Unicode规范中有一个BOM的概念。BOM——Byte Order Mark,就是字节序标记。在这里找到一段关于BOM的说明:
在UCS 编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的
字符,所以不应该出现在实际传输中。UCS规范建议我们在传输
字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是
Little-Endian的。因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。
UTF-8不需要BOM来表明
字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的
字节流,就知道这是UTF-8编码了。
Windows就是使用BOM来标记文本文件的编码方式的。
另外unicode网站的FAQ-BOM详细介绍了BOM。官方的自然权威,不过是英文的,看起来比较费劲。
UTF-8编码的文件中,BOM占三个字节。如果用记事本把一个文本文件另存为UTF-8
编码方式的话,用UE打开这个文件,切换到十六进制编辑状态就可以看到开头的EF BB BF了。这是个标识UTF-8编码文件的好办法,软件通过BOM来识别这个文件是否是UTF-8编码,很多软件还要求读入的文件必须带BOM。可是,还是有很多软件不能识别BOM。我在研究Firefox的时候就知道,在Firefox早期的版本里,扩展是不能有BOM的,不过Firefox 1.5以后的版本已经开始支持BOM了。如今又发现,PHP也不支持BOM。
PHP在设计时就没有考虑BOM的问题,也就是说他不会忽略UTF-8编码的文件开头BOM的那三个字符。由于必须在<?或者<?php后面的代码才会作为PHP代码执行,所以这三个字符将会直接输出。如果插件的文件有这个问题,将会导致在后台页面里激活或者不激活插件后显示白屏,如果是模版文件有这个问题,将会导致这三个字符直接输出,造成页面上方有一个小空行。国外的英文插件和模版一般都是用的ASCⅡ码的编码方式,不会有BOM,只有国内的插件和模版会由于作者的不知情造成问题。还有,大家修改模版的时候,由于输出页面使用UTF-8编码,那么修改模版的时候如果有加入中文字符的话,必须把文件转成UTF-8编码才能正常显示,这个时候如果所使用的编辑器自动加上了BOM的话,将会造成在页面上输出这三个字符,显示效果就要看浏览器了,一般是一个空行或是一个
乱码。
ISO 8859-1
ISO/IEC8859-1,又称Latin-1或“西欧语言”,是国际标准化组织内ISO/IEC 8859的第一个8位字符集。它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用变音符号的拉丁字母语言使用。IOS 8859-1表示的字符就是Unicode的0x0000-0x00ff之间的字符。
以下详细说明转载自:https://blog.csdn.net/harrywater123/article/details/50738079
Unicode字符集的发展历史及与UTF-8,ISO8891-1等字符集的关系
摘要:本文从Unicode入手,介绍由于通信问题而产生的字符集,以及Unicode的发展情况。介绍各种字符集的及其使用。并适时的介绍一些历史情况,主要讨论字符集在java机C语言环境中的使用,及阐述UTF,ISO 8859-1,ASCII他们之间的关系。会介绍一些乱码知识,总而言之,乱码产生的原因就是编码与解码不一致造成的。
一、概念:
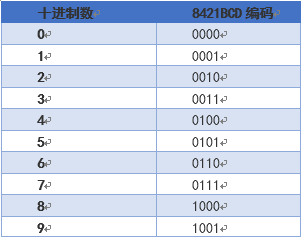
1、BCD码
最初的计算机性能和存储容量都比较差,所以普遍采用4位BCD(BinaryCoded Decimal)编码(这个编码出现比计算机还早,最早是用在打孔卡上的)。BCD编码简单点说就是将十进制用二进制表示,如下图所示。
BCD编码表示数字还可以,但表示字母或符号就很不好用,需要用多个编码来表示。后来经过演变发展成了ASCII码。ASCII含33(ASCII码范围为:0~31和127)个控制字符, 和95(ASCII码范围32~126)个可显示字符。
2、由ASCII码发展到Unicode
ASCII编码存储方式:
其中最高位0,其余七位为0或1,可表示的范围为:0 ~ 2^7= 0 ~ 128
C语言实现打印字符A
# include <stdio.h>
int main()
{
char ch = '65';
printf("%c", ch);
return 0;
}
