Build Telemetry for Distributed Services之OpenTracing实践
官网:https://opentracing.io/docs/best-practices/
Best Practices
This page aims to illustrate common use cases that developers who instrument their applications and libraries with OpenTracing API need to deal with.
Stepping Back: Who is OpenTracing for?
OpenTracing is a thin standardization layer that sits between application/library code and various systems that consume tracing and causality data. Here is a diagram:
+-------------+ +---------+ +----------+ +------------+
| Application | | Library | | OSS | | RPC/IPC |
| Code | | Code | | Services | | Frameworks |
+-------------+ +---------+ +----------+ +------------+
| | | |
| | | |
v v v v
+-----------------------------------------------------+
| · · · · · · · · · · OpenTracing · · · · · · · · · · |
+-----------------------------------------------------+
| | | |
| | | |
v v v v
+-----------+ +-------------+ +-------------+ +-----------+
| Tracing | | Logging | | Metrics | | Tracing |
| System A | | Framework B | | Framework C | | System D |
+-----------+ +-------------+ +-------------+ +-----------+
Use cases
The table below lists some use cases for OpenTracing and describes them in detail:
| Use case | Description |
|---|---|
| Application Code | Developers writing application code can use OpenTracing to describe causality, demarcate control flow, and add fine-grained logging information along the way. |
| Library Code | Libraries that take intermediate control of requests can integrate with OpenTracing for similar reasons. For instance, a web middleware library can use OpenTracing to create spans for request handling, or an ORM library can use OpenTracing to describe higher-level ORM semantics and measure execution for specific SQL queries. |
| OSS Services | Beyond embedded libraries, entire OSS services may adopt OpenTracing to integrate with distributed traces initiating in – or propagating to – other processes in a larger distributed system. For instance, an HTTP load balancer may use OpenTracing to decorate requests, or a distributed key:value store may use OpenTracing to explain the performance of reads and writes. |
| RPC/IPC Frameworks | Any subsystem tasked with crossing process boundaries may use OpenTracing to standardize the format of tracing state as it injects into and extracts from various wire formats and protocols. |
All of the above should be able to use OpenTracing to describe and propagate distributed traces without knowledge of the underlying OpenTracing implementation.
OpenTracing priorities
Since there are many orders of magnitude more programmers and applications above the OpenTracing layer (rather than below it), the APIs and use cases prioritize ease-of-use in that direction. While there are certainly ample opportunities for helper libraries and other abstractions that save time and effort for OpenTracing implementors, the use cases in this document are restricted to callers (rather than callees) of OpenTracing APIs.
Motivating Use Cases
The sections below discuss some commonly encountered use cases in the OpenTracing ecosystem.
Tracing a Function
def top_level_function():
span1 = tracer.start_span('top_level_function')
try:
. . . # business logic
finally:
span1.finish()As a follow-up, suppose that as part of the business logic above we call another function2 that we also want to trace. In order to attach that function to the ongoing trace, we need a way to access span1. We discuss how it can be done later, for now let’s assume we have a helper function get_current_span for that:
def function2():
span2 = get_current_span().start_child('function2') \
if get_current_span() else None
try:
. . . # business logic
finally:
if span2:
span2.finish()We assume that, for whatever reason, the developer does not want to start a new trace in this function if one hasn’t been started by the caller already, so we account for get_current_span potentially returning None.
These two examples are intentionally naive. Usually developers will not want to pollute their business functions directly with tracing code, but use other means like a function decorator in Python:
@traced_function
def top_level_function():
... # business logicTracing Server Endpoints
Tracing Server Endpoints
When a server wants to trace execution of a request, it generally needs to go through these steps:
- Attempt to extract a SpanContext that’s been propagated alongside the incoming request (in case the trace has already been started by the client), or start a new trace if no such propagated SpanContext could be found.
- Store the newly created Span in some request context that is propagated throughout the application, either by application code, or by the RPC framework.
- Finally, close the Span using
span.finish()when the server has finished processing the request.
Extracting a SpanContext from an Incoming Request
Let’s assume that we have an HTTP server, and the SpanContext is propagated from the client via HTTP headers, accessible via request.headers:
extracted_context = tracer.extract(
format=opentracing.HTTP_HEADER_FORMAT,
carrier=request.headers
)Here we use the headers map as the carrier. The Tracer object knows which headers it needs to read in order to reconstruct the tracer state and any Baggage.
