ELKF安装使用教程。elasticsearch+logstash+kibana+filebeta。
近期因工作需要学习了ELKF的安装和使用。网络上的中文我看大部分也比较老版本了,我想写一下,希望能给他人带来一点帮助。小弟不才,有错位之处,还请大家原谅指点。
ELKF就是:elasticsearch+logstash+kibana+filebeta。
这是一个什么东西呢?
这是一个通用的日志监控工具。可以把他当做一个数据平台,可以把他作为一个异常监控平台。可以有很多的报表,折线等显示系统当前运行情况。我个人觉得更主要的是显示业务指标情况。或者系统指标情况。当然前提是你得做好日志埋点工作。
elasticsearch
elasticsearch是一个文本数据库,基于lucene,lucene是一个分词以及建立索引的API,原理是倒排索引,对中文分词效果一般,但是可以自己添加分词器,汉字也有几个比较好的分词器,IK等,具体的可以查一下。elasticsearch在ELKF中可以把他认作数据库+model层。也可以把它认作是没有爬虫的搜索引擎。他可以很好的处理数据,分词、建立索引等,当然也包含存储。普通的关系型数据库还得你自己建立索引、创建表格、建立视图、函数等。elasticsearch直接就可以做完。他同时也提供很多的API,你完全可以用它做站内搜索引擎都没问题,完全可以,但是这个就是比较高深的东西了,我后续一定会再更新。但是现在就先不说这些了。
kibana
kibana是什么,kibana说白了就是V+C层,在ELKF中就是显示层,可以从数据库(elasticsearch)查出来数据显示给你,当然了,他有很多的插件,可以花里胡哨的显示,客户或者领导就喜欢图嘛。你做好的埋点规范的时候就很方便了。没啥说的,安装使用教程后说。
filebeta+logstash
logstash,logstash这个东西elastic公司,我个人感觉好想要放弃了。因为5.X的版本中elasticsearch已经包含了他的部分功能,而且,这个东西很鸡肋,你采集日志的时候总不能在本地服务器采集吧,肯定要去远程采集呀,可是他不能远程采集,你要是部署在应用服务器,远程发送给elasticsearch也可以,可是应用服务器还玩不玩了?。太耗资源。所以我现在自己研究部署阶段时直接把logstash拿掉了。
filebeta
filebeta ,一句话,实时读取文件的家伙。跟kafaka很像。所以也有很多的公司在搭建框架的时候,采用kafaka+logstash+elasticsearch+kibana。说实话,我没这样用过,但是根据一贯的尿性,filebeta是elastic亲儿子。kafaka是,是吧。
所以我暂时采用了elasticsearch+kibana+filebeta的形式。
安装步骤:
安装步骤其实灰常简单。
第一步,安装需要的东西你得有。软硬件的,对吧。
硬件:你得有一台Linux服务器。内存,我是5个G的虚拟机。
软件:
软件你得有这些东西,elasticsearch官网就有,我就不用贴链接了吧。如果想直接下载到Linux上,就用wget。
java你得配置好,而且,官网上说了,5.6.X的跟1.8配合的很好,1.7的一般,1.6根本不支持。所以该卸载卸载,该安装安装。
