scikit-learn机器学习(二)逻辑回归进行二分类(垃圾邮件分类),二分类性能指标,画ROC曲线,计算acc,recall,presicion,f1
数据来自UCI机器学习仓库中的垃圾信息数据集
数据可从http://archive.ics.uci.edu/ml/datasets/sms+spam+collection下载
转成csv载入数据
import matplotlib
matplotlib.rcParams['font.sans-serif']=[u'simHei']
matplotlib.rcParams['axes.unicode_minus']=False
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.model_selection import train_test_split,cross_val_score df = pd.read_csv('data/SMSSpamCollection.csv',header=None)
print(df.head) print("垃圾邮件个数:%s" % df[df[0]=='spam'][0].count())
print("正常邮件个数:%s" % df[df[0]=='ham'][0].count())
垃圾邮件个数:747
正常邮件个数:4825
创建TfidfVectorizer实例,将训练文本和测试文本都进行转换
X = df[1].values
y = df[0].values
X_train_raw,X_test_raw,y_train,y_test=train_test_split(X,y)
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train_raw)
X_test = vectorizer.transform(X_test_raw)
建立逻辑回归模型训练和预测
LR = LogisticRegression()
LR.fit(X_train,y_train)
predictions = LR.predict(X_test)
for i,prediction in enumerate(predictions[:5]):
print("预测为 %s ,信件为 %s" % (prediction,X_test_raw[i]))
预测为 ham ,信件为 Send to someone else :-)
预测为 ham ,信件为 Easy ah?sen got selected means its good..
预测为 ham ,信件为 Sorry da. I gone mad so many pending works what to do.
预测为 ham ,信件为 What not under standing.
预测为 spam ,信件为 SIX chances to win CASH! From 100 to 20,000 pounds txt> CSH11 and send to 87575. Cost 150p/day, 6days, 16+ TsandCs apply Reply HL 4 info
二元分类性能指标:混淆矩阵
# In[2]二元分类分类指标
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
# predictions 与 y_test
confusion_matrix = confusion_matrix(y_test,predictions)
print(confusion_matrix)
plt.matshow(confusion_matrix)
plt.title("混淆矩阵")
plt.colorbar()
plt.ylabel("真实值")
plt.xlabel("预测值")
plt.show()
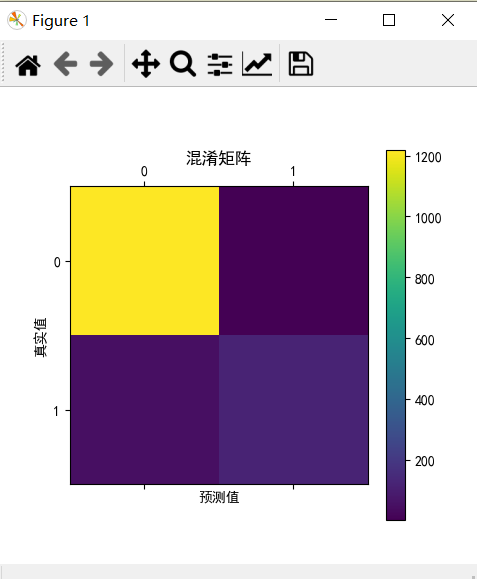
[[1217 1]
[ 52 123]]
准确率,召回率,精准率,F1值
# In[3] 给出 precision recall f1-score support
from sklearn.metrics import classification_report
print(classification_report(y_test,predictions)) from sklearn.metrics import roc_curve,auc
# 准确率
scores = cross_val_score(LR,X_train,y_train,cv=5)
print("准确率为: ",scores)
print("平均准确率为: ",np.mean(scores)) # 有时必须要将标签转为数值
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
y_train_n = class_le.fit_transform(y_train)
y_test_n = class_le.fit_transform(y_test) # 精准率
precision = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='precision')
print("平均精准率为: ",np.mean(precision))
# 召回率
recall = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='recall')
print("平均召回率为: ",np.mean(recall))
# F1值
f1 = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='f1')
print("平均F1值为: ",np.mean(f1))
准确率为: [0.96654719 0.95459976 0.95449102 0.9508982 0.96047904]
平均准确率为: 0.9574030433756144
平均精准率为: 0.9906631114805584
平均召回率为: 0.6956979405034325
平均F1值为: 0.8162874707978786
画出ROC曲线,AUC为ROC曲线以下部分的面积
# In[4] ROC曲线 y_test_n为数值
predictions_pro = LR.predict_proba(X_test)
false_positive_rate, recall, thresholds = roc_curve(y_test_n,predictions_pro[:,1])
roc_auc = auc(false_positive_rate, recall)
plt.title("受试者操作特征曲线(ROC)")
