Hadoop2.6.0安装 — 集群
文 / vincentzh
原文连接:http://www.cnblogs.com/vincentzh/p/6034187.html
这里写点 Hadoop2.6.0集群的安装和简单配置,一方面是为自己学习的过程做以记录,另一方面希望也能帮助到和LZ一样的Hadoop初学者,去搭建自己的学习和练习操作环境,后期的 MapReduce 开发环境的配置和 MapReduce 程序开发会慢慢更新出来,LZ也是边学习边记录更新博客,路人如有问题欢迎提出来一起探讨解决,不足的地方希望路人多指教,共勉!
目录
本文主要详述配置 Hadoop 集群,默认路人已经掌握了 Hadoop 单机/伪分布式的配置,否则请查阅 Hadoop2.6.0安装 — 单机/伪分布。单机/伪分布式的配置是基础,集群的配置也不过是再单机/伪分布的基础上横向扩展节点而已,另外在开发的过程中,也是单机/伪分布都要去用,或者和集群之间相互切换进行调试和运行代码。
环境准备
环境的准备和上篇(Hadoop2.6.0安装 — 单机/伪分布)的环境一致,因为LZ也是在一台电脑上搞的虚拟机学习的,Virtual Box虚拟机下Ubuntu14.04 64位系统,Hadoop版本就不用再啰嗦了吧,题目上写清楚了。此处集群包含了3个节点(机器),其中一个做 Master 节点(NameNode),其他两台机器作为 Slave 节点(DataNode)。
OK,既然集群有三个节点,需要先将三个虚拟环境准备好,才能开始集群的配置,整个流程如下:
- 三台机器都准备好 Linux 环境,分别配置 hadoop 用户,安装 SSH server、配置 Java 环境;
- 确定一台机器作为 Master 节点(虚拟环境随便指定一个都行啦,但生产环境可要用最牛逼的机器来做哈,毕竟 Master 躺了比较麻烦);
- 在确定的 Master 节点上安装 Hadoop,并完成集群配置;
- 将 Master 节点上 Hadoop 的安装目录直接 copy 到所有的 Salve 节点即可;
- 在 Master 节点启动集群。
网络配置
VirtualBox需要为三台机器配置网络,以保证集群中的所有节点之间可以互相通信,需要更改网络连接方式为桥接(Bridge)模式,才能实现虚拟机之间的网络互联,同时需要确保各节点之间的Mac地址不同。VirtualBox虚拟机几种网络连接方式的异同可以去这里查看。
为方便区分各个节点,可以去修改下各个节点的主机名(直接改为你能够辨识的主机名)。
$sudo vim /etc/hostname

此处使用了一个Master节点,两个Slave节点,需要在hosts文件中添加上节点的与IP的映射关系(所有节点都需要修改,节点直接用SSH直接连接的时候可以直接使用主机名连接)。
$sudo vi /etc/hosts
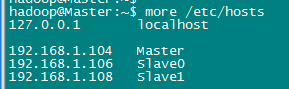
测试网络连接。所有节点之间的连接都需要逐个测试,以保证所有节点直接能够互联互通。
$ping Slave0 -c
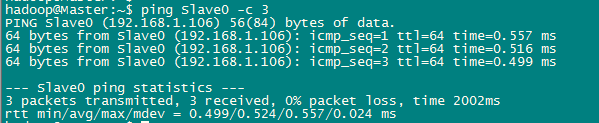
配置SSH登陆
这个操作是要让 Master 节点可以无密码 SSH 登陆到各个 Slave 节点上。
首先生成 Master 节点的公匙,在 Master 节点的终端中执行(因为改过主机名,所以还需要删掉原有的再重新生成一次):
$cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost,生成.ssh目录
$rm ./id_rsa* # 删除之前生成的公匙(如果有)
$ssh-keygen -t rsa # 一直按回车就可以
$cat ./id_rsa.pub >> ./authorized_keys
在 Master 节点将上公匙传输到 Slave0 和 Slave1 节点:
$scp ~/.ssh/id_rsa.pub hadoop@Slave0:/home/hadoop/
$scp ~/.ssh/id_rsa.pub hadoop@Slave1:/home/hadoop/
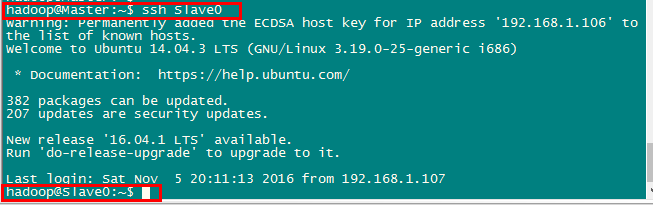
将Master节点的公钥传输到Slave节点后,需要分别在两个节点上将Master节点传输过来的公钥加入授权。这样,在 Master 节点上就可以无密码 SSH 到各个 Slave 节点了,可在 Master 节点上执行如下命令进行检验,如下图所示:
配置环境变量
配置好 Hadoop 相关的所有环境变量,具体配置在这里,同样如果为了方便操作 DataNode,可以将 Slave 节点上Hadoop安装目录下的 /sbin 和 /bin 都添加到 $PATH 环境变量中。
配置集群/分布式
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。(比伪分布多了一个slaves文件)
