JVM 和 GC
一 堆与非堆
二 常见配置汇总
1 堆设置
2 收集器设置
3 垃圾回收统计信息
4 并行收集器设置
5 并发收集器设置
三 JVM调优总结(如何规避频繁gc)
四 Java内存划分
在Java运行时的数据区里,由JVM管理的内存区域分为下图几个模块:

1) 程序计数器(Program Counter Register)
程序计数器是一个比较小的内存区域, 用于指示当前线程所执行的字节码执行到了第几行, 可以理解为是当前线程的行号指示器. 字节码解释器在工作时, 会通过改变这个计数器的值来取下一条语句指令. 每个程序计数器只用来记录一个线程的行号, 所以它是线程私有的.
如果程序执行的是一个Java方法, 则计数器记录的是正在执行的虚拟机字节码指令地址; 如果正在执行的是一个本地native方法, 则计数器的值为undefined. 由于程序计数器指示记录当前指令地址, 所以不存在内存溢出的情况. 因此, 程序计数器也是所有JVM内存区域中唯一一个没有定义OutOfMemoryError的区域。
2) 虚拟机栈(JVM Stack)
一个线程的每个方法执行时都会创建一个栈帧(Stack Frame), 栈帧中存储的有局部变量表、操作栈、动态链接、方法出口等。当方法被调用时,栈帧在JVM栈中入栈,当方法执行完成时,栈帧出栈。
局部变量表中存储着方法的相关局部变量,包括各种基本数据类型,对象的引用,返回地址等。在局部变量表中,只有long和double类型会占用2个局部变量空间(Slot,对于32位机器,一个Slot就是32个bit), 其它都是1个Slot。需要注意的是,局部变量表是在编译时就已经确定好的,方法运行所需要分配的空间在栈帧中是完全确定的,在方法的生命周期内都不会改变。
虚拟机栈中定义了两种异常,如果线程调用的栈深度大于虚拟机允许的最大深度,则抛出StatckOverFlowError;不过多数Java虚拟机都允许动态扩展虚拟机栈的大小,所以线程可以一直申请栈,直到内存不足,此时会抛出 OutOfMemoryError。每个线程对应着一个虚拟机栈,因此虚拟机栈也是线程私有的
3) 本地方法栈(Native Method Statck)
本地方法栈在作用和运行机制等方面都与虚拟机栈相同,唯一的区别是:虚拟机栈是执行Java方法的,而本地方法栈是用来执行native方法的,在很多虚拟机中(如Sun的JDK默认的HotSpot虚拟机),会将本地方法栈与虚拟机栈放在一起使用。
4)堆区(Heap)
堆区是理解Java GC机制最重要的区域,没有之一。在JVM所管理的内存中,堆区是最大的一块,堆区也是Java GC机制所管理的主要内存区域,堆区由所有线程共享,在虚拟机启动时创建。堆区的存在是为了存储对象实例,原则上讲,所有的对象都在堆区上分配内存. 根据Java虚拟机规范规定,堆内存需要在逻辑上是连续的(在物理上不需要),在实现时,可以是固定大小的,也可以是可扩展的,目前主流的虚拟机都是可扩展的。如果在执行垃圾回收之后,仍没有足够的内存分配,也不能再扩展,将会抛出OutOfMemoryError:Java heap space异常。
5)方法区(Method Area)
