ActiveMQ配置详解
一.消息目的地策略
在节点destinationPolicy配置策略,可以对单个或者所有的主题和队列进行设置,使用流量监控,当消息达到memoryLimit的时候,ActiveMQ会减慢消息的产生甚至阻塞,destinationPolicy的配置如下:
<!-- Destination specific policies using destination names or wildcards -->
<!-- wildcards意义见http://activemq.apache.org/wildcards.html -->
<destinationPolicy>
<policyMap>
<policyEntries>
<!-- 这里使用了wildcards,表示所有以Msg开头的topic -->
<policyEntry topic="Msg.>" producerFlowControl="false" memoryLimit="10mb">
<!-- 分发策略 -->
<dispatchPolicy>
<!-- 按顺序分发 -->
<strictOrderDispatchPolicy/>
</dispatchPolicy>
<!-- 恢复策略-->
<subscriptionRecoveryPolicy>
<!-- 只恢复最后一个message -->
<lastImageSubscriptionRecoveryPolicy/>
</subscriptionRecoveryPolicy>
</policyEntry>
</policyEntries>
</policyMap>
</destinationPolicy>
二.存储配置
producerFlowControl表示是否监控流量,默认为true,如果设置为false,消息就会存在磁盘中以防止内存溢 出;memoryLimit表示在producerFlowControl=”true”的情况下,消息存储在内存中最大量,当消息达到这个值 时,ActiveMQ会减慢消息的产生甚至阻塞。
队列分发策略如下:
| property | default | description |
|---|---|---|
| useConsumerPriority | true | use the priority of a consumer when dispatching messages from a Queue |
| strictOrderDispatch | false | if true queue will not round robin consumers, but it'll use a single one until its prefetch buffer is full |
| optimizedDispatch | false | don't use a separate thread for dispatching from a Queue |
| lazyDispatch | false | only page in from store the number of messages that can be dispatched at time |
| consumersBeforeDispatchStarts | 0 | when the first consumer connects, wait for specified number of consumers before message dispatching starts |
| timeBeforeDispatchStarts | 0 | when the first consumer connects, wait for specified time (in ms) before message dispatching starts |
| queuePrefetch | n/a | sets the prefetch for consumers that are using the default value |
| expireMessagesPeriod | 30000 | the period (in ms) of checks for message expiry on queued messages, value of 0 disables |
简单翻译如下:
useConsumerPriority:默认策略,按照用户优先级设置发送消息
strictOrderDispatchPolicy:保证每个topic consumer会以相同的顺序接收消息,代价是性能上的损失
policyEntry的属性参考:http://activemq.apache.org/per-destination-policies.html
当producer发送的持久化消息到达broker之后,broker首先会把它保存在持久存储中。接下来,如果发现当前有活跃的 consumer,如果这个consumer消费消息的速度能跟上producer生产消息的速度,那么ActiveMQ会直接把消息传递给broker 内部跟这个consumer关联的dispatch queue;如果当前没有活跃的consumer或者consumer消费消息的速度跟不上producer生产消息的速度,那么ActiveMQ会使用 Pending Message Cursors保存对消息的引用。在需要的时候,Pending Message Cursors把消息引用传递给broker内部跟这个consumer关联的dispatch queue。以下是两种Pending Message Cursors:
VM Cursor:在内存中保存消息的引用。
File Cursor:首先在内存中保存消息的引用,如果内存使用量达到上限,那么会把消息引用保存到临时文件中。
在缺省情况下,ActiveMQ 会根据使用的Message Store来决定使用何种类型的Message Cursors,但是你可以根据destination来配置Message Cursors。
对于topic,可以使用的pendingSubscriberPolicy 有vmCursor和fileCursor。可以使用的PendingDurableSubscriberMessageStoragePolicy有
