MySQL原理解析
逻辑架构
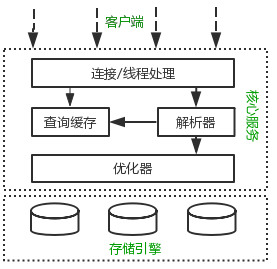
MySQL逻辑架构整体分为三层:
- 客户端层,连接处理、授权认证、安全等功能均在这一层处理。
- 核心服务层,包括查询解析、分析、优化、缓存、内置函数(比如:时间、数学、加密等函数)。所有的跨存储引擎的功能也在这一层实现:存储过程、触发器、视图等。
- 存储引擎,其负责MySQL中的数据存储和提取。和Linux下的文件系统类似,每种存储引擎都有其优势和劣势。中间的服务层通过API与存储引擎通信,这些API接口屏蔽了不同存储引擎间的差异
存储引擎
主要介绍InnoDB引擎和MyISAM引擎
InnoDB引擎:
- 将数据存储在表空间中,表空间由一系列的数据文件组成,由InnoDB管理;
- 支持每个表的数据和索引存放在单独文件中(innodb_file_per_table);
- 支持事务,采用MVCC来控制并发,并实现标准的4个事务隔离级别,支持外键;
- 索引基于聚簇索引建立,对于主键查询有较高性能;
- 数据文件的平台无关性,支持数据在不同的架构平台移植;
- 能够通过一些工具支持真正的热备。如XtraBackup等;
- 内部进行自身优化如采取可预测性预读,能够自动在内存中创建hash索引等。
MyISAM引擎:
- 不支持事务和行级锁;
- 提供大量特性如全文索引、空间函数、压缩、延迟更新等;
- 数据库故障后,安全恢复性差;
- 对于只读数据可以忍受故障恢复,MyISAM依然非常适用;
- 日志服务器的场景也比较适用,只需插入和数据读取操作;
- 不支持单表一个文件,会将所有的数据和索引内容分别存在两个文件中;
- MyISAM对整张表加锁而不是对行,所以不适用写操作比较多的场景;
- 支持索引缓存不支持数据缓存。
查询过程
我们希望通过MySQL可以获得更好的查询性能,最好的方式就是弄清楚MySQL是如何执行查询的,理解了这一点,我们可以依据它的规则去优化SQL语句。
当向MySQL发送一个SQL请求的时候,究竟发生了什么呢,如下:

客户端/服务端通信协议
1、MySQL客户端/服务端通信协议是半双工的:在任一时刻,要么是服务器向客户端发送数据,要么是客户端向服务器发送数据,这两个动作不能同时发生。一旦一端开始发送消息,另一端要接收完整个消息才能响应它,所以我们无法将一个消息切成小块独立发送,也没有办法进行流量控制。
2、客户端用一个单独的数据包将查询请求发送给服务器,所以当查询语句很长的时候,需要设置max_allowed_packet参数。但是需要注意的是,如果查询实在是太大,服务端会拒绝接收更多数据并抛出异常。
3、服务器响应给用户的数据通常会很多,由多个数据包组成。但是当服务器响应客户端请求时,客户端必须完整的接收整个返回结果,而不能只取部分结果,然后让服务器停止发送。因而在实际开发中,尽量保持查询简单且只返回必需的数据,减小通信间数据包的大小和数量是一个非常好的习惯,这也是查询中尽量避免使用SELECT *以及加上LIMIT限制的原因之一。
小结:请求语句有大小限制,不应过长;减小通信间数据包大小及通信数量
查询缓存
在解析一个查询语句前,如果查询缓存是打开的,那么MySQL会检查这个查询语句是否命中查询缓存中的数据。如果当前查询恰好命中查询缓存,在检查一次用户权限后直接返回缓存中的结果。这种情况下,查询不会被解析,也不会生成执行计划,更不会执行。
MySQL将缓存存放在一个引用表(类似于HashMap的数据结构),通过一个哈希值索引,这个哈希值通过查询语句、查询的数据库、客户端协议版本号等一些可能影响结果的信息计算得来。所以两个查询在任何字符上的不同(例如:空格、注释),都会导致缓存不会命中。
如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、mysql库中的系统表,其查询结果都不会被缓存。比如函数NOW()或者CURRENT_DATE()会因为不同的查询时间,返回不同的查询结果,再比如包含CURRENT_USER或者CONNECION_ID()的查询语句会因为不同的用户而返回不同的结果,将这样的查询结果缓存起来没有任何的意义。
MySQL的查询缓存系统会跟踪查询中涉及的每个表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。正因为如此,在任何的写操作时,MySQL必须将对应表的所有缓存都设置为失效。如果查询缓存非常大或者碎片很多,这个操作就可能带来很大的系统消耗,甚至导致系统僵死一会儿。
查询缓存对系统的额外消耗不仅仅在写操作,读操作也不例外:
- 任何的查询语句在开始之前都必须经过检查,即使这条SQL语句永远不会命中缓存
- 如果查询结果可以被缓存,那么执行完成后,会将结果存入缓存,也会带来额外的系统消耗基于此,我们要知道并不是什么情况下查询缓存都会提高系统性能,缓存和失效都会带来额外消耗,只有当缓存带来的资源节约大于其本身消耗的资源时,才会给系统带来性能提升。但要如何评估打开缓存是否能够带来性能提升是一件非常困难的事情,也不在本文讨论的范畴内。如果系统确实存在一些性能问题,可以尝试打开查询缓存,并在数据库设计上做一些优化,比如:
- 用多个小表代替一个大表,注意不要过度设计
- 批量插入代替循环单条插入
- 合理控制缓存空间大小,一般来说其大小设置为几十兆比较合适
- 可以通过SQL_CACHE和SQL_NO_CACHE来控制某个查询语句是否需要进行缓存
不要轻易打开查询缓存,特别是写密集型应用。如果一定要开启查询缓存,可以将query_cache_type设置为DEMAND,只有查询语句加入SQL_CACHE的查询才会走缓存,其他查询则不会,这样可以非常自由地控制哪些查询需要被缓存。
语法解析和预处理