在Java虚拟机规范中,将方法区作为堆的一个逻辑部分来对待,但事实上,方法区并不是堆(Non-Heap);另外,不少人的博客中,将Java GC的分代收集机制分为3个代:年轻代,老年代,永久代,这些作者将方法区定义为“永久代”,这是因为,对于之前的HotSpot Java虚拟机的实现方式中,将分代收集的思想扩展到了方法区,并将方法区设计成了永久代。不过,除HotSpot之外的多数虚拟机,并不将方法区当做永久代,HotSpot本身,也计划取消永久代。本文中,仍将使用永久代一词。
方法区是各个线程共享的区域,用于存储已经被虚拟机加载的类信息(即加载类时需要加载的信息,包括版本、field、方法、接口等信息)、final常量、静态变量、编译器即时编译的代码等。
方法区在物理上也不需要是连续的,可以选择固定大小或可扩展大小,并且方法区比堆还多了一个限制:可以选择是否执行垃圾收集。一般的,方法区上 执行的垃圾收集是很少的,这也是方法区被称为永久代的原因之一,但这也不代表着在方法区上完全没有垃圾收集,其上的垃圾收集主要是针对常量池的内存回收和对已加载类的卸载。
在方法区上定义了OutOfMemoryError:PermGen space异常,在内存不足时抛出。
运行时常量池是方法区的一部分,用于存储编译期就生成的字面常量、符号引用、翻译出来的直接引用(符号引用就是编码是用字符串表示某个变量、接口的位置,直接引用就是根据符号引用翻译出来的地址,将在类链接阶段完成翻译);运行时常量池除了存储编译期常量外,也可以存储在运行时间产生的常量(比如String类的intern()方法,作用是String维护了一个常量池,如果调用的字符“abc”已经在常量池中,则返回池中的字符串地址,否则,新建一个常量加入池中,并返回地址)。
6)直接内存(Direct Memory):直接内存并不是JVM管理的内存,可以这样理解,直接内存,就是JVM以外的机器内存. 比如,你有4G的内存,JVM占用了1G,则其余的3G就是直接内存,JDK中有一种基于通道(Channel)和缓冲区(Buffer)的内存分配方式,将由C语言实现的native函数库分配在直接内存中,用存储在JVM堆中的DirectByteBuffer来引用。由于直接内存受到本机器内存的限制,所以也可能出现OutOfMemoryError的异常。
五 Java内存分配机制
这里说的内存分配主要指的是在堆上的分配,Java内存分配和回收的机制概括来说就是: 分代分配, 分代回收.
对象将根据存活的时间被分为:年轻代(Young Generation)、年老代(Old Generation)、永久代(Permanent Generation,也就是方法区)
1) 年轻代(Young Generation) 停止-复制(Stop-and-copy)
对象被创建时,内存的分配首先发生在年轻代(大对象可以直接被创建在年老代),大部分的对象在创建后很快就不再使用,因此很快变得不可达,于是被年轻代的GC机制清理掉,这个GC机制被称为Minor GC或叫Young GC。注意,Minor GC并不代表年轻代内存不足,它事实上只表示在Eden区上的GC。
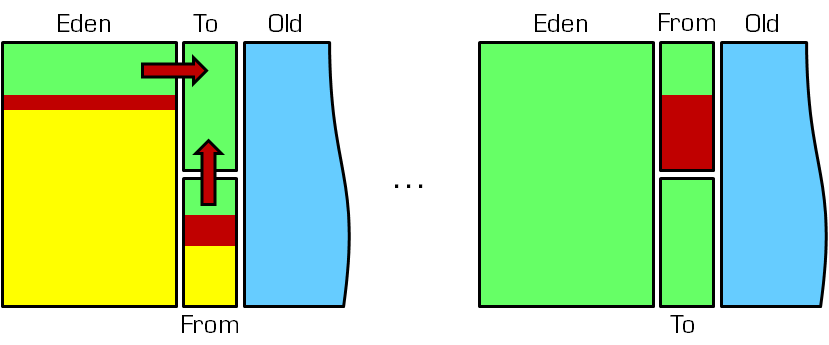