vmDurableCursor 和 fileDurableSubscriberCursor;对于queue,可以使用的pendingQueuePolicy有vmQueueCursor 和 fileQueueCursor。
Message Cursors的使用参考:http://activemq.apache.org/message-cursors.html
三.主备配置
设置消息在内存、磁盘中存储的大小,配置如下:
<systemUsage>
<systemUsage>
<memoryUsage>
<memoryUsage limit="20 mb"/>
</memoryUsage>
<storeUsage>
<storeUsage limit="1 gb"/>
</storeUsage>
<tempUsage>
<tempUsage limit="100 mb"/>
</tempUsage>
</systemUsage>
</systemUsage>
memoryUsage表示ActiveMQ使用的内存,这个值要大于等于destinationPolicy中设置的所有队列的内存之和。
storeUsage表示持久化存储文件的大小。
tempUsage表示非持久化消息存储的临时内存大小。
ActiveMQ的主备有三种方式:纯Master/Slave、文件共享方式、数据库共享方式。
1、纯Master/Slave
这种方式的主备不需要对Master Broker做特殊的配置,只要在Slave Broker中指定他的Master就可以了,指定Master有两种方式,最简单的配置就是在broker节点中添加 masterConnectorURI=”tcp://localhost:61616″即可,还有一种方式就是添加一个services节点,可以指定 连接的用户名和密码,配置如下:
<services>
<masterConnector remoteURI= "tcp://localhost:61616" userName="system" password="manager"/>
</services>
纯Master/Slave只允许一个Slave连接到Master上面,也就是说只能有2台MQ做集群,同时当Master挂了之后需要停止Slave来恢复负载。
2、数据库共享方式
这种方式的主备采用数据库做消息的持久化,支持多个Slave,所有broker持久化数据源配置成同一个数据源,当一个broker获取的数据库锁之 后,其他的broker都成为slave并且等待获取锁,当master挂了之后,其中的一个slave将会立刻获得数据库锁成为master,重启之前 挂掉的master之后,这个master也就成了slave,不需要停止slave来恢复。由于采用的是数据库做为持久化,它的性能是有限的。
3、文件共享方式
这种方式的主备具有和数据库共享方式的负载一样的特性,不同的是broker的持久化采用的是文件(我这里用KahaDB),slave等待获取的锁是文件锁,它具有更高的性能,但是需要文件共享系统的支持。
Window下共享KahaDB持久化的目录,配置如下:
<persistenceAdapter>
<kahaDB directory="//172.16.1.202/mqdata/kahadb"/>
</persistenceAdapter>
Linux下需要开启NFS服务,具体操作如下:
创建共享目录(192.168.0.1):
1、 修改etc/exports,添加需要共享的目录:/opt/mq/data *(rw,no_root_squash)
2、 启动NFS服务 service nfs start/restart
3、 查看共享 showmount –e
4、 NFS服务自启动 chkconfig –level 35 nfs on
挂载共享目录(192.168.0.2):
1、 挂载:mount –t nfs 192.168.0.1:/opt/mq/data /opt/mq/data
2、 启动自动挂载:在etc/fstab文件添加10.175.40.244:/opt/mq/data /opt/mq/data nfs defaults 0 0
然后指定KahaDB的持久化目录为/opt/mq/data即可。
AIX系统的文件共享和Linux类似,也是启动NFS服务。
注意:如果Master服务器宕机了,Slave是不会获得文件锁而启动,直到Master服务器重启。
Window下Master上有Slave连接时如图:
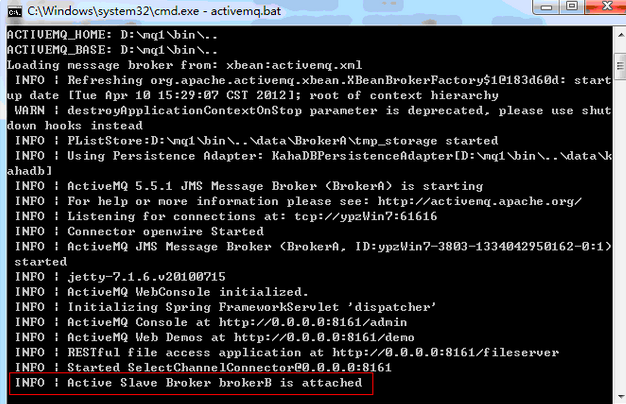
客户端连接的brokerURL为failover:(tcp://localhost:61616,tcp://localhost:61617)。用 第三部分的代码测试,先向Master Broker发送一个消息,然后关闭master,运行获取消息的方法,即可获取之前发送的消息。
四.负载均衡配置
ActiveMQ可以实现多个mq之间进行路由,假设有两个mq,分别为brokerA和brokerB,当有一条消息发送到brokerA的队列 test中,有一个客户端连接到brokerB上,并且要求获取test队列的消息时,brokerA中队列test的消息就会路由到brokerB上, 反之brokerB的消息也会路由到brokerA。
静态路由配置,brokerA不需要特别的配置,brokerB需要配置networkConnectors节点,具体配置如下:
<networkConnectors>
<networkConnector uri="static:(tcp://localhost:61616)" duplex="true"/>
</networkConnectors>
静态路由支持failover,如:static:failover://(tcp://host1:61616,tcp://host2:61616)。
动态路由配置,每个mq都需要配置如下:
<networkConnectors>
<networkConnector uri="multicast://default" />
</networkConnectors> <transportConnectors>