后来,就像建造巴比伦塔一样,世界各地的都开始使用计算机,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计算机保存他们的文字,他们决定采用127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用下到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128到255这一页的字符集被称"扩展字符集"。从此之后,贪婪的人类再没有新的状态可以用了。
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。但是这难不倒智慧的中国人民,我们不客气地把那些127号之后的奇异符号们直接取消掉, 规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
中国人民看到这样很不错,于是就把这种汉字方案叫做"GB2312"。GB2312 是对ASCII 的中文扩展。
但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,特别是某些很会麻烦别人的国家领导人。于是我们不得不继续把 GB2312 没有用到的代码点找出来老实不客气地用上。
后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK 包括了GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK 扩成了 GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。
由于世界各地都产生了自己的编码方案,这是给人的沟通带来了巨大麻烦。于是有一个叫做ISO的国际组织开始着手解决这个问题,想用一种规范来表示出所有的语言。于是Unicode就这样产生了。Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
注意:Unicode字符集有多种编码方式,如UTF-8、UTF-16等;ASCII只有一种;大多数MBCS(包括GB2312)也只有一种。
字符是各种文字和符号的总称,包括各个国家文字、标点符号、图形符号、数字等。字符集是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集有:ASCII字符集、ISO 8859字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。
各个国家和地区在制定编码标准的时候,“字符的集合”和“编码”一般都是同时制定的。因此,平常我们所说的“字符集”,比如:GB2312, GBK, JIS 等,除了有“字符的集合”这层含义外,同时也包含了“编码”的含义。
3、ISO 8859-1
ISO/IEC8859-1,又称Latin-1或“西欧语言”,是国际标准化组织内ISO/IEC 8859的第一个8位字符集。它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用变音符号的拉丁字母语言使用。IOS 8859-1表示的字符就是Unicode的0x0000-0x00ff之间的字符。
在下文代码页中有关于ISO 8859-1与Windows-1252的区别。
4、Unicode编码详解
Unicode字符集可以简写为UCS(Unicode Character Set),0x0000~0X00ff与ISO 8859-1保持一致
Unicode可以逻辑分为17平面(Plane),每个平面拥有65536( = 216)个代码点,虽然目前只有少数平面被使用。
平面0 (0000–FFFF): 基本多文种平面(Basic Multilingual Plane, BMP).
平面1 (10000–1FFFF): 多文种补充平面(SupplementaryMultilingual Plane, SMP).
平面2 (20000–2FFFF): 表意文字补充平面(SupplementaryIdeographic Plane, SIP).
平面3 (30000–3FFFF): 表意文字第三平面(TertiaryIdeographic Plane, TIP).
平面4 to 13 (40000–DFFFF)尚未使用
平面14 (E0000–EFFFF): 特别用途补充平面(SupplementarySpecial-purpose Plane, SSP)
平面15 (F0000–FFFFF)保留作为私人使用区(PrivateUse Area, PUA)
平面16 (100000–10FFFF),保留作为私人使用区(PrivateUse Area, PUA)
中、日、韩的三种文字占用了Unicode中0x3000(12288)到0x9FFF(40959)的部分,共计28671个字符;而中文在BMP中的范围是:U+4E00到U+9FA5之间是汉字的Unicode编码。
