分类器产生关系。
3、带权分类误差再分析
以DS(Decision Stumps)弱分类器为例,对于一个数据集包含多个属性,要在该数据集上学习一个DS,可以使用不同的属性作为分割判断条件。对于同一个属性,也可以选择多个不同的分割点(离散型)/阈值(连续性)作为判断条件。因此,对于一个数据集实质上可以产生很多不同的DS,那么究竟选择哪一个DS作为我们从该数据集上最终学习得到的弱分类器?
很直观的想法,我们可以使用穷举产生所有的DS,然后分别计算每个DS的分类误差,选择具有最小分类误差的DS作为从该数据集上学习到的弱分类器。然而,问题出在我们学习的这个数据集中的所有样本权重(此处可以理解为每个样本的价值、贡献度等)并不相同。我们在考虑选择哪个DS最为最终的弱分类器时不但要考虑该DS的分类错误率,还要考虑每个样本的权重问题,因为将高权重的样本分错造成的后果远比将低权重样本分错更为严重。
考虑公式(1.1)中带权分类误差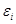 的定义,该指标有效的将分类器的分类误差和待分类样本的权重结合起来,因此可以作为选择弱分类器时的一个标准使用。
的定义,该指标有效的将分类器的分类误差和待分类样本的权重结合起来,因此可以作为选择弱分类器时的一个标准使用。
总结起来简单的说,带权分类误差 将分类器的分类误差和样本本身的权重进行结合,可以作为模型选择的一个标准使用。
将分类器的分类误差和样本本身的权重进行结合,可以作为模型选择的一个标准使用。
4、弱分类器的权重计算
弱分类器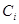 对应的权重
对应的权重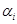 与其本身的带权分类误差相关,其计算公式如下:
与其本身的带权分类误差相关,其计算公式如下:
 (1.3)
(1.3)
通过简单分析可以知道,带权分类误差的范围是[0,1],绘制分类器的权重函数的图像,如下所示:
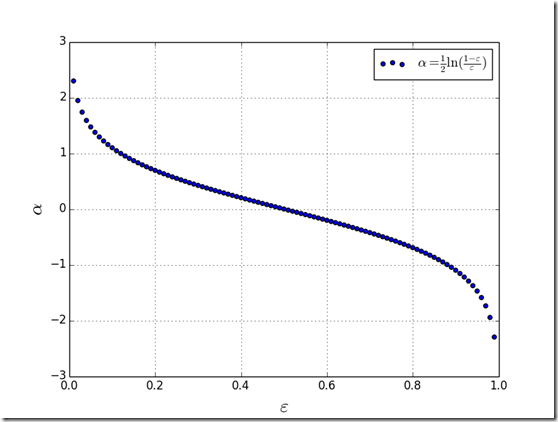
Fig. 1. 弱分类器权重函数分布
由Fig. 1.可以看出,弱分类器的权重与其对应的带权分类误差呈反比关系,即就是带权分类误差越小,该分类器对应的权值越大;反之亦然。
5、训练样本的权重更新
训练得到新的弱分类器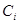 后需要对样本权值
后需要对样本权值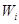 进行更新,更新的公式如下:
进行更新,更新的公式如下:
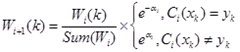 (1.4)
(1.4)
公式(1.4)定义了计算弱分类器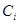 对应的权值
对应的权值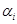 后,对样本
后,对样本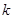 的权重更新过程。如果该分类器在该样本上分类正确,则降低该样本的权值;如果分类错误,则提高该样本的权值。公式中前半部分
的权重更新过程。如果该分类器在该样本上分类正确,则降低该样本的权值;如果分类错误,则提高该样本的权值。公式中前半部分
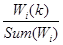 主要用于对整个权值向量进行归一化,以使其和为1。
主要用于对整个权值向量进行归一化,以使其和为1。
6、参考
维基百科关于AdaBoost算法的介绍:
用 xi 和 yi 表示原始样本集D的样本点和它们的类标(注意,yi的取值只能是+1或-1)。用 Wk(i) 表示第k次迭代时全体样本的权重分布。这样就有如下所示的AdaBoost算法:
1. begin initial D={x1,y1,...,xn,yn},kmax(最大循环次数),Wk(i)=1/n,i=1,...,n
2. k ← 0
3. do k ← k+1
4. 训练使用按照 Wk(i) 采样的 D 的弱学习器 Ck
5. Ek ← 对使用 Wk(i) 的 D 测量的 Ck 的训练误差