Continuing or Starting a Trace from an Incoming Request
The extracted_context object above can be None if the Tracer did not find relevant headers in the incoming request: presumably because the client did not send them. In this case the server needs to start a brand new trace.
extracted_context = tracer.extract(
format=opentracing.HTTP_HEADER_FORMAT,
carrier=request.headers
)
if extracted_context is None:
span = tracer.start_span(operation_name=operation)
else:
span = tracer.start_span(operation_name=operation, child_of=extracted_context)
span.set_tag('http.method', request.method)
span.set_tag('http.url', request.full_url)The set_tag calls are examples of recording additional information in the Span about the request.
The set_tag calls are examples of recording additional information in the Span about the request.
The operation above refers to the name the server wants to give to the Span. For example, if the HTTP request was a POST against /save_user/123, the operation name can be set to post:/save_user/. The OpenTracing API does not dictate how applications name the spans.
In-Process Request Context Propagation
Request context propagation refers to application’s ability to associate a certain context with the incoming request such that this context is accessible in all other layers of the application within the same process. It can be used to provide application layers with access to request-specific values such as the identity of the end user, authorization tokens, and the request’s deadline. It can also be used for transporting the current tracing Span.
Implementation of request context propagation is outside the scope of the OpenTracing API, but it is worth mentioning them here to better understand the following sections. There are two commonly used techniques of context propagation:
Implicit Propagation
In implicit propagation techniques the context is stored in platform-specific storage that allows it to be retrieved from any place in the application. Often used by RPC frameworks by utilizing such mechanisms as thread-local or continuation-local storage, or even global variables (in case of single-threaded processes).
The downside of this approach is that it almost always has a performance penalty, and in platforms like Go that do not support thread-local storage implicit propagation is nearly impossible to implement.
Explicit Propagation
In explicit propagation techniques the application code is structured to pass around a certain context object:
func HandleHttp(w http.ResponseWriter, req *http.Request) {
ctx := context.Background()
...
BusinessFunction1(ctx, arg1, ...)
}
func BusinessFunction1(ctx context.Context, arg1...) {
...
BusinessFunction2(ctx, arg1, ...)
}
func BusinessFunction2(ctx context.Context, arg1...) {
parentSpan := opentracing.SpanFromContext(ctx)
childSpan := opentracing.StartSpan(
"...", opentracing.ChildOf(parentSpan.Context()), ...)
...
}The downside of explicit context propagation is that it leaks what could be considered an infrastructure concern into the application code. This Go blog post provides an in-depth overview and justification of this approach.
Tracing Client Calls
When an application acts as an RPC client, it is expected to start a new tracing Span before making an outgoing request, and propagate the new Span along with that request. The following example shows how it can be done for an HTTP request.
def traced_request(request, operation, http_client):
# retrieve current span from propagated request context
parent_span = get_current_span()
# start a new span to represent the RPC
span = tracer.start_span(
operation_name=operation,
child_of=parent_span.context,
tags={'http.url': request.full_url}
)
# propagate the Span via HTTP request headers
tracer.inject(
span.context,
format=opentracing.HTTP_HEADER_FORMAT,
carrier=request.headers)
# define a callback where we can finish the span
def on_done(future):
if future.exception():
span.log(event='rpc exception', payload=exception)
span.set_tag('http.status_code', future.result().status_code)
span.finish()
try:
future = http_client.execute(request)
future.add_done_callback(on_done)
return future
except Exception e:
span.log(event='general exception', payload=e)
span.finish()
raise- The
get_current_span()function is not a part of the OpenTracing API. It is meant to represent some util method of retrieving the current Span from the current request context propagated implicitly (as is often the case in Python). - We assume the HTTP client is asynchronous, so it returns a Future, and we need to add an on-completion callback to be able to finish the current child Span.
- If the HTTP client returns a future with exception, we log the exception to the Span with
logmethod. - Because the HTTP client may throw an exception even before returning a Future, we use a try/catch block to finish the Span in all circumstances, to ensure it is reported and avoid leaking resources.
Using Baggage / Distributed Context Propagation
The client and server examples above propagated the Span/Trace over the wire, including any Baggage. The client may use the Baggage to pass additional data to the server and any other downstream server it might call.
# client side
span.context.set_baggage_item('auth-token', '.....')
# server side (one or more levels down from the client)
token = span.context.get_baggage_item('auth-token')Logging Events
We have already used log in the client Span use case. Events can be logged without a payload, and not just where the Span is being created / finished. For example, the application may record a cache miss event in the middle of execution, as long as it can get access to the current Span from the request context:
span = get_current_span()
span.log(event='cache-miss')The tracer automatically records a timestamp of the event, in contrast with tags that apply to the entire Span. It is also possible to associate an externally provided timestamp with the event, e.g. see Log (Go).
