MySQL数据库表的设计和优化(上)
一、单表设计与优化:
(1)设计规范化表,消除数据冗余(以使用正确字段类型最明显):
数据库范式是确保数据库结构合理,满足各种查询需要、避免数据库操作异常的数据库设计方式。满足范式要求的表,称为规范化表,范式产生于20世纪70年代初,一般表设计满足前三范式就可以,在这里简单介绍一下前三范式。 第一范式(1NF)无重复的列
所谓第一范式(1NF)是指在关系模型中,对域添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。 第二范式(2NF)属性
在1NF的基础上,非码属性必须完全依赖于码[在1NF基础上消除非主属性对主码的部分函数依赖] 第三范式(3NF)属性
在1NF基础上,任何非主属性不依赖于其它非主属性[在2NF基础上消除传递依赖。 通俗点讲:
第一范式:
属性(字段)的原子性约束,要求属性具有原子性,不可再分割; 第二范式:
记录的惟一性约束,要求记录有惟一标识,每条记录需要有一个属性来做为实体的唯一标识,即每列都要和主键相关。 第三范式:
属性(字段)冗余性的约束,即任何字段不能由其他字段派生出来,在通俗点就是:主键没有直接关系的数据列必须消除(消除的办法就是再创建一个表来存放他们,当然外键除外)。即:确保每列都和主键列直接相关,而不是间接相关。 如果数据库设计达到了完全的标准化,则把所有的表通过关键字连接在一起时,不会出现任何数据的复本(repetition)。标准化的优点是明显的,它避免了数据冗余,自然就节省了空间,也对数据的一致性(consistency)提供了根本的保障,杜绝了数据不一致的现象,同时也提高了效率。 尤其是正确字段类型的选择: 所有字段类型:
(一)整型数值:

(二)浮点数类型

(三)定点数类型

关于浮点数与定点数有点看法:
浮点数相对于定点数的优点是在长度一定的情况下,浮点数能够表示更大的数据范围;它的缺点是会引起精度问题。
使用时我们要注意:
1. 浮点数存在误差问题;
2. 对货币等对精度敏感的数据,应该用定点数表示或存储;
3. 编程中,如果用到浮点数,要特别注意误差问题,并尽量避免做浮点数比较;
4. 要注意浮点数中一些特殊值的处理。
(四)位类型

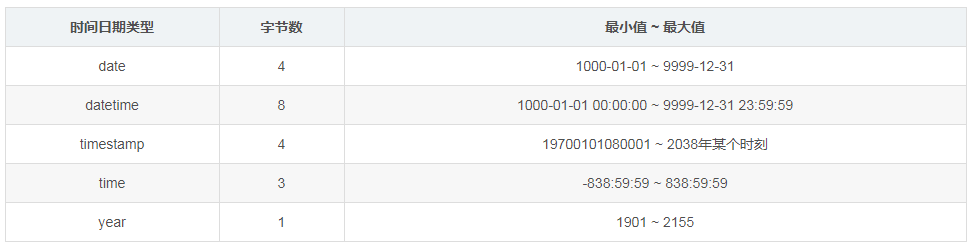
(五)日期时间类型(mysql中用now()写入当前时间)
(六)字符串类型:

针对常用的varchar,我们来思考几个问题:
1)varchar的长度?
MySQL的文档,其中对varchar字段类型这样描述:varchar(m) 变长字符串。m 表示最大列长度。m的范围是0到65,535。(VARCHAR的最大实际长度由最长的行的大小和使用的字符集确定,最大有效长度是65,532字节)。 mysql varchar(50) 不管中文 还是英文 都是存50个的,但是一个表中所有varchar字段的总长度跟编码有关,如果是utf-8,那么大概65535/3,如果是gbk,那么大概65535/2. 2)存储限制?编码长度限制?行长度限制?超出了,会变成怎样?