6. 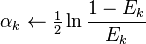
7. 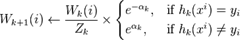
8. until k=kmax
9. return Ck和αk,k=1,...,kmax(带权值分类器的总体)
10. end
注意第5行中,当前权重分布必须考虑到分类器 Ck 的误差率。在第7行中, Zk 只是一个归一化系数,使得 Wk(i) 能够代表一个真正的分布,而 hk(xi) 是分量分类器 Ck 给出的对任一样本点 xi 的标记(+1或-1),hk(xi) = yi 时,样本被正确分类。第8行中的迭代停止条件可以被换为判断当前误差率是否小于一个阈值。
最后的总体分类的判决可以使用各个分量分类器加权平均来得到:
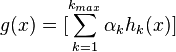
这样,最后对分类结果的判定规则是:

三、整体流程再梳理
按照自己的理解将AdaBoost的框架再进行梳理一遍,整个Boost框架分为两部分:训练和分类。
假设样本的类别为: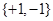
1、训练部分
a) 为训练集中每个样本分配权重
;
b) 训练弱分类器
;
c) 计算带权分类误差
;
d) 计算弱分类器对应的权重
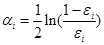
e) 更新样本权重
最终得到
个不同的弱分类器及其对应的权重。
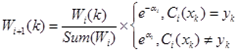

2、分类部分
a) 对待分类样本
计算函数

b) 对该样本最终的分类结果为
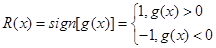
四、核心问题再讨论
1、带权分类误差的作用:
在第二部分详细讨论了带权样本误差的生成机制问题,描述了如何计算带权样本误差和它怎样对AdaBoost框架产生影响。这里,将带权样本误差的作用再做以简单的总结,带权分类误差的主要作用有两个:
1、 在训练弱分类器时,使用该指标在训练的多个DS中选择带权分类误差最小的最为该轮训练的弱分类器;
2、 在AdaBoost框架中,使用该指标计算该轮训练得到的弱分类器对应的权值;
2、弱分类器的误差和AdaBoost框架的误差:
实质上,在整个训练的过程中,每轮训练得到的弱分类器可能一直会存在分类错误的问题(不论训练了多少轮,生成的单个弱分类器都有分类错误),然而整个AdaBoost框架却有可能快速收敛(整个AdaBoost框架的错误率为0)。造成这个现象的原因是:
每轮训练结束后,AdaBoost框架会对样本的权重进行调整,该调整的结果是越到后面被错误分类的样本权重会越高。这样到后面,单个弱分类器为了达到较低的带权分类误差都会把样本权重高的样本分类正确。虽然单独来看,单个弱分类器仍会造成分类错误,但这些被错误分类的样本的权重都较低,在AdaBoost框架的最后输出时会被前面正确分类的高权重弱分类器“平衡”掉。这样造成的结果就是,虽然每个弱分类器可能都有分错的样本,然而整个AdaBoost框架却能保证对每个样本进行正确分类,从而实现快速收敛。
【原】关于AdaBoost的一些再思考的更多相关文章
- 问题:一球从某高度自由落下,每次落地后反跳回原高度的一半;再落下,求它在第n次落地时,共经过多少米?第n次反弹多高?
import java.util.Scanner; //题目:一球从100米高度自由落下,每次落地后反跳回原高度的一半:再落下,求它在第10次落地时,共经过多少米?第10次反弹多高? public c ...
- HDU 5135(再思考)
题意略. 思路:再思考后发现,为了构造出最大的三角形面积和,我们应该尽量让长的棍子相组合,这样构造出的三角形面积和最大,贪心能解. #include<bits/stdc++.h> usin ...
- EventBus/EventQueue 再思考
EventBus/EventQueue 再思考 Intro 之前写过两篇文章,造轮子系列的 EventBus/EventQueue,回想起来觉得当前的想法有点问题,当时对 EvenStore 可能有点 ...
