什么是N+1查询?
在Session的缓存中存放的是相互关联的对象图。默认情况下,当Hibernate从数据库中加载Customer对象时,会同时加载所有关联的Order对象。以Customer和Order类为例,假定ORDERS表的CUSTOMER_ID外键允许为null,图1列出了CUSTOMERS表和ORDERS表中的记录。
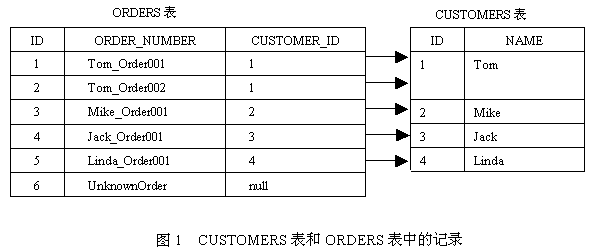
以下Session的find()方法用于到数据库中检索所有的Customer对象:
List customerLists=session.find("from Customer as c");
运行以上find()方法时,Hibernate将先查询CUSTOMERS表中所有的记录,然后根据每条记录的ID,到ORDERS表中查询有参照关系的记录,Hibernate将依次执行以下select语句:
select * from CUSTOMERS;
select * from ORDERS where CUSTOMER_ID=1;
select * from ORDERS where CUSTOMER_ID=2;
select * from ORDERS where CUSTOMER_ID=3;
select * from ORDERS where CUSTOMER_ID=4;
通过以上5条select语句,Hibernate最后加载了4个Customer对象和5个Order对象,在内存中形成了一幅关联的对象图,参见图2。
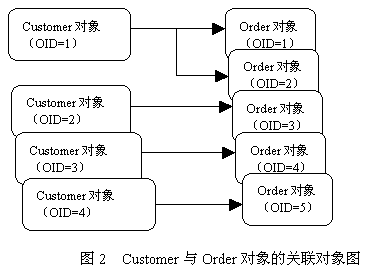
Hibernate在检索与Customer关联的Order对象时,使用了默认的立即检索策略。这种检索策略存在两大不足:
(1) select语句的数目太多,需要频繁的访问数据库,会影响检索性能。如果需要查询n个Customer对象,那么必须执行n+1次select查询语句。这就是经典的n+1次select查询问题。 这种检索策略没有利用SQL的连接查询功能,例如以上5条select语句完全可以通过以下1条select语句来完成:
select * from CUSTOMERS left outer join ORDERS
on CUSTOMERS.ID=ORDERS.CUSTOMER_ID
以上select语句使用了SQL的左外连接查询功能,能够在一条select语句中查询出CUSTOMERS表的所有记录,以及匹配的ORDERS表的记录。
(2)在应用逻辑只需要访问Customer对象,而不需要访问Order对象的场合,加载Order对象完全是多余的操作,这些多余的Order对象白白浪费了许多内存空间。
为了解决以上问题,Hibernate提供了其他两种检索策略:延迟检索策略和迫切左外连接检索策略。延迟检索策略能避免多余加载应用程序不需要访问的关联对象,迫切左外连接检索策略则充分利用了SQL的外连接查询功能,能够减少select语句的数目。
附一篇 hibernate的解决n+1的方法
Hibernate的检索策略包括类级别检索策略和关联级别检索策略。
类级别检索策略有立即检索和延迟检索,默认的检索策略是立即检索。在Hibernate映射文件中,通过在<class>上配置 lazy属性来确定检索策略。对于Session的检索方式,类级别检索策略仅适用于load方法;也就说,对于get、qurey检索,持久化对象都会被立即加载而不管lazy是false还是true.一般来说,我们检索对象就是要访问它,因此立即检索是通常的选择。由于load方法在检索不到对象时会抛出异常(立即检索的情况下),因此我个人并不建议使用load检索;而由于<class>中的lazy属性还影响到多对一及一对一的检索策略,因此使用load方法就更没必要了。
关联级别检索策略有立即检索、延迟检索和迫切左外连接检索。对于关联级别检索,又可分为一对多和多对多、多对一和一对一两种情况讨论。
1)立即检索:这是一对多默认的检索策略,此时lazy=false,outer-join=false.尽管这是默认的检索策略,但如果关联的集合是无用的,那么就不要使用这种检索方式。
2)延迟检索:此时lazy=true,outer-join=false(outer-join=true是无意义的),这是优先考虑的检索方式。
3)迫切左外连接检索:此时 lazy=false,outer-join=true,这种检索策略只适用于依靠id检索方式(load、get),而不适用于query的集合检索(它会采用立即检索策略)。相比于立即检索,这种检索策略减少了一条sql语句,但在Hibernate中,只能有一个<set>配置成 outer-join=true.