贴一下卸载安装的链接吧,我就是找这个来的。
然后建个用户,专门用来操作这一套,这一套文件最好放在一个文件夹里,赋权限好赋,另外,为啥要在建一个用户?因为root用户起不来呀,我是平时就玩儿root用户,有用户的当然不用建了。
建完之后,先用root用户把这这几个文件所在的文件夹的权限付给新创建的用户。比如;
我的文件夹叫ypf,新创建的用户也叫ypf。root用户执行命令:
chown -R ypf ypf
然后切换ypf用户。这四个压缩包挨个解压。
解压完成后套路都是一样的,比如,elasticsearch的启动文件是/elasticsearch-5.6.2/bin/elasticsearch,配置文件是/elasticsearch-5.6.2/conf/elasticsearch.yml
kibana跟elasticsearch是一样的。心急的可以直接执行/elasticsearch-5.6.2/bin/elasticsearch启动了,如果报错的话,参照我上三篇里面的,应该就这几个错误。
将elasticsearch解压后的文件夹内的 /conf/elasticsearch.yml文件做一些修改。主要修改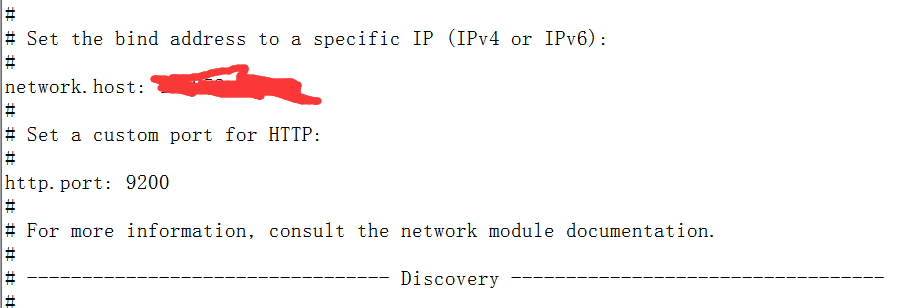
network.host和http.port,将他们的注释符号(#)都去掉,另外把host改为你的服务器地址。
里面还有一些集群方面的配置,但是暂时不需要。elasticsearch暂时就配置这些。
配置kibana,kibana.yml也在kibana的解压文件的/conf/文件夹下。
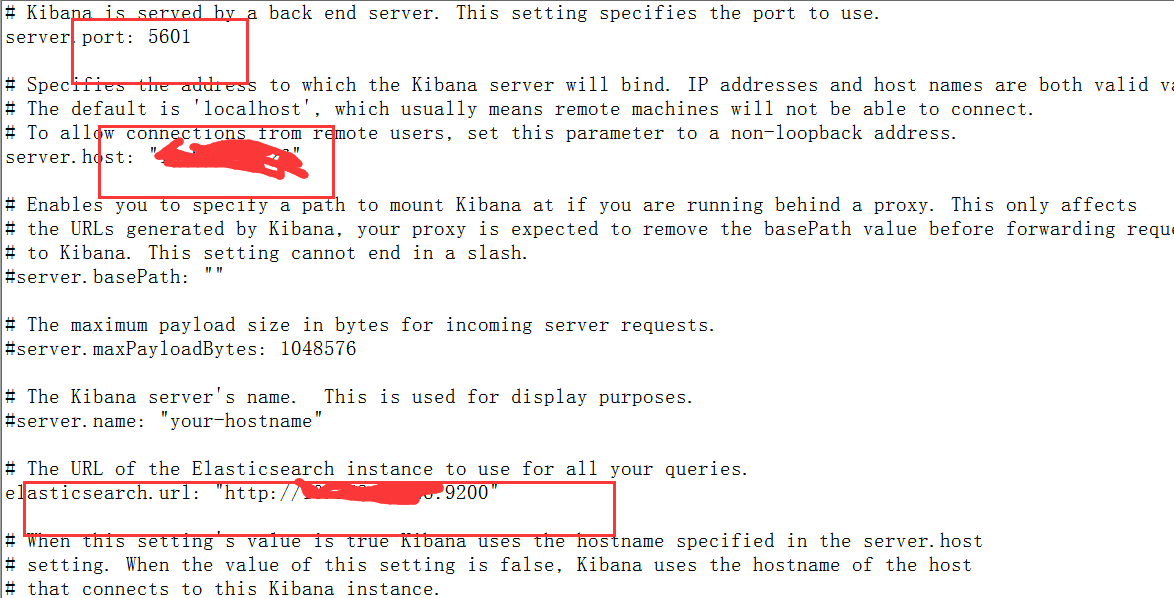
主要配置kibana的端口号和地址,更重要的是elasticsearch的地址和端口号,不然kibana是没法连接上elasticsearch数据库的。
这两项配置完成之后就可以启动了,kibana也是可以访问了。
启动方式就是执行两个文件夹下的/bin/elasticsearch和/bin/kibana文件。是脚本,当然得用sh命令执行。
当然现在页面也是查不到东西的,因为elasticsearch数据库里面根本就没有数据。
然后,我是暂时先不用logstash,因为是测试,所以我直接使用filebeat采集日志,直接发送给elasticsearch。elasticsearch收到数据之后就会自动建立索引、存储了等。
filebeta部署:
我先休息一会儿吧。改天再写。
温馨提示:该篇文章,完全手打,严禁任何形式复制粘贴。可以贴链接。谢谢
ELKF安装使用教程。elasticsearch+logstash+kibana+filebeta。的更多相关文章
- 基于CentOS6.5或Ubuntu14.04下Suricata里搭配安装 ELK (elasticsearch, logstash, kibana)(图文详解)
前期博客 基于CentOS6.5下Suricata(一款高性能的网络IDS.IPS和网络安全监控引擎)的搭建(图文详解)(博主推荐) 基于Ubuntu14.04下Suricata(一款高性能的网络ID ...
