Python之深浅copy与字符编码
一、深浅copy
1. 首先看赋值运算
l1 = [1,2,3,['barry','alex']]
l2 = l1 l1[0] = 111
print(l1) # [111, 2, 3, ['barry', 'alex']]
print(l2) # [111, 2, 3, ['barry', 'alex']] l1[3][0] = 'wusir'
print(l1) # [111, 2, 3, ['wusir', 'alex']]
print(l2) # [111, 2, 3, ['wusir', 'alex']]
PS: 所以对于赋值运算来说他们指向的是同一个内存地址,所以他们是完全相同的。
2. 浅拷贝copy
l1 = [1,2,3]
l2 = l1.copy()
l1.append(666)
print(l1,l2)#[1, 2, 3, 666] [1, 2, 3]
print(id(l1),id(l2))#1733495294216 1733495317192 l1 = [1,2,3,[22,33]]
l2 = l1.copy()
l1[-1].append(666)
print(l1,l2)#[1, 2, 3, [22, 33, 666]] [1, 2, 3, [22, 33, 666]]
print(id(l1[-1]),id(l2[-1]))#1770640312584 1770640312584
PS: 对于浅copy来说,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
3. 深copy
import copy
l1 = [1,2,3,[22,33]]
l2 = copy.deepcopy(l1)
l1[-1].append(666)
print(l1,l2)#[1, 2, 3, [22, 33, 666]] [1, 2, 3, [22, 33]]
print(id(l1[-1]),id(l2[-1]))#2011177553288 2011177553352
PS: 对于深copy来说,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变。
二、字符编码
1.字符编码的历史与分类
计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字母数字和一些特殊字符与数字的对应关系。最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
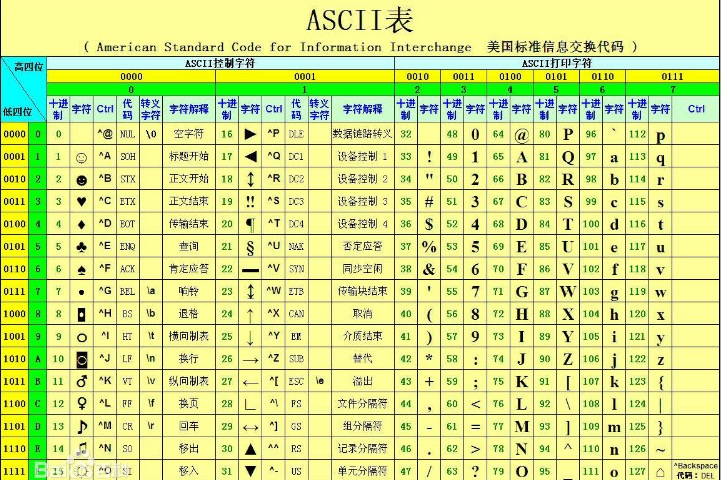
当然我们编程语言都用英文没问题,ASCII够用,但是在处理数据时,不同的国家有不同的语言,小日本会在自己的程序中加入日文,中国人会加入中文。而要表示中文,就要一个字节用>8位2进制代表,位数越多,代表的变化就多,这样,就可以尽可能多的表达出不通的汉字,所以中国人规定了自己的标准gb2312编码,规定了包含中文在内的字符->数字的对应关系。
ascii用1个字节(8位二进制)代表一个字符
unicode常用2个字节(16位二进制)代表一个字符,生僻字需要用4个字节
例:
字母x,用ascii表示是十进制的120,二进制0111 1000
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
字母x,用unicode表示二进制0000 0000 0111 1000,所以unicode兼容ascii,也兼容万国,是世界的标准
这时候乱码问题消失了,所有的文档我们都使用但是新问题出现了,如果我们的文档通篇都是英文,你用unicode会比ascii耗费多一倍的空间,在存储和传输上十分的低效
本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
基于目前的现状,内存中的编码固定就是unicode,我们唯一可变的就是硬盘的上对应的字符编码。
此时你可能会觉得,那如果我们以后开发软时统一都用unicode编码,那么不就都统一了吗,关于统一这一点你的思路是没错的,但我们不可会使用unicode编码来编写程序的文件,因为在通篇都是英文的情况下,耗费的空间几乎会多出一倍,这样在软件读入内存或写入磁盘时,都会徒增IO次数,从而降低程序的执行效率。因而我们以后在编写程序的文件时应该统一使用一个更为精准的字符编码utf-8(用1Bytes存英文,3Bytes存中文),再次强调,内存中的编码固定使用unicode。