Recording Spans With External Timestamps
There are scenarios when it is impractical to incorporate an OpenTracing compatible tracer into a service, for various reasons. For example, a user may have a log file of what’s essentially Span data coming from a black-box process (e.g. HAProxy). In order to get the data into an OpenTracing-compatible system, the API needs a way to record spans with externally defined timestamps.
explicit_span = tracer.start_span(
operation_name=external_format.operation,
start_time=external_format.start,
tags=external_format.tags
)
explicit_span.finish(
finish_time=external_format.finish,
bulk_logs=map(..., external_format.logs)
)Setting Sampling Priority Before the Trace Starts
Most distributed tracing systems apply sampling to reduce the amount of trace data that needs to be recorded and processed. Sometimes developers want to have a way to ensure that a particular trace is going to be recorded (sampled) by the tracing system, e.g. by including a special parameter in the HTTP request, like debug=true. The OpenTracing API standardizes around some useful tags, and one of them is the so-called “sampling priority”: exact semantics are implementation-specific, but any value greater than zero (the default) indicates a trace of elevated importance. In order to pass this attribute to tracing systems that rely on pre-trace sampling, the following approach can be used:
if request.get('debug'):
span = tracer.start_span(
operation_name=operation,
tags={tags.SAMPLING_PRIORITY: 1}
)Tracing Message Bus Scenarios
There are two message bus styles that should be handled: Message Queues and Publish/Subscribe (Topics).
rom a tracing perspective, the message bus style is not important, only that the span context associated with the producer is propagated to the zero or more consumers of the message. It is then the responsibility of the consumer(s) to create a span to encapsulate processing of the consumed message and establish a FollowsFrom reference to the propagated span context.
As with the RPC client example, a messaging producer is expected to start a new tracing Span before sending a message, and propagate the new Span’s SpanContext along with that message. The Span will then be finished after the message has been enqueued/published on the message bus. The following example shows how it can be done.
def traced_send(message, operation):
# retrieve current span from propagated message context
parent_span = get_current_span()
# start a new span to represent the message producer
span = tracer.start_span(
operation_name=operation,
child_of=parent_span.context,
tags={'message.destination': message.destination}
)
# propagate the Span via message headers
tracer.inject(
span.context,
format=opentracing.TEXT_MAP_FORMAT,
carrier=message.headers)
with span:
messaging_client.send(message)
except Exception e:
...
raise- The
get_current_span()function is not a part of the OpenTracing API. It is meant to represent some util method of retrieving the current Span from the current request context propagated implicitly (as is often the case in Python).
The following is an example of a message consumer checking whether an incoming message contains a span context. If it does, this will be used to establish a relationship with the message producer’s Span.
extracted_context = tracer.extract(
format=opentracing.TEXT_MAP_FORMAT,
carrier=message.headers
)
span = tracer.start_span(operation_name=operation, references=follows_from(extracted_context))
span.set_tag('message.destination', message.destination)Synchronous request-response over queues
Although not necessarily used a great deal, some messaging platforms/standards (e.g. JMS) support the ability to provide a ReplyTo destination in the header of a message. When the consumer receives the message it returns a result message to the nominated destination.
This pattern could be used to simulate a synchronous request/response, in which case the relationship type between the consumer and producer spans should technically be Child Of.
However this pattern could also be used for delegation to indicate a third party that should be informed of the result. In which case it would be treated as two separate message exchanges with Follows From relationship types linking each stage.
As it would be difficult to distinguish between these two scenarios, and the use of message oriented middleware for synchronous request/response pattern should be discouraged, it is recommended that the request/response scenario be ignored from a tracing perspective.
Instrumenting frameworks
Trace all the things!
Audience
The audience for this guide are developers interested in adding OpenTracing instrumentation to a web, RPC, or other framework that makes requests and/or receives responses. This instrumentation makes it easy for developers using the framework to incorporate end-to-end (distributed) tracing.
Distributed tracing provides insight about individual requests as they propagate throughout a system. OpenTracing is an open-source standard API for consistent distributed tracing of requests across processes, from web and mobile client platforms to the storage systems and custom backends at the bottom of an application stack. Once OpenTracing integrates across the entire application stack, it’s easy to trace requests across the distributed system. This allows developers and operators much-needed visibility to optimize and stabilize production services.
Before you begin, check here to make sure that there’s a working OpenTracing API for your platform.
Overview
At a high level, here is what you need for an OpenTracing integration:
Server framework requirements:
- Filters, interceptors, middleware, or another way to process inbound requests
- Active span storage: either a request context or a request-to-span map
- Settings or another way to configure tracer configuration
Client framework requirements:
- Filters, interceptors, or another way to process outgoing requests
- Settings or another way to configure tracing configuration
Pro-tips:
Before we dive into implementation, here are a few important concepts and features that should be made available to framework users.