- ELK日志系统:Elasticsearch+Logstash+Kibana+Filebeat搭建教程
ELK日志系统:Elasticsearch + Logstash + Kibana 搭建教程 系统架构 安装配置JDK环境 JDK安装(不能安装JRE) JDK下载地址:http://www.orac ...
- Elasticsearch + Logstash + Kibana 搭建教程
# ELK:Elasticsearch + Logstash + Kibana 搭建教程 Shipper:日志收集者.负责监控本地日志文件的变化,及时把日志文件的最新内容收集起来,输出到Redis暂存 ...
- ELK(elasticsearch+logstash+kibana)入门到熟练-从0开始搭建日志分析系统教程
#此文篇幅较长,涵盖了elk从搭建到运行的知识,看此文档,你需要会点linux,还要看得懂点正则表达式,还有一个聪明的大脑,如果你没有漏掉步骤的话,还搭建不起来elk,你来打我. ELK使用elast ...
- 键盘侠Linux干货| ELK(Elasticsearch + Logstash + Kibana) 搭建教程
前言 Elasticsearch + Logstash + Kibana(ELK)是一套开源的日志管理方案,分析网站的访问情况时我们一般会借助 Google / 百度 / CNZZ 等方式嵌入 JS ...
- ELk(Elasticsearch, Logstash, Kibana)的安装配置
目录 ELk(Elasticsearch, Logstash, Kibana)的安装配置 1. Elasticsearch的安装-官网 2. Kibana的安装配置-官网 3. Logstash的安装 ...
- ELK6.0部署:Elasticsearch+Logstash+Kibana搭建分布式日志平台
一.前言 1.ELK简介 ELK是Elasticsearch+Logstash+Kibana的简称 ElasticSearch是一个基于Lucene的分布式全文搜索引擎,提供 RESTful API进 ...
- Elasticsearch+Logstash+Kibana搭建分布式日志平台
一.前言 编译安装 1.ELK简介 下载相关安装包地址:https://www.elastic.co/cn/downloads ELK是Elasticsearch+Logstash+Kibana的简称 ...
- 【转】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
[转自]https://my.oschina.net/itblog/blog/547250 摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticS ...
随机推荐
- LNMP安装目录及配置文件
LNMP安装目录及配置文件位置 LNMP相关软件安装目录Nginx 目录: /usr/local/nginx/MySQL 目录 : /usr/local/mysql/MySQL数据库所在目录:/usr ...
- python的类变量和对象变量[转]
原文章:https://www.cnblogs.com/gtarcoder/p/5005897.html __dict__里存着{"属性名":属性值}. python是一种解释性的 ...
- mysql相关SQL
1.mysql分组获取最新数据 sql> select max(column_name) from table group by column_name having count(*) orde ...
- [Java in NetBeans] Lesson 06. Custom classes
这个课程的参考视频和图片来自youtube. 主要学到的知识点有: Constructors: A special method called when an object of the class ...
- ubuntu 的远程命令行,老是不能支持联想
首先发现没有source命令,非常奇怪,google发现是dash命令的问题. $ls -l `which sh` /bin/sh -> dash $sudo dpkg-reconfigure ...
- Python字典和集合的内部实现
1. 哈希表(Hash tables) 在Python中,字典是通过哈希表实现的.也就是说,字典是一个数组,而数组的索引是经过哈希函数处理后得到的.哈希函数的目的是使键均匀地分布在数组中.由于不同的键 ...
- 20165321 实验一Java开发环境的熟悉-2
- C# Control.Invoke匿名委托
if (txbValue.InvokeRequired) txbValue.Invoke(new MethodInvoker(delegate() { ...
- spark stream001
package stream.scala import java.io.PrintWriter import java.net.ServerSocket class LoggerSimulation ...
- idea上将项目上传到github
1.下载并安装好git,然后配置git的path路径.再配置git的全局用户名和邮箱. 2.注册github账号,如果已经有github账号,则此步骤可以省略. 3.在idea中配置git,配置如下: ...