MySQL通过关键字将SQL语句进行解析,并且创建内部数据结构解析树,这个过程解析器主要通过语法规则来验证和解析,比如是否使用了错误的关键字,查询的数据表和列是否存在等,然后对其进行各种优化,包括重写查询,决定表的读写顺序,以及选择合适的索引等。用户可以通过特殊的关键字提示(hint)优化器,影响它的决策过程。也可以请求优化器解释(explain)优化过程的各个因素,使用户知道服务器如何进行优化决策的,这个比较实用,尤其是优化某个查询语句时。
MySQL原理解析的更多相关文章
- MySQL查询优化器工作原理解析
手册上查询优化器概述 查询优化器的任务是发现执行SQL查询的最佳方案.大多数查询优化器,包括MySQL的查询优化器,总或多或少地在所有可能的查询评估方案中搜索最佳方案.对于联接查询,MySQL优化器所 ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
- GeoHash原理解析
GeoHash 核心原理解析 引子 一提到索引,大家脑子里马上浮现出B树索引,因为大量的数据库(如MySQL.oracle.PostgreSQL等)都在使用B树.B树索引本质上是对索引字段 ...
- 秋色园QBlog技术原理解析:性能优化篇:缓存总有失效时,构造持续的缓存方案(十四)
转载自:http://www.cyqdata.com/qblog/article-detail-38993 文章回顾: 1: 秋色园QBlog技术原理解析:开篇:整体认识(一) --介绍整体文件夹和文 ...
- pt-online-schema-change原理解析(转)
pt-online-schema-change原理解析 博客相关需要阅读 - zengkefu - 博客园 .pt-online-schema-change工具的使用限制: ).如果修改表有外键,除非 ...
- Mysql 原理以及常见mysql 索引等
## 主键 超键 候选键 外键 (mysql数据库常见面试题) 数据库之互联网常用架构方案 数据库之互联网常用分库分表方案 分布式事务一致性解决方案 MySQL Explain详解 ## 数据库事务的 ...
- 6_1.springboot2.x整合JDBC与数据源配置原理解析
1.引言 对于数据访问层,无论是SQL还是NOSQL,Spring Boot默认采用整合 Spring Data的方式进行统一处理,添加大量自动配置,屏蔽了很多设置.引入各种xxxTemplate,x ...
- [原][Docker]特性与原理解析
Docker特性与原理解析 文章假设你已经熟悉了Docker的基本命令和基本知识 首先看看Docker提供了哪些特性: 交互式Shell:Docker可以分配一个虚拟终端并关联到任何容器的标准输入上, ...
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
随机推荐
- Docker 启动 Mongo
参考:https://hub.docker.com/_/mongo 1,运行这个 docker run --name some-mongo -d mongo 2.进入控制台 docker exec - ...
- Python爬取爱奇艺资源
像iqiyi这种视频网站,现在下载视频都需要下载相应的客户端.那么如何不用下载客户端,直接下载非vip视频? 选择你想要爬取的内容 该安装的程序以及运行环境都配置好 下面这段代码就是我在爱奇艺里搜素“ ...
- git遇到的问题记录2019.05.07
用sourcetree拉取代码,报错如下: error: cannot lock ref 'refs/remotes/origin/my_branch': unable to resolve refe ...
- 移植 Linux 内核
目录 更新记录 1.Linux 版本及特点 2.打补丁.编译.烧写.启动内核 3.内核源码文件结构 4.内核架构分析 4.1 内核配置 4.2 Makefile架构分析 4.3 Kconfig 架构文 ...
- eureka解析hostname为localhost问题 (转)
https://blog.csdn.net/liufei198613/article/details/79583686 公司的springcloud已经上线运行,但是最近测试环境老是会出现一个诡异的问 ...
- netstat用法详解
netstat用法详解 知识,netstat用法详解 图片 netstat用法详解 内容,netstat用法详介绍,netstat用法详正文 netstat命令是一个监控TCP/IP网络的非常有用的工 ...
- Js-带进度条的轮播图
带进度条的轮播图--原生JS实现 实现了图片自动轮播,左右按钮实现图片左右转换,下方原点或者缩小图点击选择其中的某一张图片,然后有红条实现图片的进度. <div class="cont ...
- idea代码爆红,clean,或者maven reimport都不起作用
1 突然自己的idea的Maven项目代码都是爆红,但是可以运行,添加新的代码确无法运行 尝试了clean,或者reimport,甚至是大家推荐的,刷新缓存重启也没有作用 2 检查项目的jdk配置,也 ...
- linux入门常用指令1.配置本地yum源
创建光盘挂载点 [root@localhost /]# mkdir /mnt/cdrom 挂载光盘 #挂载光盘 [root@localhost /]# mount /dev/cdrom /mnt/cd ...
- CodeForces - 1221E Game With String 分类讨论
首先分析A能获胜的情况 A能获胜 当且仅当A拿完后所有剩下的都<b 所以一旦存在一个大小为X的 且 b<=X<a 则必是后手赢 当X为 a<=x<2*b 的时候 无论A或 ...