HotSpot JVM把年轻代分为了三部分:1个Eden区和2个Survivor区(分别叫from和to)。默认比例为8:1,为啥默认会是这个比例,接下来我们会聊到。一般情况下,新创建的对象都会被分配到Eden区(一些大对象特殊处理),这些对象经过第一次Minor GC后,如果仍然存活,将会被移到Survivor区。对象在Survivor区中每熬过一次Minor GC,年龄就会增加1岁,当它的年龄增加到一定程度时,就会被移动到年老代中。
因为年轻代中的对象基本都是朝生夕死的(80%以上),所以在年轻代的垃圾回收算法使用的是复制算法,复制算法的基本思想就是将内存分为两块,每次只用其中一块,当这一块内存用完,就将还活着的对象复制到另外一块上面。复制算法不会产生内存碎片。
在GC开始的时候,对象只会存在于Eden区和名为“From”的Survivor区,Survivor区“To”是空的。紧接着进行GC,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值来决定去向。年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到“To”区域。经过这次GC后,Eden区和From区已经被清空。这个时候,“From”和“To”会交换他们的角色,也就是新的“To”就是上次GC前的“From”,新的“From”就是上次GC前的“To”。不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到“To”区被填满,“To”区被填满之后,会将所有对象移动到年老代中。
有关年轻代的JVM参数
1)-XX:NewSize和-XX:MaxNewSize
用于设置年轻代的大小,建议设为整个堆大小的1/3或者1/4,两个值设为一样大。
2)-XX:SurvivorRatio
用于设置Eden和其中一个Survivor的比值,比如是8(hotspot默认是8),即分别占新生代的80%,10%,10%。如果一次回收中,Survivor+Eden中存活下来的内存超过了10%,则需要将一部分对象分配到老年代
3)-XX:+PrintTenuringDistribution
这个参数用于显示每次Minor GC时Survivor区中各个年龄段的对象的大小。
4)-XX:InitialTenuringThreshold 和 -XX:MaxTenuringThreshold
用于设置晋升到老年代的对象年龄的最小值和最大值,每个对象在坚持过一次Minor GC之后,年龄就加1。
在Eden区,HotSpot虚拟机使用了两种技术来加快内存分配。分别是bump-the-pointer和TLAB(Thread-Local Allocation Buffers),这两种技术的做法分别是:由于Eden区是连续的,因此bump-the-pointer技术的核心就是跟踪最后创建的一个对象,在对 象创建时,只需要检查最后一个对象后面是否有足够的内存即可,从而大大加快内存分配速度;而对于TLAB技术是对于多线程而言的,将Eden区分为若干段,每个线程使用独立的一段,避免相互影响。TLAB结合bump-the-pointer技术,将保证每个线程都使用Eden区的一段,并快速的分配内存。
2) 年老代(Old Generation) 标记-整理 标记-清除
对象如果在年轻代存活了足够长的时间没被清理,则会被复制到年老代,年老代的空间一般比年轻代大,能存放更多的对象,在年老代上发生的GC次数也比年轻代少。当年老代内存不足时, 将执行Major GC,也叫 Full GC。