5、 UTF格式详解
UTF是 Unicode Transformation Format的缩写。是Unicode的一种实现方案。任何文字在Unicode中都对应一个值,这个值称为代码点也叫码位(CodePoint)。代码点的值通常写为:U+ABCD,在Java中可以直接将一个字符赋值为,
public class Test1 {
public static void main(String[] args) throws Exception {
char ch = '\u6211';
System.out.println(ch);
}
}
输出结果:我
UTF-8四种具体实现方式:
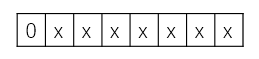
1.第一种是一个字节的编码:即128个ascii字符(只需要一个字节)
格式:0xxxxxxx
2^7 - 1 = 127 = 7F = (0111-1111)
编码方式Unicoe范围由(U+0000 至 U+007F)
2.第二种是两个字节的编码:即带有符号的拉丁文,希腊文,西里尔字母,亚美尼亚语,希伯来文,阿拉伯文等,则需要两个字节编码(Unicode 范围由U+0080至U+07FF)
格式:110xxxxx 10xxxxxx
(0080)16 = (128)10
(07FF) 16 = (2047)10 = 2^11-1;
3.第三种是三字节的编码,即其他多文种平面(BMP)中的字符(这包括了大部分的汉字)(范围为: U+0800 至 U+FFFF)
格式:1110xxxx 10xxxxxx 10xxxxxx
U+0800 = 2048;
U+FFFF = 65535 = 2^16 -1;
1110xxxx 10xxxxxx 10xxxxxx
4.第四种是4-6字节编码。
U+1 0000至U+1 FFFFF:使用四字节
U+20 0000 至U+3FF FFFF:使用五字节
U+400 0000至U+7FFF FFFF
UTF-8就是以8位为单元对UCS进行编码。从UCS-2到UTF-8的编码方式如下:
UCS-2编码(16进制)
范围
UTF-8 字节流(二进制)
0000 - 007F
0 - 127
0xxxxxxx
0080 - 07FF
128-2047
110xxxxx 10xxxxxx
0800 - FFFF
2048-65535
1110xxxx 10xxxxxx 10xxxxxx
例如“汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,所以肯定要用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 110001 001001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
目前计算机一般使用 2 个字节(16 位)来存放一个序号(DBCS,DoubleByte Character System),因此,这种方式存放的字符也被称作宽字节字符。比如,字符串"中文123" 在 Windows2000 下,内存中实际存放的是 5 个字符,一共10个字节;若在gb2312编码中,共计五个字符,7个字节。
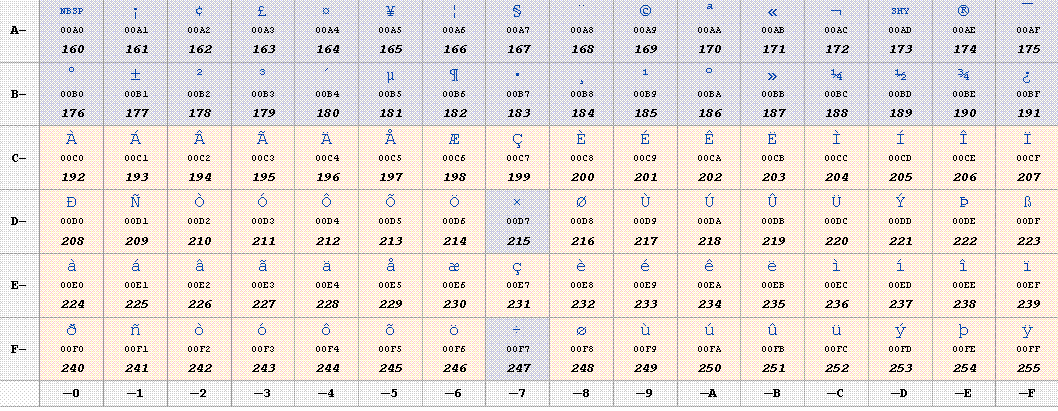
6、代码页及字符集对照表
Windows将字符集称作代码页。代码页是字符集编码的别名,也有人称"内码表",
437 IBM437 OEM美国
932 shift_jis 日语 (Shift-JIS)
936 gb2312 简体中文 (GB2312)
950 big5 繁体中文 (Big5)
1200 utf-16 Unicode(Little-Endian)
1201 UnicodeFFFE Unicode (Big-Endian)
1252 Windows-1252 西欧字符 (Windows)
1253 windows-1253 希腊字符 (Windows)
65001 UTF-8
ISO-8859-1和Windows-1252的区别
ISO-8859-1,正式编号为ISO/IEC 8859-1:1998,又称Latin-1或“西欧语言”,是国际标准化组织内ISO/IEC 8859的第一个8位字符集。它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用附加符号的拉丁字母语言使用。Unicode的前0-255个字符与ISO-8859-1相一致。