Operation Names
You’ll notice an operation_name variable floating around this tutorial. Every span is created with an operation name that should follow the guidelines outlined here. You should have a default operation name for each span, but also provide a way for the user to specify custom operation names.
Examples of default operation names:
- The name of the request handler method
- The name of a web resource
- The concatenated names of an RPC service and method
Specifying Which Requests to Trace
Some users may want to trace every request while other may want only specific requests to be traced. You should ideally allow users to set up tracing for either of these scenarios. For example, you could provide @Trace annotations/decorators, in which only annotated handler functions have tracing enabled. You can also provide settings for the user to specify whether they’re using these annotations, versus whether they want all requests to be traced automatically.
Tracing Request Properties
Users may also want to track information about the requests without having to manually access the span and set the tags themselves. It’s helpful to provide a way for users to specify properties of the request they want to trace, and then automatically trace these features. Ideally, this would be similar to the Span Decorator function in gRPC:
// SpanDecorator binds a function that decorates gRPC Spans.
func SpanDecorator(decorator SpanDecoratorFunc) Option {
return func(o *options) {
o.decorator = decorator
}
}Another approach could have a setting TRACED_REQUEST_ATTRIBUTES that the user can pass a list of attributes (such as URL, METHOD, or HEADERS), and then in your tracing filters, you would include the following:
for attr in settings.TRACED_REQUEST_ATTRIBUTES:
if hasattr(request, attr):
payload = str(getattr(request, attr))
span.set_tag(attr, payload)Server-side Tracing
The goals of server-side tracing are to trace the lifetime of a request to a server and connect this instrumentation to any pre-existing trace in the client. You can do this by creating spans when the server receives the request and ending the span when the server finishes processing the request. The workflow for tracing a server request is as follows:
- Server Receives Request
- Extract the current trace state from the inter-process transport (HTTP, etc)
- Start the span
- Store the current trace state
- Server Finishes Processing the Request / Sends Response
- Finish the span
Because this workflow depends on request processing, you’ll need to know how to change the framework’s requests and responses handling–whether this is through filters, middleware, a configurable stack, or some other mechanism.
Extract the Current Trace State
In order to trace across process boundaries in distributed systems, services need to be able to continue the trace injected by the client that sent each request. OpenTracing allows this to happen by providing inject and extract methods that encode a span’s context into a carrier. (The specifics of the encoding is left to the implementor, so you won’t have to worry about that.)
If there was an active request on the client side, the span context will already be injected into the the request. Your job is to then extract that span context using the io.opentracing.Tracer.extract method. The carrier that you’ll extract from depends on which type of service you’re using; web servers, for example, use HTTP headers as the carrier for HTTP requests (as shown below):
Python
span_ctx = tracer.extract(opentracing.Format.HTTP_HEADERS, request.headers)Java
import io.opentracing.propagation.Format;
import io.opentracing.propagation.TextMap;
Map<String, String> headers = request.getHeaders();
SpanContext parentSpan = tracer.getTracer().extract(Format.Builtin.HTTP_HEADERS,
new TextMapExtractAdapter(headers));OpenTracing can throw errors when an extract fails due to no span being present, so make sure to catch the errors that signify there was no injected span and not crash your server. This often just means that the request is coming from a third-party (or untraced) client, and the server should start a new trace.
Start the span
Once you receive a request and extract any existing span context, you should immediately start a span representing the lifetime of the request to the server. If there is an extracted span context present, then the new server span should be created with a ChildOf reference to the extracted span, signifying the relationship between the client request and server response. If there was no injected span, you’ll just start a new span with no references.
Python
if(extracted_span_ctx):
span = tracer.start_span(operation_name=operation_name,
child_of=extracted_span_ctx)
else:
span = tracer.start_span(operation_name=operation_name)Java
if(parentSpan == null){
span = tracer.buildSpan(operationName).start();
} else {
span = tracer.buildSpan(operationName).asChildOf(parentSpan).start();
}Store the current span context
- Use of request context: If your framework has a request context that can store arbitrary values, then you can store the current span in the request context for the duration of the processing of a request. This works particularly well if your framework has filters that can alter how requests are processed. For example, if you have a request context called ctx, you could apply a filter similar to this:
def filter(request):
span = # extract / start span from request
with (ctx.active_span = span):
process_request(request)
span.finish()Now, at any point during the processing of the request, if the user accesses
ctx.active_span, they’ll receive the span for that request. Note that once the request is processed,ctx.active_spanshould retain whatever value it had before the request was processed.Map Requests to their associated span: You may not have a request context available, or you may use filters that have separate methods for preprocessing and postprocessing requests. If this is the case, you can instead create a mapping of requests to the span that represents its lifetime. One way that you could do this is to create a framework-specific tracer wrapper that stores this mapping. For example:
class MyFrameworkTracer:
def __init__(opentracing_tracer):
self.internal_tracer = opentracing_tracer
self.active_spans = {}
def add_span(request, span):
self.active_spans[request] = span
def get_span(request):
return self.active_spans[request]
def finish_span(request):
span = self.active_spans[request]
span.finish()
del self.active_spans[request]If your server can handle multiple requests at once, then make sure that your implementation of the span map is threadsafe.