多对一和一对一检索策略一般使用<many-to-one>、<one-to-one>配置。<many- to-one>中需要配置的属性是 outer-join,同时还需要配置one端关联的<class>的lazy属性(配置的可不是<many-to-one>中的lazy哦),它们的组合后的检索策略如下:
1) outer-join=auto:这是默认值,如果lazy=true为延迟检索,如果lazy=false为迫切左外连接检索
2) outer-join=true,无关于lazy,都为迫切左外连接检索。
3) outer-join=false,如果lazy=true为延迟检索,否则为立即检索。
可以看到,在默认的情况下(outer-join=auto,lazy=false),对关联的one端对象Hibernate采用的迫切左外连接检索。依我看,很多情况下,我们并不需要加载one端关联的对象(很可能我们需要的仅仅是关联对象的id);另外,如果关联对象也采用了迫切左外连接检索,就会出现select语句中有多个外连接表,如果个数多的话会影响检索性能,这也是为什么Hibernate通过 hibernate.max_fetch_depth属性来控制外连接的深度。对于迫切左外连接检索,query的集合检索并不适用,它会采用立即检索策略。
对于检索策略,需要根据实际情况进行选择。对于立即检索和延迟检索,它们的优点在于select语句简单(每张表一条语句)、查询速度快,缺点在于关联表时需要多条select语句,增加了访问数据库的频率。因此在选择即检索和延迟检索时,可以考虑使用批量检索策略来减少select语句的数量(配置batch-size属性)。对于切左外连接检索,优点在于select较少,但缺点是select语句的复杂度提高,多表之间的关联会是很耗时的操作。另外,配置文件是死的,但程序是活的,可以根据需要在程序里显示的指定检索策略(可能经常需要在程序中显示指定迫切左外连接检索)。为了清楚检索策略的配置效果如何,可以配置show_sql属性查看程序运行时Hibernate执行的sql语句。
什么是N+1查询?的更多相关文章
- 使用TSQL查询和更新 JSON 数据
JSON是一个非常流行的,用于数据交换的文本数据(textual data)格式,主要用于Web和移动应用程序中.JSON 使用“键/值对”(Key:Value pair)存储数据,能够表示嵌套键值对 ...
- UWP 律师查询 MVVM
APP简介 律师查询是基于聚合数据的律师查询接口做的,这个接口目前处于停用状态,但是,由于我是之前申请的,所以,还可以用,应该是无法再申请了. 效果图 开发 一.HttpHelper 既然是请求接口的 ...
- Elasticsearch 5.0 中term 查询和match 查询的认识
Elasticsearch 5.0 关于term query和match query的认识 一.基本情况 前言:term query和match query牵扯的东西比较多,例如分词器.mapping ...
- ASP.NET Aries 入门开发教程4:查询区的下拉配置
背景: 今天去深圳溜达了一天,刚回来,看到首页都是微软大法好,看来离.NET的春天就差3个月了~~ 回到正题,这篇的教程讲解下拉配置. 查询区的下拉配置: 1:查询框怎么配置成下拉? 在配置表头:格式 ...
- ASP.NET Aries 入门开发教程3:开发一个列表页面及操控查询区
前言: Aries框架毕竟是开发框架,所以重点还是要写代码的,这样开发人员才不会失业,哈. 步骤1:新建html 建一个Html,主要有三步: 1:引入Aries.Loader.js 2:弄一个tab ...