<transportConnector name="openwire" uri="tcp://0.0.0.0:61618" discoveryUri="multicast://default" />
</transportConnectors>
注意:networkConnectors需要配置在persistenceAdapter之前。
重启ActiveMQ,可以看到brokerA的日志如图:
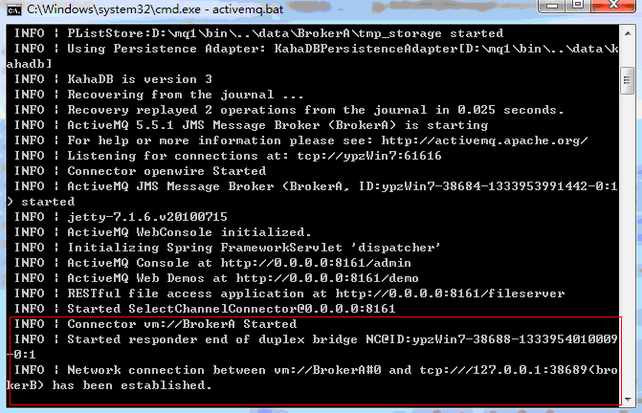
networkConnector的属性请参照:http://activemq.apache.org/networks-of-brokers.html
五.持久化配置
1、AMQ
AMQ是一种文件存储形式,它具有写入速度快和容易恢复的特点。消息存储在一个个文件中,文件的默认大小为32兆,如果一条消息的大小超过了32 兆,那么这个值必须设置大点。当一个存储文件中的消息已经全部被消费,那么这个文件将被标识为可删除,在下一个清除阶段,这个文件被删除。默认配置如下:
<persistenceAdapter>
<amqPersistenceAdapter directory="activemq-data" maxFileLength="32mb"/>
</persistenceAdapter>
AMQ的属性:
| 属性名称 | 默认值 | 描述 |
| directory | activemq-data | 消息文件和日志的存储目录 |
| useNIO | true | 使用NIO协议存储消息 |
| syncOnWrite | false | 同步写到磁盘,这个选项对性能影响非常大 |
| maxFileLength | 32mb | 一个消息文件的大小 |
| persistentIndex | true | 消息索引的持久化,如果为false,那么索引保存在内存中 |
| maxCheckpointMessageAddSize | 4kb | 一个事务允许的最大消息量 |
| cleanupInterval | 30000 | 清除操作周期,单位ms |
| indexBinSize | 1024 | 索引文件缓存页面数,缺省为1024,当amq扩充或者缩减存储时,会锁定整个broker,导致一定时间的阻塞,所以这个值应该调整到比较大,但是代码中实现会动态伸缩,调整效果并不理想。 |
| indexKeySize | 96 | 索引key的大小,key是消息ID |
| indexPageSize | 16kb | 索引的页大小 |
| directoryArchive | archive | 存储被归档的消息文件目录 |
| archiveDataLogs | false | 当为true时,归档的消息文件被移到directoryArchive,而不是直接删除 |
2、KahaDB
KahaDB是基于文件的本地数据库储存形式,虽然没有AMQ的速度快,但是它具有强扩展性,恢复的时间比AMQ短,从5.4版本之后KahaDB做为默认的持久化方式。默认配置如下:
<persistenceAdapter>
<kahaDB directory="activemq-data" journalMaxFileLength="32mb"/>
</persistenceAdapter>
KahaDB的属性:
| property name | default value | Comments |
| directory | activemq-data | 消息文件和日志的存储目录 |
| indexWriteBatchSize | 1000 | 一批索引的大小,当要更新的索引量到达这个值时,更新到消息文件中 |
| indexCacheSize | 10000 | 内存中,索引的页大小 |
| enableIndexWriteAsync | false | 索引是否异步写到消息文件中 |
| journalMaxFileLength | 32mb | 一个消息文件的大小 |
| enableJournalDiskSyncs | true | 是否讲非事务的消息同步写入到磁盘 |
| cleanupInterval | 30000 | 清除操作周期,单位ms |
| checkpointInterval | 5000 | 索引写入到消息文件的周期,单位ms |
| ignoreMissingJournalfiles | false | 忽略丢失的消息文件,false,当丢失了消息文件,启动异常 |
| checkForCorruptJournalFiles | false | 检查消息文件是否损坏,true,检查发现损坏会尝试修复 |
| checksumJournalFiles | false | 产生一个checksum,以便能够检测journal文件是否损坏。 |
| 5.4版本之后有效的属性: | ||
| archiveDataLogs | false | 当为true时,归档的消息文件被移到directoryArchive,而不是直接删除 |
| directoryArchive | null | 存储被归档的消息文件目录 |
| databaseLockedWaitDelay | 10000 | 在使用负载时,等待获得文件锁的延迟时间,单位ms |
| maxAsyncJobs | 10000 | 同个生产者产生等待写入的异步消息最大量 |
| concurrentStoreAndDispatchTopics | false | 当写入消息的时候,是否转发主题消息 |
| concurrentStoreAndDispatchQueues | true | 当写入消息的时候,是否转发队列消息 |
| 5.6版本之后有效的属性: | ||
| archiveCorruptedIndex | false | 是否归档错误的索引 |
从5.6版本之后,有可能发布通过多个kahadb持久适配器来实现分布式目标队列存储。什么时候用呢?如果有一个快速的生产者和消费者,当某一个 时刻生产者发生了不规范的消费,那么有可能产生一条消息被存储在两个消息文件中,同时,有些目标队列是危险的并且要求访问磁盘。在这种情况下,你应该用通 配符来使用mKahaDB。如果目标队列是分布的,事务是可以跨越多个消息文件的。