Windows-1252经常被错误地贴上ISO-8859-1的标签,因为它们十分相似。除了128到159(十六进制80到9F)范围内的很少使用的C1控制字符被替换为额外的字符外,Windows-1252代码页的字符和ISO-8859-1完全一致。Windows-28591代码页才是真正的ISO-8859-1,然而,英文版的Windows 7系统上似乎没有Windows-28591代码页,至于其他系统有没有我就不知道了。Windows-1252是ISO的超集。
最后说点废话,百度百科上的东西大部分都是复制粘贴中文维基百科上的,中文维基百科没有的东西,百度百科也不太可能会有,比如说Windows-1252。而维基上的中文资料远远少于英文资料,很多详尽的英文资料要么没有翻译成中文,要么只是翻译成很简略的中文,比如ISO-8859-1。翻译维基百科的词条又没有钱赚,中国人那么聪明,才不会去做这种吃力不讨好的事情。
UTF-16和UCS-2都是Unicode的编码方式。
Unicode使用一个确定的名字和一个叫做代码点(code point)的整数来定义一个字符。例如©字符被命名为“copyright sign”并且有一个值为U+00A9(0xA9,十进制169)的代码点。
Unicode的码空间为U+0000到U+10FFFF,共有1,112,064个代码点(code point)可用来映射字符. Unicode的码空间可以划分为17个平面(plane),每个平面包含216(65,536)个代码点。每个平面的代码点可表示为从U+xx0000到U+xxFFFF, 其中xx表示十六进制值从0016 到1016,共计17个平面。
第一个Unicode平面(代码点从U+0000至U+FFFF)包含了最常用的字符,该平面被称为基本多语言平面(Basic Multilingual Plane),缩写为BMP。其他平面称为辅助平面(Supplementary Planes)。
UCS-2 (2-byte UniversalCharacter Set)是一种定长的编码方式,UCS-2仅仅简的使用一个16位码元来表示代码点,也就是说在0到0xFFFF的代码点范围内,它和UTF-16基本一致。
UTF-16 (16-bit UnicodeTransformation Format)是UCS-2的拓展,它可以表示BMP以为的字符。UTF-16使用一个或者两个16位的码元来表示代码点,这样就可以对0到0x10FFFF的代码点进行编码。
例如,在UCS-2和UTF-16中,BMP中的字符U+00A9copyright sign(©)都被编码为0x00A9。
但是在BMP之外的字符,例如,只能用UTF-16进行编码,使用两个16位码元来表示:0xD834 0xDF06。这被称作代理对,值得注意的是一个代理对仅仅表示一个字符,而不是两个。UCS-2并没有代理对的概念,所以会将0xD834 0xDF06解释为两个字符。
UTF-16与UCS-2的联系与区别:
简单的说,UTF-16可看成是UCS-2的父集。在没有辅助平面字符(surrogate code points)前,UTF-16与UCS-2所指的是同一的意思。(严格的说这并不正确,因为在UTF-16中从U+D800到U+DFFF的代码点不对应于任何字符,而在使用UCS-2的时代,U+D800到U+DFFF内的值被占用。)但当引入辅助平面字符后,就称为UTF-16了。
但UCS-2只是一个编码方案,UTF-16却要用于实际的传输,所以就不得不考虑字节序的问题。
7、UTF的字节序和BOM
UTF-8以字节为编码单元,没有字节序的问题。UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如收到一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?
Unicode规范中推荐的标记字节顺序的方法是BOM。BOM是Byte Order Mark。BOM是一个有点小聪明的想法:
在UCS编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTHNO-BREAK SPACE"。
这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符" zero widthno-break space"又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB BF(读者可以用我们前面介绍的编码方法验证一下)。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
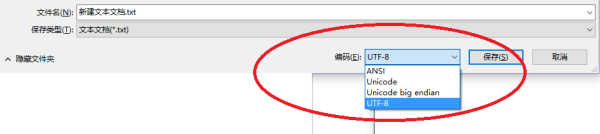
8、Windows记事本有四种保存格式
用记事本-文件-另存为,如上如图即可看到Windows记事本保存的四种格式,如上如所示,分别为:
l ANSI:在简体中文系统的windows中ANSI即gb2312.