- ExtJS 4.2 业务开发(二)数据展示和查询
本篇开始模拟一个船舶管理系统,提供查询.添加.修改船舶的功能,这里介绍其中的数据展示和查询功能. 目录 1. 数据展示 2. 数据查询 3. 在线演示 1. 数据展示 在这里我们将模拟一个船舶管理系统 ...
- 深入理解MySql子查询IN的执行和优化
IN为什么慢? 在应用程序中使用子查询后,SQL语句的查询性能变得非常糟糕.例如: SELECT driver_id FROM driver where driver_id in (SELECT dr ...
- ElasticSearch 5学习(10)——结构化查询(包括新特性)
之前我们所有的查询都属于命令行查询,但是不利于复杂的查询,而且一般在项目开发中不使用命令行查询方式,只有在调试测试时使用简单命令行查询,但是,如果想要善用搜索,我们必须使用请求体查询(request ...
- 【初学python】使用python连接mysql数据查询结果并显示
因为测试工作经常需要与后台数据库进行数据比较和统计,所以采用python编写连接数据库脚本方便测试,提高工作效率,脚本如下(python连接mysql需要引入第三方库MySQLdb,百度下载安装) # ...
- JdbcTemplate+PageImpl实现多表分页查询
一.基础实体 @MappedSuperclass public abstract class AbsIdEntity implements Serializable { private static ...
随机推荐
- Spring走向注解驱动编程
SpringFramework的两大核心,IOC(Inversion of control)控制反转和DI(Dependency Inject)依赖注入,其推崇的理念是应用系统不应以java代码的方式 ...
- python数据可视化:pyecharts
发现了一个做数据可视化非常好的库:pyecharts.非常便捷好用,大力推荐!! 官方介绍:pyecharts 是一个用于生成 Echarts 图表的类库.Echarts 是百度开源的一个数据可视化 ...
- 关于appium操作真机打开app之后无法定位页面元素的问题的解决办法
appium操作真机打开app后无法定位页面元素:例如微信或者支付宝支付时,手机的安全控件会对支付环境进行保护,会断掉当前appium与真机的链接,导致连接失败,无法定位到页面元素,在做ui自动化之前 ...
- ubuntu 16.04 修改网卡显示名称
~# sudo nano /etc/default/grub找到:GRUB_CMDLINE_LINUX=""改为:GRUB_CMDLINE_LINUX="net.ifna ...
- nginx利用fastcgi_cache模块缓存
nginx不仅有个大家很熟悉的缓存代理后端内容的proxy_cache,还有个被很多人忽视的fastcgi_cache.proxy_cache的作用是缓存后端服务器的内容,可能是任何内容,包括静态的和 ...
- Java点滴-List<Integer> list; 中尖括号的意思
这是jdk1.5后版本才有的新特性,泛型,指定传入的类型.这样定义之后,这个list只能接收Integer的对象. 以前没有加这个,传入的都是Object类型的,取出来的时候要强制类型转换为自己想要的 ...
- CentOS7.2配置LNMP环境并安装配置网站WordPress
1,安装环境查看 2,安装MySQL5.7.22 下载MySQL wget https://downloads.mysql.com/archives/get/file/mysql-5.7.22-1.e ...
- SpringBoot Profile使用详解及配置源码解析
在实践的过程中我们经常会遇到不同的环境需要不同配置文件的情况,如果每换一个环境重新修改配置文件或重新打包一次会比较麻烦,Spring Boot为此提供了Profile配置来解决此问题. Profile ...
- vue组件中的驼峰命名和短横线命名
参考链接:https://www.jianshu.com/p/f12872fc7bfb
- webkit浏览器下改变滚动条样式
/*定义滚动条轨道 内阴影+圆角*/ ::-webkit-scrollbar-track { -webkit-box-shadow: inset 0 0 6px rgba(0,0,0,0.3); ba ...