1. slaves文件,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。LZ直接将 Slave0 和 Slave1 都加入其中。
2. core-site.xml(此处需要主义 fs.defaultFS 属性,LZ在用window上的eclipse配置开发环境的时候一直配置不成功,但将 Master 改为具体IP地址之后没问题,这里将在开发环境配置的时候详述)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
3. hdfs-site.xml,dfs.replication 一般设为 3,但我们只有两个 Slave 节点,所以 dfs.replication 的值还是设为 2:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
4. mapred-site.xml(需要先重命名,默认文件名为 mapred-site.xml.template,因为默认情况只配置HDFS),然后配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
5. yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置好后,将 Master 上的 /usr/local/hadoop 文件夹复制到各个节点上。
注:如果之前在Master节点上启动过Hadoop,需要在copy之前先删除hadoop目录下的 tmp 文件和 logs下的文件。在 Master 节点上执行:
$cd /usr/local
$sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
$sudo rm -r ./hadoop/logs/* # 删除日志文件
$tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
$cd ~
$scp ./hadoop.master.tar.gz Slave0:/home/hadoop
copy结束后,在Slave0和Slave1节点上直接将copy过来的目录解压即可(Master节点需要和Slave节点有相同的配置)。
$sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
$sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
$sudo chown -R hadoop /usr/local/hadoop
启动集群/分布式
首次启动需要先在 Master 节点执行 NameNode 的格式化,之后的启动不需要再去进行:
$hdfs namenode -format
逐个启动所有守护进程,并在各个节点通过jps查看所有守护进程启动情况。
$start-dfs.sh
$start-yarn.sh
$mr-jobhistory-daemon.sh start historyserve
Master节点

Slave0节点
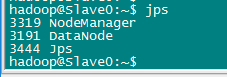
Slave节点
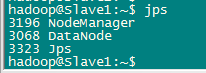
要确保所有的守护进程都能够正常启动。另外还需要在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有 2 个 Datanodes:

关闭集群同样也是在Master节点上执行
$stop-yarn.sh
$stop-dfs.sh
$mr-jobhistory-daemon.sh stop historyserver
问题排查
如果有任何节点无法启动或启动不正常,需要在各自的 logs 文件中查找启动日志,逐个排查问题原因。常见的原因如下:
- hosts 文件中的主机名和 IP 映射错误;
- 5个配置文件中的有拼写错误,或者关键信息(如:IP地址)设置错误;
- LZ 碰到过的,特么真心诡异的问题,所有问题全排查过都OK的,就是有个DataNode启不起来,后来才发先 slaves 文件被污染,但查看显示正常,将 slaves 文件删除后重建添加DataNode主机名即可。
Hadoop2.6.0安装 — 集群的更多相关文章
- 基于Hadoop2.5.0的集群搭建
http://download.csdn.net/download/yameing/8011891 一. 规划 1. 准备安装包 JDK:http://download.oracle.com/otn ...
- 菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章
菜鸟玩云计算之十八:Hadoop 2.5.0 HA 集群安装第1章 cheungmine, 2014-10-25 0 引言 在生产环境上安装Hadoop高可用集群一直是一个需要极度耐心和体力的细致工作 ...