针对第一个问题:varchar 字段是将实际内容单独存储在聚簇索引之外,实际存储从第二个字节开始,接着要用1到2个字节表示实际长度(长度超过255时需要2个字节),因此最大长度不能超过65535。 针对第二个问题:字符类型若为gbk,每个字符最多占2个字节。字符类型若为utf8,每个字符最多占3个字节。 针对第三个问题:导致实际应用中varchar长度限制的是一个行定义的长度。 MySQL要求一个行的定义长度不能超过65535。若定义的表长度超过这个值,则提示 ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. You have to change some columns to TEXT or BLOBs。
1
针对第四个问题:若定义的时候超过上述限制,则varchar字段会被强行转为text类型,并产生warning。 3)与char的对比:
CHAR(M)定义的列的长度为固定的,M取值可以为0~255之间,当保存CHAR值时,在它们的右边填充空格以达到指定的长度。当检 索到CHAR值时,尾部的空格被删除掉。在存储或检索过程中不进行大小写转换。CHAR存储定长数据很方便,CHAR字段上的索引效率级高,比如定义 char(10),那么不论你存储的数据是否达到了10个字节,都要占去10个字节的空间,不足的自动用空格填充。 CHAR和VARCHAR最大的不同就是一个是固定长度,一个是可变长度。由于是可变长度,因此实际存储的时候是实际字符串再加上一个记录 字符串长度的字节(如果超过255则需要两个字节)。如果分配给CHAR或VARCHAR列的值超过列的最大长度,则对值进行裁剪以使其适合。如果被裁掉 的字符不是空格,则会产生一条警告。如果裁剪非空格字符,则会造成错误(而不是警告)并通过使用严格SQL模式禁用值的插入。 4)char、varchar与text的建议:
TEXT只能储存纯文本文件。 效率来说基本是char>varchar>text,但是如果使用的是Innodb引擎的话,推荐使用varchar代替char char和varchar可以有默认值,text不能指定默认值 以下给出几个类型选取建议
(一)数字类型:
1)不到不要使用DOUBLE,不仅仅只是存储长度的问题,同时还会存在精确性的问题。
2)固定精度的小数,也不建议使用DECIMAL
建议乘以固定倍数转换成整数存储,可以大大节省存储空间,且不会带来任何附加维护成本。
3)对于整数的存储,在数据量较大的情况下,建议区分开 TINYINT / INT / BIGINT 的选择
因为三者所占用的存储空间也有很大的差别,能确定不会使用负数的字段,建议添加unsigned定义。当然,如果数据量较小的数据库,也可以不用严格区分三个整数类型。
4)对于整型数值,mysql支持在类型名称后面的小括号内指定显示宽度
例如int(5)表示当数值宽度小于5位时候在数值前面填满宽度,一般配合zerofill属性使用。如果一个列指定为zerofill,则MySQL自动为该列添加unsigned属性。
5)在数据量较大时、建议把实数类型转为整数类型。
原因很简单:1. 浮点不精确;2.定点计算代价昂贵。例如:要存放财务数据精确到万分之一、则可以把所有金额乘以一百万、然后存在BIGINT下。 (二)字符类型:
1)尽量不要使用 TEXT 数据类型,其处理方式决定了他的性能要低于char或者是varchar类型的处理。
定长字段,建议使用 CHAR 类型,不定长字段尽量使用 VARCHAR,且仅仅设定适当的最大长度,而不是非常随意的给一个很大的最大长度限定,因为不同的长度范围,MySQL也会有不一样的存储处理。
2)char会删除字符串尾部的空格,varchar不会,varchar向前补1-2字节;char定长。binary类似于char,binary只能保存二进制字符串。
char是固定长度,所以它的处理速度比varchar快得多,但缺点是浪费存储空间,不能在行尾保存空格。在MySQL中,MyISAM建议使用固定长度代替可变长度列;InnoDB建议使用varchar类型,因为在InnoDB中,内部行存储格式没有区分固定长度和可变长度。
3)enum类型忽略大小写。
4)text与blob区别:
blob保存二进制数据;text保存字符数据,有字符集。text和blob不能有默认值。 应用:text与blob主要区别是text用来保存字符数据(如文章,日记等),blob用来保存二进制数据(如照片等)。blob与text在执行了大量删除操作时候,有性能问题(产生大量的“空洞“),为提高性能建议定期optimize table 对这类表进行碎片整理。
关于text与blob我们有些看法建议:
BLOB和TEXT值也会引起自己的一些问题,特别是执行了大量的删除或更新操作的时候。删除这种值会在数据表中留下很大的"空洞",以后填入这些"空洞"的记录可能长度不同,为了提高性能,建议定期使用 OPTIMIZE TABLE 功能对这类表进行碎片整理.