The filters would then be applied along these lines:
def process_request(request):
span = # extract / start span from request
tracer.add_span(request, span)
def process_response(request, response):
tracer.finish_span(request)- Note that the user here can call
tracer.get_span(request)during response processing to access the current span. Make sure that the request (or whatever unique request identifier you’re using to map to spans) is availabe to the user.
Client-side tracing
Enabling client-side tracing is applicable to frameworks that have a client component that is able to initiate a request. The goal is to inject a span into the header of the request that can then be passed to the server-side portion of the framework. Just like with server-side tracing, you’ll need to know how to alter how your clients send requests and receive responses. When done correctly, the trace of a request is visible end-to-end.
Workflow for client-side tracing:
- Prepare request
- Load the current trace state
- Start a span
- Inject the span into the request
- Send request
- Receive response
- Finish the span
Load the Current Trace State / Start a Span
Just like on the server side, we have to recognize whether we need to start a new trace or connect with an already-active trace. For instance, most microservices act as both client and server within the larger distributed system, and their outbound client requests should be associated with whatever request the service was handling at the time. If there’s an active trace, you’ll start a span for the client request with the active span as its parent. Otherwise, the span you start will have no parent.
How you recognize whether there is an active trace depends on how you’re storing active spans. If you’re using a request context, then you can do something like this:
if hasattr(ctx, active_span):
parent_span = getattr(ctx, active_span)
span = tracer.start_span(operation_name=operation_name,
child_of=parent_span)
else:
span = tracer.start_span(operation_name=operation_name)If you’re using the request-to-span mapping technique, your approach might look like:
parent_span = tracer.get_span(request)
span = tracer.start_span(
operation_name=operation_name,
child_of=parent_span)You can see examples of this approach in gRPC and JDBI.
nject the Span
This is where you pass the trace information into the client’s request so that the server you send it to can continue the trace. If you’re sending an HTTP request, then you’ll just use the HTTP headers as your carrier.
span = # start span from the current trace state
tracer.inject(span, opentracing.Format.HTTP_HEADERS, request.headers)Finish the Span
When you receive a response, you want to end the span to signify that the client request is finished. Just like on the server side, how you do this depends on how your client request/response processing happens. If your filter wraps the request directly you can just do this:
def filter(request, response):
span = # start span from the current trace state
tracer.inject(span, opentracing.Format.HTTP_HEADERS, request.headers)
response = send_request(request)
if response.error:
span.set_tag(opentracing., true)
span.finish()Otherwise, if you have ways to process the request and response separately, you might extend your tracer to include a mapping of client requests to spans, and your implementation would look more like this:
ef process_request(request):
span = # start span from the current trace state
tracer.inject(span. opentracing.Format.HTTP_HEADERS, request.headers)
tracer.add_client_span(request, span)
def process_response(request, response):
tracer.finish_client_span(request)Closing Remarks
If you’d like to highlight your project as OpenTracing-compatible, feel free to use our GitHub badge and link it to the OpenTracing website.
Instrumenting your application
Before getting onto recommendations on how to instrument your large-scale system with OpenTracing, be sure to read the Specification overview.
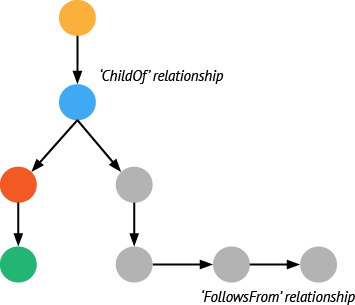
- Spans are logical units of work in a distributed system, and by definition they all have a name, a start time, and a duration. In a trace, Spans are associated with the distributed system component that generated them.
- Relationships are the connections between Spans. A Span may reference zero or more other Spans that are causally related. These connections between Spans help describe the semantics of the running system, as well as the critical path for latency-sensitive (distributed) transactions.
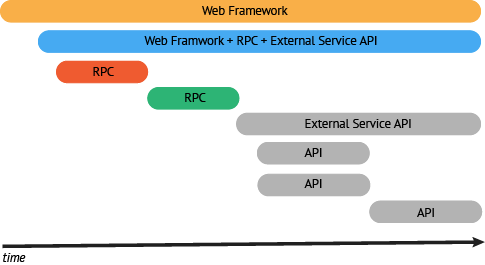
Your desired end state is to emit Spans for all or your code components along with the relationships between those Spans. When starting to build out your infrastructure with distributed tracing, the best practice is to start with service frameworks (e.g., an RPC layer) or other components known to have broad interaction with multiple execution paths.