plt.plot(false_positive_rate, recall, 'b', label='AUC = % 0.2f' % roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.xlabel('假阳性率')
plt.ylabel('召回率')
plt.show()

所有代码:
# -*- coding: utf-8 -*-
import matplotlib
matplotlib.rcParams['font.sans-serif']=[u'simHei']
matplotlib.rcParams['axes.unicode_minus']=False
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model.logistic import LogisticRegression
from sklearn.model_selection import train_test_split,cross_val_score df = pd.read_csv('data/SMSSpamCollection.csv',header=None)
print(df.head) print("垃圾邮件个数:%s" % df[df[0]=='spam'][0].count())
print("正常邮件个数:%s" % df[df[0]=='ham'][0].count()) # In[1]
X = df[1].values
y = df[0].values
X_train_raw,X_test_raw,y_train,y_test=train_test_split(X,y)
vectorizer = TfidfVectorizer()
X_train = vectorizer.fit_transform(X_train_raw)
X_test = vectorizer.transform(X_test_raw) LR = LogisticRegression()
LR.fit(X_train,y_train)
predictions = LR.predict(X_test)
for i,prediction in enumerate(predictions[:5]):
print("预测为 %s ,信件为 %s" % (prediction,X_test_raw[i])) # In[2]二元分类分类指标
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
# predictions 与 y_test
confusion_matrix = confusion_matrix(y_test,predictions)
print(confusion_matrix)
plt.matshow(confusion_matrix)
plt.title("混淆矩阵")
plt.colorbar()
plt.ylabel("真实值")
plt.xlabel("预测值")
plt.show() # In[3] 给出 precision recall f1-score support
from sklearn.metrics import classification_report
print(classification_report(y_test,predictions)) from sklearn.metrics import roc_curve,auc
# 准确率
scores = cross_val_score(LR,X_train,y_train,cv=5)
print("准确率为: ",scores)
print("平均准确率为: ",np.mean(scores)) # 必须要将标签转为数值
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
y_train_n = class_le.fit_transform(y_train)
y_test_n = class_le.fit_transform(y_test) # 精准率
precision = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='precision')
print("平均精准率为: ",np.mean(precision))
# 召回率
recall = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='recall')
print("平均召回率为: ",np.mean(recall))
# F1值
f1 = cross_val_score(LR,X_train,y_train_n,cv=5,scoring='f1')
print("平均F1值为: ",np.mean(f1)) # In[4] ROC曲线 y_test_n为数值
predictions_pro = LR.predict_proba(X_test)
false_positive_rate, recall, thresholds = roc_curve(y_test_n,predictions_pro[:,1])
roc_auc = auc(false_positive_rate, recall)
plt.title("受试者操作特征曲线(ROC)")
plt.plot(false_positive_rate, recall, 'b', label='AUC = % 0.2f' % roc_auc)
plt.legend(loc='lower right')
plt.plot([0,1],[0,1],'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.xlabel('假阳性率')
plt.ylabel('召回率')
plt.show()
scikit-learn机器学习(二)逻辑回归进行二分类(垃圾邮件分类),二分类性能指标,画ROC曲线,计算acc,recall,presicion,f1的更多相关文章
- 机器学习二 逻辑回归作业、逻辑回归(Logistic Regression)
机器学习二 逻辑回归作业 作业在这,http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/hw2.pdf 是区分spam的. 57 ...
- 通俗地说逻辑回归【Logistic regression】算法(二)sklearn逻辑回归实战
前情提要: 通俗地说逻辑回归[Logistic regression]算法(一) 逻辑回归模型原理介绍 上一篇主要介绍了逻辑回归中,相对理论化的知识,这次主要是对上篇做一点点补充,以及介绍sklear ...