在不必要的时候避免检索大型的BLOB或TEXT值。
把BLOB或TEXT列分离到单独的表中。在某些环境中,如果把这些数据列移动到第二张数据表中,可以让你把原数据表中 的数据列转换为固定长度的数据行格式,那么它就是有意义的。这会减少主表中的碎片,使你得到固定长度数据行的性能优势。它还使你在主数据表上运行 SELECT *查询的时候不会通过网络传输大量的BLOB或TEXT值。 (三)时间类型:
1)尽量使用TIMESTAMP类型
因为其存储空间只需要 DATETIME 类型的一半。对于只需要精确到某一天的数据类型,建议使用DATE类型,因为他的存储空间只需要3个字节,比TIMESTAMP还少。不建议通过INT类型类存储一个unix timestamp 的值,因为这太不直观,会给维护带来不必要的麻烦,同时还不会带来任何好处。
2)根据实际需要选择能够满足应用的最小存储日期类型。
3)timestamp,日期类型中只有它能够和实际时区相对应。
(四)ENUM & SET:
对于状态字段,可以尝试使用 ENUM 来存放,因为可以极大的降低存储空间,而且即使需要增加新的类型,只要增加于末尾,修改结构也不需要重建表数据。如果是存放可预先定义的属性数据呢?可以尝试使用SET类型,即使存在多种属性,同样可以游刃有余,同时还可以节省不小的存储空间。 (五)LOB类型:
强烈反对在数据库中存放 LOB 类型数据,虽然数据库提供了这样的功能,但这不是他所擅长的,我们更应该让合适的工具做他擅长的事情,才能将其发挥到极致。 (2)适当的冗余,增加计算列:(实际开发中必须思考的点)
数据库设计的实用原则是:在数据冗余和处理速度之间找到合适的平衡点。
满足范式的表一定是规范化的表,但不一定是最佳的设计。很多情况下会为了提高数据库的运行效率,常常需要降低范式标准:适当增加冗余,达到以空间换时间的目的。比如
我们有一个表,产品名称,单价,库存量,总价值。这个表是不满足第三范式的,因为“总价值”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。但是,增加“总价值”这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。合理的冗余可以分散数据量大的表的并发压力,也可以加快特殊查询的速度,冗余字段可以有效减少数据库表的连接,提高效率。
其中"总价值"就是一个计算列,在数据库中有两种类型:数据列和计算列,数据列就是需要我们手动或者程序给予赋值的列,计算列是源于表中其他的数据计算得来,比如这里的"总价值" 在SQL中创建计算列:
create table goods(
id int auto_increment not null,
c1 int,
c2 int,
c3 int as (c1+c2), //这个就是计算列啦
primary key(id)
) (3)索引的设计:
表优化的重要途径,比如百万级别的表没有索引,注定卡死。
(4)主键和外键的必要性(实际项目开发的重要取舍)
概述:
主键与外键的设计,在全局数据库的设计中,占有重要地位。 因为:主键是实体的抽象,主键与外键的配对,表示实体之间的连接。 主键:
根据第二范式,需要有一个字段去标识这条记录,主键无疑是最好的标识,但是很多表也不一定需要主键,但是对于数据量大,查询频繁的数据库表,一定要有主键,主键可以增加效率、防止重复等优点。
主键的选择也比较重要,一般选择总的长度小的键,小的键的比较速度快,同时小的键可以使主键的B树结构的层次更少。 主键的选择还要注意组合主键的字段次序,对于组合主键来说,不同的字段次序的主键的性能差别可能会很大,一般应该选择重复率低、单独或者组合查询可能性大的字段放在前面。 外键:
外键作为数据库对象,很多人认为麻烦而不用,实际上,外键在大部分情况下是很有用的,理由是:外键是最高效的一致性维护方法。 数据库的一致性要求,依次可以用外键、CHECK约束、规则约束、触发器、客户端程序,一般认为,离数据越近的方法效率越高。但是!!!要谨慎使用级联删除和级联更新,因为级联删除和级联更新有些突破了传统的关于外键的定义,功能有点太过强大,使用前必须确定自己已经把握好其功能范围,否则,级联删除和级联更新可能让你的数据莫名其妙的被修改或者丢失。从性能看级联删除和级联更新是比其他方法更高效的方法。 实际项目中的主外键取舍设计:(在性能和可扩展性之间寻求平衡)