l Unicode:对应UTF-16LE,
l Unicode Big Endian:对应UTF-16BE
l UTF-8:使用了变长的编码
Big Endian 和 Little Endian名词的由来
这两个术语来自于 Jonathan Swift 的《《格利佛游记》其中交战的两个派别无法就应该从哪一端--小端还是大端--打开一个半熟的鸡蛋达成一致。:)
“endian”这个词出自《格列佛游记》。小人国的内战就源于吃鸡蛋时是究竟从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开,由此曾发生过六次叛乱,其中一个皇帝送了命,另一个丢了王位。
我们一般将endian翻译成“字节序”,将big endian和little endian称作“大尾”和“小尾”。
在那个时代,Swift是在讽刺英国和法国之间的持续冲突,Danny Cohen,一位网络协议的早期开创者,第一次使用这两个术语来指代字节顺序,后来这个术语被广泛接纳了。
主要表现在存储格式上,比如一个字符的编码为ABCD
Big Endian的(FE FF)存储格式为:AB CD;
Little Endian的(FF FE)存储格式为:CD AB ;
Windows记事本就是使用BOM来标记文本文件的编码方式的。当打开一个txt文本,会自动添加BOM。
二 应用
1. 1 Java对字符的处理
1 )、String类的
public byte[] getBytes(Charset charset)
这是java字符串处理的一个标准函数,其作用是将字符串所表示的字符按照charset编码,并以字节方式表示。注意字符串在java内存中总是按unicode编码存储的。
public class Test1 {
public static void main(String[] args) throws Exception {
String string = "你好!";
String str1 = new String(string.getBytes("gbk"));
System.out.println(str1);
}
}
将一个String 类型Unicode字符串转为对应字节,一般String默认光标gbk编码;各个编译器可能不同,可以到windows-preference-general-workspace界面的左下角有显示,也可以自行调节。
2)、 new String(charset)
这是java字符串处理的另一个标准函数,和上一个函数的作用相反,将字节数组按照charset编码进行组合识别,最后转换为unicode存储。参考上述getBytes的例子
3)、setCharacterEncoding()
该函数用来设置http请求或者相应的编码。
1.2. String 与byte的相互转换
java字符编码常见问题主要在两个方面
l 字节到String
l String转字节。
1 字节到String。
只有字节才有编码含义,String永远是Unicode。在java中,字符默认存储的编码为utf-8码,所以String str1 = “你好,Ice Blue”;Str的编码为utf-8可以用一下代码来实验:
System.out.println(Charset.defaultCharset());
以下java代码实现了将一个字符的编码转换为汉字。
public class Test02 {
public static void main(String[] args) throws Exception {
System.out.println("字节按编码转成字符:");
String strUtf8Hex = "E4B8ADE69687"; // “中文”的utf8的16进制编码
byte byteUtf8[] = hex2byte(strUtf8Hex);// 转成字节流
String str = new String(byteUtf8,"UTF-8");
System.out.println(str);
}
public static byte[] hex2byte(String str) {
byte[] b = new byte[str.length() / 2];
for (inti = 0; i < str.length(); i += 2) {
String str2 = str.substring(i, i + 2);
b[i / 2] = (byte) Integer.parseInt(str2, 16);
}
return b;
}
}
2. String转字节。String.getBytes方法是按编码集转换编码,不能理解为取出String的字节来。是平时常见转码工作应该采用的方法。
以下代码实现了将一个汉字转换为其对应编码
public class Test1 {
public static void main(String[]args) throws Exception {
System.out.println("字节按编码转成字符:");
String strUtf8Hex ="中文賦";// “中文”的utf8的16进制编码
byte[] Utf8byte = strUtf8Hex.getBytes("UTF-16BE");
System.out.println(byte2hex(Utf8byte));