可能存在年老代对象引用新生代对象的情况,如果需要执行Young GC,则可能需要查询整个老年代以确定是否可以清理回收,这显然是低效的。解决的方法是,年老代中维护一个512 byte的块——"card table",所有老年代对象引用新生代对象的记录都记录在这里。Young GC时,只要查这里即可,不用再去查全部老年代,因此性能大大提高。
老年代存储的对象比年轻代多得多,而且不乏大对象,对老年代进行内存清理时,如果使用停止-复制算法,则相当低效。一般,老年代用的算法是标记-整理算法.
永久代的回收有两种:常量池中的常量,无用的类信息,常量的回收很简单,没有引用了就可以被回收。对于无用的类进行回收,必须保证3点:
1 类的所有实例都已经被回收
2 加载类的ClassLoader已经被回收
3 类对象的Class对象没有被引用(即没有通过反射引用该类的地方)
六 垃圾收集器

平时工作中大多数系统都使用CMS、即使静默升级到JDK7默认仍然采用CMS、那么G1相对于CMS的区别在:
- G1在压缩空间方面有优势
- G1通过将内存空间分成区域(Region)的方式避免内存碎片问题
- Eden, Survivor, Old区不再固定、在内存使用效率上来说更灵活
- G1可以通过设置预期停顿时间(Pause Time)来控制垃圾收集时间避免应用雪崩现象
- G1在回收内存后会马上同时做合并空闲内存的工作、而CMS默认是在STW(stop the world)的时候做
- G1会在Young GC中使用、而CMS只能在O区使用
就目前而言、CMS还是默认首选的GC策略、可能在以下场景下G1更适合:
- 服务端多核CPU、JVM内存占用较大的应用(至少大于4G)
- 应用在运行过程中会产生大量内存碎片、需要经常压缩空间
- 想要更可控、可预期的GC停顿周期;防止高并发下应用雪崩现象
七 jdk8 Metaspace元空间的引入
其实,移除永久代的工作从JDK1.7就开始了。JDK1.7中,存储在永久代的部分数据就已经转移到了Java Heap或者是 Native Heap。但永久代仍存在于JDK1.7中,并没完全移除,譬如符号引用(Symbols)转移到了native heap;字面量(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap。我们可以通过一段程序来比较 JDK 1.6 与 JDK 1.7及 JDK 1.8 的区别,以字符串常量为例:
public class StringOomMock {
static String base = "string";
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
for (int i=0;i< Integer.MAX_VALUE;i++){
String str = base + base;
base = str;
list.add(str.intern());
}
}
}
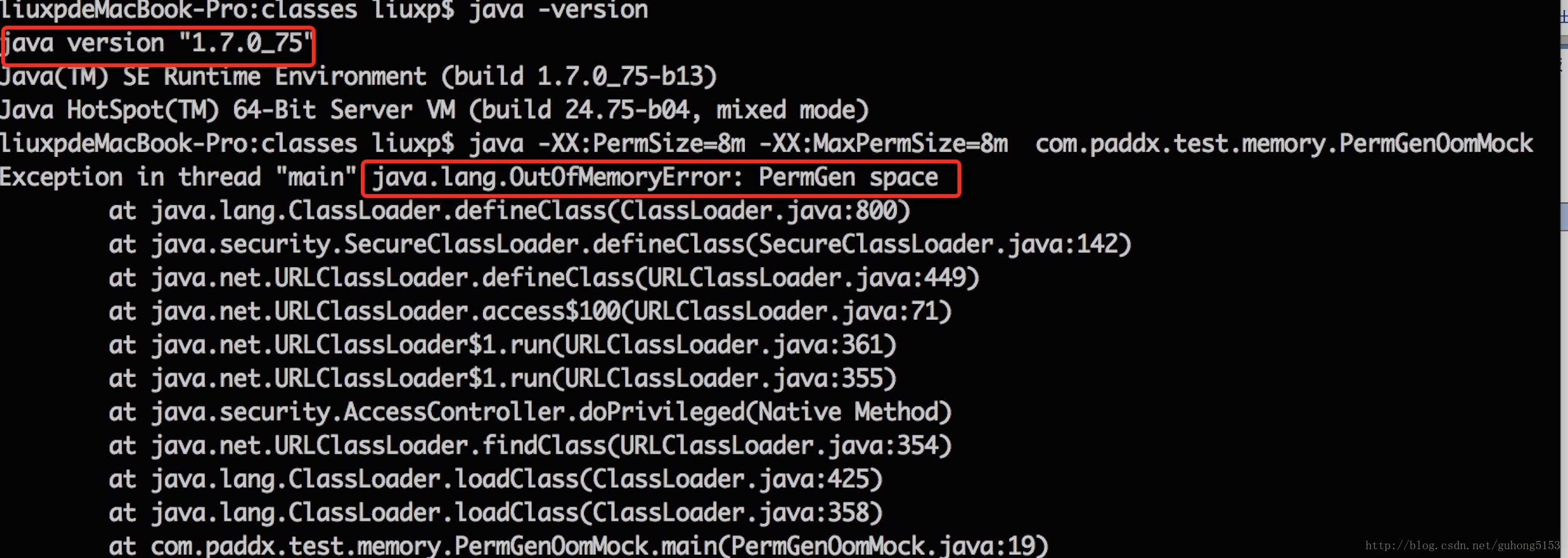
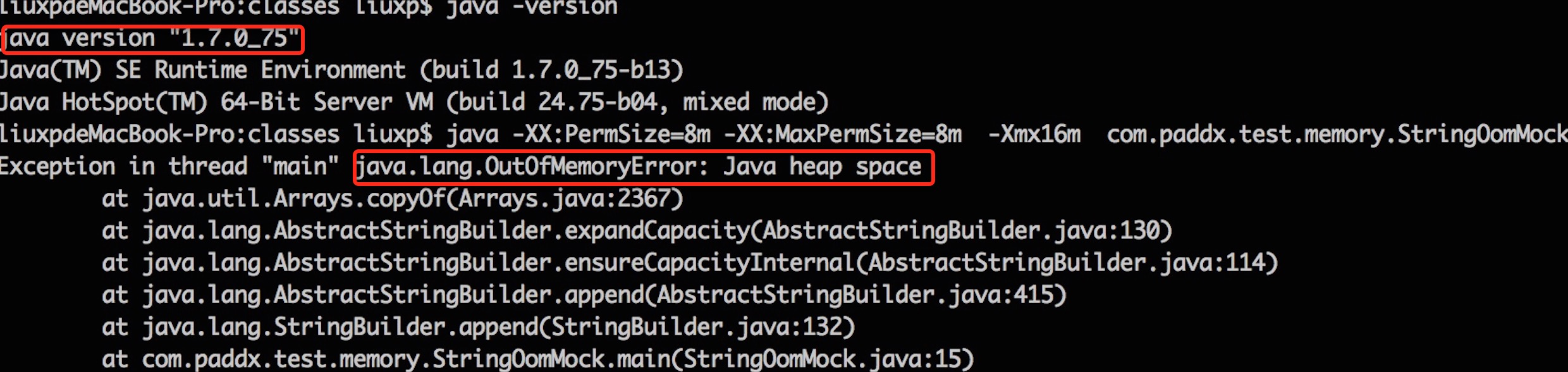