每个KahaDB的实例都可以配置单独的适配器,如果没有目标队列提交给filteredKahaDB,那么意味着对所有的队列有效。如果一个队列没有对应的适配器,那么将会抛出一个异常。配置如下:
<persistenceAdapter>
<mKahaDB directory="${activemq.base}/data/kahadb">
<filteredPersistenceAdapters>
<!-- match all queues -->
<filteredKahaDB queue=">">
<persistenceAdapter>
<kahaDB journalMaxFileLength="32mb"/>
</persistenceAdapter>
</filteredKahaDB> <!-- match all destinations -->
<filteredKahaDB>
<persistenceAdapter>
<kahaDB enableJournalDiskSyncs="false"/>
</persistenceAdapter>
</filteredKahaDB>
</filteredPersistenceAdapters>
</mKahaDB>
</persistenceAdapter>
如果filteredKahaDB的perDestination属性设置为true,那么匹配的目标队列将会得到自己对应的KahaDB实例。配置如下:
<persistenceAdapter>
<mKahaDB directory="${activemq.base}/data/kahadb">
<filteredPersistenceAdapters>
<!-- kahaDB per destinations -->
<filteredKahaDB perDestination="true" >
<persistenceAdapter>
<kahaDB journalMaxFileLength="32mb" />
</persistenceAdapter>
</filteredKahaDB>
</filteredPersistenceAdapters>
</mKahaDB>
</persistenceAdapter>
3、JDBC
配置JDBC适配器:
<persistenceAdapter>
<jdbcPersistenceAdapter dataSource="#mysql-ds" createTablesOnStartup="false" />
</persistenceAdapter>
dataSource指定持久化数据库的bean,createTablesOnStartup是否在启动的时候创建数据表,默认值是true,这样每次启动都会去创建数据表了,一般是第一次启动的时候设置为true,之后改成false。
MYSQL持久化bean
<bean id="mysql-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost/activemq?relaxAutoCommit=true"/>
<property name="username" value="activemq"/>
<property name="password" value="activemq"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
SQL Server持久化bean
<bean id="mssql-ds" class="net.sourceforge.jtds.jdbcx.JtdsDataSource" destroy-method="close">
<property name="serverName" value="SERVERNAME"/>
<property name="portNumber" value="PORTNUMBER"/>
<property name="databaseName" value="DATABASENAME"/>
<property name="user" value="USER"/>
<property name="password" value="PASSWORD"/>
</bean>
Oracle持久化bean
<bean id="oracle-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@10.53.132.47:1521:activemq"/>
<property name="username" value="activemq"/>
<property name="password" value="activemq"/>
<property name="maxActive" value="200"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
DB2持久化bean
<bean id="db2-ds" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.ibm.db2.jcc.DB2Driver"/>
<property name="url" value="jdbc:db2://hndb02.bf.ctc.com:50002/activemq"/>
<property name="username" value="activemq"/>
<property name="password" value="activemq"/>
<property name="maxActive" value="200"/>
<property name="poolPreparedStatements" value="true"/>
</bean>
ActiveMQ配置详解的更多相关文章
- ActiveMQ基本详解与总结& 消息队列-推/拉模式学习 & ActiveMQ及JMS学习
转自:https://www.cnblogs.com/Survivalist/p/8094069.html ActiveMQ基本详解与总结 基本使用可以参考https://www.cnblogs.co ...