By using a service framework that is instrumented with OpenTracing (gRPC, etc.) you can get a head start on this effort. However, if you are working with a non-instrumented framework you can get some assistance with this part by reading the IPC/RPC Framework Guide.
Focus on Areas of Value
As mentioned above, start with your RPC layers and your web framework to provide a good foundation for your instrumentation. Both of these will likely have a large coverage area and touch a significant number of transaction paths.
Next you should look for areas of your infrastructure on the path of a transaction not covered by your service framework. Instrument enough of these code components to create a trace along the critical path of a high value transaction.
By prioritizing based on the Spans in your transaction on the critical path and consume the greatest time, there is the greatest opportunity for measurable optimization. For example, adding detailed instrumentation to a span making up 1% of the total transaction time is unlikely to provide meaningful gains in your understanding of end-to-end latency.
Crawl, Walk, Run
As you are implementing tracing across your system, the key to building value is to balance completing some well-articulated high value traces with the notion of total code coverage. The greatest value is going to come from building just enough coverage to generate end-to-end traces for some number of high-value transactions. It is important to visualize your instrumentation as early as possible. This will help you identify areas that need further visibility.
Once you have an end-to-end trace, you can evaluate and prioritize areas where greater visibility will be worth the level of effort for the additional instrumentation. As you start to dig deeper, look for the units of work that can be reused. An example of this would be instrumenting a library that is used across multiple services.
This approach often leads to broad coverage (RPC, web frameworks, etc) while also adding high-value spans to business-critical transactions. Even if the instrumentation for specific spans involve one-off work, patterns will emerge that will assist in optimizing prioritization of future work.
Conceptual Example
Here is an example of this progression to make the approach more tangible:
For this example we want to trace a request initiated by a mobile client and propagating through a small constellation of backend services.
- First, we must identify the overall flow of the transaction. In our example, the transactions look like this:
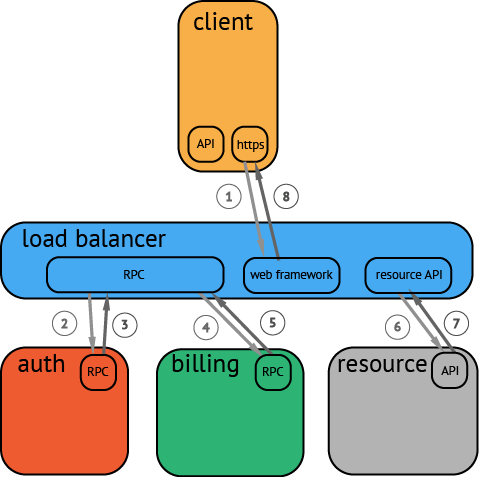
Start with a user action that creates a web request from a mobile client (HTTP) → web tier (RPC) → auth service (RPC) → billing service (RPC) → resource request (API) → response to web tier (API) → response to client (HTTP)
Now that we have high-level conceptual understanding of a transaction flow we can look to instrument a few of the broader protocols and frameworks. The best choice will be to start with the RPC service since this will be an easy way to gather spans for everything happening behind the web service (or at least everything leveraging the RPC service directly).
The next component that makes sense to instrument is the web framework. By adding the web framework we are able to then have an end-to-end trace. It may be rough, but at least the full workflow can be captured by our tracing system.
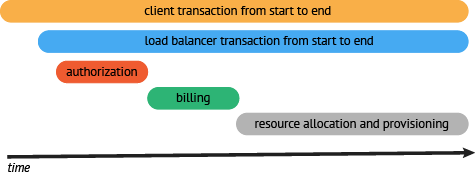
- At this point we want to take a look at the trace and evaluate where our efforts will provide the greatest value. In our example we can see the area that has the greatest delay for this request is the time it takes for resources to be allocated. This is likely a good place to start adding more granular visibility into the allocation process and instrument the components involved. Once we instrument the resource API we see that resource request can be broken down into:
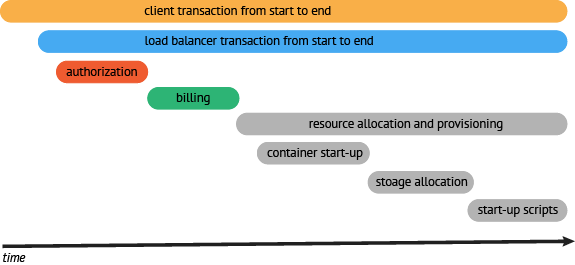
resource request (API) → container startup (API) → storage allocation (API) → startup scripts (API) → resource ready response (API)
- Once we have instrumented the resource allocation process components, we can see that the bulk of the time is during resource provisioning. The next step would be to go a bit deeper and look to see if there were optimizations that could be done in this process. Maybe we could provision resources in parallel rather than in serial.