边缘模块指的是小功能不常用需求很少再改的模块;中心模块是指关联的东西太多的模块、是很多表的主表;物理键指的是在表建立主外键关联,逻辑主外键指的是利用字段去实现逻辑主外键关联;热点模块指的是需求经常要改的模块 大型系统:
针对性能要求不高,安全要求高的模块,推荐使用物理主外键关联;针对性能要求高、安全自己控制的模块,推荐不用物理外键;
针对中心模块和其他模块的联系,推荐使用物理主外键。
针对热点模块,必须使用逻辑主外键
针对边缘模块,推荐使用物理主外键 小系统:
随便你啦,也就是20张表以下的系统。逻辑不复杂都无所谓啦,不过推荐还是使用外键。 注意:
不用外键而用程序控制数据一致性和完整性时,应该写一层来保证,然后个个应用通过这个层来访问数据库。
外键是有性能问题的,不能过分追求。 (5)存储过程、视图、函数的适当使用 :
很多人习惯将复杂操作都放在应用程序层,但如果你要优化数据访问性能,将SQL代码移植到数据库上(使用存储过程,视图,函数和触发器)也是一个很大的改进原因如下: 1)存储过程减少了网络传输、处理及存储的工作量,且经过编译和优化,执行速度快,易于维护,且表的结构改变时,不影响客户端的应用程序
2)使用存储过程,视图,函数有助于减少应用程序中SQL复制的弊端,因为现在只在一个地方集中处理SQL
3)使用数据库对象实现所有的TSQL有助于分析TSQL的性能问题,同时有助于你集中管理TSQL代码,更好的重构TSQL代码。
(6)传说中的‘三少原则’:
1)数据库的表越少越好
2)表的字段越少越好
3)字段中的组合主键、组合索引越少越好
这里的少是相对的,是减少数据冗余的重要设计理念而已。
实际上,我们为了减少单表查询压力,会把去分表,从而分发记录量,避免一个超级表的诞生。 (7)分割你的表,减小表尺寸
如果你发现某个表的记录太多,例如超过一千万条,则要对该表进行水平分割。水平分割的做法是,以该表主键的某个值为界线,将该表的记录水平分割为两个表。
如果你若发现某个表的字段太多,例如超过八十个,则垂直分割该表,将原来的一个表分解为两个表 (8)字段设计原则:
字段是数据库最基本的单位,其设计对性能的影响是很大的。需要注意如下:
1)数据类型尽量用数字型,数字型的比较比字符型的快很多。
2)数据类型尽量小,这里的尽量小是指在满足可以预见的未来需求的前提下的。
3)尽量不要允许NULL,除非必要,可以用NOT NULL+DEFAULT代替。
NULL 类型比较特殊,SQL 难优化。虽然 MySQL NULL类型和 Oracle 的NULL 有差异,会进入索引中,但如果是一个组合索引,那么这个NULL 类型的字段会极大影响整个索引的效率。此外,NULL 在索引中的处理也是特殊的,也会占用额外的存放空间。
4)少用TEXT和IMAGE,二进制字段的读写是比较慢的,而且,读取的方法也不多,大部分情况下最好不用。
5)自增字段要慎用,不利于数据迁移
MySQL数据库表的设计和优化(上)的更多相关文章
- MySQL数据库表的设计和优化(下)
二.基于单表设计的多表设计原则:(1)表关系: 一)一对一关系: 定义: 在这种关系中,关系表的每一边都只能存在一个记录.每个数据表中的关键字在对应的关系表中只能存在一个记录或者没有对应的记录.这种关 ...
- 「mysql优化专题」优化之路高级进阶——表的设计及优化(6)
正文:表的设计及优化(真技术文) 优化①:创建规范化表,消除数据冗余 数据库范式是确保数据库结构合理,满足各种查询需要.避免数据库操作异常的数据库设计方式.满足范式要求的表,称为规范化表,范式产生于2 ...
- 6.MySQL优化---高级进阶之表的设计及优化
转自互联网整理. 优化之路高级进阶——表的设计及优化 优化①:创建规范化表,消除数据冗余 数据库范式是确保数据库结构合理,满足各种查询需要.避免数据库操作异常的数据库设计方式.满足范式要求的表,称为规 ...
