EM 算法(三)-GMM
高斯混合模型
混合模型,顾名思义就是几个概率分布密度混合在一起,而高斯混合模型是最常见的混合模型;
GMM,全称 Gaussian Mixture Model,中文名高斯混合模型,也就是由多个高斯分布混合起来的模型;
概率密度函数为
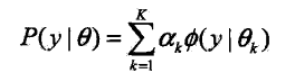
K 表示高斯分布的个数,αk 表示每个高斯分布的系数,αk>0,并且 Σαk=1,
Ø(y|θk) 表示每个高斯分布,θk 表示每个高斯分布的参数,θk=(uk,σk2);
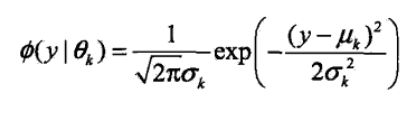
举个例子
男人和女人的身高都服从各自的高斯分布,把男人女人混在一起,那他们的身高就服从高斯混合分布;
高斯混合模型就是用混合在一起的身高数据,估计男人和女人各自的高斯分布
小结
GMM 实际上分为两步,第一步是选择一个高斯分布,如男人数据集,这里涉及取到某个分布的概率,αk,
然后从该分布中取一个样本,等同于普通高斯分布
GMM 常用于聚类,也就是把每个概率密度分布聚为一类;如果概率密度分布为已知,那就变成参数估计问题
EM 解释 GMM
EM 的核心是 隐变量 和 似然函数