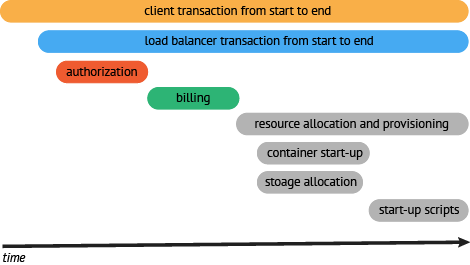
Now that there is visibility and an established baseline for an end-to-end workflow, we can articulate a realistic external SLO for that request. In addition, articulating SLO’s for internal services can also become part of the conversation about uptime and error budgets.
The next iteration would be to go back to the top level of the trace and look for other large spans that appear to lack visibility and apply more granular instrumentation. If instead the visibility is sufficient, the next step would be to move on to another transaction.
Rinse and repeat.
Standards and conventions
Background
OpenTracing defines an API through which application instrumentation can log data to a pluggable tracer. In general, there is no guarantee made by OpenTracing about the way that data will be handled by an underlying tracer. So what type of data should be provided to the APIs in order to best ensure compatibility across tracer implementations?
A high-level understanding between the instrumentor and tracer developers adds great value: if certain known tag key/values are used for common application scenarios, tracers can choose to pay special attention to them. The same is true of logged events, and span structure in general.
As an example, consider the common case of a HTTP-based application server. The URL of an incoming request that the application is handling is often useful for diagnostics, as well as the HTTP verb and the resultant status code. An instrumentor could choose to report the URL in a tag named URL, or perhaps named http.url: either would be valid from the pure API perspective. But if the Tracer wishes to add intelligence, such as indexing on the URL value or sampling proactively for requests to a particular endpoint, it must know where to look for relevant data. In short, when tag names and other instrumentor-provided values are used consistently, the tracers on the other side of the API can employ more intelligence.
The guidelines provided here describe a common ground on which instrumentors and tracer authors can build beyond pure data collection. Adherence to the guidelines is optional but highly recommended for instrumentors.
Semantic conventions
The complete list of semantic conventions for instrumentation can be found in the Semantic Conventions specification.
If you see an opportunity for additional standardization, please file an issue against the specification repository or raise the point on OpenTracing’s public Gitter channel.
OpenTracing Language Support
OpenTracing APIs are available for the following platforms:
Please refer to the README files in the respective per-platform repositories for usage examples.
Community contributions are welcome for other languages at any time.
Supported tracers
CNCF Jaeger
Jaeger \ˈyā-gər\ is a distributed tracing system, originally open sourced by Uber Technologies. It provides distributed context propagation, distributed transaction monitoring, root cause analysis, service dependency analysis, and performance / latency optimization. Built with OpenTracing support from inception, Jaeger includes OpenTracing client libraries in several languages, including Java, Go, Python, Node.js, C++ and C#. It is a Cloud Native Computing Foundation member project.
LightStep
LightStep operates a SaaS solution with OpenTracing-native tracers in production environments. There are OpenTracing-compatible LightStep Tracers available for Go, Python, Javascript, Objective-C, Java, PHP, Ruby, and C++.
Instana
Instana provides an APM solution supporting OpenTracing in Crystal, Go, Java, Node.js, Python and Ruby. The Instana OpenTracing tracers are interoperable with the other Instana out of the box tracers for .Net, Crystal, Java, Scala, NodeJs, PHP, Python and Ruby.
Apache SkyWalking
Apache SkyWalking is an APM (application performance monitor) tool for distributed systems, specially designed for microservices, cloud native and container-based (Docker, K8s, Mesos) architectures. Underlying technology is a distributed tracing system. The SkyWalking javaagent is interoperable with OpenTracing-java APIs.
inspectIT
inspectIT aims to be an End-to-End APM solution for Java with support for OpenTracing. The instrumentation capability allows to set up inspectIT in no time with an extensive support for different frameworks and application servers. For more information, take a look at the documentation.
stagemonitor
Stagemonitor is an open-source tracing, profiling and metrics solution for Java applications. It uses byte code manipulation to automatically trace your application without code changes. Stagemonitor is compatible with various OpenTracing implementations and can report to multiple back-ends like Elasticsearch and Zipkin. It also tracks metrics, like response time and error rates.
Datadog
Datadog APM supports OpenTracing, and aims to provide OpenTracing-compatible tracers for all supported languages.