- 一球从100米高度自由落下,每次落地后反跳回原高度的一半;再落下,求它在第n次落地时,共经过多少米?第n次反弹多高?(n<=10)
单纯考逻辑 题目: 一球从100米高度自由落下,每次落地后反跳回原高度的一半:再落下,求它在第n次落地时,共经过多少米?第n次反弹多高?(n<=10) 输入描述: 一行,一个整数n (1< ...
- Web系统开发构架再思考-前后端的完全分离
前言 前后端完全分离其实一直是Web开发人员的梦想,也一直是我的梦想,遥想当年,无论是直接在代码里面输出HTML,还是在HTML里面嵌入各种代码,都不能让人感到满意.期间的痛苦和纠结,我想所有Web开 ...
- GPU计算的十大质疑—GPU计算再思考
http://blog.csdn.NET/babyfacer/article/details/6902985 原文链接:http://www.hpcwire.com/hpcwire/2011-06-0 ...
- 开源应用框架BitAdminCore重构再思考
索引 NET Core应用框架之BitAdminCore框架应用篇系列 框架演示:https://www.bitadmincore.com 框架源码:https://github.com/chenyi ...
- 【Python3练习题 015】 一球从100米高度自由落下,每次落地后反跳回原高度的一半,再落下。求它在第10次落地时,共经过多少米?第10次反弹多高?
a = [100] #每个‘反弹落地’过程经过的路程,第1次只有落地(100米) h = 100 #每个‘反弹落地’过程,反弹的高度,第1次为100米 print('第1次从%s米高落地,走过%s ...
- 22.一个球从100m高度自由下落,每次落地后返跳回原高度的一半,再反弹。求它在第10次落地时,共经过多少米,第10次反弹多高。
#include <stdio.h> #include <stdlib.h> int main() { ,hn=sn/; int i; ;i<=;i++) //注意i是从 ...
随机推荐
- html 转成 pdf 进行预览、下载、打印
html 页面转成 pdf,直接看代码: 参考地址: https://github.com/linwalker/render-html-to-pdf 给出代码 方便粘贴: var downPdf = ...
- C# DataGridView插入DB
public static bool ContrastColumns(DataColumnCollection co1, DataGridViewColumnCollection co2) { boo ...
- jQuery Ajax -附示例
jQuery其实就是一个JavaScript的类库,其将复杂的功能做了上层封装,使得开发者可以在其基础上写更少的代码实现更多的功能. jQuery 不是生产者,而是大自然搬运工. jQuery Aja ...
- [NOIp2009普及组]细胞分裂
思路: 首先将$30000$以内的所有质数求出,再对$m1$质因数分解. 对于每个$s$,计算它和$m1$的每个公共质因数的倍数关系,取$max$则为该细胞满足条件所花费的最少时间. 再对于每个细胞的 ...
- Editplus中添加System.out.println()快捷键
首先,找到自己电脑Editplus的安装路径,在所属文件夹中找到JAVA.ACP文件: 然后,在文件的末尾加上如下代码: #T=syso System.out.println("^!&quo ...
- 毫秒转时间(java.js)
SimpleDateFormat sdf = new SimpleDateFormat( "yyyy-MM-dd HH:mm:ss"); GregorianCalendar gc ...
- 根据请求号(request ID)查找正在运行的sql
--下面的SQL可以根据Request ID找到对应的Session信息: select * from v$session where paddr in (select addr from v$pro ...
- IEEE 754二进制浮点数算术标准
可能很多人都遇到过浮点数精度丢失的问题,下面以JavaScript为例. 1 - 0.9 = 0.09999999999999998 纳尼,不应该是0.1么,怎么变成0.099999999999999 ...
- 如何在Windows 10上访问NFS的share
大致过程是: 1. 开启名为"Services for NFS"的Windows Feature. 2. 如果需要拥有写权限,需要修改注册表. 3. Mount即可. 具体步骤详见 ...
- 【GPU编解码】GPU硬解码---DXVA (转)
前面介绍利用NVIDIA公司提供的CUVID库进行视频硬解码,下面将介绍利用DXVA进行硬解码. 一.DXVA介绍 DXVA是微软公司专门定制的视频加速规范,是一种接口规范.DXVA规范制定硬件加速解 ...