1、在存入磁盘时,需要将unicode转成一种更为精准的格式,utf-8:全称Unicode Transformation Format,将数据量控制到最精简
2、在读入内存时,需要将utf-8转成unicode
所以我们需要明确:内存中用unicode是为了兼容万国软件,即便是硬盘中有各国编码编写的软件,unicode也有相对应的映射关系,但在现在的开发中,程序员普遍使用utf-8编码了,估计在将来的某一天等所有老的软件都淘汰掉了情况下,就可以变成:内存utf-8<->硬盘utf-8的形式了。
2. 编码:
ascii:字母,数字,特殊字符。
万国码:unicode :
A: 0000 0010 0000 0010 两个字节,表示一个字符。
中: 0000 0010 0000 0010 两个字节,表示一个字符。
升级:
A: 0000 0010 0000 0010 0000 0010 0000 0010 四个字节,表示一个字符。
中: 0000 0010 0000 0010 0000 0010 0000 0010 四个字节,表示一个字符。
占空间,浪费资源。
utf-8:最少用一个字节,表示一个字符.
A: 0000 0010
欧洲:0000 00100000 0010
中文:0000 00100000 00100000 0010
gbk国标。
A: 0000 0010
中: 0000 0010 0000 0010
python3x:
1,不同编码之间的二进制是不能互相识别的。
2,python3x str内部编码方式(内存)为unicode,但是,对于文件的存储,和传输不能用unicode
bytes类型:内部编码方式(内存)为非unicode
#对于英文
str:
s = 'laonanhai' 表现形式
#内部编码方式 unicode
bytes:
s1 = b'laonanhai' 表现形式
#内部编码方式 非unicode (utf-8,gbk,gb2312....)
#对于中文:
str:
s = '中国'
print(s,type(s))
bytes:
s1 = b'\xe4\xb8\xad\xe5\x9b\xbd'
print(s1,type(s1))
转化:
s = 'laonanhai'
s2 = s.encode('utf-8') #str -->bytes encode 编码
s3 = s.encode('gbk')
print(s2,s3)#b'laonanhai' b'laonanhai'
s = '中国'
s2 = s.encode('utf-8') #str -->bytes encode 编码
# s3 = s.encode('gbk')
# print(s2)#b'\xe4\xb8\xad\xe5\x9b\xbd'
# print(s3)#b'\xd6\xd0\xb9\xfa'
ss = s2.decode('utf-8') # bytes ---> str decode 解码
print(ss)#中国
!!!总结非常重要的两点!!!
#1、保证不乱吗的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码 #2、在内存中写的所有字符,一视同仁,都是unicode编码,比如我们打开编辑器,输入一个“你”,我们并不能说“你”就是一个汉字,
此时它仅仅只是一个符号,该符号可能很多国家都在使用,根据我们使用的输入法不同这个字的样式可能也不太一样。
只有在我们往硬盘保存或者基于网络传输时,才能确定”你“到底是一个汉字,还是一个日本字,这就是unicode转换成其他编码格式的过程了
unicode----->encode-------->utf-8
utf-8-------->decode---------->unicode

Python之深浅copy与字符编码的更多相关文章
- Python : 熟悉又陌生的字符编码(转自Python 开发者)
Python : 熟悉又陌生的字符编码 字符编码是计算机编程中不可回避的问题,不管你用 Python2 还是 Python3,亦或是 C++, Java 等,我都觉得非常有必要厘清计算机中的字符编码概 ...
- python全栈开发-Day7 字符编码总结
python全栈开发-Day7 字符编码总结 一.字符编码总结 1.什么是字符编码 人类的字符--------->翻译--------->数字 翻译的过程遵循的标准即字符编码(就是一个字符 ...