Wavefront by VMware
Wavefront is a cloud-native monitoring and analytics platform that provides three dimensional microservices observability with metrics, histograms and OpenTracing-compatible distributed tracing. With minimal code change, developers can now visualize, monitor and analyze key health performance metrics and distributed traces of Java, Python and .NET applications built on common frameworks such as Dropwizard and gRPC. Check out the distributed tracing demo here.
Elastic APM
Elastic APM is an open source APM solution based on top of the Elastic Stack. Elastic APM agents are available for Java, Node.js, Python, Ruby, Real User Monitoring JavaScript, and Go. Elastic APM records distributed traces, application metrics, and errors in Elasticsearch to be visualized via a curated UI in Kibana, integrating with machine learning and alerting, and seamless correlation with application logs and infrastructure monitoring.
Build Telemetry for Distributed Services之OpenTracing实践的更多相关文章
- Build Telemetry for Distributed Services之OpenTracing项目
中文文档地址:https://wu-sheng.gitbooks.io/opentracing-io/content/pages/quick-start.html 中文github地址:https:/ ...
- Build Telemetry for Distributed Services之OpenTracing简介
官网地址:https://opentracing.io/ What is Distributed Tracing? Who Uses Distributed Tracing? What is Open ...
- Build Telemetry for Distributed Services之OpenTracing指导:C#
官网链接:https://opentracing.io/guides/ 官方微博:https://medium.com/opentracing Welcome to the OpenTracing G ...
- Build Telemetry for Distributed Services之Open Telemetry简介
官网链接:https://opentelemetry.io/about/ OpenTelemetry is the next major version of the OpenTracing and ...
- Build Telemetry for Distributed Services之Open Telemetry来历
官网:https://opentelemetry.io/ github:https://github.com/open-telemetry/ Effective observability requi ...
- Build Telemetry for Distributed Services之Jaeger
github链接:https://github.com/jaegertracing/jaeger 官网:https://www.jaegertracing.io/ Jaeger: open sourc ...
- Build Telemetry for Distributed Services之OpenCensus:C#
OpenCensus Easily collect telemetry like metrics and distributed traces from your services OpenCensu ...
- Build Telemetry for Distributed Services之Elastic APM
官网地址:https://www.elastic.co/guide/en/apm/get-started/current/index.html Overview Elastic APM is an a ...
- Build Telemetry for Distributed Services之OpenCensus:Tracing2(待续)
part 1:Tracing1 Sampling Sampling Samplers Global sampler Per span sampler Rules References
随机推荐
- Linux网络管理——ifconfig、route
Linux识别到的网络设备 eth# eth0 eth1 以太网卡 wifi# wifi0 wifi1 无线网卡 ppp# ppp0 ppp1 拨号连接 lo 本地环回网卡 ...
- Linux学习笔记(十一)shell基础:管道符、通配符和其他特殊符号
一.多命令顺序执行 && || 相当于其他高级语言中的 ? : 二.管道符 [命令1] | [命令2] 命令1的正确输出作为命令2的操作对象 分屏显示结果 netstat -an 命令 ...
- winform中使用缓存
文章:Winform里面的缓存使用 另外一篇文章:缓存-MemoryCache Class
- mongodb索引 多健索引
多健索引与单键索引创建形式相同,区别在于字段的值,单键索引,顾名思义,他的值为一个单一的值,例如字符串,数字或者日期,而多健索引,他的值具有多个记录,例如一个数组,两者建立方式类似 增加一条数组记录 ...
- MySQL进阶2 sql选择语句 where
与SQL语句一致 #进阶2: 条件查询 /* 语法 select 查询列表 #3 from 表名 #1 where 筛选条件; #2 分类: 1.按条件表达式进行筛选 > < = != & ...
- 关于tcp send的再次思考
最近在用socket时,再次思考了一下如何确保对方收到消息的问题 下面是一些不错的回答 https://www.zhihu.com/question/25016042/answer/73785738 ...
- gorm 更新数据时,0值会被忽略
原文: https://www.tizi365.com/archives/22.html ------------------------------------------------------- ...
- Nginx中ngx_http_auth_basic_moudel和ngx_http_stub_status_module模块
ngx_http_auth_basic_module实现基于⽤用户的访问控制,使⽤用basic机制进⾏行行⽤用户认证指令:5.1 auth_basicSyntax: auth_basic string ...
- python_网络编程socket(UDP)
服务端: import socket sk = socket.socket(type=socket.SOCK_DGRAM) #创建基于UDP协议的socket对象 sk.bind(('127.0.0. ...
- http文件服务器上传与下载功能
https://www.cnblogs.com/liferecord/p/4843615.html