- 菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章
菜鸟玩云计算之十九:Hadoop 2.5.0 HA 集群安装第2章 cheungmine, 2014-10-26 在上一章中,我们准备好了计算机和软件.本章开始部署hadoop 高可用集群. 2 部署 ...
- Redis Cluster 4.0.9 集群安装搭建
Redis Cluster 4.0.9集群搭建步骤:yum install -y gcc g++ gcc-c++ make openssl cd redis-4.0.9 make mkdir -p / ...
- Redis 3.0 Cluster集群配置
Redis 3.0 Cluster集群配置 安装环境依赖 安装gcc:yum install gcc 安装zlib:yum install zib 安装ruby:yum install ruby 安装 ...
- weblogic11g 安装集群 —— win2003 系统、单台主机
weblogic11g 安装集群 —— win2003 系统.单台主机 注意:此为weblogic11g 在win2003系统下(一台主机)的安装集群,linux.hpux.aix及多个主机下原理一 ...
- 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群(转载-2)
原文:http://www.cnblogs.com/PurpleDream/p/4510279.html 分布式存储 CentOS6.5虚拟机环境搭建FastDFS-5.0.5集群 前言: ...
- linux下redis4.0.2集群部署(利用原生命令)
一.部署架构如下 每台服务器准备2个节点,一主一从,主节点为另外两台其中一台的主,从节点为另外两台其中一台的从. 二.准备6个节点配置文件 在172.28.18.75上操作 cd /etc/redis ...
- Redis-4.0.11集群配置
版本:redis-3.0.5 redis-3.2.0 redis-3.2.9 redis-4.0.11 参考:http://redis.io/topics/cluster-tutorial. 集群 ...
随机推荐
- ASP.NET Web API自身对CORS的支持: EnableCorsAttribute特性背后的故事
从编程的角度来讲,ASP.NET Web API针对CORS的实现仅仅涉及到HttpConfiguration的扩展方法EnableCors和EnableCorsAttribute特性.但是整个COR ...
- 《Hive编程指南》—— 读后总结
知识图谱
- C#设计模式-外观模式
在软件开发过程中,客户端程序经常会与复杂系统的内部子系统进行耦合,从而导致客户端程序随着子系统的变化而变化,然而为了将复杂系统的内部子系统与客户端之间的依赖解耦,从而就有了外观模式,也称作 ”门面“模 ...
- WPF入门教程系列十七——WPF中的数据绑定(三)
四. XML数据绑定 这次我们来学习新的绑定知识,XML数据绑定.XmlDataProvider 用来绑定 XML 数据,该XML数据可以是嵌入.Xmal文件的 XmlDataProvider 标记中 ...
- ClickOnce部署
(1):一些发布方式 ClickOnce是什么玩意儿,这个问题嘛,在21世纪的互联网严重发达的时代,估计也没有必要大费奏章去介绍了,弄不好的话,还有抄袭之嫌.因此,有关ClickOnce的介绍,各位朋 ...
- hibernate基础之无法自动创建表总结
刚刚接触Hibernate尝试写一个事例项目,但是搞了一天硬是苦逼的没弄通,一直的报无法创建表,现在就把这些经验给大家分享一下: 1.书写问题: <property name="hbm ...
- .NET平台开源项目速览(5)深入使用与扩展SharpConfig组件
上个月在文章:这些.NET开源项目你知道吗?让.NET开源来得更加猛烈些吧 和 .NET平台开源项目速览(1)SharpConfig配置文件读写组件 中都提到了SharpConfig组件,简单轻量级 ...
- Android重写菜单增加系统自带返回键
条件:当前项目导入了ActionBarSherlock这个jar包,这个jar包的作用为了程序的兼容性,考虑低版本的问题. 学习ActionBarSherlock参考博客链接:http://blog. ...
- Html,Css,Dom,javascript细节总结
最近愈发觉得基础的重要性,细节决定成败,所以希望能够将自己注意到的搜集到的一些关于前端的小细节小知识整理出来,更好的方便自己记忆回顾. 1.在构建网页Html框架时,尽量只给外层标记(即是父标记)定义 ...
- Android动画学习(二)——Tween Animation
前两天写过一篇Android动画学习的概述,大致的划分了下Android Animation的主要分类,没有看过的同学请移步:Android动画学习(一)——Android动画系统框架简介.今天接着来 ...