- 【转】Python中的字符串与字符编码
[转]Python中的字符串与字符编码 本节内容: 前言 相关概念 Python中的默认编码 Python2与Python3中对字符串的支持 字符编码转换 一.前言 Python中的字符编码是个老生常 ...
- Python编程笔记二进制、字符编码、数据类型
Python编程笔记二进制.字符编码.数据类型 一.二进制 bin() 在python中可以用bin()内置函数获取一个十进制的数的二进制 计算机容量单位 8bit = 1 bytes 字节,最小的存 ...
- Python的深浅copy详解
Python的深浅copy详解 目录 Python的深浅copy详解 一.浅copy的原理 1.1 浅copy的定义 1.2 浅copy的方法 二.深copy的原理 2.1 深copy的定义 2.2 ...
- Python中的字符串与字符编码
本节内容: 前言 相关概念 Python中的默认编码 Python2与Python3中对字符串的支持 字符编码转换 一.前言 Python中的字符编码是个老生常谈的话题,同行们都写过很多这方面的文章. ...
- python学习第四天 --字符编码 与格式化及其字符串切片
字符编码 与格式化 第三天已经知道了字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采 ...
- python基础(三)----字符编码以及文件处理
字符编码与文件处理 一.字符编码 由字符翻译成二进制数字的过程 字符--------(翻译过程)------->数字 这个过程实际就是一个字符如何对应一个特定数字的标准,这个标准称之 ...
- python全栈开发-Day6 字符编码
python全栈开发-Day6 字符编码 一 .了解字符编码的知识储备 一 .计算机基础知识 二 .文本编辑器存取文件的原理(nodepad++,pycharm,word) #1.打开编辑器就打开了启 ...
随机推荐
- (转)Shiro学习
(二期)13.权限框架shiro讲解 [课程13]自定义Realm.xmind36.8KB [课程13]用户授权流程.xmind0.2MB [课程13]shiro简介.xmind0.3MB [课程13 ...
- git删除远程分支文件,不改变本地文件
git提交项目时候踩的Git的坑 特别 由于准备春招,所以希望各位看客方便的话,能去github上面帮我Star一下项目 https://github.com/Draymonders/Campus-S ...
- hihoCoder week10 后序遍历
题目链接 https://hihocoder.com/contest/hiho10/problem/1 给出先序 中序 求 后序 #include <bits/stdc++.h> usi ...
- P5091 【模板】欧拉定理
思路 欧拉定理 当a与m互质时 \[ a^ {\phi (m)} \equiv 1 \ \ (mod\ m) \] 扩展欧拉定理 当a与m不互质且\(b\ge \phi(m)\)时, \[ a^b \ ...
- Multi-attention Network for One Shot Learning
Multi-attention Network for One Shot Learning 2018-05-15 22:35:50 本文的贡献点在于: 1. 表明类别标签信息对 one shot l ...
- 用maven和spring搭建ActiveMQ环境
前面搭建过了简单的环境,这次用稍微实际一点的maven+spring+activemq来进行搭建 准备:win7,eclipse,jdk1.8,tomcat8,maven3.5.2,activemq5 ...
- 实现一个键对应多个值的字典(multidict)
一个字典就是一个键对应一个单值的映射.如果你想要一个键映射多个值,那么你就需要将这多个值放到另外的容器中, 比如列表或者集合里面.比如,你可以像下面这样构造这样的字典: d = { , , ], , ...
- tkinter 打包成exe可执行文件
1.安装pyinstaller pip install pyinstaller 2.打包 打开cmd,切换到需要打包的文件(demo.py)目录.执行 pyinstaller -F -w demo.p ...
- 《剑指offer》第四十四题(数字序列中某一位的数字)
// 面试题44:数字序列中某一位的数字 // 题目:数字以0123456789101112131415…的格式序列化到一个字符序列中.在这 // 个序列中,第5位(从0开始计数)是5,第13位是1, ...
- Android集成人脸识别demo分享
本应用来源于虹软人工智能开放平台,人脸识别技术工程如何使用? 1.下载代码 git clone https://github.com/andyxm/ArcFaceDemo.git 2.下载虹软人脸识别 ...