}
public static String byte2hex(byte[]b) {
String sum = "";
String stmp = "";
for (inti = 0; i < b.length; i++) {
stmp = Integer.toHexString(b[i] & 0XFF);//保留前8位
if (stmp.length() == 1)
sum = sum + "0" + stmp;
else
sum = sum + stmp;
}
return sum.toUpperCase();
}
}
3 控制台乱码问题
Eclipse 的控制台必须用GBK编码。所以条件1和条件4必须同时满足否则运行的还是乱码。才能保证不是乱码。
条件1,Window | Preferences | Workspace | Textfileencoding | GBK编码。这样定义的是整个工作区间的编码。这样就把整个工作空间的编码格式定死了,但是如果某一个工程用的是不同的编码格式的话这样单独再解决。如下:
条件2,工程上右键 | Properties | Resource | Textfileencoding | UTF-8编码。或者适合的编码格式。这样定义的是整个工程的编码。这样就把整个工程的编码格式定死了,但是如果某一个文件用的是不同的编码格式的话这样单独再解决。如下:
条件3,在某个文件上右键| Properties | Resource | Textfileencoding | UTF-8编码。或者适合的编码格式。这样定义的是单独某个文件的编码。
这里要说的是文件的实际编码格式优先用的是:第3个,其次再用2,最后先用1。有时候是123,必须满足条件。无论怎样这几种编码格式试一试就全知道了。
条件4,还有运行时编码设置如下:菜单:Run Configuration | 右侧的选项卡Common 的 Console Encoding 选择UTF-8编码。这个是用来控制console控制台显示,必须是与前面几个编码相同UTF-8,就不会乱码。
这样保证了工作空间和工程代码编程方式和工程里的单独文件的编码格式的不冲突。
拓展:
计算机数制的概念
基本概念:
数码:数制中表示基本数值大小的不同数字符号。
例如,
二进制有两个数码:0,1;
十进制有10个数码:0、1、2、3、4、5、6、7、8、9。
十六进制有16个数码:0、1、2、3、4、5、6、7、8、9,A、B、C、D、E、F
基数:数制所使用数码的个数。例如,二进制的基数为2;十进制的基数为10。
位权: 数制中某一位上的1所表示数值的大小(所处位置的价值)。例如,十进制的123,1的位权是100,2的位权是10,3的位权是1。二进制中的 1011 ,第一个1的位权是8,0的位权是4,第二个1的位权是2,第三个1的位权是1;
数制:按进位的原则进行计数,称为进位计数制,简称数制。不论是哪一种数制,其计数和运算都有共同的规律和特点。
⑴ 逢N进一
N是指数制中所需要的数字字符的总个数,称为基数。如:0、1、2、3、4、5、6、7、8、9等10个不同的符号来表示数值,这个10就是数字字符的总个数,也是十进制的基数,表示逢十进一。
⑵ 位权表示法
位权是指一个数字在某个固定位置上所代表的值,处在不同位置上的数字所代表的值不同,每个数字的位置决定了它的值或者位权。位权与基数的关系是:各进位制中位权的值是基数的若干次幂。
数制符号
二进制B(binary)
八进制O(octal)
十进制D(decimal)
十六进制H(hexadecimal)
至于进制转换网上有很多参考文档,这里不再赘述。
参考资料:
1 趣谈Unicode,ansi,utf-8,Unicode big endian这些编码有什么区别(http://blog.csdn.net/fanwenbo/article/details/2298800)
2 Unicode字符查询(http://unicode-table.com/cn/#control-character)
3 国标码查询 (http://www.qqxiuzi.cn/bianma/guobiaoma.php)
4 Code Page Identifiers ( https://msdn.microsoft.com/en-us/library/windows/desktop/dd317756(v=vs.85).aspx)
- 字符编码知识:Unicode、UTF-8、ASCII、GB2312等编码之间是如何转换的?
转自: http://apps.hi.baidu.com/share/detail/17798660 字符编码是计算机技术的基石,想要熟练使用计算机,就必须懂得字符编码的知识.不注意的人可能对这个不 ...
- Unicode中的BOM
BOM简述 BOM是byte order mark的缩写,在UTF-16和UTF-32中需要使用BOM来区分字节的顺序,因为我们目前的CPU有两种系列,一种是大端模式,一种是小端模式(我们常用的电脑手 ...
- 编码格式简介:ASCII码、ANSI、GBK、GB2312、GB18030和Unicode、UTF-8,BOM头
编码格式简介:ASCII码.ANSI.GBK.GB2312.GB18030和Unicode.UTF-8,BOM头 二进制: 只有0和1. 十进制.十六进制.八进制: 计算机其实挺笨的,它只认识0101 ...