- Mysql数据库调优和性能优化
1. 简介 在Web应用程序体系架构中,数据持久层(通常是一个关系数据库)是关键的核心部分,它对系统的性能有非常重要的影响.MySQL是目前使用最多的开源数据库,但是mysql数据库的默认设置性能非常 ...
- Mysql数据库调优和性能优化的21条最佳实践
Mysql数据库调优和性能优化的21条最佳实践 1. 简介 在Web应用程序体系架构中,数据持久层(通常是一个关系数据库)是关键的核心部分,它对系统的性能有非常重要的影响.MySQL是目前使用最多的开 ...
- 使用PowerDesigner创建mysql数据库表图
使用PowerDesigner 建数据库表. 一直很忙,没有时间写东西.这次搞点会声会色的,嘿嘿 此技能为项目经理必备技能. 本次主角: 1.在workspace下建立一项目: physical da ...
- 树形结构的数据库表Schema设计-基于左右值编码
树形结构的数据库表Schema设计 程序设计过程中,我们常常用树形结构来表征某些数据的关联关系,如企业上下级部门.栏目结构.商品分类等等,通常而言,这些树状结构需要借助于数据库完 成持久化.然而目前的 ...
- 记一次mysql多表查询(left jion)优化案例
一次mysql多表查询(left jion)优化案例 在新上线的供需模块中,发现某一个查询按钮点击后,出不来结果,找到该按钮对应sql手动执行,发现需要20-30秒才能出结果,所以服务端程序判断超时, ...
- 对mysql数据库表的相关操作
虫师博客(Python使用MySQL数据库(新)): https://www.cnblogs.com/fnng/p/3565912.html 1.更改表的结构,增加一个字段放置新增的属性 alter ...
随机推荐
- vue+webpack4 脚手架搭建
1, vue 中 h => h(App) 的含义: //render: h => h(App) 是下面内容的缩写: render: function (createElement) { r ...
- 05-Docker私有仓库
一.介绍私有仓库顾名思义,如果我们不想把docker镜像公开放到公有仓库中,只想在部门或团队内部共享docker镜像,这时私有仓库就来了. 二.私有仓库搭建与配置1.拉取私有仓库镜像,这里说明一下,私 ...
- 【xsy1301】 原题的价值 组合数+斯特林数+FFT
题目大意:求$n\times2^{\frac{(n-1)(n-2)/2}{2}}\sum\limits_{i=0}^{n-1}\dbinom{n-1}{i}i^k$ 数据范围:$n≤10^9$,$k≤ ...
- RMQ问题【模板】
概念 RMQ 是英文 Range Maximum/Minimum Query 的缩写,表示区间最大(最小)值. 解决 RMQ 问题的主要方法有两种,分别是 ST 表和线段树.本文主要讲 ST 表. S ...
- TensorFlow(四):手写数字识别
一:数据集 采用MNIST数据集:-->官网 数据集被分成两部分:60000行的训练数据集和10000行的测试数据集. 其中每一张图片包含28*28个像素,我们把这个数组展开成一个向量,长度为2 ...
- php curl 传递数据
<?php header("Content-type: text/html; charset=utf-8"); /** * curl 传递数据 */ class curl { ...
- 内存分析工具 MAT 的使用【转】
转自:http://blog.csdn.net/aaa2832/article/details/19419679/ 1 内存泄漏的排查方法 Dalvik Debug Monitor Server (D ...
- CF463E Caisa and Tree
要是你们能和我一样看错题目意思误认为是要求互质的就舒服了. 考虑修改很少,所以修改完之后可以暴力遍历树. 那么现在问题转换成了如何求一个点的答案,直接把所有质因子存下来然后用\(set\)维护即可. ...
- エンジニア死滅シタ世界之荒れ果てたショップ [MISSION LEVEL: C] -Python3答案
题目 题目要求输入三个数字,半角空格间隔开.格式N A B 条件 ・1 ≦ N ≦ 9 ・0 ≦ A ≦ B ≦ 5000 ・(B的位数) ≦ N 输出A到B包括AB之间的所有数,如果数字的位数不够N ...
- 4.弹性网络( Elastic Net)
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/qq_21904665/article/details/52315642 ElasticNet 是一种 ...