这段程序以2的指数级不断的生成新的字符串,这样可以比较快速的消耗内存。我们通过 JDK 1.6、JDK 1.7 和 JDK 1.8 分别运行:
JDK 1.6 的运行结果:

元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小:
-XX:MetaspaceSize,初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
-XX:MaxMetaspaceSize,最大空间,默认是没有限制的。
除了上面两个指定大小的选项以外,还有两个与 GC 相关的属性:
-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集
-XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为释放空间所导致的垃圾收集
现在我们在 JDK 8下重新运行一下代码段 4,不过这次不再指定 PermSize 和 MaxPermSize。而是指定 MetaSpaceSize 和 MaxMetaSpaceSize的大小。输出结果如下:
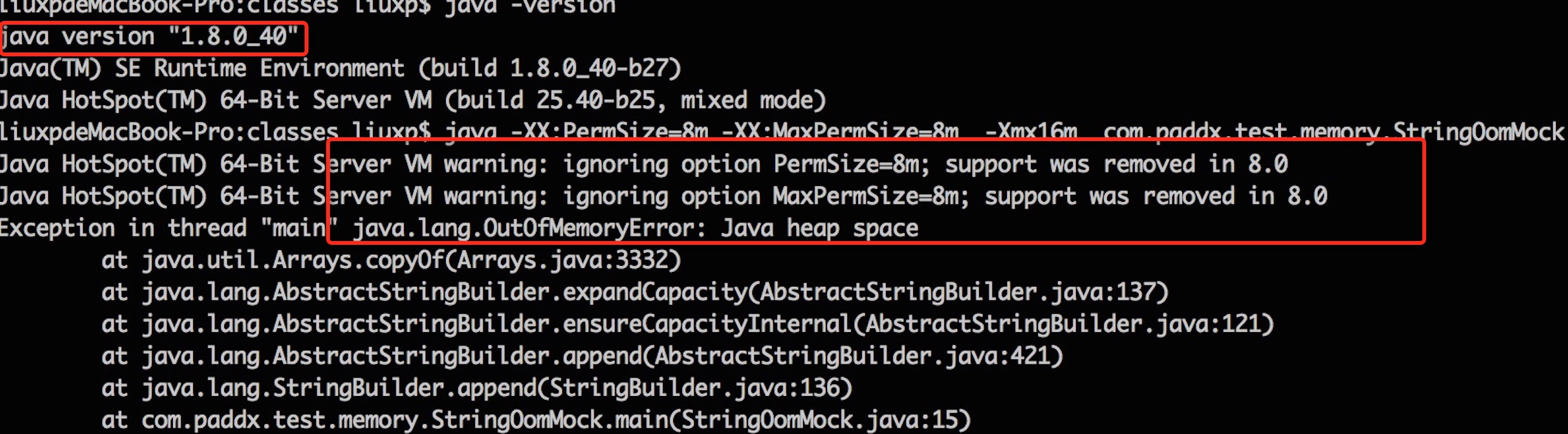
从输出结果,我们可以看出,这次不再出现永久代溢出,而是出现了元空间的溢出。
四、总结
通过上面分析,大家应该大致了解了 JVM 的内存划分,也清楚了 JDK 8 中永久代向元空间的转换。不过大家应该都有一个疑问,就是为什么要做这个转换?所以,最后给大家总结以下几点原因:
1、字符串存在永久代中,容易出现性能问题和内存溢出。
2、类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
3、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
4、Oracle 可能会将HotSpot 与 JRockit 合二为一。
八 shallow heap 和 retained heap的区别
1 shallow size
是对象本身占据的内存的大小,不包含其引用的对象。对于常规对象(非数组)的shadow size由其成员变量的数量和类型来定,而数组的shallow size则是数组元素大小的总和。
2 retained size
Retained Size=当前对象大小 + 当前对象可直接或间接引用到的对象的大小总和。(间接引用的含义:A->B->C,C就是间接引用) ,并且排除被GC Roots直接或者间接引用的对象
换句话说,Retained Size就是当前对象被GC后,从Heap上总共能释放掉的内存。
不过,释放的时候还要排除被GC Roots直接或间接引用的对象。他们暂时不会被被当做Garbage。

GC Roots直接引用了A和B两个对象。
A对象的Retained Size=A对象的Shallow Size
B对象的Retained Size=B对象的Shallow Size + C对象的Shallow Size
栗子
JVM 和 GC的更多相关文章
- JVM的GC概述
JVM的GC概述 GC即垃圾回收,是指jvm用于释放那些不再使用的对象所占用的内存.在充分理解了垃圾收集算法和执行过程后,才能有效的优化它的性能. 有些垃圾收集专用于特殊的应用程序.比如,实时应用程序 ...