求导结果如下
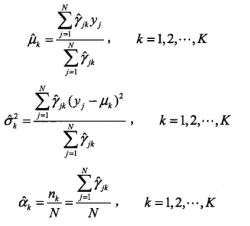
GMM 的 EM 算法

算法流程

Python 实现 GMM
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Ellipse
from scipy.stats import multivariate_normal
plt.style.use('seaborn') # 生成数据
def generate_X(true_Mu, true_Var):
### 生成2000条二维模拟数据,其中400个样本来自N(μ1,var1) ,600个来自N(μ2,var2) ,1000个样本来自N(μ3,var3)
# 第一簇的数据
num1, mu1, var1 = 400, true_Mu[0], true_Var[0]
X1 = np.random.multivariate_normal(mu1, np.diag(var1), num1)
# 第二簇的数据
num2, mu2, var2 = 600, true_Mu[1], true_Var[1]
X2 = np.random.multivariate_normal(mu2, np.diag(var2), num2)
# 第三簇的数据
num3, mu3, var3 = 1000, true_Mu[2], true_Var[2]
X3 = np.random.multivariate_normal(mu3, np.diag(var3), num3)
# 合并在一起
X = np.vstack((X1, X2, X3))
# 显示数据
plt.figure(figsize=(10, 8))
plt.axis([-10, 15, -5, 15])
plt.scatter(X1[:, 0], X1[:, 1], s=5)
plt.scatter(X2[:, 0], X2[:, 1], s=5)
plt.scatter(X3[:, 0], X3[:, 1], s=5)
plt.show()
return X # 更新W
def update_W(X, Mu, Var, Pi):
n_points, n_clusters = len(X), len(Pi)
pdfs = np.zeros(((n_points, n_clusters)))
for i in range(n_clusters):
pdfs[:, i] = Pi[i] * multivariate_normal.pdf(X, Mu[i], np.diag(Var[i]))
W = pdfs / pdfs.sum(axis=1).reshape(-1, 1)
return W # 更新pi
def update_Pi(W):
Pi = W.sum(axis=0) / W.sum()
return Pi # 计算log似然函数
def logLH(X, Pi, Mu, Var):
# 仅计算损失,这步可有可无
n_points, n_clusters = len(X), len(Pi)
pdfs = np.zeros(((n_points, n_clusters)))
for i in range(n_clusters):
pdfs[:, i] = Pi[i] * multivariate_normal.pdf(X, Mu[i], np.diag(Var[i]))
return np.mean(np.log(pdfs.sum(axis=1))) # 画出聚类图像
def plot_clusters(X, Mu, Var, Mu_true=None, Var_true=None):
colors = ['b', 'g', 'r']
n_clusters = len(Mu)
plt.figure(figsize=(10, 8))
plt.axis([-10, 15, -5, 15])
plt.scatter(X[:, 0], X[:, 1], s=5)
ax = plt.gca()
for i in range(n_clusters):
plot_args = {'fc': 'None', 'lw': 2, 'edgecolor': colors[i], 'ls': ':'}
ellipse = Ellipse(Mu[i], 3 * Var[i][0], 3 * Var[i][1], **plot_args)
ax.add_patch(ellipse)
if (Mu_true is not None) & (Var_true is not None):
for i in range(n_clusters):
plot_args = {'fc': 'None', 'lw': 2, 'edgecolor': colors[i], 'alpha': 0.5}
ellipse = Ellipse(Mu_true[i], 3 * Var_true[i][0], 3 * Var_true[i][1], **plot_args)
ax.add_patch(ellipse)
plt.show() # 更新Mu
def update_Mu(X, W):
n_clusters = W.shape[1]
Mu = np.zeros((n_clusters, 2))
for i in range(n_clusters):
Mu[i] = np.average(X, axis=0, weights=W[:, i])
return Mu # 更新Var
def update_Var(X, Mu, W):
n_clusters = W.shape[1]
Var = np.zeros((n_clusters, 2))
for i in range(n_clusters):
Var[i] = np.average((X - Mu[i]) ** 2, axis=0, weights=W[:, i])
return Var if __name__ == '__main__':
# 生成数据
true_Mu = [[0.5, 0.5], [5.5, 2.5], [1, 7]]
true_Var = [[1, 3], [2, 2], [6, 2]]
X = generate_X(true_Mu, true_Var)
# 初始化
n_clusters = 3 # 聚类个数
n_points = len(X) # 样本数
Mu = [[0, -1], [6, 0], [0, 9]] # 3 个期望
Var = [[1, 1], [1, 1], [1, 1]] # 3 个方差
Pi = [1 / n_clusters] * 3
W = np.ones((n_points, n_clusters)) / n_clusters # 隐变量,每个样本属于每个分布的概率
Pi = W.sum(axis=0) / W.sum() # 每个分布的比率
# 迭代
loglh = []
for i in range(5):
plot_clusters(X, Mu, Var, true_Mu, true_Var)
loglh.append(logLH(X, Pi, Mu, Var))
W = update_W(X, Mu, Var, Pi)
Pi = update_Pi(W)
Mu = update_Mu(X, W)
print('log-likehood:%.3f'%loglh[-1])
Var = update_Var(X, Mu, W)
参考资料:
https://blog.csdn.net/jinping_shi/article/details/59613054
《统计学习方法》李航
EM 算法(三)-GMM的更多相关文章
- 统计学习方法笔记--EM算法--三硬币例子补充
本文,意在说明<统计学习方法>第九章EM算法的三硬币例子,公式(9.5-9.6如何而来) 下面是(公式9.5-9.8)的说明, 本人水平有限,怀着分享学习的态度发表此文,欢迎大家批评,交流 ...
- 机器学习(七)EM算法、GMM
一.GMM算法 EM算法实在是难以介绍清楚,因此我们用EM算法的一个特例GMM算法作为引入. 1.GMM算法问题描述 GMM模型称为混合高斯分布,顾名思义,它是由几组分别符合不同参数的高斯分布的数据混 ...
- 机器学习——EM算法与GMM算法
目录 最大似然估计 K-means算法 EM算法 GMM算法(实际是高斯混合聚类) 中心思想:①极大似然估计 ②θ=f(θold) 此算法非常老,几乎不会问到,但思想很重要. EM的原理推导还是蛮复杂 ...
- EM算法之GMM聚类
以下为GMM聚类程序 import pandas as pd import matplotlib.pyplot as plt import numpy as np data=pd.read_csv(' ...
- 【机器学习】GMM和EM算法
机器学习算法-GMM和EM算法 目录 机器学习算法-GMM和EM算法 1. GMM模型 2. GMM模型参数求解 2.1 参数的求解 2.2 参数和的求解 3. GMM算法的实现 3.1 gmm类的定 ...
- 6. EM算法-高斯混合模型GMM+Lasso详细代码实现
1. 前言 我们之前有介绍过4. EM算法-高斯混合模型GMM详细代码实现,在那片博文里面把GMM说涉及到的过程,可能会遇到的问题,基本讲了.今天我们升级下,主要一起解析下EM算法中GMM(搞事混合模 ...
- GMM与EM算法
用EM算法估计GMM模型参数 参考 西瓜书 再看下算法流程
- 最大熵模型和EM算法
一.极大似然已经发生的事件是独立重复事件,符合同一分布已经发生的时间是可能性(似然)的事件利用这两个假设,已经发生时间的联合密度值就最大,所以就可以求出总体分布f中参数θ 用极大似然进行机器学习有监督 ...
- PLSA及EM算法
前言:本文主要介绍PLSA及EM算法,首先给出LSA(隐性语义分析)的早期方法SVD,然后引入基于概率的PLSA模型,其参数学习采用EM算法.接着我们分析如何运用EM算法估计一个简单的mixture ...
随机推荐
- JavaWeb-RESTful(一)_RESTful初认识
系列博文 JavaWeb-RESTful(一)_RESTful初认识 传送门 JavaWeb-RESTful(二)_使用SpringMVC开发RESTful_上 传送门 JavaWeb-RESTful ...
- phpmyadmin 导入sql报错(sql为phpstudy内置数据库导出来)
解决方法 1.打开sql,把头部注释去掉
- Java操作符——i++ 和 ++i的区别
问题:前置自增和后置自增的区别 Code-后置自增 public class Test { public static void main(String[] args) { int a = 2; in ...
- ccf 201612-4 压缩编码(DP)(100)
ccf 201612-4 压缩编码 问题分析: 解决本问题,首先需要知道哈夫曼编码.参见:哈夫曼编码_百度百科. 这是一个编码问题,似乎可以用哈夫曼编码来解决,但是略有不同的地方在于“每个字符的编码按 ...
- RGB颜色透明度转换
100% — FF95% — F290% — E685% — D980% — CC75% — BF70% — B365% — A660% — 9955% — 8C50% — 8045% — 7340% ...
- XML字符串和 java对象项目转换
这是之前写,仅供参考(如果缺少jar包可以私信我,CSDN现在下载的东西太费了,动不动就要积分,开源精神所剩无几了,也没办法都需要吃饭,可以理解) import javax.xml.bind.JAXB ...
- re&xpath&bs4
一.re 二.xpath 三.bs4
- react navigation goBack()返回到任意页面(不集成redux) 一
方案一: 一.适用场景:在app端开发的时候,相反回到某一个页面的时候保持跳转页面的所有状态不更新,也就是说不触发新的生命周期. 例如:A——>B——>C——>D 要想从D页面直接返 ...
- Mac下的Pycharm教程
除非你是用记事本写代码,或者用vim写代码的大牛,那么推荐使用PyCharm编写Python代码. PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效 ...
- jvm学习笔记:一、类的加载、连接、初始化
在JAVA代码中,类型的加载.连接与初始化过程都是程序运行期间完成的. 类型的加载:将已经存在的class从硬盘加载到内存. 类型的连接:将类与类之间的关系确定好. 类型的初始化:类型 静态的变量进行 ...