- 100天搞定机器学习|Day8 逻辑回归的数学原理
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day4-6 逻辑回归
逻辑回归avik-jain介绍的不是特别详细,下面再唠叨一遍这个算法. 1.模型 在分类问题中,比如判断邮件是否为垃圾邮件,判断肿瘤是否为阳性,目标变量是离散的,只有两种取值,通常会编码为0和1.假设 ...
- 机器学习之分类器性能指标之ROC曲线、AUC值
分类器性能指标之ROC曲线.AUC值 一 roc曲线 1.roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性 ...
- [机器学习]-分类问题常用评价指标、混淆矩阵及ROC曲线绘制方法
分类问题 分类问题是人工智能领域中最常见的一类问题之一,掌握合适的评价指标,对模型进行恰当的评价,是至关重要的. 同样地,分割问题是像素级别的分类,除了mAcc.mIoU之外,也可以采用分类问题的一些 ...
- 【机器学习】逻辑回归(Logistic Regression)
注:最近开始学习<人工智能>选修课,老师提纲挈领的介绍了一番,听完课只了解了个大概,剩下的细节只能自己继续摸索. 从本质上讲:机器学习就是一个模型对外界的刺激(训练样本)做出反应,趋利避害 ...
- 机器学习 (三) 逻辑回归 Logistic Regression
文章内容均来自斯坦福大学的Andrew Ng教授讲解的Machine Learning课程,本文是针对该课程的个人学习笔记,如有疏漏,请以原课程所讲述内容为准.感谢博主Rachel Zhang 的个人 ...
- 机器学习:逻辑回归(OvR 与 OvO)
一.基础理解 问题:逻辑回归算法是用回归的方式解决分类的问题,而且只可以解决二分类问题: 方案:可以通过改造,使得逻辑回归算法可以解决多分类问题: 改造方法: OvR(One vs Rest),一对剩 ...
随机推荐
- SP116 INTERVAL - Intervals
题意翻译 区间取数 题目描述 有n个区间,在区间[ai,bi]中至少取任意互不相同的ci个整数.求在满足n个区间的情况下,至少要取多少个正整数. 输入输出格式 输入格式 多组数据. 第一行的一个整数T ...
- 太白金星的考验----python while循环的执着
我们知道 while循环的使用意味着 反复的执行一些操作,而且在while循环体中 从第一行代码执行到最后一行代码,(请您务必留心这句话!) 直到不再满足while后面给出的限定条件,才结束循环跳出到 ...
- hibernate配置和映射文件
映射文件 <?xml version="1.0" encoding="utf-8"?><!DOCTYPE hibernate-mapping ...
- 使用jdk自带的线程池。加载10个线程。
在开发中使用线程,经常不经意间就new Thread()一个出来,然后发现,这样做不是很好,特别是很多线程同时处理的时候,会出现CPU被用光导致机器假死,线程运行完成自动销毁后,又复活的情况. 所以在 ...
- 002转载----C# 基于OneNet 的物联网数据通信
作者:lnwin521 来源:CSDN 原文:https://blog.csdn.net/lnwin521/article/details/84549606 (遇到404情况请复制粘贴后再打开)版权声 ...
- controller层直接通过server类调用mapper的通用方法
自己写的方法没有,但是逆向生成的server类会有继承maybatis-plus的框架 与下图的配置有关
- [Luogu] 矩形覆盖
https://www.luogu.org/problemnew/show/P1034 数据太水 爆搜过掉 #include <iostream> #include <cstdio& ...
- 8月清北学堂培训 Day4
今天上午是赵和旭老师的讲授~ 概率与期望 dp 概率 某个事件 A 发生的可能性的大小,称之为事件 A 的概率,记作 P ( A ) . 假设某事的所有可能结果有 n 种,每种结果都是等概率,事件 A ...
- masm 编译贪吃蛇游戏
code: ;TITLE GAME4TH PAGE , STSEG SEGMENT DB DUP () STSEG ENDS ;----------------------------------- ...
- IntelliJ IDEA 设置忽略SVN文件和文件夹
IntelliJ IDEA 在提交文件至SVN时,可以设置忽略某些文件和文件夹,以免误提交不需要提交的文件.最后,插个题外话,介绍一下如何设置代码默认折叠或者展开.下面使用IntelliJ ID ...