- 消息中间件ActiveMQ使用详解
消息中间件ActiveMQ使用详解 一.消息中间件的介绍 介绍 消息队列 是指利用 高效可靠 的 消息传递机制 进行与平台无关的 数据交流,并基于 数据通信 来进行分布式系统的集成. 特点(作用) ...
- Log4j配置详解(转)
一.Log4j简介 Log4j有三个主要的组件:Loggers(记录器),Appenders (输出源)和Layouts(布局).这里可简单理解为日志类别,日志要输出的地方和日志以何种形式输出.综合使 ...
- logback 常用配置详解<appender>
logback 常用配置详解 <appender> <appender>: <appender>是<configuration>的子节点,是负责写日志的 ...
- [转]阿里巴巴数据库连接池 druid配置详解
一.背景 java程序很大一部分要操作数据库,为了提高性能操作数据库的时候,又不得不使用数据库连接池.数据库连接池有很多选择,c3p.dhcp.proxool等,druid作为一名后起之秀,凭借其出色 ...
- libCURL开源库在VS2010环境下编译安装,配置详解
libCURL开源库在VS2010环境下编译安装,配置详解 转自:http://my.oschina.net/u/1420791/blog/198247 http://blog.csdn.net/su ...
- logback配置详解3<filter>
logback 常用配置详解(三) <filter> <filter>: 过滤器,执行一个过滤器会有返回个枚举值,即DENY,NEUTRAL,ACCEPT其中之一.返回DENY ...
- logback配置详解2<appender>
logback 常用配置详解(二) <appender> <appender>: <appender>是<configuration>的子节点,是负责写 ...
- log4j.properties配置详解
1.Loggers Loggers组件在此系统中被分为五个级别:DEBUG.INFO.WARN.ERROR和FATAL.这五个级别是有顺序的,DEBUG < INFO < WARN < ...
随机推荐
- String替换占位符
/** * 依次替换占位符 * 例如: 姓名:{s},电话:{s},邮箱:{s} --> 姓名:小张,电话:18800000001,邮箱:abc@123.com * pattern = &quo ...
- spring的finishBeanFactoryInitialization方法分析
spring源码版本5.0.5 概述 该方法会实例化所有剩余的非懒加载单例 bean.除了一些内部的 bean.实现了 BeanFactoryPostProcessor 接口的 bean.实现了 Be ...
- Mysql数据库多对多关系未建新表
原则上,多对多关系是要新建一个关系表的,当遇到没有新建表的情况下如何查询多对多的SQL呢? FIND_IN_SET(str,strlist) 官网:http://dev.mysql.com/doc/r ...
- JS栈内存与堆内存
㈠JavaScript变量 ⒈分类 ⑴JavaScript中的变量分为基本类型和引用类型. ⑵基本类型就是保存在栈内存中的简单数据段. ⑶引用类型指的是那些保存在堆内存中的对象. ⒉基本类型 基本类 ...
- Java数据库小项目00---基础知识
目录 JDBC的简单使用 向JDBC注入攻击 防止注入攻击 自建JDBC工具类 自建工具类优化--使用配置文件 使用数据库连接池优化工具类 JDBC的简单使用 package Test; import ...
- removeClass([class|fn])
removeClass([class|fn]) 概述 从所有匹配的元素中删除全部或者指定的类.直线电机生产厂家 参数 classStringV1.0 一个或多个要删除的CSS类名,请用空格分开 f ...
- effective c++ (四)
条款10:令operator=返回一个reference to *this 为了实现“连锁赋值”,赋值操作符必须返回一个reference指向操作符的左侧实参,这是你为classes实现赋值操作符时应 ...
- sql到python正则
import urllib.requestimport re,timeresult=[]for i in range(100): urls ="http://xxx.com/-1%20 ...
- Netfilter 之 连接跟踪初始化
基础参数初始化 nf_conntrack_init_start函数完成连接跟踪基础参数的初始化,包括了hash,slab,扩展项,GC任务等: int nf_conntrack_init_start( ...
- outlier异常值检验算法之_箱型图(附python代码)
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003&u ...