- 【Python】使用codecs模块进行文件操作及消除文件中的BOM
前言 此前遇到过UTF8格式的文件有无BOM的导致的问题,最近在做自动化测试,读写配置文件时又遇到类似的问题,和此前一样,又是折腾了挺久之后,通过工具比较才知道原因. 两次在一个问题上面栽更头,就在想 ...
- OWIN规范中最让人费解的地方
OWIN defines a standard interface between .NET web servers and web applications. OWIN最让人费解不是OWIN的五大角 ...
- MANIFEST.INF!JAR规范中
MANIFEST.INF!JAR规范中 META-INF 目录中内容心得.顺带整理了网上资料,提供地址 标签: jarjava产品sunantapache 2012-03-31 17:09 2768人 ...
- OpenGL ES SL 3.0规范中以前的attribute改成了in varying改成了out
OpenGL ES和OpenGL的图标 关于“OpenGL ES SL 3.0规范中以前的attribute改成了in varying改成了out”这个问题,做一阐述: 1.关键字的小修 ...
- CommonJS 规范中的 module、module.exports 区别
CommonJS 规范中的 module.module.exports 区别 CommonJS规范规定,每个模块内部,module变量代表当前模块.这个变量是一个对象,它的exports属性(即mod ...
- UTF-8中的BOM
UTF-8中的BOM UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式.字符"ZERO WIDTH NO-BREAK SPACE"的UTF-8编码是EF BB B ...
随机推荐
- MySql 多表关系
多表关系 一对一关系 一对一关系是最好理解的一种关系,在数据库建表的时候可以将人表的主键放置与身份证表里面,也可以将身份证表的主键放置于人表里面 一对多关系 班级是1端,学生是多端,结合面向对象的思想 ...
- LeetCode 142——环形链表II(JAVA)
给定一个链表,返回链表开始入环的第一个节点. 如果链表无环,则返回 null. 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始). 如果 pos 是 - ...
- X86逆向5:破解程序的自效验
在软件的破解过程中,经常会遇到程序的自效验问题,什么是自效验?当文件大小发生变化,或者MD5特征变化的时候就会触发自效验暗装,有些暗装是直接退出,而有些则是格盘蓝屏等,所以在调试这样的程序的时候尽量在 ...
- RHEL8配置本地yum源
在RHEL8中把软件源分成了两部分一个是BaseOS,一个是AppStream. 在Red Hat Enterprise Linux 8.0中,统一的ISO自动加载BaseOS和AppStream安装 ...
- 怎样使用 ssh 命令远程连接服务器?
以 Git Bash 和 阿里云 ECS云服务器 为例, 想要进行远程连接, 可以使用 ssh 用户名@服务器IP 进行连接. 如下: 注意: 1. 密码输入时是没有提示的 2. root 是超级管理 ...
- hdu 1215 求约数和 唯一分解定理的基本运用
http://acm.hdu.edu.cn/showproblem.php?pid=1215 题意:求解小于n的所有因子和 利用数论的唯一分解定理. 若n = p1^e1 * p2^e2 * ……*p ...
- asp.net 4.Redirect重定向和文件图片上传
1.Response.Redirect 如图所示: 1.用户点击修改按钮, 浏览器向服务器发送一个POST请求 http://localhost:6543/UpdateUser.ashx 2.服务器的 ...
- WIN7(WINDOWS7)在添加网络打印机时提示这个,这里的密码是什么密码,能不能不用密码?
360急救箱应该提高计算机的网络访问安全性,加上与验证机制,所以当你要访问的网络资源,你需要输入用户名和密码进行认证. 1,点击“开始 - 运行”,输入gpedit.msc然后按Enter键. 2,计 ...
- 如果你的评论被WordPress的Akismet插件屏蔽,怎么解封?
Akismet是Matt Mullenweg早期创办的一个项目,现在已经是Automattic公司的一个专注于剿杀垃圾评论的产品.在Wordpress用户中使用最多,z-blog也有用户在用,由于垃圾 ...
- 学习笔记--三分法&秦九韶算法
前言 其实也没什么好说的吧,三分法就是用来求一个单调函数的最值和满足最大值的\(x\),秦九韶算法就是在\(O(N)\)时间内求一个多项式值 怎么用 三分法使用--看这篇:https://www.cn ...