- Linux使用jstat命令查看jvm的GC情况
Linux使用jstat命令查看jvm的GC情况 http://www.open-open.com/lib/view/open1390916852007.html http://www.aiuxian ...
- poptest老李谈jvm的GC
poptest老李谈jvm的GC poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨询qq:90882 ...
- Linux使用jstat命令查看jvm的GC情况(转)
B. jstack jstack主要用来查看某个Java进程内的线程堆栈信息.语法格式如下: 1 jstack [option] pid 2 jstack [option] executable co ...
- jvm的GC日志分析 [转]
jvm的GC日志分析 标签: jvm内存javagc 2015-06-22 16:37 1566人阅读 评论(1) 收藏 举报 分类: Java(4) JVM的GC日志的主要参数包括如下几个: ...
- JVM 的GC算法和垃圾收集器
1.标记清除算法 黑色部分代表可回收对象,灰色部分代表存活对象,绿色部分代表未使用的.最基础的收集算法就是标记清除算法如同他名字一样,算法分为"标记"和"清除" ...
- JVM&G1 GC 学习笔记(一)
在入门学习JVM的过程中,我们需要先了解关于JVM的知识中有哪些关键词或关键术语,今天在看完书后我想记录下来. Xms64mb 虚拟机初始化时设置内存大小为64mb Xmx256mb 设定虚拟 ...
- 深入理解JVM+G1+GC.pdf (中文版带书签)
目录 序 VII前言 IX 第1章 JVM & GC基础知识 11.1 引言 21.2 基本术语 31.2.1 Java相关术语 41.2.2 JVM/GC通用术语 241.2.3 G1涉及术 ...
- JVM之GC(二)
昨天总结了GC之前要做的事情,今天介绍一下主流的GC算法. 先介绍一下几个名词: Stop The World(STW):JVM进行GC的时候总不能一边清理垃圾一边制造垃圾把,那么垃圾鉴定的准确性根本 ...
- JVM之GC(一)
Java较C而言,最大的区别在于内存管理.JVM设有无用内存空间自动回收复用机制,也就是我们所说的GC. 之前说过,栈是为线程.为函数的执行分配内存的地方,用完即“销毁”,这里留待以后做深入探讨:堆是 ...
随机推荐
- 【luoguP2827】 蚯蚓
题目描述 本题中,我们将用符号\rfloor⌊c⌋ 表示对 cc 向下取整,例如:\lfloor 3.0 \rfloor = \lfloor 3.1 \rfloor = \lfloor 3.9 \rf ...
- HFUUOJ1024 动态开点线段树+标记永久化
题意 分析 动态加点线段树,标记永久化好写常数小 Code #include<bits/stdc++.h> #define fi first #define se second #defi ...
- linux(centos7)下安装maven
Linux下安装maven 1.首先到Maven官网下载安装文件,目前最新版本为3.0.3,下载文件为apache-maven-3.0.3-bin.tar.gz,下载可以使用yum命令: 2.进入下载 ...
- How to use reminder feature of the outlook
https://support.office.com/en-us/article/set-or-remove-reminders-7a992377-ca93-4ddd-a711-851ef359792 ...
- 487-3279 字符串处理+MAP
487-3279 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 300264 Accepted: 53757 Descr ...
- 客户端连接虚拟机上的MYSQL报错
这个原因是因为虚拟机的数据库拒绝其他主机访问 所以需要设置虚拟机的mysql 打开mysql mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' ID ...
- 有关react-native的最常用的库(文件、样式、UI组件)
一.对文件的处理 1.react-native-fs 2.react-native-file-selector 3.MaterialFilePicker 二.React-Native 样式指南 1.r ...
- AJAX异步对象,即XMLHttpRequest
//创建AJAX异步对象,即XMLHttpRequest function createAJAX(){ var ajax = null; try{ ajax = new ActiveXObject(& ...
- python从入门到放弃之Tensorflow(一)
Tensorflow使用错误集锦: 错误1 : FutureWarning: Conversion of the second argument of issubdtype from ‘float’ ...
- js图片预览带进度条
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...